









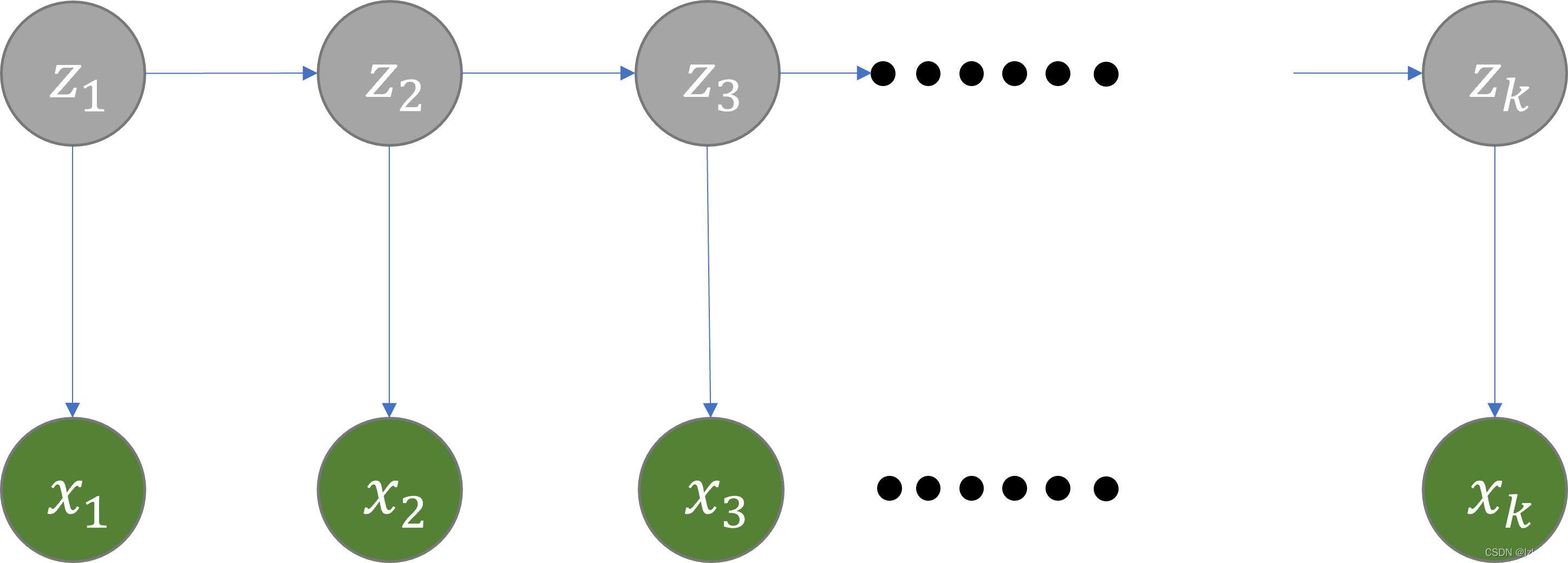
隐马尔科夫模型(HMM)
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。序列的每一个位置又可以看作是一个时刻。
生成式模型vs判别式模型
给定任务:已知序列 x x x,求标签 y y y,我们要做的实际上就是求 p ( Y ∣ X ) p(Y|X) p(Y∣X)
生成式模型
生成式模型是对联合概率 p ( x , y ) p(x, y) p(x,y)进行建模,就是考虑所有可能的标签 y y y,选择 p ( x , y ) p(x,y) p(x,y)最大的作为输出。
比较常见的生成式模型有:朴素贝叶斯、隐马尔科夫模型等
判别式模型
判别式模型是对条件概率 p ( y ∣ x ) p(y|x) p(y∣x)进行建模,就是在已知样本集中通过统计或计算得到条件概率,选择 p ( y ∣ x ) p(y|x) p(y∣x)最大的作为输出。
比较常见的判别式模型有:逻辑回归、条件随机场等
隐马尔可夫模型是一个生成式的模型,即每次给定观测序列,我们考虑所有的标记序列 y y y并求出 p ( x , y ) p(x, y) p(x,y),找到使 p ( x , y ) p(x,y) p(x,y)最大的 y y y
下面介绍HMM中的三大参数
HMM的参数
HMM模型有三大参数,即 θ = ( π , A , B ) \theta=(\pi,A,B) θ=(π,A,B)
参数 π \pi π
参数 π \pi π是一个一维的向量 ( π 1 , π 2 . . . π n ) (\pi_{1},\pi_2...\pi_n) (π1,π2...πn),每个元素代表的是状态 i i i出现在序列第一个位置的概率。以词性预测为例, π \pi π就表示动词、名词、形容词……出现在句子开头的概率。
参数A
参数 A A A也叫transition probability matrix,也就是状态转移概率矩阵。矩阵中每一个元素 A i j A_{ij} Aij表示从状态 i i i转移到状态 j j j的概率。
参数B
参数 B B B也叫做emission probability matrix,也就是生成概率矩阵。矩阵中每一个元素 B i j B_{ij} Bij表示状态 i i i生成观测值 j j j的概率。
下面,我们重点介绍HMM中的三大问题,并对每一个问题做详细探讨。
HMM三大问题
HMM要解决的三大问题如下:
- Inference:在已知模型参数 θ \theta θ和观测序列 x x x的前提下,计算概率 p ( z k ∣ x , θ ) p(z_k|x,\theta) p(zk∣x,θ)。
- Learning:已知观测序列 x x x,求HMM模型参数 θ = ( π , A , B ) \theta=(\pi,A,B) θ=(π,A,B)
- Decoding:已知模型参数 θ \theta θ和观测序列 x x x,求最优的标记序列 z z z
Inference
