







 本文介绍了维恩图和集合图在数据集合可视化中的应用,特别是在多组数据比较时的选择。当集合数量小于5时,推荐使用维恩图,而超过5个时,集合图更为清晰。文章通过R语言的VennDiagram和UpsetR包提供了绘制这两种图的示例代码,并展示了如何通过UpsetR创建多元化的集合图展示形式。
本文介绍了维恩图和集合图在数据集合可视化中的应用,特别是在多组数据比较时的选择。当集合数量小于5时,推荐使用维恩图,而超过5个时,集合图更为清晰。文章通过R语言的VennDiagram和UpsetR包提供了绘制这两种图的示例代码,并展示了如何通过UpsetR创建多元化的集合图展示形式。
在进行数据的集合可视化时,即突出不同处理、各组样本之间独有或共有的特征或元素,可以利用
维恩图(Venn plot)或
集合图(Upset plot)来展示。通常,大家对维恩图的了解较多,因为它在所发表的文章中比较常见。然而,当集合的数量种类较多(超过5个时),其可视化显得杂乱无章。事实上,这两类图所展示的内容的本质是一样的,可以根据自身的实际情况,选择合适自己文章的图形。
🐣 一、维恩图与集合图的比较
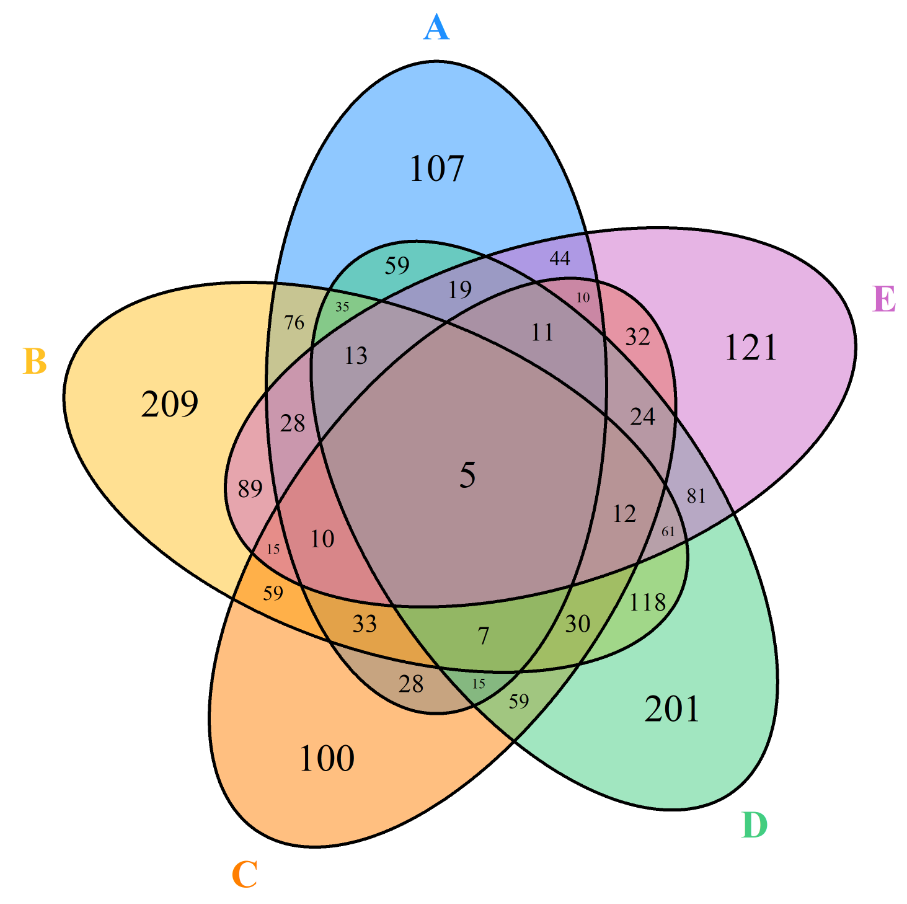
我们看几张维恩图和集合图,先从视觉上对这两种图有一个大致了解。不同集合数量导致维恩图和集合图的可视化差异明显:从 维恩图 来看,当数量分布在 2 和 3 时,视觉效果相当好。我们可以很清晰地识别不同组之间独有和共有的特征或元素。随着集合数的增加,当数量为 4 时,还能够较清晰地获取相关信息。当数量等于 5 时,想对图实现清晰地捕捉是有点困难的。

