







 本文介绍了一种爬取NBA中文官网球员数据的方法,利用requests和json库,通过分析页面找到并解析保存球员数据的json文件,最终将数据保存为json格式。
本文介绍了一种爬取NBA中文官网球员数据的方法,利用requests和json库,通过分析页面找到并解析保存球员数据的json文件,最终将数据保存为json格式。
现在很多网站的数据都是通过Ajax动态加载的,我认为这恰恰降低了我们爬取的难度,因为我们无需考虑如何解析数据,只需要将json文件转换为字典形式,通过字典的键就可以取得我们所需要的数据。
爬取网站:NBA中文官网
用到的库:requests、json
思路:
- 分析页面找到保存有球员名字的json文件
- 解析json文件获取球员名字
- 获取保存球员数据的json文件
- 解析json文件获取有用的数据
- 将数据写入文件
步骤:
1:页面分析
打开NBA中文官网 选择数据 球员数据
进入之后我们可以看到一个包含50个球员数据的页面
点击一条进入详情页 选择数据选项卡
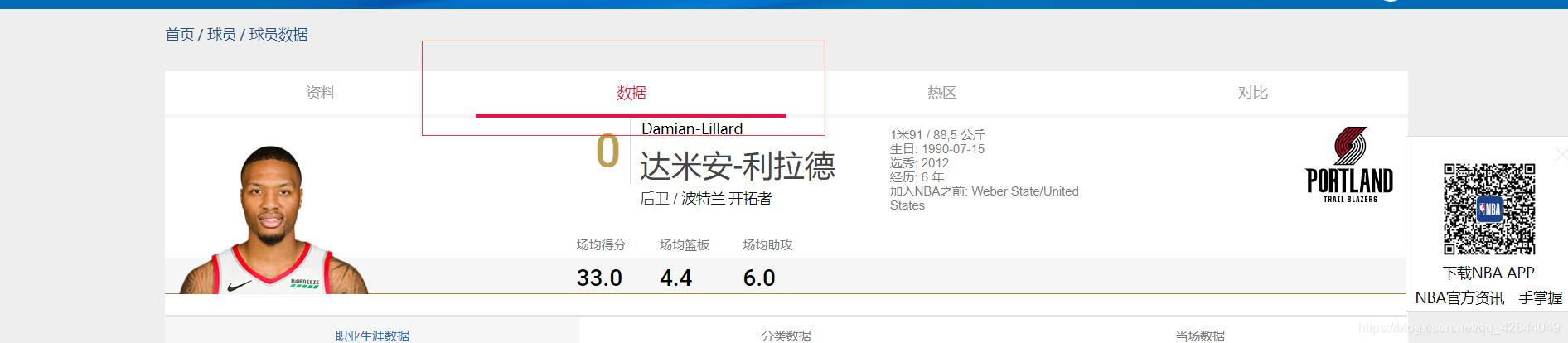
我们可以看到这名球员的详细数据,利拉德在最近五场比赛中的场均得分已经达到了第一。
我们需要爬取的就是每名球员的职业生涯数据
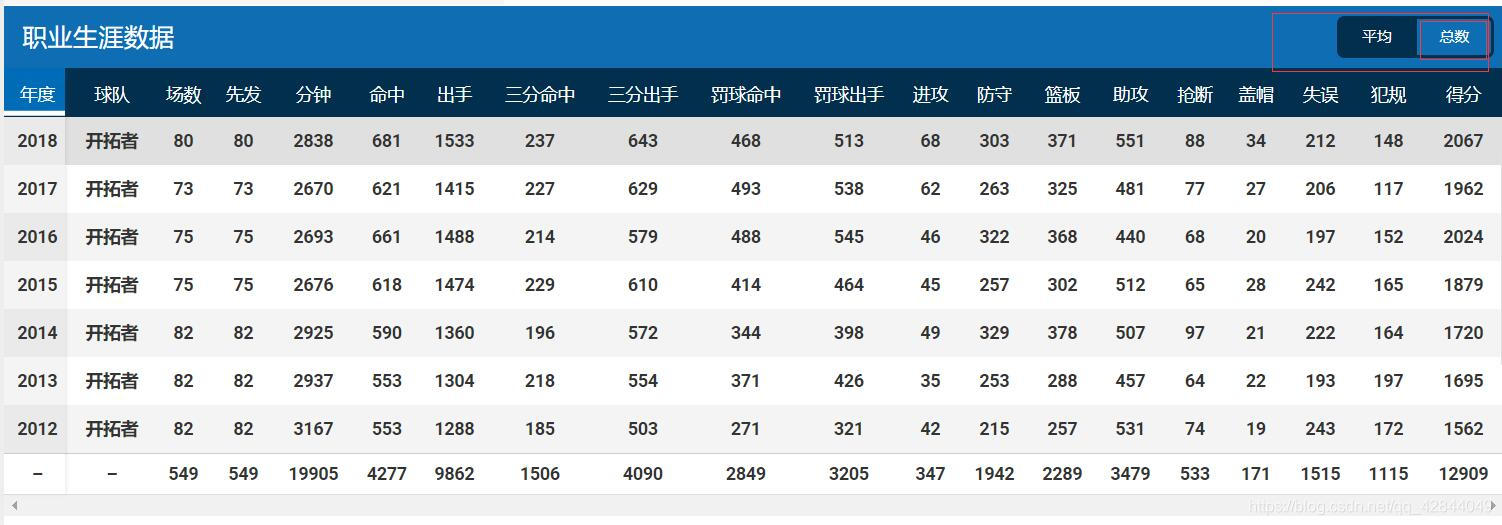
我选择的是总数这个选项卡,因为平均选项卡中球员的场均得分、三分命中率等数据都已经统计出来了,后续我还会对这些数据进行清洗分析以及可视化,所以我没有爬他统计好的数据。
找到保存数据的json文件,再说一遍 谷歌大法好 按F12打开开发者选项选择Network 和 XHR 选项卡
刷新页面

最后一个json文件保存的就是球员的数据
点击这个json文件获取这个json文件的url
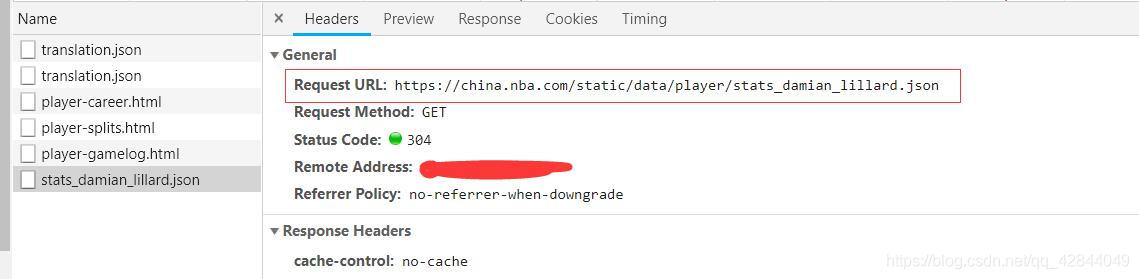
再打开另一个球员的json文件

我们可以发现这些url的规律,我们可以将球员的名字用一个变量代替从而实现循环抓取
这就是为什么我们要先获取球员的名字的原因。
同样的套路我们找到保存所有球员名字的json文件
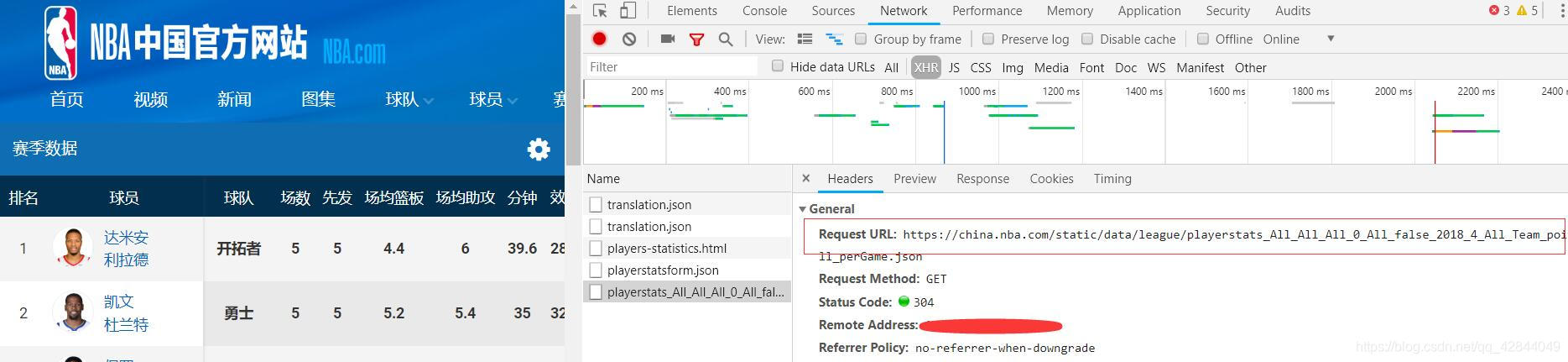
接下来我们就可以写代码获取这些球员的数据了
2:获取球员名字
定义一个方法获取json文件
def get_json(url):
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
json_data = json.loads(response.text)
return json_data
return None
except ConnectionError:
return None
定义解析球员名字的方法
def parse_player_data(json_file):
for data in json_file['payload']['players']:
yield data['playerProfile']['code']
不要问我怎么知道每个键的含义,你可以获取json文件后通过遍历他的键和值来找到他们之间的关系
也可以通过pandas的read_json()方法你也能很快发现他们之间的关系。还有就是有一个json文件放的是每个键的意思不过比较难找0.0滑稽保命

定义解析球员数据的方法
def parse_json(json_file):
for item in json_file['payload']['player']['stats']['regularSeasonStat']['playerTeams']:
try:
#时间
date = item['season']
#球队
team = item['profile']['name']
#出场
games = item['statAverage']['games']
#先发
gamesStarted = item['statAverage']['gamesStarted']
#分钟
mins = item['statTotal']['mins']
#命中
fgm = item['statTotal']['fgm']
#出手
fga = item['statTotal']['fga']
#三分命中
tpm = item['statTotal']['tpm']
#三分出手
