







目录
1. 这篇文章的主要研究内容
A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data:基于深度神经网络的多元时间序列数据无监督异常检测与诊断
目标:对多元时间序列数据进行异常检测和诊断(根本原因识别),并根据不同事故的严重程度为操作人员提供不同级别的异常评分。
存在的挑战:
(1) 在历史数据中很少甚至没有异常标签,这使得监督算法不可行;
(2) 多元时间序列数据之间存在时间相关性,因此模型需要能够捕获不同时间步的时间依赖性;
(3) 在实际应用中,多元时间序列数据通常含有噪声。当噪声变得比较严重时,可能会影响时间预测模型的推广能力。因此系统应该对噪声具有鲁棒性。
文章提出的方法:多尺度卷积递归编码器-解码器(Multi-Scale Convolutional Recurrent Encoder-Decoder, MSCRED)
该方法的主要思路:
(1) MSCRED首先构造多尺度(分辨率)特征矩阵来描述跨不同时间步的多级系统状态,系统状态的不同级别表示不同异常事件的严重程度。
(2) 给定签名矩阵,使用卷积编码器对传感器之间的相关模式进行编码,并使用基于注意力的卷积长短时记忆(ConvLSTM)网络对时间信息进行建模;
(3) 使用卷积解码器重构特征矩阵,并使用平方损失进行端到端学习。
2. MSCRED Framework
1. Problem Statement
给定时间长度为T的n个时间序列数据 X = ( x 1 , x 2 , . . . , x n ) T ∈ R n × T \pmb{X} = (\pmb{x_1}, \pmb{x_2}, ... , \pmb{x_n})^T \in R^{n\times T} XX=(x1x1,x2x2,...,xnxn)T∈Rn×T ,并且假设数据不存在异常。
因为在训练过程中使用的是正常的数据,因此我们可以理解为神经网络学出了一个正常模式下的时间序列。
对于测试数据,如果测试数据和网络重构出的序列差别很大的话,我们就认为它是异常的。
我们的目标有两个:
- 异常检测:即检测T之后某个时间步的异常事件。
- 异常诊断:即根据检测结果,识别最可能导致每个异常的异常时间序列,定性地解释异常的严重程度(持续时间尺度)。
2. Overview