从 集合图 来看,当数量等于 2 和 3 时,集合图从视觉上看略显单调。随着集合数量的增加,当数量增加到 5 时,相比于维恩图,集合图展示的结果(不同组的特有或共有信息)依然清晰(当然集合图也是可以改颜色的,这个大家不用担心并不是如此黑)。
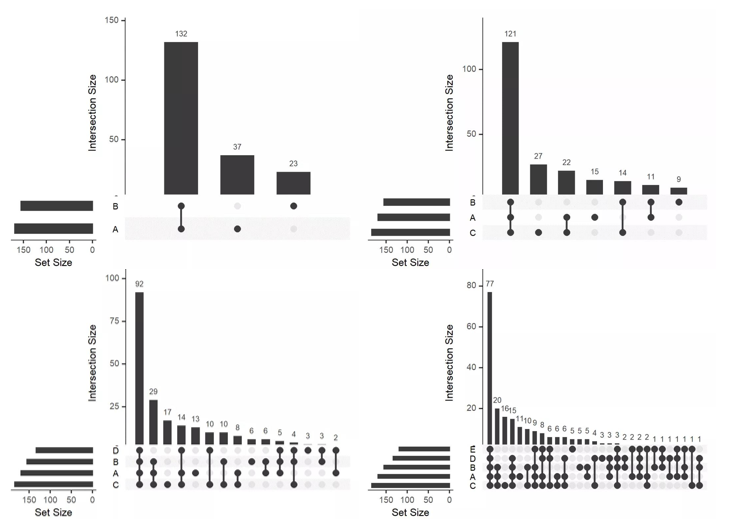
尽管两种图形看起来差异很大,但是其本质均反映了各组之间的集合关系。因此,我们要做的就是根据自己数据的情况,选择合适的集合图形。
简言之
- 当集合数量<5时,建议使用维恩图更加清晰;
- 当集合数量>5时,建议使用集合图更加清晰;
- 集合图能够实现更多的展示方式。
🐤 二、利用R语言绘制维恩图和集合图
绘制维恩图,主要用到R语言VennDiagram包中的venn.diagram函数;绘制集合图,主要用到R语言UpsetR包中的upset函数。学习代码的时候,还是按照惯例,先用?或者help查阅一下对应参数及其用法;结果如下:
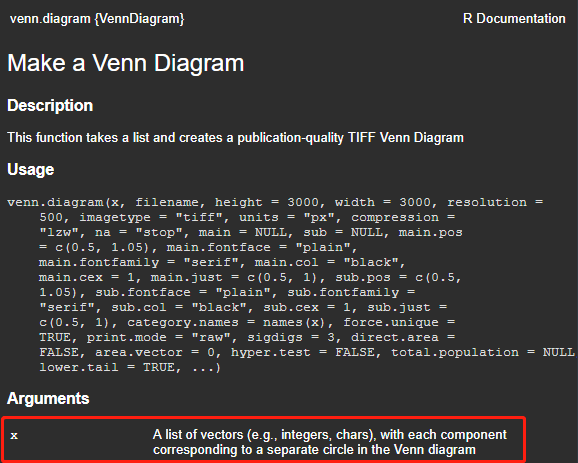
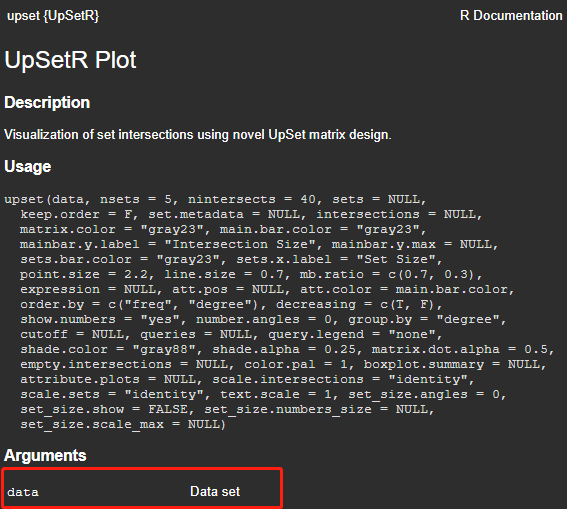
这里,需要注意的是,两种图形对数据的要求不同。venn.diagram要求用 list 输入以各组为集合的元素向量,存在几个分组就对应几个集合;而upset则以以数据框形式输入,用 数字0和1表示元素是否存在分组集合 中。以下截图来自两个函数的Example:
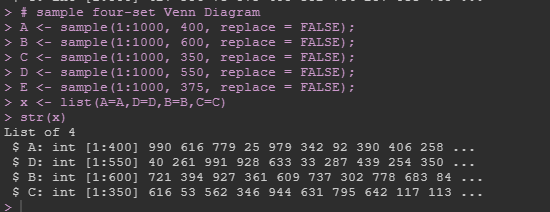
具体的代码实战过程:以五个分组为例。
🍌 1、维恩图
# 选择并设定工作路径
choose.dir()
setwd()
# 加载R包
library(VennDiagram)
