









Elastic-Job java-api方式实现
为什么要用定时任务?
1.数据备份每天凌晨 每天凌晨2点,因为凌晨的时候系统不是繁忙,不使用定时任务,就是用人工操作
2.心跳的监控,每隔10分钟去监听接口,是否正常,没有定时任务需要人工去查一下
3.每隔5分钟去淘宝京东抓取订单,有些卖家在不同的平台上架,总不能商家去每隔平台定时自己拉取一下吧
4.订单的支付,由于用户30分钟没有付款,自动取消该订单 是企业应用系统中必要的,是必须要的 解决掉了,大量的人力和物力 ,SpringTask 支持单点 ,不支持集群 Quartz 支持集群 但是不支持分布式不能将一个任务进行拆解 ,可以动态添加
优点:
Elastic-job 分布式集群 支持分布式 缺点不可以动态添加,将一个任务,拆分成多个独立的任务项目,由分布式的服务器分别执行某一个,或多个分片项 一个大量的任务 会进行拆解成多份进行处理 多个服务,一一承担
它有几种服务模式?
他有三种:大家在这里先记住这三种模式即可,后面我会为大家一一讲解
1. Simple(简单) 简单模式
2. DataFlow(流) 流模式
3. Script (脚本) 脚本模式
什么是分布式调度?
分布式处理请求中的一部分调度,就是不同的请求过来,分给不同的服务进行助理,我有服务1和服务2,就是这两个服务同时提供服务
什么是分片?
一个任务,拆分成多个独立的任务项,每个服务获得一个或多个分片项 例如两台服务器,每台服务器执行50%
,基数偶数拆分,如果听不懂的话,看如下图
有两个服务,分片分两片,一个服务执行一片,就相当于把一个任务拆分成两份,查询到100条数据,也就是拆分成两份,一个人处理50个数据
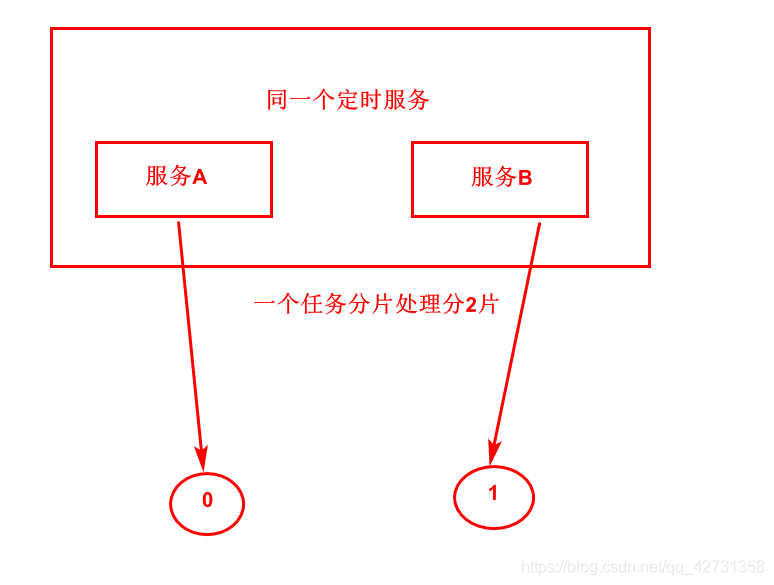
如果分10片会怎么样拆分?
如下图:
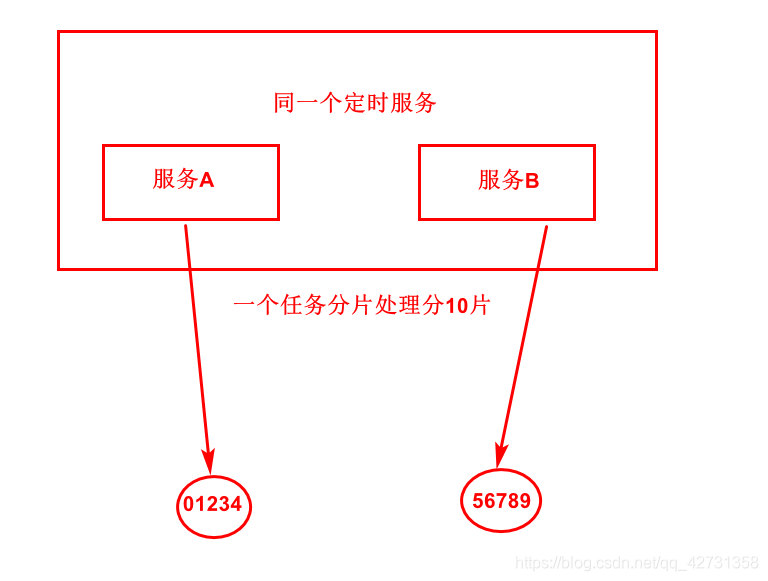
如果分9片会怎么样那?
