






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转载自 | 新智元、量子位
因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏。
全球复现DeepSeek的一波狂潮来了!
正如LeCun所言:「这一次,正是开源对闭源的胜利!」
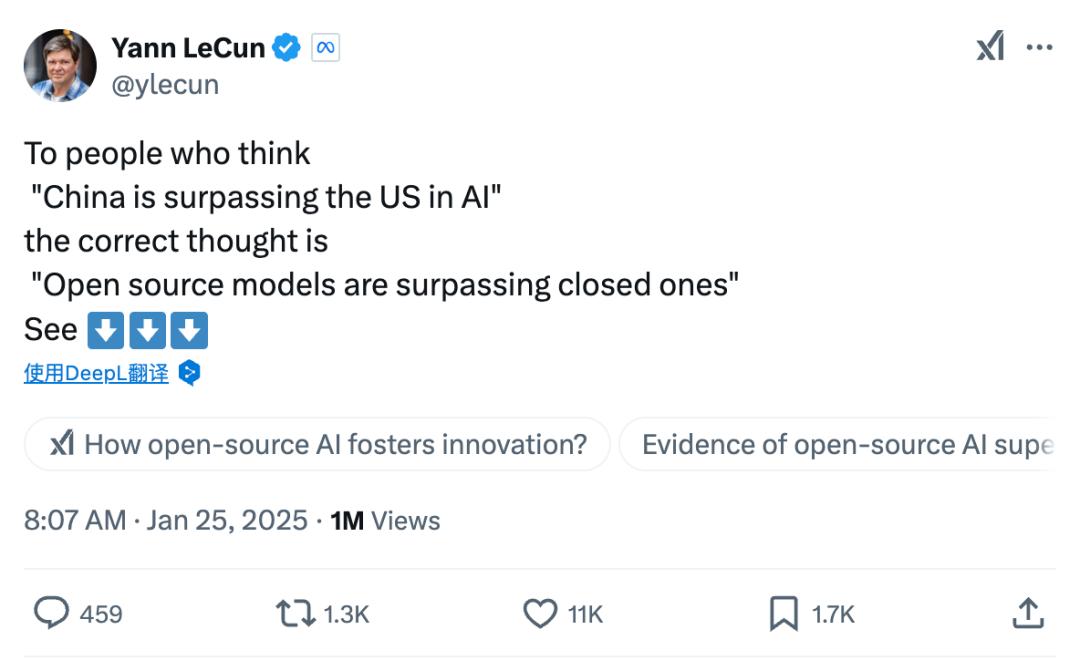
在没有顶级芯片的情况下,以极低成本芯片训出突破性模型的DeepSeek,或将威胁到美国的AI霸权。
大模型比拼的不再是动辄千万亿美元的算力战。
OpenAI、Meta、谷歌这些大公司引以为傲的技术优势和高估值将会瓦解,英伟达的股价将开始动摇。
种种这些观点和讨论,让人不禁怀疑:数百亿美元支出,对这个行业真的必要吗?甚至有人说,中国量化基金的一群天才,将导致纳斯达克崩盘。
从此,大模型时代很可能会进入一个分水岭:超强性能的模型不再独属于算力巨头,而是属于每个人。
以下项目地址汇总:
DeepSeek-R1:
https://github.com/deepseek-ai/DeepSeek-R1
HuggingFace:
https://github.com/huggingface/open-r1
伯克利团队:
https://github.com/Jiayi-Pan/TinyZero
港科大团队:
https://github.com/hkust-nlp/simpleRL-reason
Open R1:DeepSeek-R1全开源复现?
今天,HuggingFace团队官宣复刻DeepSeek R1所有pipeline。
复刻完成后,所有的训练数据、训练脚本等等,将全部开源。
这个项目叫做Open R1,当前还在进行中。截止目前,星标冲破3.4k,斩获255个fork。
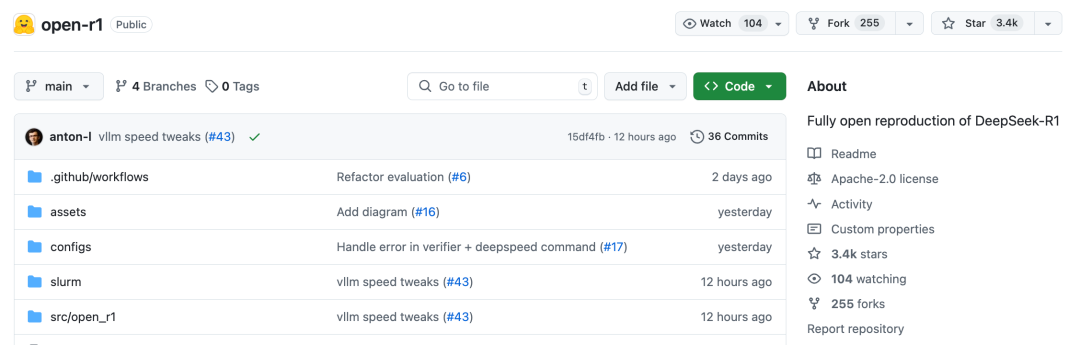
项目地址:https://github.com/huggingface/open-r1
不过话说回来,DeepSeek-R1本身就是开源的,HuggingFace搞这么个“Open R1”项目,又是为何?