tpa = item['statTotal']['tpa']
#罚球命中
ftm = item['statTotal']['ftm']
#罚球出手
fta = item['statTotal']['fta']
#进攻
offRebs = item['statTotal']['offRebs']
#防守
defRebs = item['statTotal']['defRebs']
#篮板
rebs = item['statTotal']['rebs']
#助攻
assists = item['statTotal']['assists']
#抢断
steals = item['statTotal']['steals']
#盖帽
blocks = item['statTotal']['blocks']
#失误
turnovers = item['statTotal']['turnovers']
#犯规
fouls = item['statTotal']['fouls']
#得分
points = item['statTotal']['points']
except Exception as e:
print(e)
yield {
'detail':{
'date':date,
'team':team,
'games':games,
'gamesStarted':gamesStarted,
'mins':mins,
'fgm':fgm,
'fga':fga,
'tpm':tpm,
'tpa':tpa,
'ftm':ftm,
'fta':fta,
'offRebs':offRebs,
'defRebs':defRebs,
'rebs':rebs,
'assists':assists,
'steals':steals,
'blocks':blocks,
'turnovers':turnovers,
'fouls':fouls,
'points':points
}
}
保存数据
try:
with open('result.json', 'w',
encoding='utf-8') as file:
file.write('[' + '\n')
count = len(result)
for i in range(0, count):
if i != count - 1:
file.write(json.dumps(result[i], ensure_ascii=False) + ',' + '\n')
else:
file.write(json.dumps(result[i], ensure_ascii=False) + '\n')
file.write(']')
file.close()
except Exception as e:
print(e)
完整代码
#作者: LENOVO
#时间: 2019/4/26 14:48
import json
import requests
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
def get_json(url):
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
json_data = json.loads(response.text)
return json_data
return None
except ConnectionError:
return None
def parse_json(json_file):
for item in json_file['payload']['player']['stats']['regularSeasonStat']['playerTeams']:
try:
#时间
date = item['season']
#球队
team = item['profile']['name']
#出场
games = item['statAverage']['games']
#先发
gamesStarted = item['statAverage']['gamesStarted']
#分钟
mins = item['statTotal']['mins']
#命中
fgm = item['statTotal']['fgm']
#出手
fga = item['statTotal']['fga']
#三分命中
tpm = item['statTotal']['tpm']