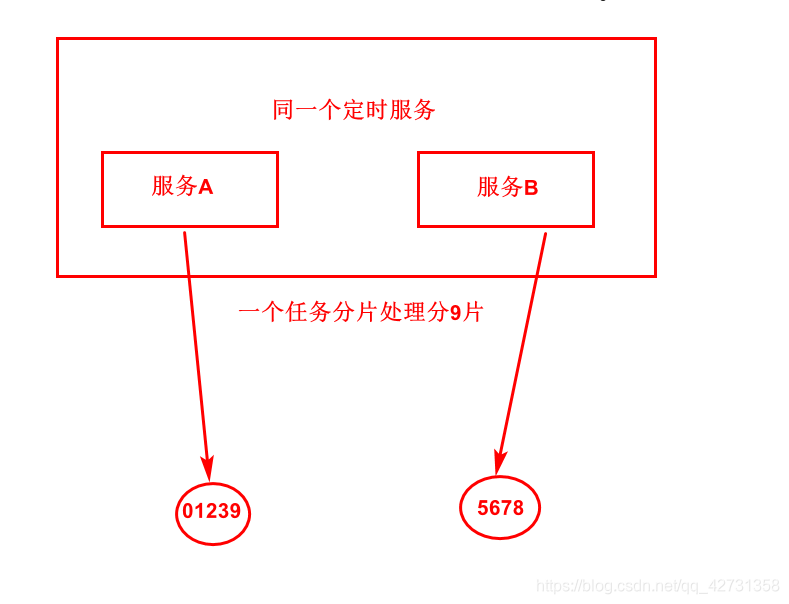
看图可理解到他的分片机制,是如何分片的,还有一个如果分一片,两个服务会怎么样那?
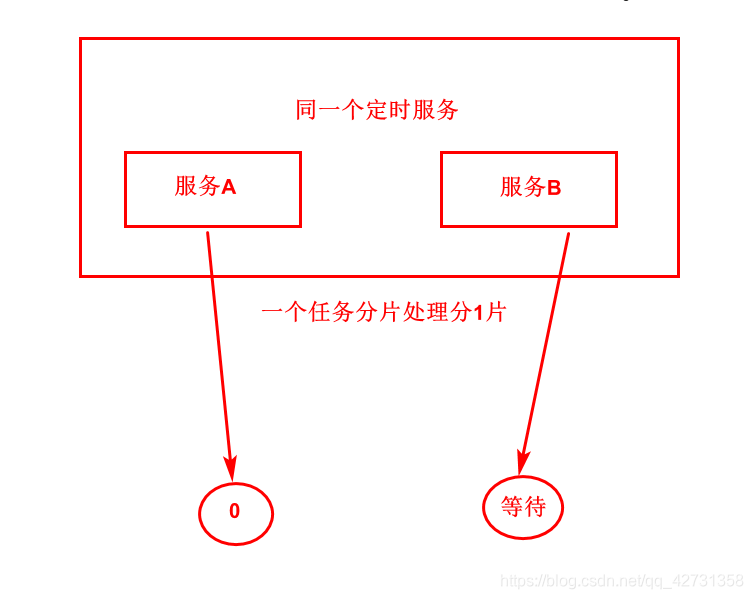
由上图得出,两个相同的服务,执行一个任务的时候分一片处理,另一个则会进行等待,等待服务A宕机,他会失效转移,将A服务没有执行完,或者A服务该执行的,他会代替A服务去执行,这样就可以实现高可用
Elastic-job 不直接提供数据处理 ,只提供分片,开发者自行处理
作业高可用:
部署多台定时任务,分片总数设置为1,多于1台服务器执行作业,1主n从,执行服务器崩溃后,等待的服务器将启动,执行下次任务,1分片 多个服务 abc a能拿到 bc等待 a挂机 bc继续去执行,失效转移 复活之后 恢复到原来的
前提依赖于zookeeper,大家可以在网上找一下安装zookeeper的帖子,自行安装
引入maven依赖:
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>2.1.5</version>
</dependency>
Simple模式:
Simple类型作业意为简单实现,未经任何封装的类型。需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行。与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能。
JAVA-API方式使用 简单模式:称之为简单模式,也就是和普通定时任务一样的,根据分片处理业务
/**
* 任务类
*/
public class MySimpleJob implements SimpleJob {
/**
* 分片上下文
* @param shardingContext
*/
@Override
public void execute(ShardingContext shardingContext) {
LocalDateTime localDateTime=LocalDateTime.now();
System.out.println(localDateTime+"我是分片项:"+shardingContext.getShardingItem()+
"===>定时分片总数:"+shardingContext.getShardingTotalCount());
switch (shardingContext.getShardingItem()) {
case 0:
System.out.println("京东订单抓取");
break;
case 1:
System.out.println("淘宝订单抓取");
break;
}
}
}
/**
* 注册中心
* @return
*/
public static CoordinatorRegistryCenter zkCenter(){
ZookeeperConfiguration zookeeperRegistryCenter=
new ZookeeperConfiguration("39.102.123.141:2181,39.102.123.141:2182,39.102.123.141:2183",
"elastic-simple-job");
CoordinatorRegistryCenter coordinatorRegistryCenter=
new ZookeeperRegistryCenter(zookeeperRegistryCenter);
coordinatorRegistryCenter.init();
return coordinatorRegistryCenter;
}
/**
* Job核心配置类
* @return
*/
public static LiteJobConfiguration simpleConfiguration(){
//核心配置
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration
.newBuilder("my-simple-job",
"0/10 * * * * ?",
2).build();
//核心类型配置
JobTypeConfiguration jobTypeConfiguration=
new SimpleJobConfiguration(
jobCoreConfiguration,
MySimpleJob.class.getCanonicalName());
LiteJobConfiguration liteJobConfiguration=LiteJobConfiguration.newBuilder(jobTypeConfiguration)
.overwrite(true)
.build();
return liteJobConfiguration;
}
运行:
System.out.println("=======>START Job<=======");
new JobScheduler(zkCenter(), simpleConfiguration()).init();
System.out.println("=======>STOP Job<=======");
结果:
2020-12-29T14:14:56.166我是分片项:1===>定时分片总数:2
淘宝订单抓取
2020-12-29T14:14:56.166我是分片项:0===>定时分片总数:2
京东订单抓取
2020-12-29T14:15:05.658我是分片项:0===>定时分片总数:2
京东订单抓取
2020-12-29T14:15:05.659我是分片项:1===>定时分片总数:2
淘宝订单抓取
两个服务的话,是拆开的
运行结果如下
服务A执行0 服务B执行1
DataFlow模式:
DataFlow流模式,为什么称之为流模式,例如我要去根据我的订单有100个,一次只能抓取10个,两个分片,那么请看下图:
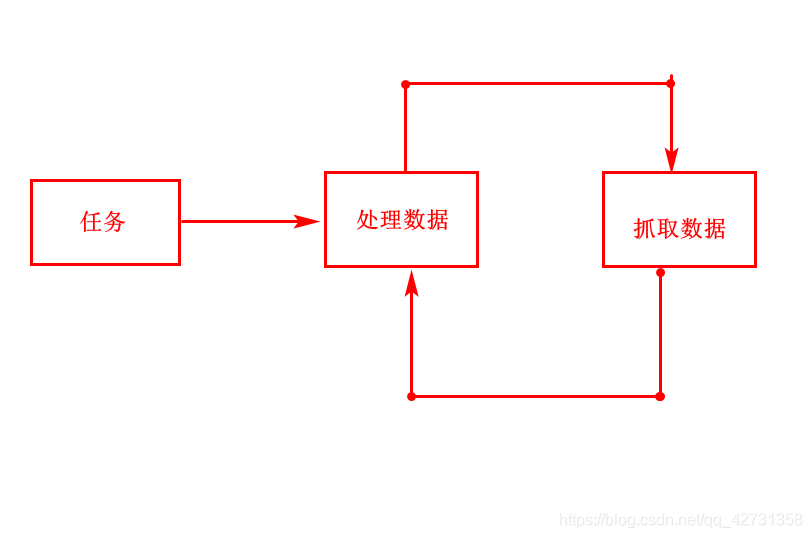
上图一个负责抓取数据,一个负责处理数据,一次抓取10条,这样反复循环,直到抓取完毕,等下次定时任务启动在这样反复处理数据
代码:
public class MyDataFlowJob implements DataflowJob<Order> {
List<Order> list=new ArrayList<>();
{
for (int i = 0; i < 100; i++) {
Order order=new Order();
order.setOrderId(i);
order.setStatus("0");
list.add(order);
}
}
/**
* 抓取数据
* @param shardingContext
* @return
*/
@Override
public List<Order> fetchData(ShardingContext shardingContext) {
List<Order> collect = list.stream().filter(o -> o.getStatus() .equals("0") )
.filter(id -> id.getOrderId() % shardingContext.getShardingTotalCount() == shardingContext.getShardingItem())
.collect(Collectors.toList());
List<Order> orders=null;
if(!collect.isEmpty()){
orders = collect.subList(0, 10);
}
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
LocalDateTime localDateTime=LocalDateTime.now();
System.out.println(localDateTime+" 我是分片项:"+shardingContext.getShardingItem()
+" ====>定时分片总数"+shardingContext.getShardingTotalCount()
+" 我抓取的数据是:"+orders);
return orders;
}
/**
* 处理数据
* @param shardingContext
* @param data
*/
@Override
public void processData(ShardingContext shardingContext, List<Order> data) {
//更改订单状态
data.forEach(s->s.setStatus("1"));
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
LocalDateTime localDateTime=LocalDateTime.now();
System.out.println(localDateTime+
" 我是分片项:"+shardingContext.getShardingItem()
+" 我正在处理数据!!"
);
}
}
注册中心
/**
* 注册中心
* @return
*/
public static CoordinatorRegistryCenter zkCenter(){
ZookeeperConfiguration zookeeperRegistryCenter=
new ZookeeperConfiguration("39.102.123.148:2181,39.102.123.148:2182,39.102.123.148:2183",
"elastic-simple-job");