官方在项目页中做了解释:
这个项目的目的是构建R1 pipeline中缺失的部分,以便所有人都能在此之上复制和构建R1。
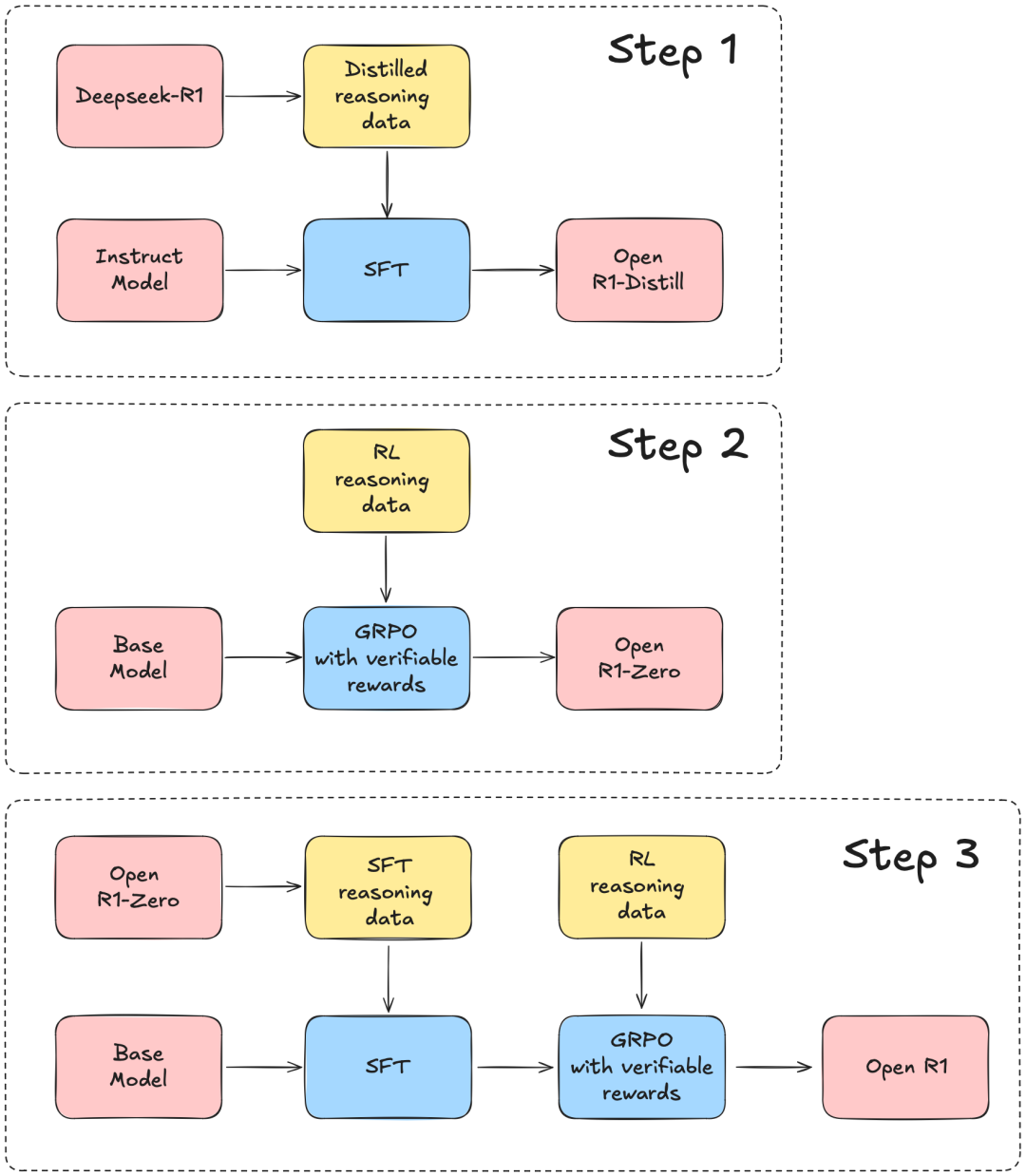
HuggingFace表示,将以DeepSeek-R1的技术报告为指导,分3个步骤完成这个项目:
第1步:用DeepSeek-R1蒸馏高质量语料库,来复制R1-Distill模型。
第2步:复制DeepSeek用来构建R1-Zero的纯强化学习(RL)pipeline。这可能涉及为数学、推理和代码整理新的大规模数据集。
第3步:通过多阶段训练,从基础模型过渡到RL版本。
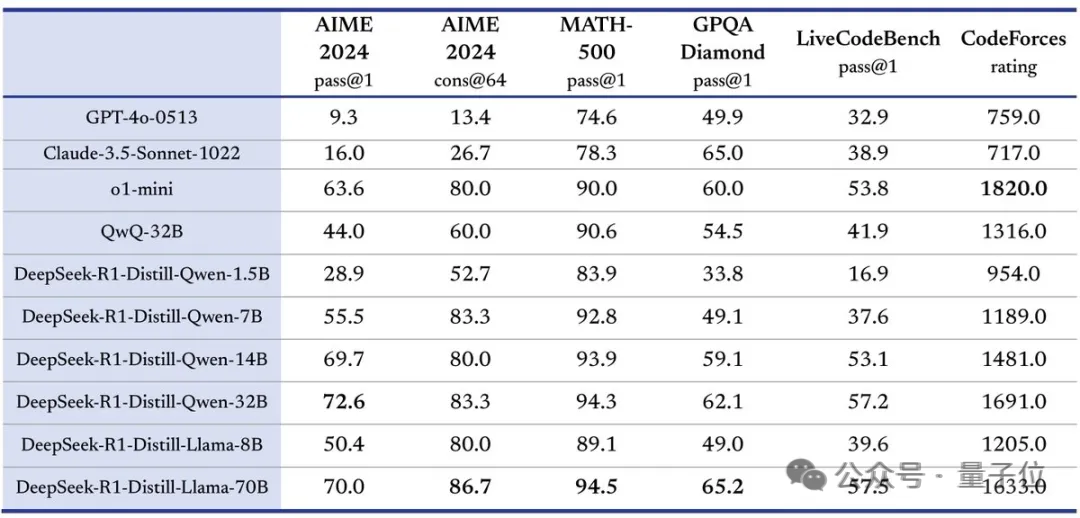
结合DeepSeek的官方技术报告来看,也就是说,Open R1项目首先要实现的,是用R1数据蒸馏小模型,看看效果是不是像DeepSeek说的那么好:
DeepSeek开源了6个用R1蒸馏的小模型,其中蒸馏版Qwen-1.5甚至能在部分任务上超过GPT-4o。
接下来,就是按照DeepSeek所说,不用SFT,纯靠RL调教出R1-Zero,再在R1-Zero的基础上复刻出性能逼近o1的R1模型。
其中多阶段训练是指,R1技术报告提到,DeepSeek-R1训练过程中引入了一个多阶段训练流程,具体包括以下4个阶段:
冷启动
用数千个长思维链(CoT)样本对基础模型进行监督微调(SFT),为模型提供初始的推理能力
面向推理的强化学习
在第一个SFT阶段的基础之上,用和训练R1-Zero相同的大规模强化学习方法,进一步提升模型的推理能力,特别是应对编程、数学、科学和逻辑推理任务的能力。
拒绝采样和监督微调
再次使用监督微调,提升模型的非推理能力,如事实知识、对话能力等。
针对所有场景的强化学习
这次强化学习的重点是让模型行为与人类偏好保持一致,提升模型的可用性和安全性。
目前,在GitHub仓库中,已经可以看到这几个文件:
GRPO实现
训练和评估代码
合成数据生成器
伯克利团队30美元成本复刻 R1-Zero?
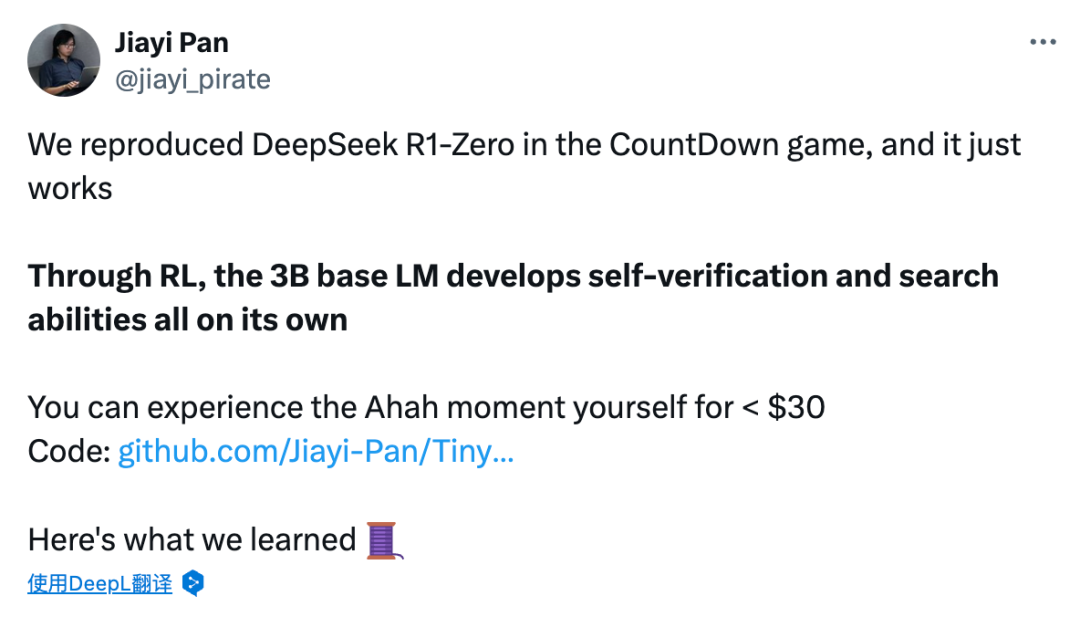
来自UC伯克利博士生潘家怡和另两位研究人员,在CountDown游戏中复现了DeepSeek R1-Zero。
他们表示,结果相当出色!
