







目录
Background
就不具体介绍OpenTSDB了。这里主要介绍怎么在基于CDH部署的HBase上集成OpenTSDB。之前使用的时序数据库InfluxDB,后面要做平台,不想花钱买InfluxDB集群,就只能上开源的OpenTSDB了,现在只是在测试环境上测试,这里做个记录,方便以后正式上快速安装部署。
1、安装部署
- 1.1 安装JDK
这个 jdk1.6+ 都行,我这里用的1.8,具体安装就不赘述了。
注意:需要配置JAVA_HOME,具体配置如下:
# jdk 安装路径
export JAVA_HOME=/usr/java/latest
export PATH=$PATH:$JAVA_HOME/bin
- 1.2 安装gnuplot
# GnuPlot 4.2 or later
yum -y install gnuplot
- 1.3 HBase版本要求
OpenTSDB2.4.0要求HBase版本大于0.92,我们这里使用的CDH6.2,集成的HBase是2.1.0的。
- 1.4 安装opentsdb
wget https://github.com/OpenTSDB/opentsdb/releases/tag/v2.4.0/opentsdb-2.4.0.noarch.rpm
rpm -ivh opentsdb-2.4.0.noarch.rpm
- 1.5 查看默认安装位置

2、修改配置
vim /usr/share/opentsdb/etc/opentsdb/opentsdb.conf
# 默认端口
tsd.network.port = 4242
# 是否自动创建 metic,默认值为 false
tsd.core.auto_create_metrics = true
# 修改为 zookeeper 集群地址
tsd.storage.hbase.zk_quorum = Cloud06,Cloud07,Cloud08
3、添加到系统服务
这里主要为了方便以后操作服务,有的软件安装好就自己添加到系统服务了,这个需要我们手动添加,把opentsdb的服务注册为系统服务,然后才可以用
systemctl status/start/stop/restart opentsdb来操作服务。
- 添加配置文件
vim /usr/lib/systemd/system/opentsdb.service
- 配置文件内容如下
[Unit]
Description=OpenTSDB Service
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=forking
ExecStart=/usr/share/opentsdb/etc/init.d/opentsdb start
ExecStop=/usr/share/opentsdb/etc/init.d/opentsdb stop
Restart=on-abort
[Install]
WantedBy=multi-user.target
- 设置开机自启动
systemctl enable opentsdb.service
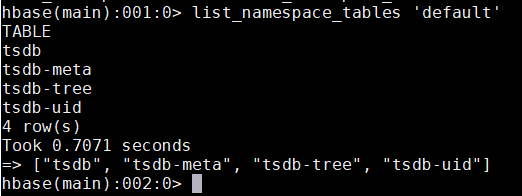
4、在hbase中创建tsdb的元信息及数据表
数据压缩采用SNAPPY压缩方式;
find / -name hbase 可以找到hbase的安装目录;
hbase表创建脚本的位置在上面截图中已经标出来了。
env COMPRESSION=SNAPPY HBASE_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase /usr/share/opentsdb/tools/create_table.sh

5、启动OpenTSDB
systemctl start opentsdb
systemctl status opentsdb

6、浏览器访问(Cloud01:4242)

7、后面使用计划
每个TSD实例都是独立的。没有master,没有共享状态(shared state),因此实际生产部署可能会通过运行多个TSD实例(读写分离)以实现负载均衡。Varnish(官方推荐)或者 nginx+Consul。
8、生产配置优化
# 在bin/tsdb中,设置JVM大小 12G
JVMARGS=${JVMARGS-'-Xmx12288m -enableassertions -enablesystemassertions'}
# 下面在 opentsdb.conf 配置文件中修改
# 是否在TSD启动的时候,预热UID缓存数据,为了提升性能,需要开启
tsd.http.request.enable_chunked=true
# Http写入数据时是否支持一次写入大批量的数据
tsd.core.preload_uid_cache=true
# 写入批量数据的上限
tsd.http.request.max_chunk=51200
# tsd查询的timeout,如果为0,则不会timeout
tsd.query.timeout=300
# 每来一条数据append到hbase
tsd.storage.enable_appends=true
# append打开,这种就关闭
tsd.storage.enable_compaction=false
# 写入相同时间是否覆盖前面的值
tsd.storage.fix_duplicates=true
# 是否启用 salting 功能,默认为0不开启。hashed salt ID 占用的字节数
tsd.storage.salt.width=1
# 打散到几个bucket去,默认20
tsd.storage.salt.buckets=6
# metric UID长度,默认3
tsd.storage.uid.width.metric=4
# tagK UID长度,默认3
tsd.storage.uid.width.tagk=4
# tagV UID长度 默认3
tsd.storage.uid.width.tagv=4
















 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