?venn.diagram
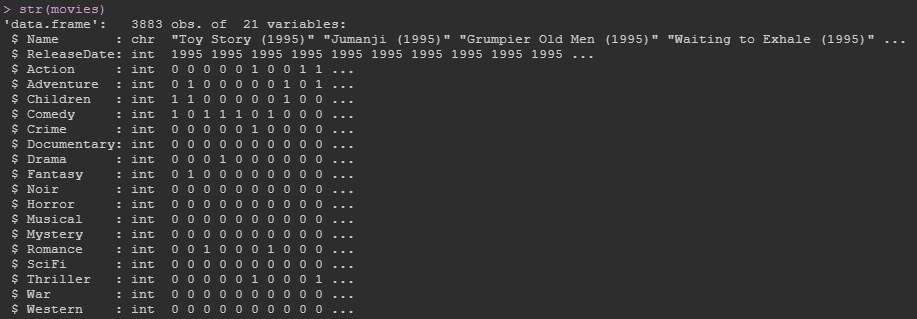
str(x) # 查看数据类型
# 样本五组维恩图
venn.plot <- venn.diagram(
x,
filename = "Venn_5set_pretty.tiff", # 导出文件名
col = "black", # 维恩图每个组边的颜色
fill = c("dodgerblue", "goldenrod1", "darkorange1", "seagreen3", "orchid3"), # 各组的填充颜色
alpha = 0.50, # 透明度
cex = c(1.5, 1.5, 1.5, 1.5, 1.5, 1, 0.8, 1, 0.8, 1, 0.8, 1, 0.8,
1, 0.8, 1, 0.55, 1, 0.55, 1, 0.55, 1, 0.55, 1, 0.55, 1, 1, 1, 1, 1, 1.5), # 向量给出每个区域标签的大小
cat.col = c("dodgerblue", "goldenrod1", "darkorange1", "seagreen3", "orchid3"), # 向量给出每个类别名称的颜色
cat.cex = 1.5, # 向量给出每个类别名称的大小
cat.fontface = "bold", # 向量给出每个类别名称的字体
margin = 0.05 # 以网格单位表示图表周围空白的数量
);

需要注意: 维恩图的绘制结果无法在Rstudio中直接展示,而是生成图形并保存于工作目录。所以,一定要清楚自己所设置的工作路径。
🥝 2、集合图
library(UpSetR) # 加载R包
