






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文小白将和大家一起学习如何在不使用计算量很大的滑动窗口的情况下对任意尺寸的图像进行图像分类。通过修改,将ResNet-18CNN框架需要224×224尺寸的图像输入改为任意尺寸的图像输入。
首先,我们澄清一个对卷积神经网络(CNN)的误解。
卷积神经网络不需要固定大小的输入
如果用过CNN对图像进行分类,我们需要对输入图像进行裁剪或调整大小使其满足CNN网络所需的输入大小。虽然这种做法非常普遍,但是使用此方法存在一些局限。
1. 分辨率下降:如果在一幅大图中有一只小狗但其只占据图像中的一小部分,则调整图像的大小会使照片中的狗变得更小,以致无法正确分类图像。
2. 非正方形长宽比:通常,图像分类网络是在正方形图像上训练的。如果输入图像不是正方形,一般来说我们会从中心取出正方形区域,或者使用不同的比例调整宽度和高度以使图像变为正方形。第一种情况下,我们可能把不在中心的重要特征忽略了。而在第二种情况下,图像信息会因缩放比例不均匀而失真。
3. 计算量大:为了解决该问题,我们可以重叠裁剪图像,并在每个窗口上执行图像分类。这样计算量很大,而且完全没有必要。
有趣的是,许多人没有意识到如果我们对网络进行较小的修改,CNN便可以接受任何大小的图像作为输入,而且不需要再次训练!本文我们将通过修改一个标准网络的示例来向各位小伙伴介绍如何实现输入任意大小的图像。
修改图像分类体系结构以处理任意大小的图
几乎所有分类结构的末尾都有一个全连接层(FC)。(注意:FC层在PyTorch中称为“线性”层)FC层的问题在于它们需要输入固定尺寸的数据。如果我们更改输入图像的大小,就无法进行计算。因此,我们需要用其他东西替换FC层,但是在此之前,我们需要了解为什么在图像分类体系结构中需要使用全连接层。
现代的CNN架构由几个卷积层块和最后的几个FC层组成。这种结构可以追溯到神经网络的早期研究。卷积层作为“智能”过滤器从图像中提取语义信息,它们在某种程度上保留了图像对象之间的空间关系。但是,为了对图像中的对象进行分类,我们并不需要此空间信息,因此通常将最后一个卷积层的输出展平为一个长向量。该长向量是FC层的输入,它不考虑空间信息。FC层仅对图像中所有空间位置的深层特征进行加权求和。
实际上这种结构的效果很好,并且通过了大量实践的证明。但是,由于存在FC层,因此网络只能接受固定大小的输入。因此,我们需要将FC层替换为不需要固定大小输入的一种网络层。这就是不限于其输入尺寸的卷积层!
接下来我们要做的就是使用等效的卷积层去替代FC层。
全连接层到卷积层的转换
FC和卷积层在目标输入上有所不同–卷积层侧重于局部输入区域,而FC层则将全局特征组合在一起。但是,FC层和卷积层都计算点积,因此在本质上是相似的。所以满足两者之间互相转换的条件。
我们通过一个例子来解释这一点。
假设有一个FC层以卷积层的输出作为输入,卷积层输出5x5x16张量。我们还假设FC层的输出大小为120。如果使用FC层,则首先将5x5x16的体积展平为FC层的400×1(即5x5x16)矢量。但是,我们使用等效的卷积层,需要使用大小为5x5x16的核。在CNN中,核的深度(在这种情况下为16)总是与输入的深度相同,通常宽度和高度是相同的(在这种情况下为5)。因此,我们可以简单地说内核大小为5,而不是5x5x16。滤波器的数量需要与我们想要的输出相同,因此设置为120。同时,步幅设置为1,填充为0。
修改ResNet-18架构
ResNet-18是一种流行的CNN架构,该网络的需要输入大小为224×224的图像。但是我们将对其进行修改以接受任意大小的输入。
下图是框架的组成
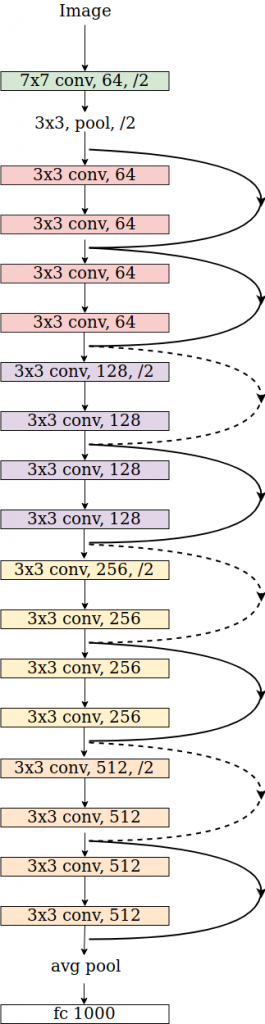
在PyTorch中,Resnet-18体系结构从卷积层开始,称为conv1(请参见下面的代码)。然后是池化层。
接下来依次是4个卷积块,图中使用了粉红色,紫色,黄色和橙色。这些模块被命名为layer1,layer2,layer3,和layer4。每个模块包含4个卷积层。
最后,我们有一个平均池化层。该层的输出被展平并送到最终完全连接层FC。
下面代码是Resnet框架的实现。
# from the torchvision's implementation of ResNet
class ResNet:
# ...
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate = replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate = replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate = replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# ...
