






想使用Dbeaver工具连接spark使用sparkSql访问Hive表,就要用到一个东西SparkThirdService;这东西就类似java jdbc连接,连接hive的hiveService2这种东西;
下面的列子是Hdp,并且Hdp带的Spark和Hive已经配置好了集成;
1.创建SparkThirdService
通过如下命令创建一个SparkThirdService, 类似于HiveService2 , JDBC, 最后效果就是创建了一个Spark应用程序;Hdp 默认的SparkThirdService 端口是10016
#进入Spark安装目录
sudo -u hive ./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10016 \
--hiveconf hive.server2.thrift.bind.host=19x.xxx.xxx.xx \
--hiveconf spark.sql.warehouse.dir=hdfs://xxxx.com:8020/warehouse/tablespace/managed/hive \
--master yarn \
--executor-memory 4G \
--conf spark.sql.shuffle.partitions=10
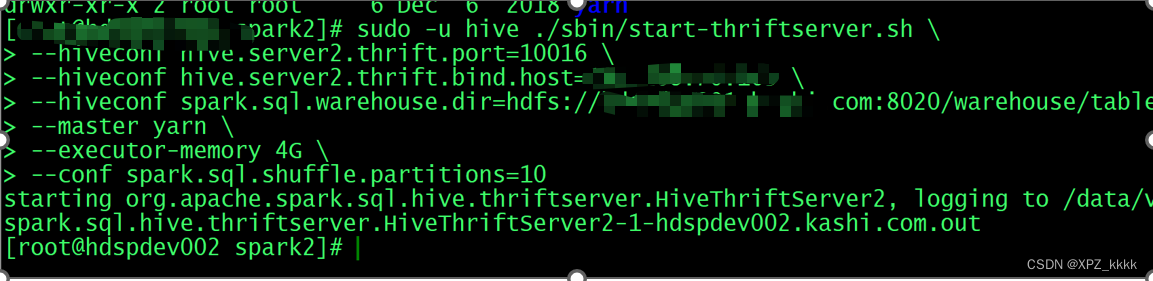
也可以补充execute-memory | cores 等资源参数
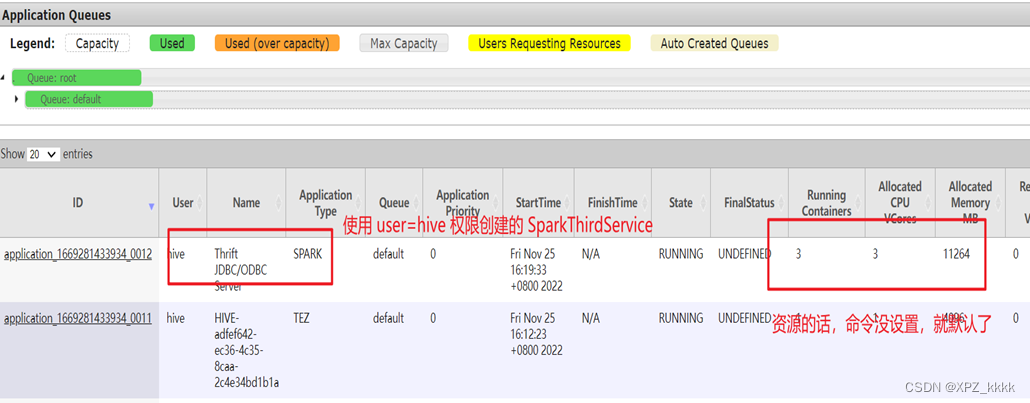
在Yarn页面查看上面创建的Spark应用
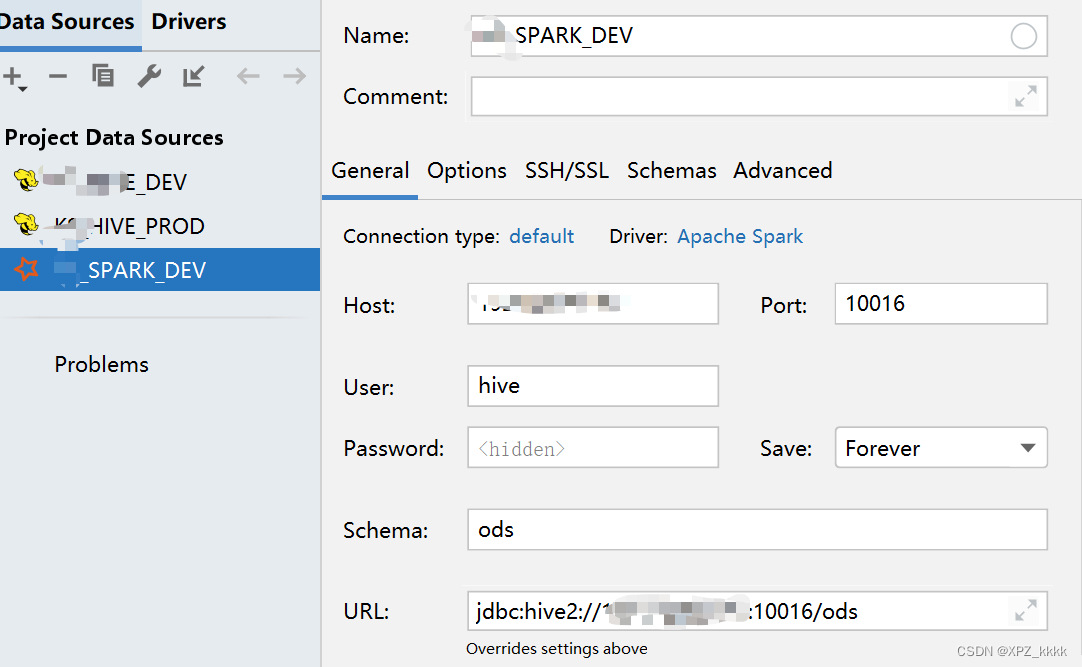