实验中,团队验证了通过强化学习RL,3B的基础语言模型也能够自我验证和搜索。
更令人兴奋的是,成本不到30美金(约217元),就可以亲眼见证「啊哈」时刻。
这个项目叫做TinyZero,采用了R1-Zero算法——给定一个基础语言模型、提示和真实奖励信号,运行强化学习。
然后,团队将其应用在CountDown游戏中(这是一个玩家使用基础算术运算,将数字组合以达到目标数字的游戏)。
模型从最初的简单输出开始,逐步进化出自我纠正和搜索的策略。
在以下示例中,模型提出了解决方案,自我验证,并反复纠正,直到解决问题为止。

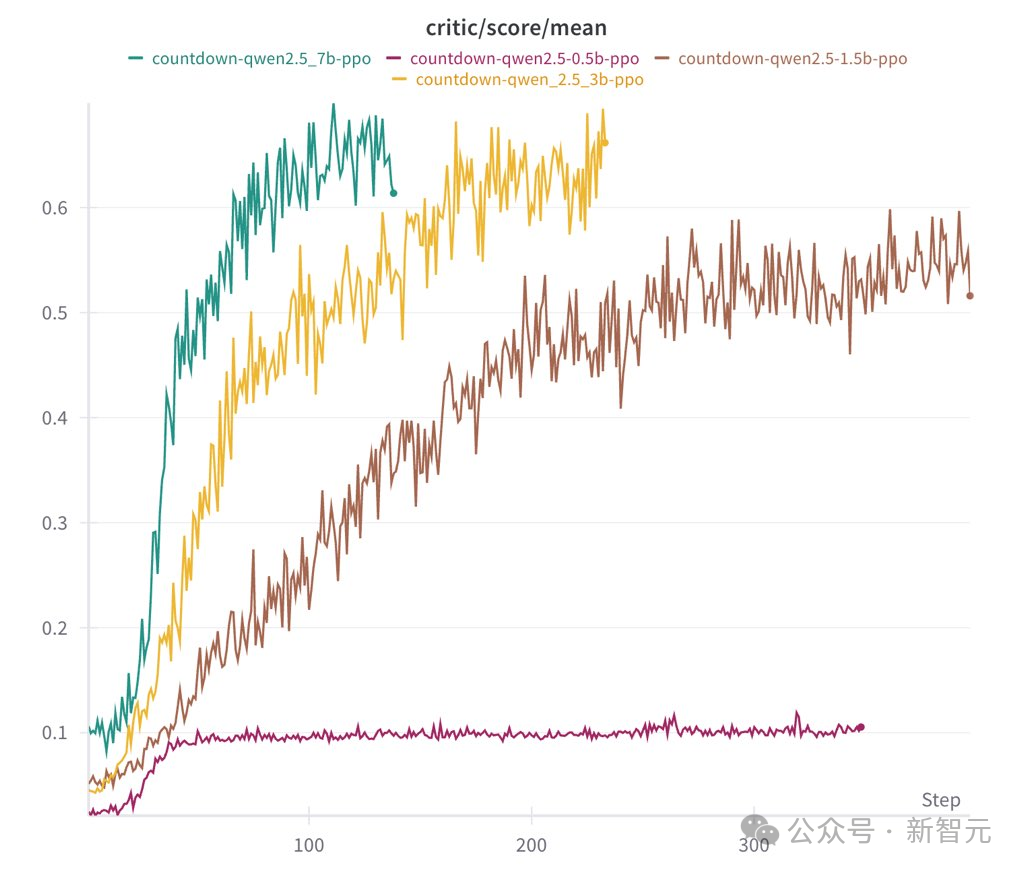
在消融实验中,研究人员运行了Qwen-2.5-Base(0.5B、1.5B、3B、7B四种参数规模)。
结果发现,0.5B模型仅仅是猜测一个解决方案然后停止。而从1.5B开始,模型学会了搜索、自我验证和修正其解决方案,从而能够获得更高的分数。
他们认为,在这个过程,基础模型的参数规模是决定性能的关键。
他们还验证了,额外的指令微调(SFT)并非是必要的,这也印证了R1-Zero的设计决策。

这是首个验证LLM推理能力的实现可以纯粹通过RL,无需监督微调的开源研究
基础模型和指令模型两者区别:
指令模型运行速度快,但最终表现与基础模型相当
指令输出的模型更具结构性和可读性
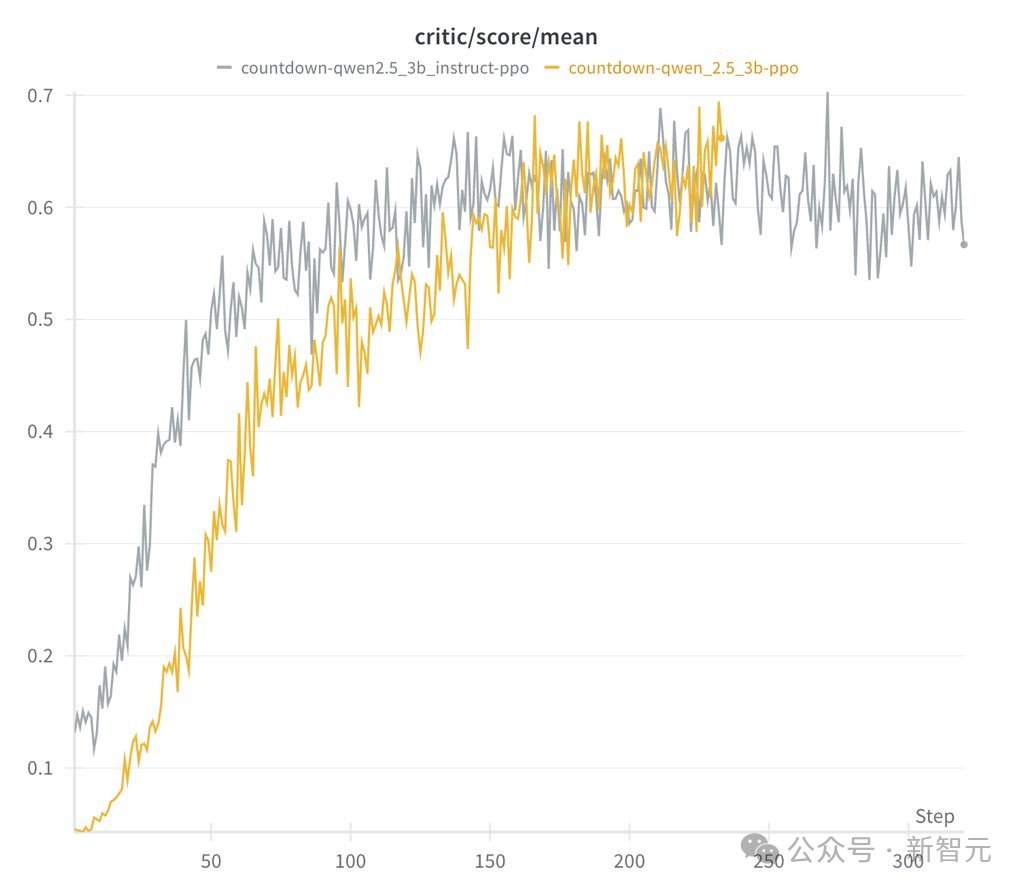