首先介绍Inference问题,也就是在已知模型参数 θ \theta θ和观测序列 x x x的前提下,计算概率 p ( z k ∣ x , θ ) p(z_k|x,\theta) p(zk∣x,θ)。最简单粗暴的方法是枚举所有可能的状态序列,再进行计算,但显然这个复杂度是指数级别的,不可取。根据条件概率公式, p ( z k ∣ x , θ ) = p ( z k , x ∣ θ ) p ( x ∣ θ ) p(z_k|x,\theta)=\frac{p(z_k,x|\theta)}{p(x|\theta)} p(zk∣x,θ)=p(x∣θ)p(zk,x∣θ),也就是说 p ( z k ∣ x , θ ) ∝ p ( z k , x ∣ θ ) p(z_k|x,\theta)\propto p(z_k,x|\theta) p(zk∣x,θ)∝p(zk,x∣θ)。而 p ( z k , x ) = p ( x 1 : k , z k ) p ( x k + 1 : n ∣ z k , x 1 : k ) p(z_k,x)=p(x_{1:k},z_k)p(x_{k+1:n}|z_k,x_{1:k}) p(zk,x)=p(x1:k,zk)p(xk+1:n∣zk,x1:k)。因此,我们介绍两种重要算法来解决这一问题,即Forward和Backward算法,这两个算法的本质都是动态规划(DP)。
前向算法(Forward Algorithm)
前向算法计算的是
p
(
x
1
:
k
,
z
k
∣
θ
)
p(x_{1:k},z_k|\theta)
p(x1:k,zk∣θ)。首先,我们尝试找到递推关系
p
(
x
1
:
k
,
z
k
∣
θ
)
=
C
∗
p
(
x
1
:
k
−
1
,
z
k
−
1
∣
θ
)
p(x_{1:k},z_k|\theta)=C*p(x_{1:k-1},z_{k-1}|\theta)
p(x1:k,zk∣θ)=C∗p(x1:k−1,zk−1∣θ)
这里的
C
C
C是我们要找的一个式子。这里可以看到有一个
z
k
−
1
z_{k-1}
zk−1项,因此我们可以尝试引入
z
k
−
1
z_{k-1}
zk−1并把它边缘化,即
p
(
x
1
:
k
,
z
k
∣
θ
)
=
∑
z
k
−
1
p
(
z
k
−
1
,
z
k
,
x
1
:
k
)
p(x_{1:k},z_k|\theta)=\sum_{z_{k-1}}{p(z_{k-1},z_k,x_{1:k})}
p(x1:k,zk∣θ)=zk−1∑p(zk−1,zk,x1:k)
接着我们对式子进行一个拆分得到
∑
z
k
−
1
p
(
z
k
−
1
,
z
k
,
x
1
:
k
)
=
∑
z
k
−
1
p
(
z
k
−
1
,
z
k
,
x
1
:
k
−
1
,
x
k
)
\sum_{z_{k-1}}p(z_{k-1},z_k,x_{1:k})=\sum_{z_{k-1}}p(z_{k-1},z_k,x_{1:k-1},x_k)
zk−1∑p(zk−1,zk,x1:k)=zk−1∑p(zk−1,zk,x1:k−1,xk)