CoordinatorRegistryCenter coordinatorRegistryCenter=
new ZookeeperRegistryCenter(zookeeperRegistryCenter);
coordinatorRegistryCenter.init();
return coordinatorRegistryCenter;
}
DataFlow的配置
/**
* Job核心配置类
* @return
*/
public static LiteJobConfiguration dataFlowConfiguration(){
//核心配置
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration
.newBuilder("my-dataFlow",
"0/5 * * * * ?",
2).build();
//核心类型配置
JobTypeConfiguration jobTypeConfiguration=
new DataflowJobConfiguration(
jobCoreConfiguration,
MyDataFlowJob.class.getCanonicalName(),true);
LiteJobConfiguration liteJobConfiguration=LiteJobConfiguration.newBuilder(jobTypeConfiguration)
.overwrite(true)
.build();
return liteJobConfiguration;
}
public class ApplicationElasticJob {
public static void main(String[] args) {
System.out.println("=======>START Job<=======");
new JobScheduler(zkCenter(), dataFlowConfiguration()).init();
System.out.println("=======>STOP Job<=======");
}
运行结果服务A
2020-12-29T15:06:34.778 我是分片项:1 ====>定时分片总数2 我抓取的数据是:[Order{orderId=1, status='0'}, Order{orderId=3, status='0'}, Order{orderId=5, status='0'}, Order{orderId=7, status='0'}, Order{orderId=9, status='0'}, Order{orderId=11, status='0'}, Order{orderId=13, status='0'}, Order{orderId=15, status='0'}, Order{orderId=17, status='0'}, Order{orderId=19, status='0'}]
2020-12-29T15:06:37.779 我是分片项:1 我正在处理数据!!
2020-12-29T15:06:40.791 我是分片项:1 ====>定时分片总数2 我抓取的数据是:[Order{orderId=21, status='0'}, Order{orderId=23, status='0'}, Order{orderId=25, status='0'}, Order{orderId=27, status='0'}, Order{orderId=29, status='0'}, Order{orderId=31, status='0'}, Order{orderId=33, status='0'}, Order{orderId=35, status='0'}, Order{orderId=37, status='0'}, Order{orderId=39, status='0'}]
2020-12-29T15:06:43.791 我是分片项:1 我正在处理数据!!
2020-12-29T15:06:46.881 我是分片项:1 ====>定时分片总数2 我抓取的数据是:[Order{orderId=41, status='0'}, Order{orderId=43, status='0'}, Order{orderId=45, status='0'}, Order{orderId=47, status='0'}, Order{orderId=49, status='0'}, Order{orderId=51, status='0'}, Order{orderId=53, status='0'}, Order{orderId=55, status='0'}, Order{orderId=57, status='0'}, Order{orderId=59, status='0'}]
2020-12-29T15:06:49.882 我是分片项:1 我正在处理数据!!