此外,他们还发现,具体的RL算法并不重要。PPO、GRPO、PRIME这些算法中,长思维链(Long CoT)都能够涌现,且带来不错的性能表现。
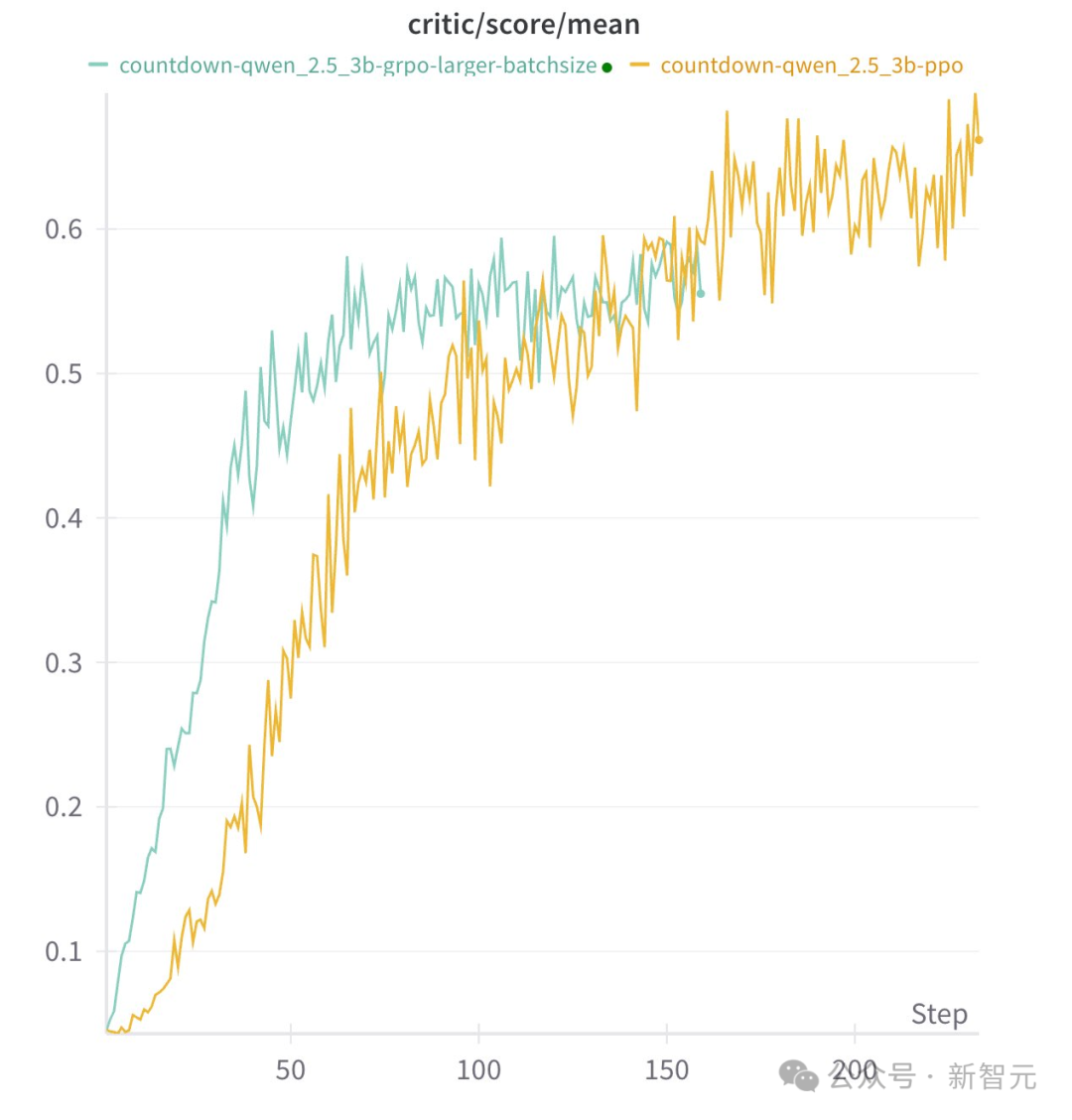
而且,模型在推理行为中非常依赖于具体的任务:
对于Countdow任务,模型学习进行搜索和自我验证
对于数字乘法任务,模型反而学习使用分布规则分解问题,并逐步解决
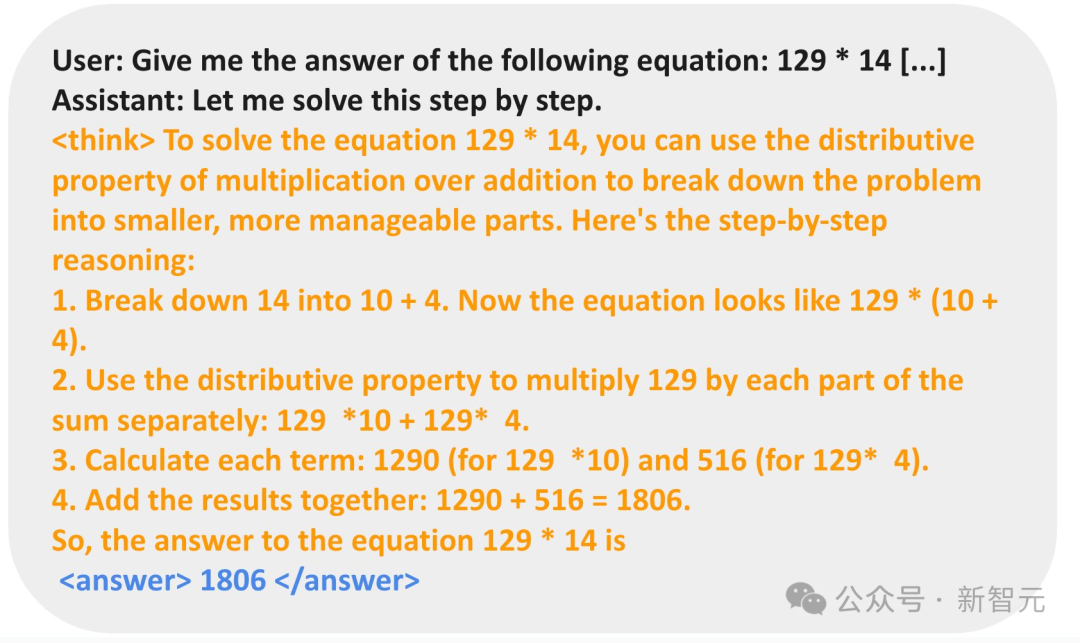
苹果机器学习科学家Yizhe Zhang对此表示,太酷了,小到1.5B的模型,也能通过RL涌现出自我验证的能力。

港科大团队使用8K样本完成7B模型复刻
港科大助理教授何俊贤的团队(共同一作黄裕振、Weihao Zeng),只用了8K个样本,就在7B模型上复刻出了DeepSeek-R1-Zero和DeepSeek-R1的训练。
结果令人惊喜——模型在复杂的数学推理上取得了十分强劲结果。


项目地址:https://github.com/hkust-nlp/simpleRL-reason
他们以Qwen2.5-Math-7B(基础模型)为起点,直接对其进行强化学习。
整个过程中,没有进行监督微调(SFT),也没有使用奖励模型。
最终,模型在AIME基准上实现了33.3%的准确率,在AMC上为62.5%,在MATH上为77.2%。
这一表现不仅超越了Qwen2.5-Math-7B-Instruct,并且还可以和使用超过50倍数据量和更复杂组件的PRIME和rStar-MATH相媲美!