∑ z k − 1 p ( z k − 1 , z k , x 1 : k − 1 , x k ) = ∑ z k − 1 p ( x 1 : k − 1 , z k − 1 ) p ( z k ∣ x 1 : k − 1 , z k − 1 ) p ( x k ∣ z k , z k − 1 , x 1 : k − 1 ) \sum_{z_{k-1}}p(z_{k-1},z_k,x_{1:k-1},x_k)=\sum_{z_{k-1}}p(x_{1:k-1},z_{k-1})p(z_k|x_{1:k-1},z_{k-1})p(x_k|z_k,z_{k-1},x_{1:k-1}) zk−1∑p(zk−1,zk,x1:k−1,xk)=zk−1∑p(x1:k−1,zk−1)p(zk∣x1:k−1,zk−1)p(xk∣zk,zk−1,x1:k−1)
根据D-Separation我们知道上式可以改写为
∑
z
k
−
1
p
(
x
1
:
k
−
1
,
z
k
−
1
)
p
(
z
k
∣
x
1
:
k
−
1
,
z
k
−
1
)
p
(
x
k
∣
z
k
,
z
k
−
1
,
x
1
:
k
−
1
)
=
∑
z
k
−
1
p
(
x
1
:
k
−
1
,
z
k
−
1
)
p
(
z
k
∣
z
k
−
1
)
p
(
x
k
∣
z
k
)
\sum_{z_{k-1}}p(x_{1:k-1},z_{k-1})p(z_k|x_{1:k-1},z_{k-1})p(x_k|z_k,z_{k-1},x_{1:k-1})=\sum_{z_{k-1}}p(x_{1:k-1},z_{k-1})p(z_k|z_{k-1})p(x_k|z_k)
zk−1∑p(x1:k−1,zk−1)p(zk∣x1:k−1,zk−1)p(xk∣zk,zk−1,x1:k−1)=zk−1∑p(x1:k−1,zk−1)p(zk∣zk−1)p(xk∣zk)
于是,我们成功的找到了这个递推关系。定义
α
t
(
i
)
\alpha_{t}(i)
αt(i)表示
1
1
1到
t
t
t时刻状态
z
t
=
i
z_t=i
zt=i的前向概率,递推公式为
α
t
(
j
)
=
[
∑
i
N
α
t
−
1
(
i
)
A
i
j
]
B
j
,
x
k
\alpha_t{(j)}=[\sum_{i}^{N}{\alpha_{t-1}(i)A_{ij}}]B_{j,x_k}
αt(j)=[i∑Nαt−1(i)Aij]Bj,xk
初始状态为
α
1
(
i
)
=
π
i
B
i
,
x
1
\alpha_1(i)=\pi_iB_{i,x_1}
α1(i)=πiBi,x1
后向算法(Backward Algorithm)
后向算法要计算的是
p
(
x
k
+
1
:
n
∣
z
k
,
θ
)
p(x_{k+1:n}|z_k,\theta)
p(xk+1:n∣zk,θ),其推导过程与前向算法一样,只是递推的方向不同。
p
(
x
k
+
1
:
n
∣
z
k
)
=
∑
z
k
+
1
p
(
x
k
+
1
:
n
,
z
k
+
1
∣
z
k
)
p(x_{k+1:n}|z_k)=\sum_{z_{k+1}}p(x_{k+1:n},z_{k+1}|z_k)
p(xk+1:n∣zk)=zk+1∑p(xk+1:n,zk+1∣zk)
∑ z k + 1 p ( x k + 1 : n , z k + 1 ∣ z k ) = ∑ z k + 1 p ( z k + 1 ∣ z k ) p ( x k + 1 ∣ z k , z k + 1 ) p ( x k + 2 : n ∣ z k , z k + 1 , x k + 1 ) \sum_{z_{k+1}}p(x_{k+1:n},z_{k+1}|z_k)=\sum_{z_{k+1}}p(z_{k+1}|z_k)p(x_{k+1}|z_k,z_{k+1})p(x_{k+2:n}|z_k,z_{k+1},x_{k+1}) zk+1∑p(xk+1:n,zk+1∣zk)=zk+1∑p(zk+1∣zk)p(xk+1∣zk,zk+1)p(xk+2:n∣zk,zk+1,xk+1)