(1)Characterizing Status with Signature Matrices,用特征矩阵表征状态
为了表征从 t − w t-w t−w 到 t t t 这一时间步内不同时间序列片段之间的相互关系,我们基于不同时间序列两两之间的内积构造了一个 n × n n\times n n×n 的特征矩阵 M t M^t Mt 。
内积
m
i
j
t
∈
M
t
m_{ij}^t \in M^t
mijt∈Mt 的计算过程为:
m
i
j
t
=
∑
δ
=
0
w
x
i
t
−
δ
x
j
t
−
δ
κ
m_{ij}^t = \frac{\sum\limits^w_{\delta=0} x_i^{t-\delta} x_j^{t-\delta}}{\kappa}
mijt=κδ=0∑wxit−δxjt−δ 其中,
κ
\kappa
κ 是缩放因子(
κ
=
w
\kappa=w
κ=w)。
为了表征不同尺度下的系统状态,我们构造了
s
(
s
=
3
)
s(s=3)
s(s=3) 个不同时间步长
(
w
=
10
,
30
,
60
)
(w=10,30,60)
(w=10,30,60) 的特征矩阵。(本文中假设事件的严重程度与异常持续的时间成正比)
1个时间步对应一个 n × n × 3 n\times n\times 3 n×n×3 的签名矩阵,因此 T T T个时间步就对应 T T T个 n × n × 3 n\times n\times 3 n×n×3 的签名矩阵。
(2)Convolutional Encoder,卷积编码器
这里使用一个全卷积编码器(fully convolutional encoder)来编码系统特征矩阵的空间模式。
首先我们将
M
t
M^t
Mt 拼接成一个张量
X
t
,
0
∈
R
n
×
n
×
s
\mathcal{X}^{t,0} \in R^{n\times n\times s}
Xt,0∈Rn×n×s ,然后将其送入若干卷积层。假设第
l
−
1
l-1
l−1 层的特征映射为
X
t
,
l
−
1
∈
R
n
l
−
1
×
n
l
−
1
×
d
l
−
1
\mathcal{X}^{t,l-1} \in R^{n_{l-1} \times n_{l-1}\times d_{l-1}}
Xt,l−1∈Rnl−1×nl−1×dl−1 ,则第
l
l
l 层的输出为:
X
t
,
l
=
f
(
W
l
∗
X
t
,
l
−
1
+
b
l
)
\mathcal{X}^{t,l} = f(W^l * \mathcal{X}^{t,l-1} + b^l)
Xt,l=f(Wl∗Xt,l−1+bl) 这里 * 表示卷积操作,
f
(
⋅
)
f(·)
f(⋅) 为激活函数,
W
l
W^l
Wl 是第
l
l
l 层的卷积核,大小为
k
l
×
k
l
×
d
l
−
1
k_l \times k_l \times d_{l-1}
kl×kl×dl−1 ,
b
l
b^l
bl 是第
l
l
l 层的偏置项。
在本工作中,我们使用缩放指数线性单元(Scaled Exponential Linear Unit, SELU)作为激活函数 和 4个卷积层,即Conv1-Conv4 ,3 × 3 × 3大小的核有32个,3 × 3 × 32大小的核有64个,2×2 × 64大小的核有128个,2×2 × 128大小的核有256个,步长分别为1 × 1、2×2、2×2和2×2。
例如,针对30个传感器的10000分钟的数据,输入是
30
×
10000
30\times 10000
30×10000 的矩阵,,设置3个时间窗口,长度分别为10,30,60,时间间隔为10。那么可以得到 10000/10=1000 个
30
×
30
×
3
30\times 30\times 3
30×30×3 的特征矩阵。对于每一个
30
×
30
×
3
30\times 30\times 3
30×30×3 的特征矩阵,其卷积操作过程为:

(3)Attention based ConvLSTM,基于注意力的卷积长短时记忆网络
卷积编码器生成的空间特征图在时间上依赖于之前的时间步长。虽然ConvLSTM (Shi et al. 2015)已被开发用于捕获视频序列中的时间信息,但其性能可能会随着序列长度的增加而恶化。
在 ConvLSTM 中,给定第 l l l 个卷积层的特征映射 X t , l \mathcal{X}^{t,l} Xt,l ,当前状态 H t , l = C o n v L S T M ( X t , l , H t , l − 1 ) \mathcal{H}^{t,l} = ConvLSTM(\mathcal{X}^{t,l} , \mathcal{H}^{t,l-1}) Ht,l=ConvLSTM(Xt,l,Ht,l−1) 。具体做法为:

为了克服LSTM在处理三维信息中的不足,ConvLSTM 将 LSTM 中的2D的输入转换成了3D的tensor,最后两个维度是空间维度(行和列)。对于每一时刻t的数据,ConvLSTM 将 LSTM 中的一部分连接操作替换为了卷积操作,即通过当前输入和局部邻居的过去状态来进行预测。
为了解决上面提到的 ConvLSTM 存在的问题,本篇论文中开发了一种基于注意力的ConvLSTM,它可以跨不同的时间步自适应选择相关的隐藏状态(特征映射)。即:

其中,Vec(·) 为向量,
χ
\chi
χ 为缩放因子(
χ
\chi
χ=5.0)。
(4)Convolutional Decoder,卷积解码器
卷积解码器的表达式为:
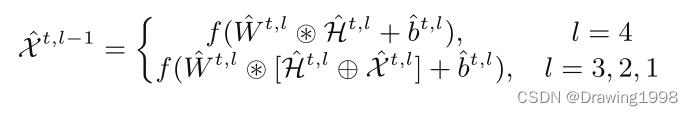
3. Loss Function
特征矩阵的重构误差定义为:
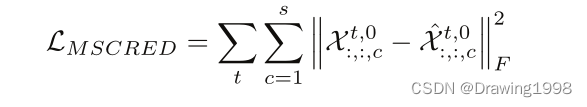















 3944
3944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