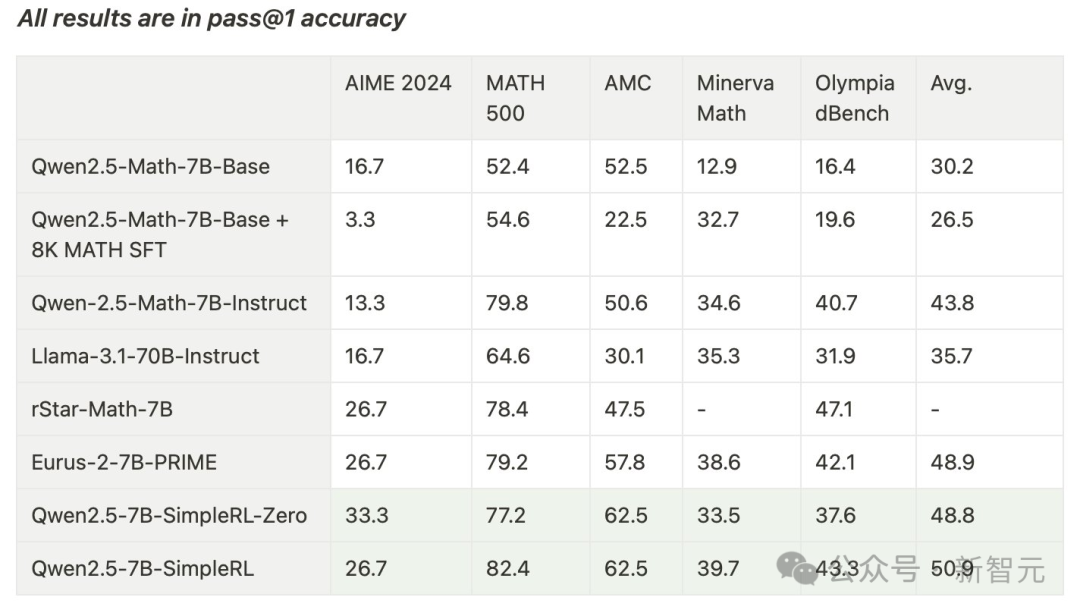
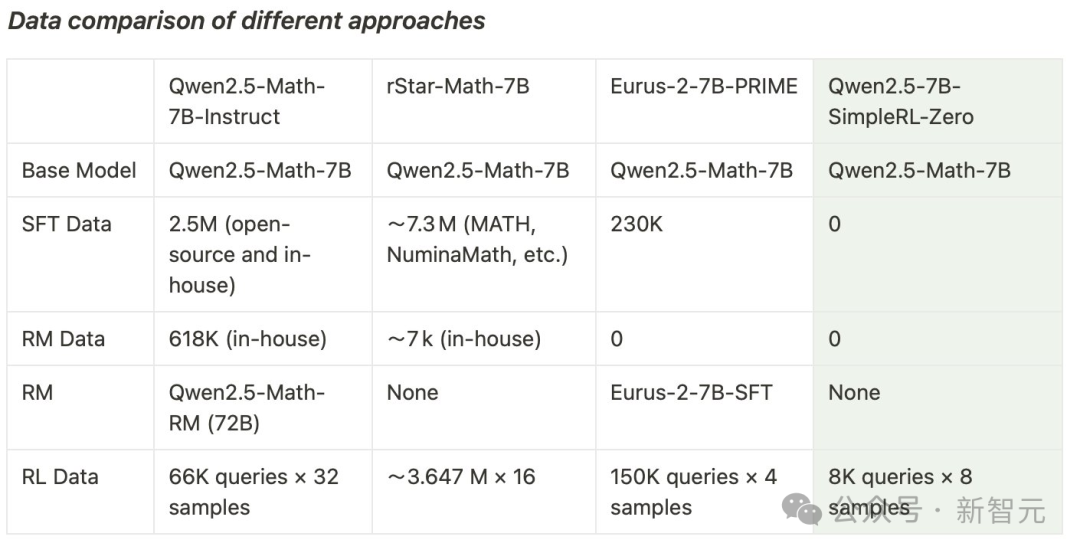
其中,Qwen2.5-7B-SimpleRL-Zero是在Qwen2.5-Math-7B基础模型上仅使用纯PPO方法训练的,仅采用了MATH数据集中的8K样本。
Qwen2.5-7B-SimpleRL则首先通过Long CoT监督微调(SFT)作为冷启动,然后再进行强化学习。
在这两种方法中,团队都只使用了相同的8K MATH样本,仅此而已。
大概在第44步的时候,「啊哈时刻」出现了!模型的响应中,出现了自我反思。

并且,在这个过程中,模型还显现了更长的CoT推理能力和自我反思能力。
在博客中,研究者详细剖析了实验设置,以及在这个强化学习训练过程中所观察到的现象,例如长链式思考(CoT)和自我反思机制的自发形成。
与DeepSeek R1类似,研究者的强化学习方案极其简单,没有使用奖励模型或MCTS(蒙特卡洛树搜索)类技术。
他们使用的是PPO算法,并采用基于规则的奖励函数,根据生成输出的格式和正确性分配奖励:
如果输出以指定格式提供最终答案且正确,获得+1的奖励
如果输出提供最终答案但不正确,奖励设为-0.5
如果输出未能提供最终答案,奖励设为-1
该实现基于OpenRLHF。初步试验表明,这个奖励函数有助于策略模型快速收敛,产生符合期望格式的输出。