∑ z k + 1 p ( z k + 1 ∣ z k ) p ( x k + 1 ∣ z k , z k + 1 ) p ( x k + 2 : n ∣ z k , z k + 1 , x k + 1 ) = ∑ z k + 1 p ( z k + 1 ∣ z k ) p ( x k + 1 ∣ z k + 1 ) p ( x k + 2 : n ∣ z k + 1 ) \sum_{z_{k+1}}p(z_{k+1}|z_k)p(x_{k+1}|z_k,z_{k+1})p(x_{k+2:n}|z_k,z_{k+1},x_{k+1})=\sum_{z_{k+1}}p(z_{k+1}|z_k)p(x_{k+1}|z_{k+1})p(x_{k+2:n}|z_{k+1}) zk+1∑p(zk+1∣zk)p(xk+1∣zk,zk+1)p(xk+2:n∣zk,zk+1,xk+1)=zk+1∑p(zk+1∣zk)p(xk+1∣zk+1)p(xk+2:n∣zk+1)
定义
β
t
(
i
)
\beta_{t}(i)
βt(i)表示
t
t
t到
n
n
n,
t
t
t时刻状态为
z
t
=
i
z_t=i
zt=i的后向概率,递推公式为
β
t
(
i
)
=
∑
j
n
A
i
j
B
j
,
x
t
+
1
β
t
+
1
(
j
)
\beta_t(i)=\sum_{j}^n{A_{ij}B_{j,x_{t+1}}\beta_{t+1}(j)}
βt(i)=j∑nAijBj,xt+1βt+1(j)
初始状态为
β
T
(
i
)
=
1
\beta_T(i)=1
βT(i)=1
有了前向算法和后向算法,我们的
p
(
z
k
∣
x
)
p(z_k|x)
p(zk∣x)就可以进行计算,之前我们得到
p
(
z
k
∣
x
)
∝
p
(
x
1
:
k
,
z
k
)
p
(
x
k
+
1
:
n
∣
z
k
,
x
1
:
k
)
p(z_k|x)\propto p(x_{1:k},z_k)p(x_{k+1:n}|z_k,x_{1:k})
p(zk∣x)∝p(x1:k,zk)p(xk+1:n∣zk,x1:k),根据前向后向算法,
p
(
z
k
=
i
∣
x
)
∝
α
k
(
i
)
β
k
(
i
)
p(z_k=i|x)\propto \alpha_k(i)\beta_k(i)
p(zk=i∣x)∝αk(i)βk(i)。由于是概率,所以我们做一个归一化,也就是
p
(
z
k
=
i
∣
x
)
=
α
k
(
i
)
β
k
(
i
)
∑
j
α
k
(
j
)
β
k
(
j
)
p(z_k=i|x)=\frac{\alpha_k(i)\beta_k(i)}{\sum_{j}\alpha_k(j)\beta_k(j)}
p(zk=i∣x)=∑jαk(j)βk(j)αk(i)βk(i)
我们把这个概率用
γ
k
(
i
)
\gamma_k(i)
γk(i)来表示
根据前向向量和后向向量,我们可以再一个概率
