







前言:Redis原理介绍
首先我们想象一个场景,服务器里有一个文件,这个文件我想快速的查找出某个我想要的数据,Linux中有grep,awk等命令,我还可以用C,C++等各种语言,读取这个文件的IO流读取查找,这里会有一些什么问题?
提示:
一丶有一些大家都知道的常识,在计算机中,数据在磁盘的,磁盘的维度有两个指标,第一个是寻址,寻址的速度是毫秒级的,第二个是带宽,也就是单位时间可以有多少个字节流过去,多大的数据流过去,基本上是G或者M级别的,就是几百兆或者几个G的这样一个带宽速度,这是磁盘的基础知识。
二丶另外一个就是内存,内存有一个寻址,他的寻址纳秒级别,可想而知他的速度,一千分之一秒是毫秒,一千分之一毫秒是微秒,一千分之一微秒是纳秒。
如上一和二进行对比,磁盘和内存相比是很慢的,磁盘比内存慢了10万被,在寻址上慢了10倍,这样思考一下,只要是数据放在内存,一定是比磁盘快的!!!
IO Buffer
首先我们想读取文件,是不是需要IO流? Buffer存在一个成本问题,磁盘有磁道和扇区,每个扇区有多少字节?每次扇区有512个字节,如果我们想访问这个硬盘的硬件,这个硬盘的大小大概1个T,都是最小力度每个扇区进行查找,我的数据在那个扇区放着?这样的话我们查找,是不是成本变大,索引变大,1T里面很多512,那么操作系统中是不是需要索引,这个索引大小是不是我们就不确定多少字节了,他需要一个很大的数据区间,才能获取扇区,所哟成本越大,索引越大,我们的磁盘格式化的时候会有4k对齐,也就是真正用到硬件的时候,并不是按照扇区的读写量,他会变得大一些,如果自己读的话是512个字节,读取到1K就给硬盘了,硬盘都是默认4k格式化的,无论读多少都是最少4k从磁盘拿的,文件如果从几M到几个G查询的速度变慢了,如果访问的话硬盘是否收到影响?也就是IO读取的速度,换言而知,我们如果把这些数据放入数据库中是不是,查找速度变快了,如果咱们在数据库建一张表,里面有很多行,存到磁盘的时候,他其实在物理存的时候,用到了4K这个小格子概念,这个4K和咱们格式化的时候和我们的磁盘对的上,所以数据库准备很多这样的4K,也就是曾经数据是线性在一个文件里面,他的底层是4K,所以文件混在一起,4k连起开不能把他们分割,如果我在自己的软件里定义一个4k这4K的数据他都有不同的ID号,0号丶1号。。。。,我要查找4K里面的某个数据,正好符合我的磁盘IO,自己也可以变小,变小的话是不是变慢了?磁盘IO一次读取的是4k,我要查找数据的时候调用对某个位置,一下就可以拿出来了,如果我定义小了,对资源是一种浪费,为什么浪费如果定义1k但是底层也会按照4K走,定义大了无所谓,可以往大了调,因为IO读取会从第一个数据读取到内存,然后挨个去找,他走的还是全亮的IO,查找的时候和前面的复杂度,几乎一样.
MYSQL
我们如何让数据库变快?
数据库是怎么做的变快的哪,也就是建一张表,如果不加索引的话,还是和以前一样的,所以数据库里面出现了索引,索引其实就是4k这种存储的模型,无非就是4k的格子前面放了一行行的数据,然后这4k里面放着你的一列数据,比如说手机号一列,我就把这个手机号拿到前面4K的里面,每一个手机号,都有指向的关系,我们称之为索引。所以数据量变大的话,索引也会随之变多,数据是用4K,4K的去存,如果想查询很快的话,那就建一个索引系统。
就是我们建表的时候,数据一般用什么存储方式?必须给出,一张表有多少列,每一列他是什么类型,约束是什么,每一列的类型就是字节的宽度,比如说varchar(20),那么第一列一定会开辟出20个字节,只要是给出类型长度,这样表的每一行数据的宽度就定死了,例如说这个有10个字节,你只给出第一个和第七个,剩下没有的都会用0会开辟,用空的东西去补充哪些字节,首先我们要知道,存的时候更倾向于行级存储,以行为单位来存,咱们给了固定宽度,有一个好处,我们有10个字节,每个字都是4个字节的话就是40个,随便给了其中一个字段有值,那么剩下的30个我也会占空,把这行的未知占位,为了以后的增删改。
索引
有了索引之后,就是数据和索引其实都是存在硬盘中的,然后这个时候查的时候是要用到一个东西,就是在内存里面准备一个B+Tree,内存是计算机查找数据最快的地方,B+Tree所有的叶子就是小格子,B+Tree其实树干在内存里的,比如说区间和偏移,这个时候你想查询数据,在where条件里,只要命中索引了,那么就会走B+Tree的树干,最终找到某一个叶子,比如说这个手机号恰好在这个叶子的区间,那么把他从磁盘读取到内存,最笨的方法,遍历完之后,可以下一次我要查询,我就直到他在哪个叶子里了,最简单B+Tree,然后二叉树,中间例如是6左边是小于6的,右边是大于6的,如果你想查10,肯定会走右边这条路,肯定树干随着最小的方向去找,这样是不是就节省了很多时间,但是7-10都会挨个读取到内存,把这些索引存到内存的话,内存不够,存不下这些索引,所以可以这么干,那就是拆分,内存中就只存储一个树干,顺藤摸瓜,就只存一个区间,这样能快速定位,为什么拆分,磁盘能存储大量的数据,内存的速度快,他两个结合利用各自的优点,岂不是美滋滋,最终不是解决了IO流量,磁盘查询慢这样是不是减少寻址的过程,就类似于我们的村庄,我要找小明,我就得从第一家开始找,我不知道小明他家在哪里,这样挨家挨户去找,耗费资源,自己也累够呛,这时你需要村长,你问小明他家在哪里,村长比划一下,从某个大路树干,到哪里去,然后他家就在那里的附近,正好有邻居,你问邻居,邻居说,他是我们5队的,然后你就能找到这个小明家,我下次来是不是不用问了,我去过他家,快速定位。随着人口变多,表的数据量变大,查询速度索引等都会变低
