






静态网页的处理大致可以分为几个步骤
导入模块、发送请求、解析数据、处理数据
导入模块
这里我们需要导入request库和etree
前者用来获取请求,后者用来解析
import requests
from lxml import etree
发送请求
首先写你要爬取网站的url
url = "http://www.a-hospital.com/w/%E7%96%BE%E7%97%85"
然后写请求头
headers = {
'User-Agent': ''
}
请求头这里可以打开你的网站,F12打开“网络”,在其中随便找到一个User-Agent即可
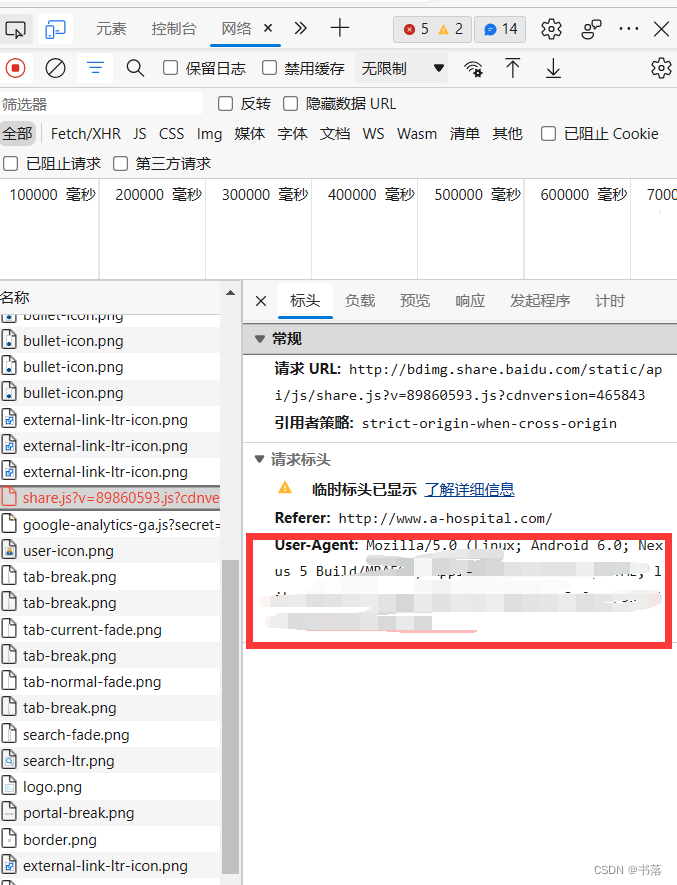
然后获取网页
res = requests.get(url=url,headers=headers)
解析数据
得到网页之后,使用etree中的HTML解析
然后找到你需要的数据位置,右键复制XPath
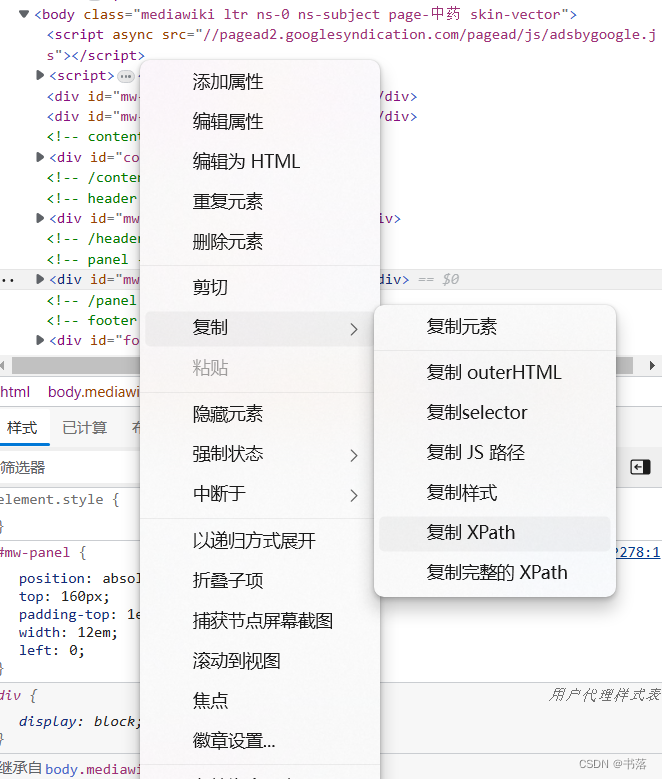
html = etree.HTML(res.text)
diss_liss = html.xpath('/html/body/div[3]/div[2]/h4')
这里需要注意,有的网站复制时会给你加一个“/tbody”,这时你的获取列表就会是空的,我们在xpath中手动删除tbody即可
处理数据
按照你想要的方式读取即可
由于之前的步骤爬下的是列表,基本都要搭配使用for语句进行处理
for lis in liss:
lis_ = lis.xpath('./ul/li')
for li in lis_:
data = li[0].text
print(data)
运行结果
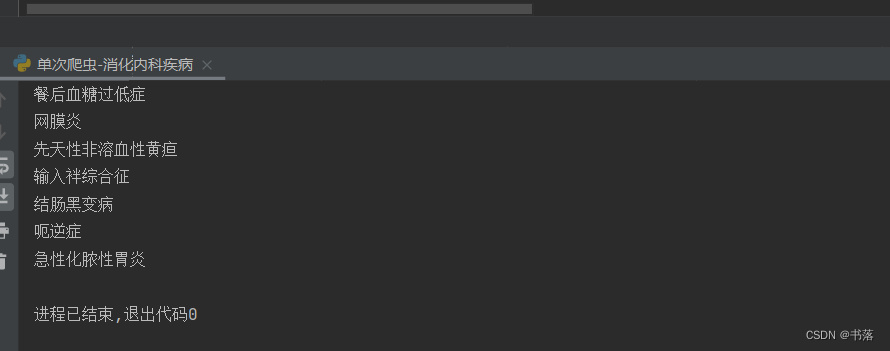
源码
import requests
from lxml import etree
url = "http://www.a-hospital.com/w/%E6%B6%88%E5%8C%96%E5%86%85%E7%A7%91%E7%96%BE%E7%97%85"
headers = {
'User-Agent': '
}
res = requests.get(url=url,headers=headers)
html = etree.HTML(res.text)
liss = html.xpath('//*[@id="bodyContent"]/table[2]/tr/td')
for lis in liss:
lis_ = lis.xpath('./ul/li')
for li in lis_:
data = li[0].text
print(data)















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