第一部分:SimpleRL-Zero(从头开始的强化学习)
接下来,研究者为我们分享了训练过程动态分析和一些有趣的涌现模式。
训练过程动态分析
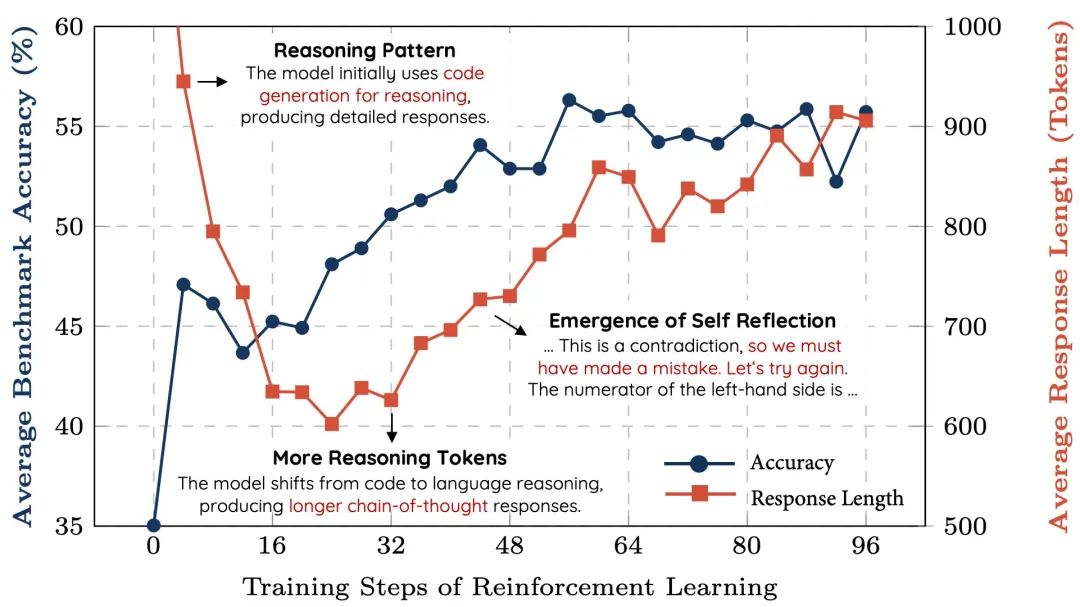
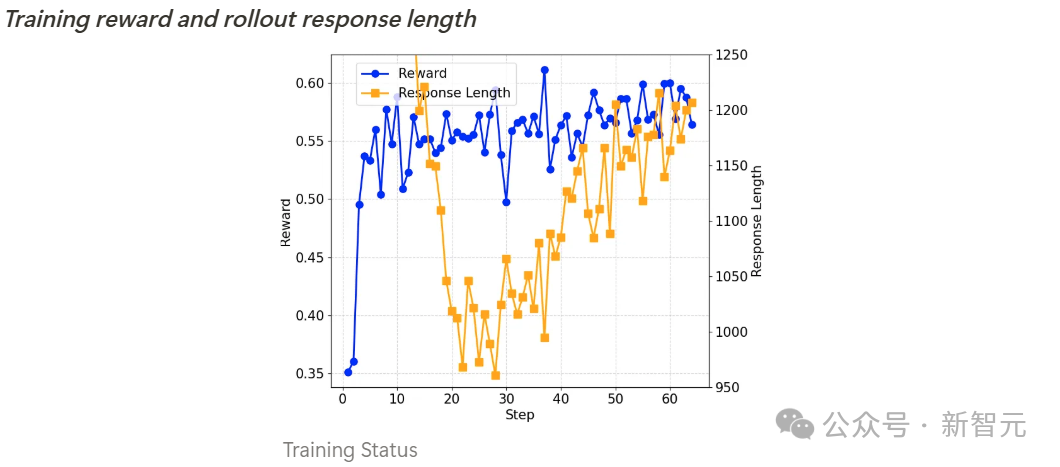
如下所示,所有基准测试的准确率在训练过程中都在稳步提高,而输出长度则呈现先减少后逐渐增加的趋势。
经过进一步调查,研究者发现,Qwen2.5-Math-7B基础模型在初始阶段倾向于生成大量代码,这可能源于模型原始训练数据的分布特征。
输出长度的首次下降,是因为强化学习训练逐渐消除了这种代码生成模式,转而学会使用自然语言进行推理。
随后,生成长度开始再次增加,此时出现了自我反思机制。
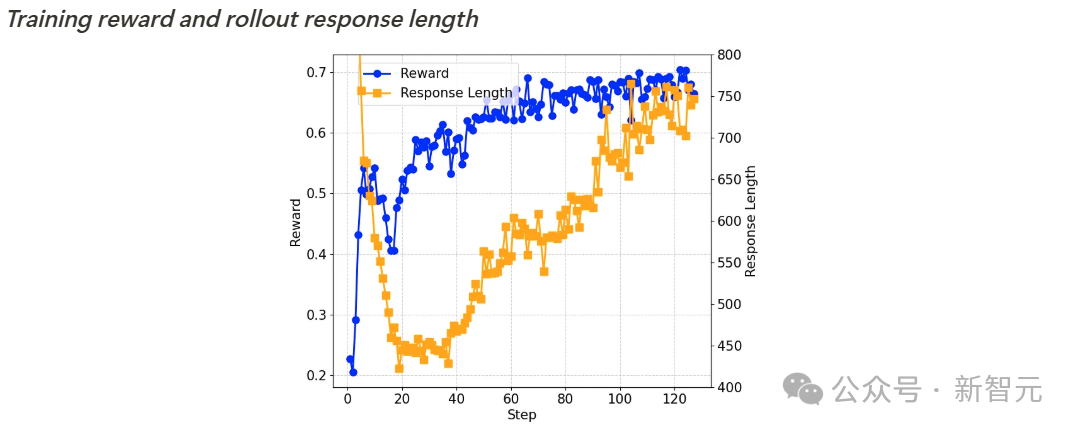
训练奖励和输出长度
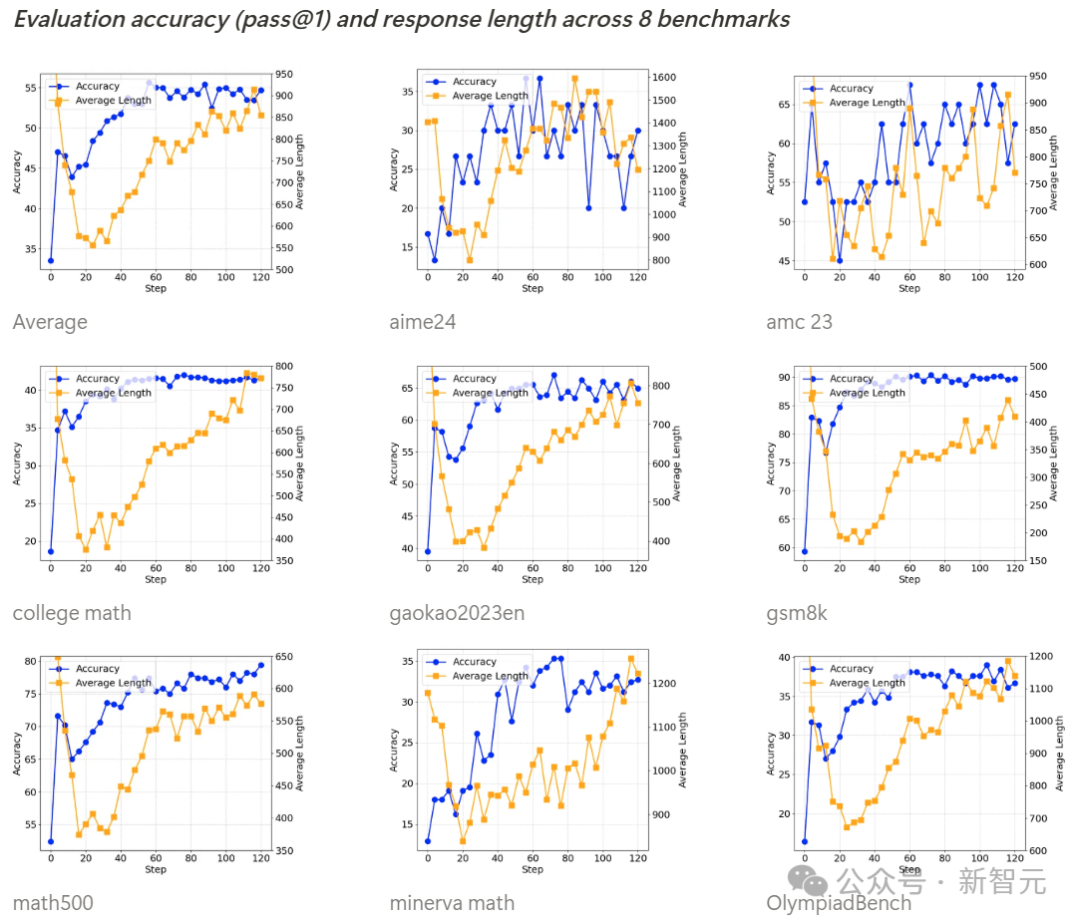
基准测试准确率(pass@1)和输出长度
自我反思机制的涌现
在训练到第 40 步左右时,研究者观察到:模型开始形成自我反思模式,这正是DeepSeek-R1论文中所描述的「aha moment」(顿悟时刻)。

第二部分:SimpleRL(基于模仿预热的强化学习)