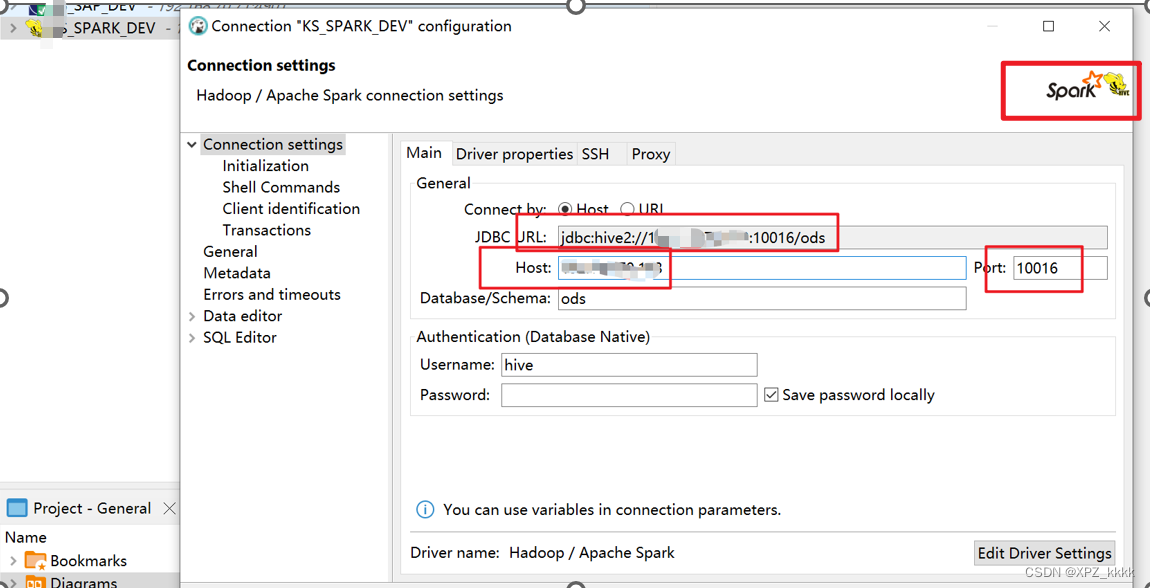
2.使用Dbeaver连接Spark,开始使用SparkSql
3.使用SparkSql操作Hive表
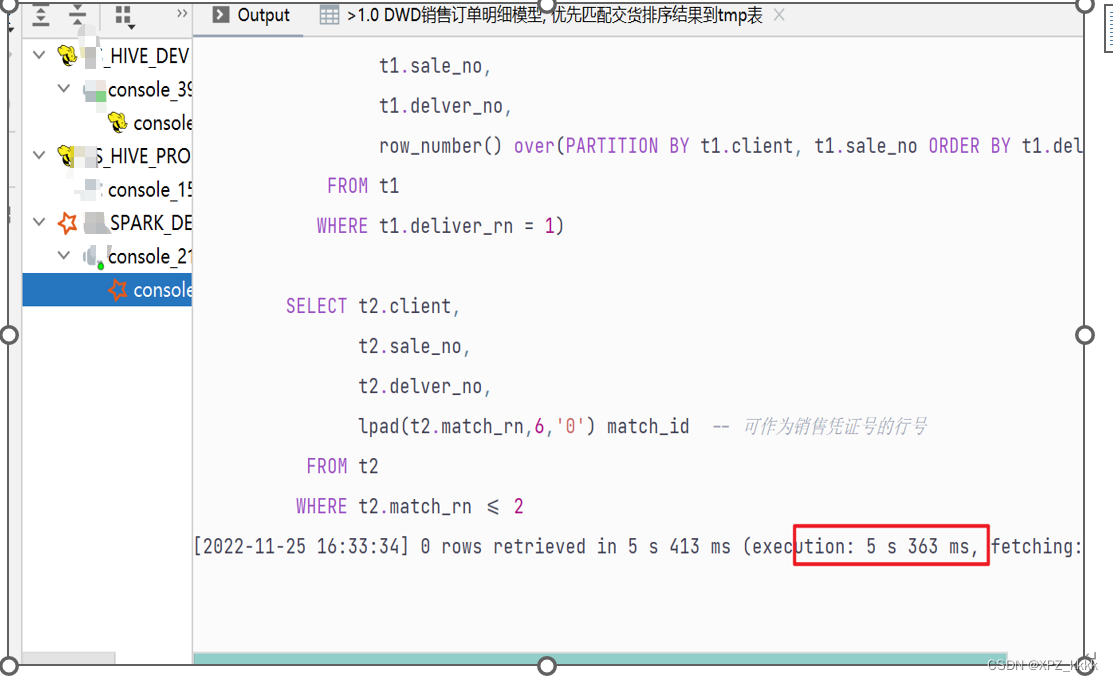
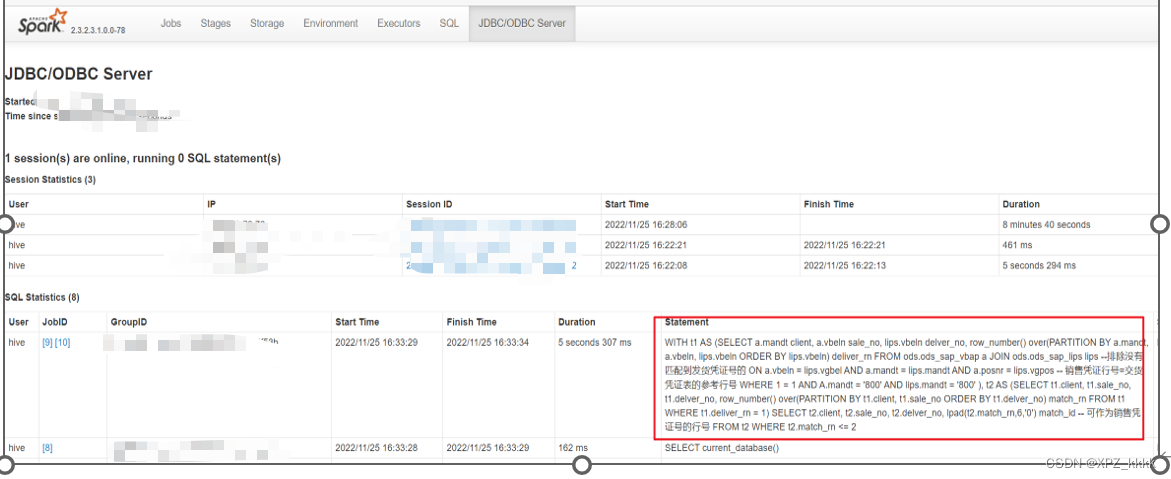
这个Spark应用确实跑的是Dbeaver里面执行的sql
 3.关闭SparkSthirdService
3.关闭SparkSthirdService
Kill- 9 对应的Spark进程号
或者在yarn上kill这个应用:
yarn application -kill applicaton_xxxxx
查看10016端口号对应的进程号。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