head(movies) # 查看数据前6行
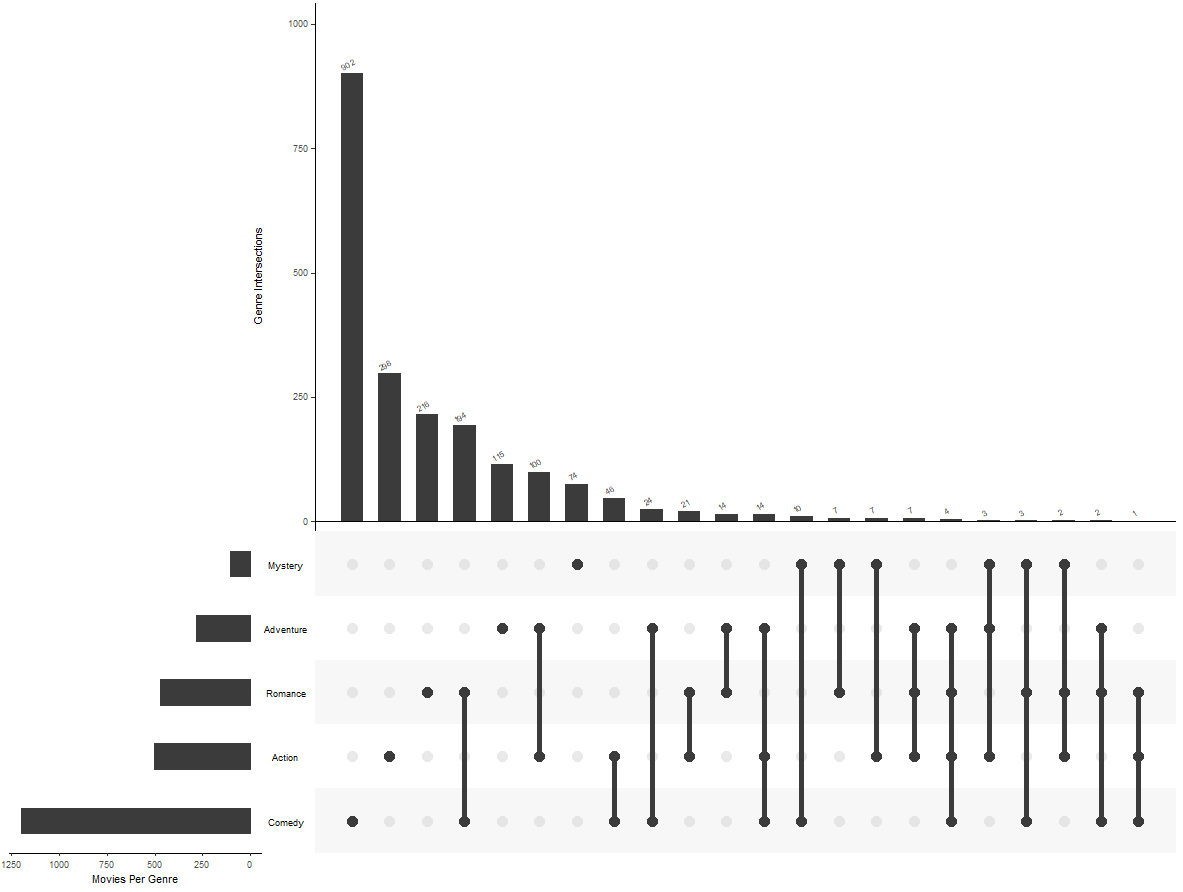
upset(data = movies,
sets = c("Action", "Adventure", "Comedy", "Drama", "Mystery",
"Thriller", "Romance", "War", "Western"), # 指定集合
number.angles = 30, # 设置交互集合柱状图上方数字的角度
point.size = 3.5, # 设置矩阵中圆圈的大小
line.size = 2, # 设置矩阵中连接圆圈的线的大小
mainbar.y.label = "Genre Intersections", # 设置y轴标签
sets.x.label = "Movies Per Genre", # 设置x轴标签
mb.ratio = c(0.6, 0.4), # 设置bar plot和matrix plot图形高度的占比
order.by = "freq") # 设置矩阵中的交点应该如何排列

结果如下:
进一步绘制集合图的多种展示形式:这部分代码就不一一解读了,大家尝试自己学习。
# 构建metadata信息
sets <- names(movies[3:19])
avgRottenTomatoesScore <- round(runif(17, min = 0, max = 90))
metadata <- as.data.frame(cbind(sets, avgRottenTomatoesScore))
names(metadata) <- c("sets", "avgRottenTomatoesScore")