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x我们将通过继承原始的ResNet类来创建一个新类FullyConvolutionalResnet18,具体代码如下:
class FullyConvolutionalResnet18(models.ResNet):
def __init__(self, num_classes=1000, pretrained=False, **kwargs):
# Start with standard resnet18 defined here
super().__init__(block = models.resnet.BasicBlock, layers = [2, 2, 2, 2], num_classes = num_classes, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url( models.resnet.model_urls["resnet18"], progress=True)
self.load_state_dict(state_dict)
# Replace AdaptiveAvgPool2d with standard AvgPool2d
self.avgpool = nn.AvgPool2d((7, 7))
# Convert the original fc layer to a convolutional layer.
self.last_conv = torch.nn.Conv2d( in_channels = self.fc.in_features, out_channels = num_classes, kernel_size = 1)
self.last_conv.weight.data.copy_( self.fc.weight.data.view ( *self.fc.weight.data.shape, 1, 1))
self.last_conv.bias.data.copy_ (self.fc.bias.data)
# Reimplementing forward pass.
def _forward_impl(self, x):
# Standard forward for resnet18
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
# Notice, there is no forward pass
# through the original fully connected layer.
# Instead, we forward pass through the last conv layer
x = self.last_conv(x)
return x使用完全卷积ResNet-18
通过我们的定义,我们已经拥有了能够对任意尺寸图像进行处理的ResNet-18,加下来将要介绍如何使用我们新定义的ResNet-18。
#1. 导入标准库
import torch
import torch.nn as nn
from torchvision import models
from torch.hub import load_state_dict_from_url
from PIL import Image
import cv2
import numpy as np
from matplotlib import pyplot as plt
#2. 读取ImageNet类ID到名称的映射
if __name__ == "__main__":
# Read ImageNet class id to name mapping
with open('imagenet_classes.txt') as f:
labels = [line.strip() for line in f.readlines()]读取图像并将其转换为可以与PyTorch一起使用。

输入图像:请注意,骆驼不在图像上居中
# Read image
original_image = cv2.imread('camel.jpg')
# Convert original image to RGB format
image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
# Transform input image
# 1. Convert to Tensor
# 2. Subtract mean
# 3. Divide by standard deviation
transform = transforms.Compose([
transforms.ToTensor(), #Convert image to tensor.