如前所述,研究者在进行强化学习之前,先进行了long CoT SFT预热,使用了8,000个从QwQ-32B-Preview中提取的MATH示例响应作为SFT数据集。
这种冷启动的潜在优势在于:模型在开始强化学习时已具备long CoT思维模式和自我反思能力,从而可能在强化学习阶段实现更快更好的学习效果。
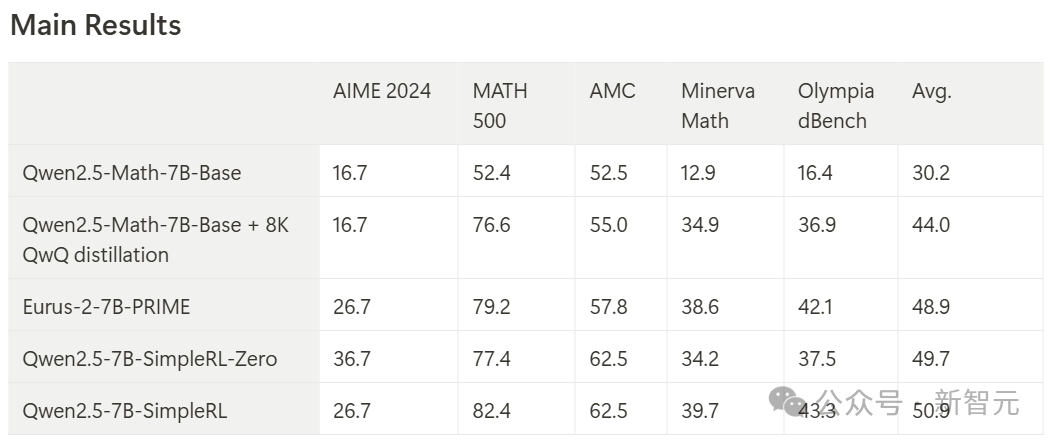
与RL训练前的模型(Qwen2.5-Math-7B-Base + 8K QwQ知识蒸馏版本)相比,Qwen2.5-7B-SimpleRL的平均性能显著提升了6.9个百分点。
此外,Qwen2.5-7B-SimpleRL不仅持续优于Eurus-2-7B-PRIME,还在5个基准测试中的3个上超越了Qwen2.5-7B-SimpleRL-Zero。
训练过程分析
训练奖励和输出长度
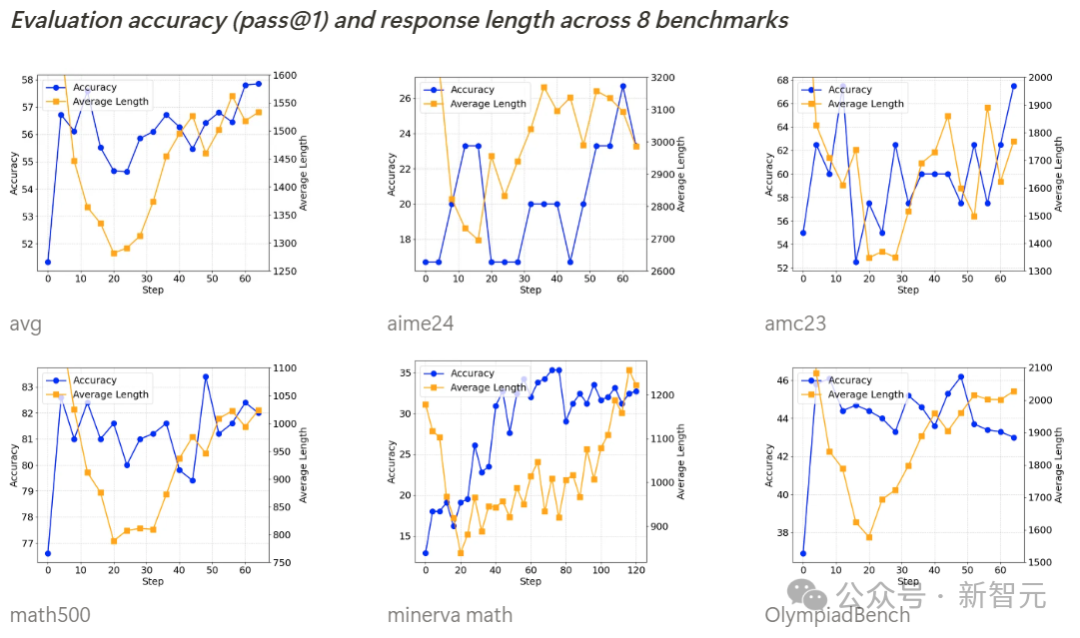
基准测试准确率(pass@1)和输出长度
Qwen2.5-SimpleRL的训练动态表现与Qwen2.5-SimpleRL-Zero相似。
有趣的是,尽管研究者先进行了long CoT SFT,但在强化学习初期仍然观察到输出长度减少的现象。
他们推测,这可能是因为从QwQ提取的推理模式不适合小型策略模型,或超出了其能力范围。