head(metadata)
metadata$avgRottenTomatoesScore <- as.numeric(as.character(metadata$avgRottenTomatoesScore))
## Upset plot具有多种展现形式
## 添加元数据条形图
upset(movies,
sets = c("Action", "Adventure", "Comedy", "Drama", "Mystery", "Thriller", "Romance", "War", "Western"),
set.metadata = list(data = metadata,
plots = list(list(type = "hist", column = "avgRottenTomatoesScore", assign = 20))))
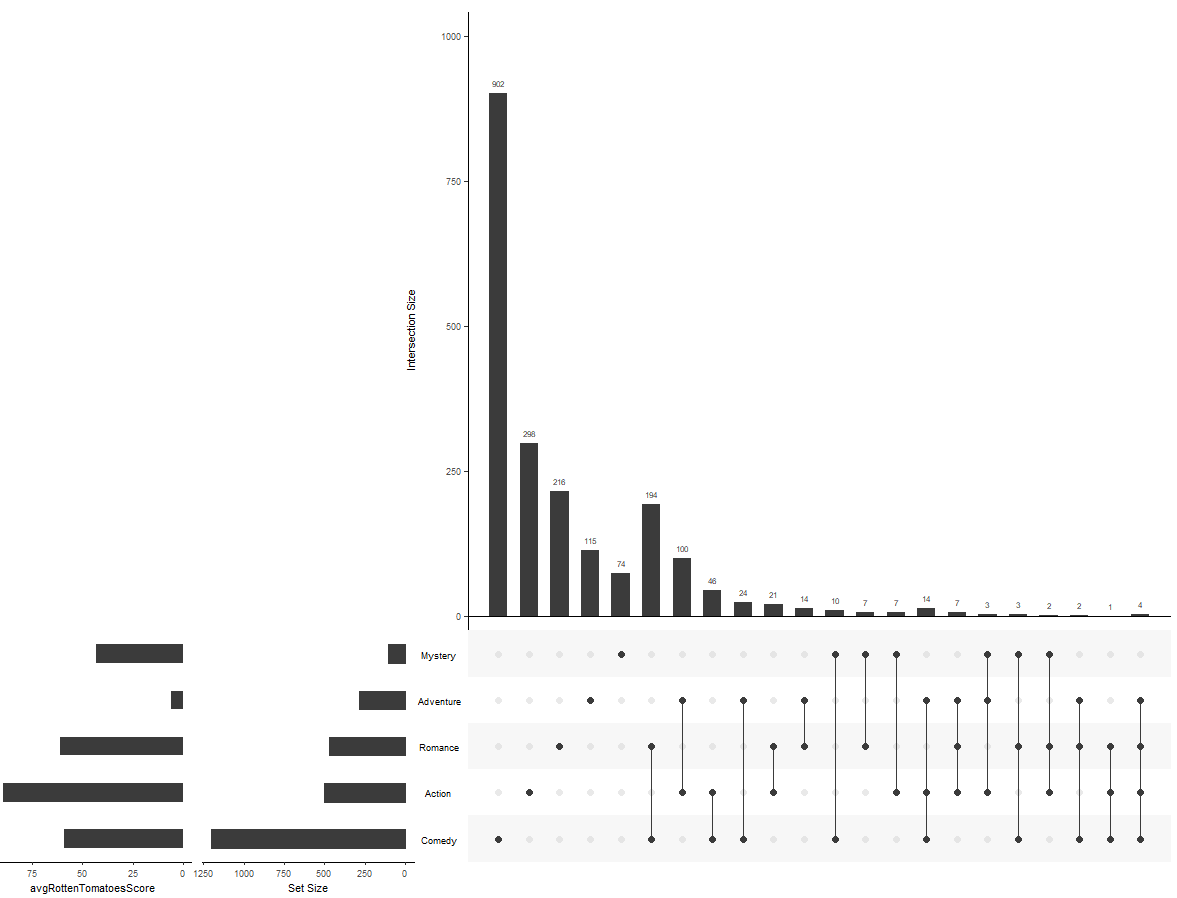
## 添加元数据热图
Cities <- sample(c("Boston", "NYC", "LA"), 17, replace = T)
metadata <- cbind(metadata, Cities)
metadata$Cities <- as.character(metadata$Cities)
metadata[which(metadata$sets %in% c("Drama", "Comedy", "Action", "Thriller", "Romance")), ]
head(metadata)
upset(movies,
sets = c("Drama", "Comedy", "Action", "Thriller", "Romance"),