ξ
k
(
i
,
j
)
=
p
(
z
k
=
i
,
z
k
+
1
=
j
∣
x
,
θ
)
=
p
(
z
k
=
i
,
z
k
+
1
=
j
,
x
∣
θ
)
p
(
x
∣
θ
)
\xi_k(i,j)=p(z_k=i,z_{k+1}=j|x,\theta)=\frac{p(z_k=i,z_{k+1}=j,x|\theta)}{p(x|\theta)}
ξk(i,j)=p(zk=i,zk+1=j∣x,θ)=p(x∣θ)p(zk=i,zk+1=j,x∣θ)
p ( x ∣ θ ) = ∑ i n ∑ j n p ( z k = i , z k + 1 = j , x ∣ θ ) p(x|\theta)=\sum_{i}^n\sum_{j}^np(z_k=i,z_{k+1}=j,x|\theta) p(x∣θ)=i∑nj∑np(zk=i,zk+1=j,x∣θ)
p ( z k = i , z k + 1 = j , x ∣ θ ) = α k ( i ) A i j B j , x k + 1 β k + 1 ( j ) p(z_k=i,z_{k+1}=j,x|\theta)=\alpha_k(i)A_{ij}B_{j,x_{k+1}}\beta_{k+1}(j) p(zk=i,zk+1=j,x∣θ)=αk(i)AijBj,xk+1βk+1(j)
于是,
ξ
k
(
i
,
j
)
=
α
k
(
i
)
A
i
j
B
j
,
x
k
+
1
β
k
+
1
(
j
)
∑
i
n
∑
j
n
α
k
(
i
)
A
i
j
B
j
,
x
k
+
1
β
k
+
1
(
j
)
\xi_k(i,j)=\frac{\alpha_k(i)A_{ij}B_{j,x_{k+1}}\beta_{k+1}(j)}{\sum_{i}^n\sum_{j}^n\alpha_k(i)A_{ij}B_{j,x_{k+1}}\beta_{k+1}(j)}
ξk(i,j)=∑in∑jnαk(i)AijBj,xk+1βk+1(j)αk(i)AijBj,xk+1βk+1(j)
Learning
学习问题也就是参数估计问题。对于状态 z z z序列已知的情况(complete case),我们只需要对数据集进行统计即可,类似于N-gram模型。但是在HMM中,我们的状态序列是未知的,这也就是为什么被叫做隐马尔科夫模型。对于这种情况(incomplete case),我们采用的方法叫做EM算法
EM算法
EM算法全称叫做Expectation Maximization algorithm,专门用于求解含有 l a t e n t latent latent v a r i a b l e variable variable的模型参数。EM算法的流程如下:
- 设置模型参数的初始值 θ 0 \theta_0 θ0
- E步:将模型参数初始值视为已知量,根据第 i i i次迭代的模型参数 θ i \theta_i θi求第 i + 1 i+1 i+1步状态序列 z z z的期望
- M步:求使得E步求出的期望最大的模型参数 θ i + 1 \theta_{i+1} θi+1作为第 i + 1 i+1 i+1次迭代的模型参数估计值
- 迭代,直至收敛
参数 π \pi π求解
π
=
(
π
1
,
π
2
.
.
.
.
.
.