transforms.Normalize(
mean=[0.485, 0.456, 0.406], # Subtract mean
std=[0.229, 0.224, 0.225] # Divide by standard deviation
)])
image = transform(image)
image = image.unsqueeze(0)使用预先训练的参数加载FullyConvolutionalResNet18模型。
# Load modified resnet18 model with pretrained ImageNet weights
model = FullyConvolutionalResnet18(pretrained=True).eval()进行网络计算,得到结果
with torch.no_grad():
# Perform inference.
# Instead of a 1x1000 vector, we will get a
# 1x1000xnxm output ( i.e. a probabibility map
# of size n x m for each 1000 class,
# where n and m depend on the size of the image.)
preds = model(image)
preds = torch.softmax(preds, dim=1)
print('Response map shape : ', preds.shape)
# Find the class with the maximum score in the n x m output map
pred, class_idx = torch.max(preds, dim=1)
print(class_idx)
row_max, row_idx = torch.max(pred, dim=1)
col_max, col_idx = torch.max(row_max, dim=1)
predicted_class = class_idx[0, row_idx[0, col_idx], col_idx]
# Print top predicted class
print('Predicted Class : ', labels[predicted_class], predicted_class)运行上面代码时,我们会得到以下输出。
Response map shape : torch.Size([1, 1000, 3, 8])
tensor([[[977, 977, 977, 977, 977, 978, 354, 437],
[978, 977, 980, 977, 858, 970, 354, 461],
[977, 978, 977, 977, 977, 977, 354, 354]]])
Predicted Class : Arabian camel, dromedary, Camelus dromedarius tensor([354])在原始的ResNet中,输出是1000个元素的向量,其中向量的每个元素对应于ImageNet的1000个类的类概率。
在FC的版本中,我们得到一个大小为[1,1000,n,m]的响应图,其中n和m取决于原始图像的大小和网络本身。
在我们的示例中,当我们输入大小为1920×725的图像时,我们会收到大小为[1,1000,3,8]的响应图。
预测类的响应图
接下来,我们找到预测类的响应图,并对其进行上采样以适合原始图像。我们对响应图进行阈值处理以获得感兴趣的区域并在其周围找到一个边界框。具体代码如下所示:
# Find the n x m score map for the predicted class
score_map = preds[0, predicted_class, :, :].cpu().numpy()
score_map = score_map[0]
# Resize score map to the original image size
score_map = cv2.resize(score_map, (original_image.shape[1], original_image.shape[0]))
# Binarize score map
_, score_map_for_contours = cv2.threshold(score_map, 0.25, 1, type=cv2.THRESH_BINARY)
score_map_for_contours = score_map_for_contours.astype(np.uint8).copy()
# Find the countour of the binary blob
contours, _ = cv2.findContours(score_map_for_contours, mode=cv2.RETR_EXTERNAL, method=cv2.CHAIN_APPROX_SIMPLE)
# Find bounding box around the object.
rect = cv2.boundingRect(contours[0])显示结果
以下代码用于以图像形式显示结果。响应图中越亮的区域表示高可能性区域。
# Apply score map as a mask to original image
score_map = score_map - np.min(score_map[:])
score_map = score_map / np.max(score_map[:])
接下来,我们将响应图与原始图像相乘并显示边界框。
score_map = cv2.cvtColor(score_map, cv2.COLOR_GRAY2BGR)
masked_image = (original_image * score_map).astype(np.uint8)
# Display bounding box
cv2.rectangle(masked_image, rect[:2], (rect[0] + rect[2], rect[1] + rect[3]), (0, 0, 255), 2)
# Display images
cv2.imshow("Original Image", original_image)
cv2.imshow("scaled_score_map", score_map)
cv2.imshow("activations_and_bbox", masked_image)
cv2.waitKey(0)结果如下所示。我们看到只有骆驼被突出显示。通过对响应图设定阈值而创建的边界框将捕获骆驼。从这个意义上说,全卷积图像分类器的作用就像对象检测器!

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