set.metadata = list(data = metadata,
plots = list(list(type = "heat", column = "Cities", assign = 10, colors = c(Boston = "green", NYC = "navy", LA = "purple")))))
upset(movies,
sets = c("Drama", "Comedy", "Action", "Thriller", "Romance"),
set.metadata = list(data = metadata,
plots = list(list(type = "heat", column = "Cities", assign = 10, colors = c(Boston = "green", NYC = "navy", LA = "purple")),
list(type = "heat", column = "avgRottenTomatoesScore", assign = 10))))

## 添加内置属性直方图
upset(movies,
main.bar.color = "black",
queries = list(list(query = intersects, params = list("Drama"), active = T)),
attribute.plots = list(gridrows = 50,
plots = list(list(plot = histogram, x = "ReleaseDate", queries = F),
list(plot = histogram, x = "AvgRating", queries = T)), ncols = 2))
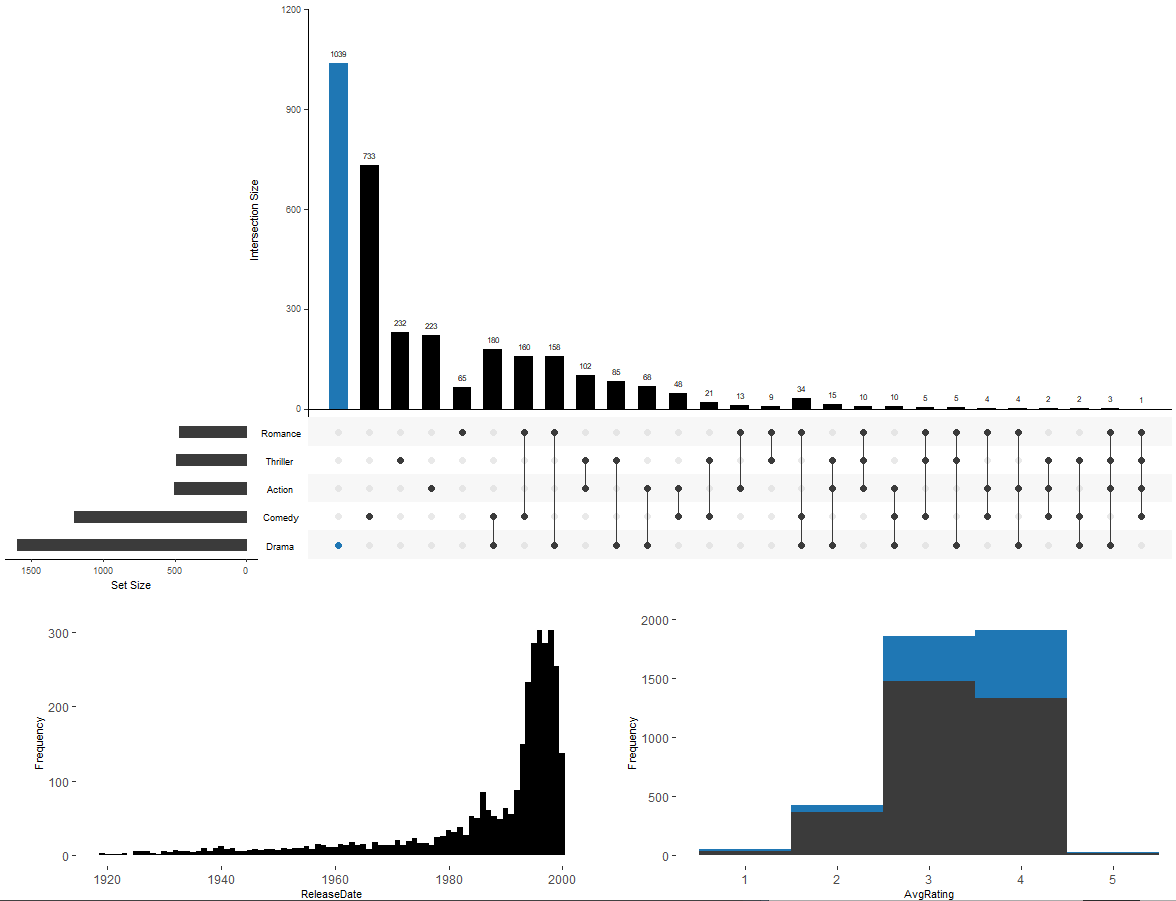
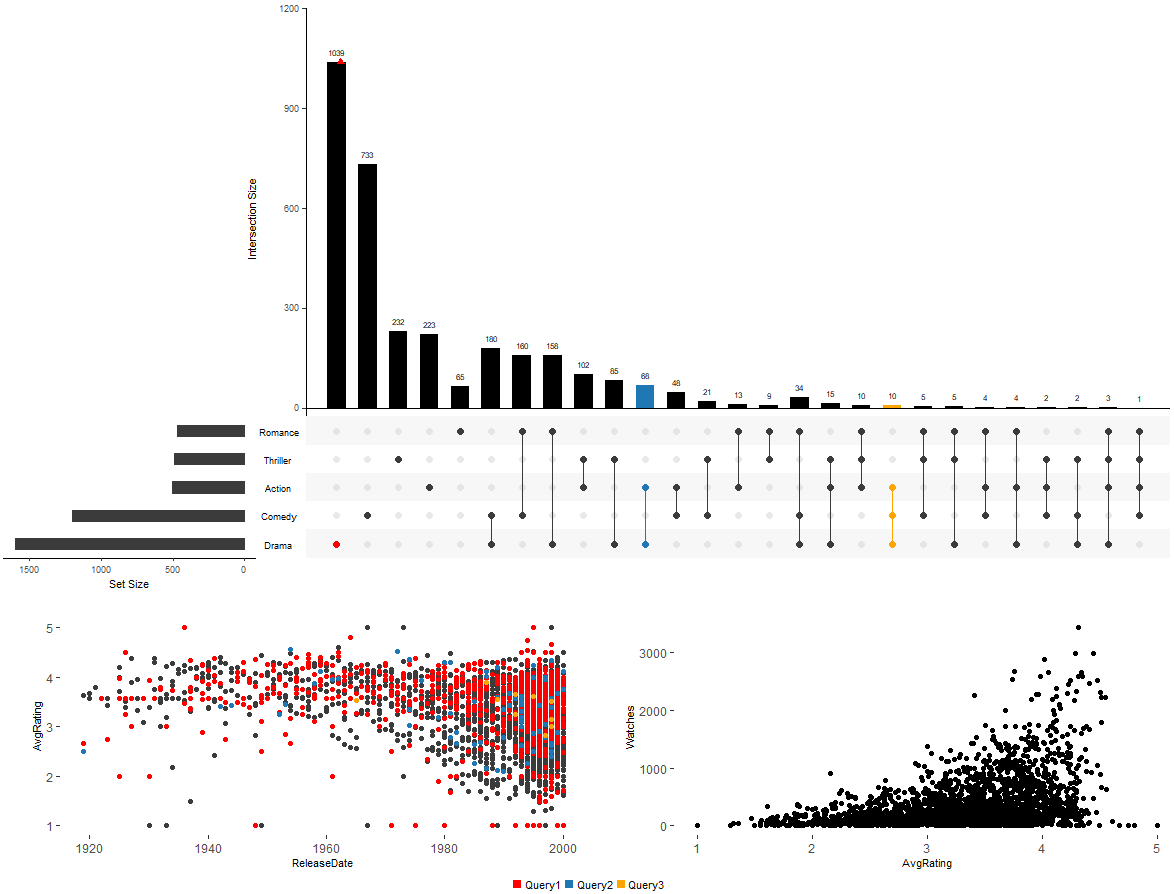
## 添加内置属性散点图
upset(movies,
main.bar.color = "black",
queries = list(list(query = intersects, params = list("Drama"), color = "red", active = F),
list(query = intersects, params = list("Action", "Drama"), active = T),
list(query = intersects, params = list("Drama", "Comedy", "Action"), color = "orange", active = T)),
attribute.plots = list(gridrows = 45,
plots = list(list(plot = scatter_plot, x = "ReleaseDate", y = "AvgRating", queries = T),
list(plot = scatter_plot, x = "AvgRating", y = "Watches", queries = F)), ncols = 2), query.legend = "bottom")




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