π
n
)
\pi=(\pi_1,\pi_2......\pi_n)
π=(π1,π2......πn)表示每一种状态作为初始状态的概率。由Inference问题我们可以求出
p
(
z
k
∣
x
)
p(z_k|x)
p(zk∣x),我们可以把这个概率当作是
π
\pi
π的一个期望值。于是套用EM算法即可。期望计算公式为
π
i
(
n
+
1
)
=
γ
1
(
i
)
\pi_i^{(n+1)}=\gamma_1(i)
πi(n+1)=γ1(i)
参数A求解
参数
A
A
A是转移概率矩阵,每个元素
A
i
j
A_{ij}
Aij的概率表达为
p
(
z
k
=
i
,
z
k
+
1
=
j
∣
x
)
p(z_k=i,z_{k+1}=j|x)
p(zk=i,zk+1=j∣x)。而这个概率是我们之前求出的
ξ
k
(
i
,
j
)
\xi_k(i,j)
ξk(i,j)。这个概率也可以被视作是一个期望值,于是可以使用EM算法。期望计算公式为
A
i
j
(
n
+
1
)
=
∑
t
=
1
T
−
1
ξ
t
(
i
,
j
)
∑
t
=
1
T
−
1
γ
t
(
i
)
A_{ij}^{(n+1)}=\frac{\sum_{t=1}^{T-1}\xi_t(i,j)}{\sum_{t=1}^{T-1}\gamma_t(i)}
Aij(n+1)=∑t=1T−1γt(i)∑t=1T−1ξt(i,j)
参数B求解
参数B是生成概率矩阵,同理,期望计算公式为
B
i
,
x
t
(
n
+
1
)
=
∑
t
=
1
,
x
t
=
k
T
γ
t
(
i
)
∑
t
=
1
T
γ
t
(
i
)
B_{i,x_t}^{(n+1)}=\frac{\sum_{t=1,x_t=k}^T\gamma_t(i)}{\sum_{t=1}^T\gamma_t(i)}
Bi,xt(n+1)=∑t=1Tγt(i)∑t=1,xt=kTγt(i)

Decoding
预测问题也被称为解码问题,就是已知观测序列和模型参数,来预测最优的标记序列。最笨的办法是枚举出所有可能的状态序列,然后找概率最大的,但复杂度显然是不可接受的。
下面介绍Viterbi算法。维特比算法本质是一种动态规划算法,它的计算原理可以通过下图来理解

Viterbi算法其实就是在寻找一条最优的路径,那么在HMM问题中,就是找一条概率最大的路径。
定义
δ
k
(
i
)
\delta_k(i)
δk(i)表示到第
k
k
k时刻,
z
k
=
i
z_k=i
zk=i的最优路径,递推公式如下
δ
k
+
1
(
j
)
=
m
a
x
i
=
(
1
,
2
,
3...
n
)
(
δ
k
(
i
)
A
i
j
B
i
,
x
k
+
1
)
\delta_{k+1}(j)=max_{i=(1,2,3...n)}(\delta_{k}(i)A_{ij}B_{i,x_{k+1}})
δk+1(j)=maxi=(1,2,3...n)(δk(i)AijBi,xk+1)
初始条件为
δ
1
(
i
)
=
π
i
B
i
,
x
1
\delta_1(i)=\pi_iB_{i,x_1}
δ1(i)=πiBi,x1
由于涉及到概率相乘,我们也可以把
δ
\delta
δ定义在对数空间,那么递推式为
δ
k
+
1
(
j
)
=
m
a
x
i
=
(
1
,
2
,
3...
n
)
{
δ
k
(
i
)
+
l
o
g
(
A
i
j
)
+
l
o
g
(
B
j
,
x
k
+
1
)
}
\delta_{k+1}(j)=max_{i=(1,2,3...n)}\lbrace\delta_{k}(i)+log(A_{ij}) + log(B_{j,x_{k+1}})\rbrace
δk+1(j)=maxi=(1,2,3...n){δk(i)+log(Aij)+log(Bj,xk+1)}
δ 1 ( i ) = l o g π i + l o g B i , x 1 \delta_1(i)=log\pi_i+logB_{i,x_1} δ1(i)=logπi+logBi,x1
算法复杂度是 O ( n 2 m ) O(n^2m) O(n2m)
以把
δ
\delta
δ定义在对数空间,那么递推式为
δ
k
+
1
(
j
)
=
m
a
x
i
=
(
1
,
2
,
3...
n
)
{
δ
k
(
i
)
+
l
o
g
(
A
i
j
)
+
l
o
g
(
B
j
,
x
k
+
1
)
}
\delta_{k+1}(j)=max_{i=(1,2,3...n)}\lbrace\delta_{k}(i)+log(A_{ij}) + log(B_{j,x_{k+1}})\rbrace
δk+1(j)=maxi=(1,2,3...n){δk(i)+log(Aij)+log(Bj,xk+1)}
δ 1 ( i ) = l o g π i + l o g B i , x 1 \delta_1(i)=log\pi_i+logB_{i,x_1} δ1(i)=logπi+logBi,x1
算法复杂度是 O ( n 2 m ) O(n^2m) O(n2m)
至此,HMM模型的内容就介绍完了,这个模型的原理较为复杂,要勤复习。














 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