2020-12-29T15:07:13.438 我是分片项:1 ====>定时分片总数2 我抓取的数据是:[Order{orderId=61, status='0'}, Order{orderId=63, status='0'}, Order{orderId=65, status='0'}, Order{orderId=67, status='0'}, Order{orderId=69, status='0'}, Order{orderId=71, status='0'}, Order{orderId=73, status='0'}, Order{orderId=75, status='0'}, Order{orderId=77, status='0'}, Order{orderId=79, status='0'}]
2020-12-29T15:07:16.439 我是分片项:1 我正在处理数据!!
服务B
2020-12-29T15:06:33.566 我是分片项:0 ====>定时分片总数2 我抓取的数据是:[Order{orderId=0, status='0'}, Order{orderId=2, status='0'}, Order{orderId=4, status='0'}, Order{orderId=6, status='0'}, Order{orderId=8, status='0'}, Order{orderId=10, status='0'}, Order{orderId=12, status='0'}, Order{orderId=14, status='0'}, Order{orderId=16, status='0'}, Order{orderId=18, status='0'}]
2020-12-29T15:06:36.570 我是分片项:0 我正在处理数据!!
2020-12-29T15:06:39.736 我是分片项:0 ====>定时分片总数2 我抓取的数据是:[Order{orderId=20, status='0'}, Order{orderId=22, status='0'}, Order{orderId=24, status='0'}, Order{orderId=26, status='0'}, Order{orderId=28, status='0'}, Order{orderId=30, status='0'}, Order{orderId=32, status='0'}, Order{orderId=34, status='0'}, Order{orderId=36, status='0'}, Order{orderId=38, status='0'}]
2020-12-29T15:06:42.736 我是分片项:0 我正在处理数据!!
2020-12-29T15:06:46.787 我是分片项:0 ====>定时分片总数2 我抓取的数据是:[Order{orderId=40, status='0'}, Order{orderId=42, status='0'}, Order{orderId=44, status='0'}, Order{orderId=46, status='0'}, Order{orderId=48, status='0'}, Order{orderId=50, status='0'}, Order{orderId=52, status='0'}, Order{orderId=54, status='0'}, Order{orderId=56, status='0'}, Order{orderId=58, status='0'}]
2020-12-29T15:06:49.787 我是分片项:0 我正在处理数据!!
Scirpt模式
也就是运维定时执行脚本命令的时候
/**
* Job核心配置类
* @return
*/
public static LiteJobConfiguration scriptConfiguration(){
//核心配置
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration
.newBuilder("my-script",
"0/5 * * * * ?",
2).build();
//核心类型配置
JobTypeConfiguration jobTypeConfiguration=new ScriptJobConfiguration(jobCoreConfiguration, "C:\\Users\\capitek\\Desktop\\test.cmd");
LiteJobConfiguration liteJobConfiguration=LiteJobConfiguration.newBuilder(jobTypeConfiguration)
//.overwrite(true)
.build();
return liteJobConfiguration;
}
运行
new JobScheduler(zkCenter(), scriptConfiguration()).init();
运行脚本定时执行
脚本内容
echo 我是CMD脚本,我的作业信息是: %1,%2,%3,%4,%5,%6
运行结果:
E:\code\Elastic-Job-Quartz>echo 我是CMD脚本,我的作业信息�? {"jobName":"my-script","taskId":"my-script@-@0,1@-@READY@-@192.168.100.1@-@14276","shardingTotalCount":2,"jobParameter":"","shardingItem":1},
我是CMD脚本,我的作业信息�? {"jobName":"my-script","taskId":"my-script@-@0,1@-@READY@-@192.168.100.1@-@14276","shardingTotalCount":2,"jobParameter":"","shardingItem":1},
E:\code\Elastic-Job-Quartz>echo 我是CMD脚本,我的作业信息�? {"jobName":"my-script","taskId":"my-script@-@0,1@-@READY@-@192.168.100.1@-@14276","shardingTotalCount":2,"jobParameter":"","shardingItem":0},
我是CMD脚本,我的作业信息�? {"jobName":"my-script","taskId":"my-script@-@0,1@-@READY@-@192.168.100.1@-@14276","shardingTotalCount":2,"jobParameter":"","shardingItem":0},
这就是JAVA-API启动方式 这三种后续整合Spring















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