在索引上执行增删改
首先增删改,如果表有索引,然后增删改变慢,因为你要修改数据的话,这个数据你建了多少索引都会找到索引列,所以你必须修改索引或者调整他的位置,就是维护索引会让你的增删改变慢。
查询速度
一丶加入我的表100g,硬盘就能装下100g,然后内存也刚刚把所有的树干存下,然后那都没有一处,哪里都没有问题,来一个人查询的时候,他的where 条件能够命中索引,那么这个时候,如果一个少量查询,依然会很快。就是查询进来后因为你的where条件走的还是B+tree,走的还是一个索引块,然而这个块依然走的是data page ,他并没有说,你的数据量编发,我未来会把别的data page 也到带到内存中
二丶为什么说查询速度什么时候变慢,也就是说并发,很多一块查询,很多查询都到达了,或者一个复杂的查询,这个时候是不是要获取data page 到内存,因为你的数据量变大,数据量越大,能够被很多查询的命中的几率,被不同命中的几率也会变大,所以这个时候影响带宽的速度,也就是说同时来1万个人查询,每个人查询查一个4k,每个人查询条件都不一样,刚好是又散在不同的4k上的,那么这一万个查询进入服务器后,一万个4k是挨个向我们内存走的,查一个走一个,那么这时候有一部分人在等待4k,等别人走完了,他才能查询到。
三丶假设B+Tree不受影响,因为硬盘不光寻址慢,还有一个带宽!!!
数据库,分库,分表,分治,分布式这里都不说了 因为讲的是redis
还有一点磁盘是没有指针的,内存中是可以指针操作的
为了查询速度快,是不是想到了缓存?
一、Redis是什么?
咱们先看看数据库的排名!
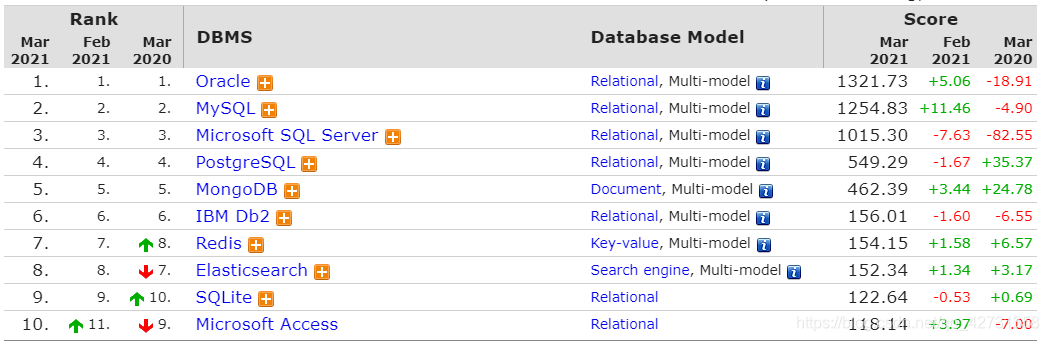
示例:第一名是谁?
Oracle,这是关系型数据库,第二名Mysql 几乎排行第一第二他两个,而我们看redis,他是key-value类型的,基于内存的,redis内置了复制,然后Lua脚本,LRU驱动事件,事务和不同级别的磁盘持久化,并通过redis哨兵自动分区提高可用性,他又集群groups,然后也有一种主从复制的东西。
二、Redis和Memcach对比
1.为什么说Redis比Memcach要好?
memcache是KV键值对的,Redis也是KV键值对的,memcache的value是没有类型概念的,redis有了类型概念,这是两个区别,这是为什么?例如我要存储数据 他是key value的是不是? value存json,他两个都可以存储,例如我我要是放个数组,如果我想取某个元素,memcache,我需要获取IO,读取,如果很大的数组那?我是不是一次性读取很多的数据,client连接读取,我是不是需要取出来for循环遍历找到他,如果我用redis,我不需要读取那么大的数据,只需要给出索引下标我就能拿到某个值,客户端也不需要写太多的代码,也不需要取走全量的数据!
2.安装
安装步骤如下:先去官网
wget https://download.redis.io/releases/redis-版本号.tar.gz
$ tar xzf redis-版本号.tar.gz
$ cd redis-版本号
$ make
src/redis-server
在执行make的时候他是要读取make file的,make file本身就是一个文本文件,一个编译脚本,这个文件的真身在src下,如果没有gcc的话 先安装gcc
yum install gcc
如果编译报错的话 先清理一下
make disclean
redis/src下面会有可执行文件但是自己感觉太low了? 是不是想让他变成一个服务?
make install PREFIX=路径
这是指定到哪里去,PREFIX会覆盖它的脚本文件里面的变量,告诉他安装到哪个目录,cd到你设置的目录 是不是发现bin目录里面有可执行的文件?
你是不是想让他变成一个服务?
server redis start 这种命令启动?
先去源码目录,去util目录下,会有一个redis server,安装server,那么执行install server就可以了,这个脚本原来就知道你的程序安装到哪个目录了,这个时候我们配置一下环境变量
vi /etc/profile
export REDIS_HOME=路径
在你的原来的环境变量下面加上 :$REDIS_HOME/bin
这样你就能直接使用Redis的服务了,在任何地方
redis是单线程的














 5115
5115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