因此,模型选择放弃这种模式,转而自主发展新的长链式推理方式。
最后,研究者用达芬奇的一句话,对这项研究做了总结——
简约,便是最终极的精致。
从斯坦福到MIT,R1成为首选
一个副业项目,让全世界科技大厂为之惶恐。
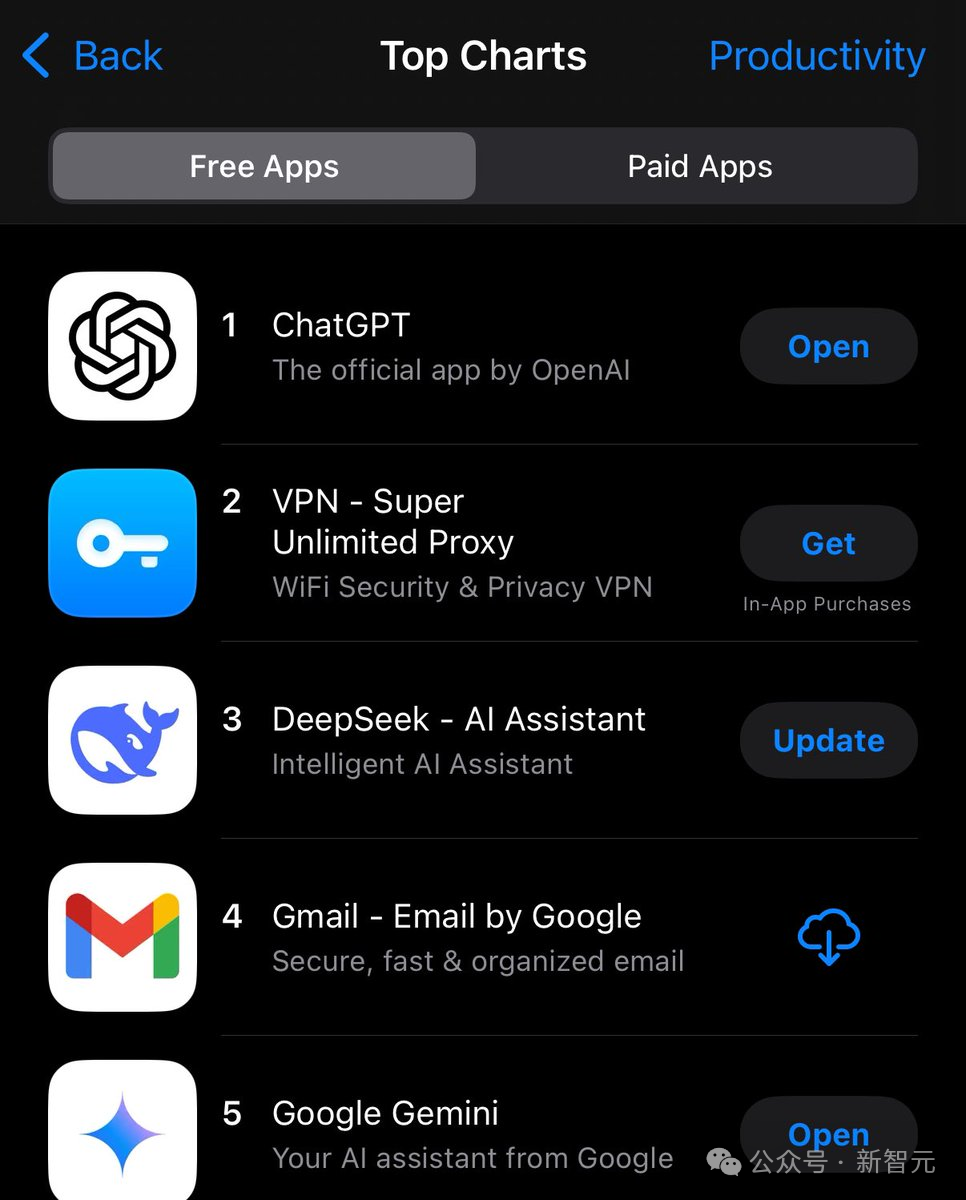
DeepSeek这波成功,也成为业界的神话,网友最新截图显示,这款应用已经在APP Store「效率」应用榜单中挤进前三。
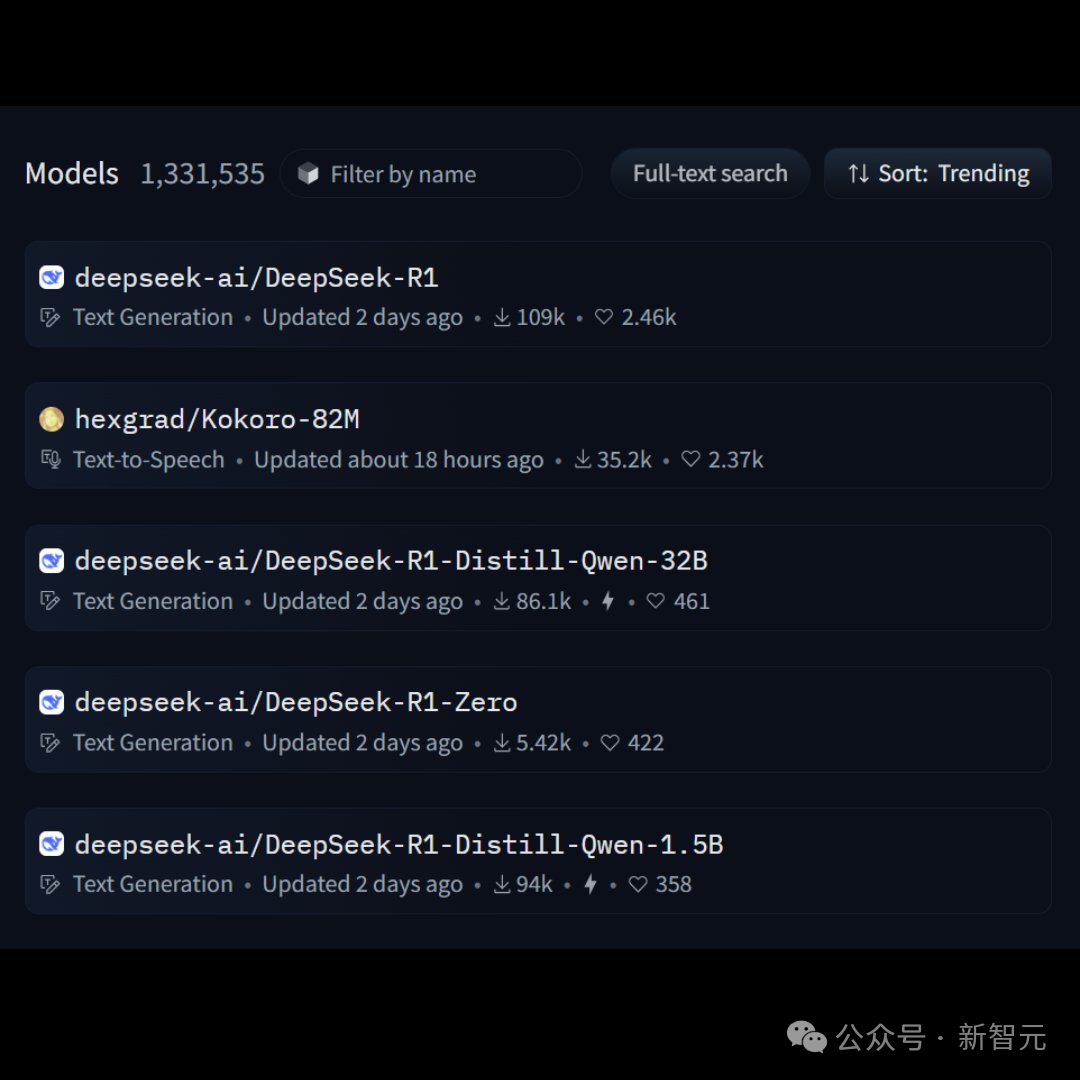
在Hugging Face中,R1下载量直接登顶,另外3个模型也霸占着热榜。
a16z合伙人Anjney Midha称,一夜之间,从斯坦福到MIT,DeepSeek R1已经成为美国顶尖高校研究人员「首选模型」。

还有研究人员表示,DeepSeek基本上取代了我用ChatGPT的需求。

中国AI,这一次真的震撼了世界。
参考资料:
https://x.com/junxian_he/status/1883183099787571519
https://x.com/jiayi_pirate/status/1882839370505621655
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