#三分出手
tpa = item['statTotal']['tpa']
#罚球命中
ftm = item['statTotal']['ftm']
#罚球出手
fta = item['statTotal']['fta']
#进攻
offRebs = item['statTotal']['offRebs']
#防守
defRebs = item['statTotal']['defRebs']
#篮板
rebs = item['statTotal']['rebs']
#助攻
assists = item['statTotal']['assists']
#抢断
steals = item['statTotal']['steals']
#盖帽
blocks = item['statTotal']['blocks']
#失误
turnovers = item['statTotal']['turnovers']
#犯规
fouls = item['statTotal']['fouls']
#得分
points = item['statTotal']['points']
except Exception as e:
print(e)
yield {
'detail':{
'date':date,
'team':team,
'games':games,
'gamesStarted':gamesStarted,
'mins':mins,
'fgm':fgm,
'fga':fga,
'tpm':tpm,
'tpa':tpa,
'ftm':ftm,
'fta':fta,
'offRebs':offRebs,
'defRebs':defRebs,
'rebs':rebs,
'assists':assists,
'steals':steals,
'blocks':blocks,
'turnovers':turnovers,
'fouls':fouls,
'points':points
}
}
def parse_player_data(json_file):
for data in json_file['payload']['players']:
yield data['playerProfile']['code']
def main():
result = []
name_url = 'https://china.nba.com/static/data/league/playerstats_All_All_All_0_All_false_2018_4_All_Team_points_All_perGame.json'
name_json= get_json(name_url)
name_data = parse_player_data(name_json)
for offset in name_data:
url = 'https://china.nba.com/static/data/player/stats_'+str(offset)+'.json'
json_data = get_json(url)
# print(json_data['payload'])
items = parse_json(json_data)
for item in items:
item['name'] = offset
# print(item)
#加入球员名字以便在分析数据的时候可以通过球员的名字对数据进行分类
result.append(item)
#print(result)
try:
with open('result.json', 'w',
encoding='utf-8') as file:
file.write('[' + '\n')
count = len(result)
for i in range(0, count):
if i != count - 1:
file.write(json.dumps(result[i], ensure_ascii=False) + ',' + '\n')
else:
file.write(json.dumps(result[i], ensure_ascii=False) + '\n')
file.write(']')
file.close()
except Exception as e:
print(e)
if __name__ == '__main__':
main()
运行结果
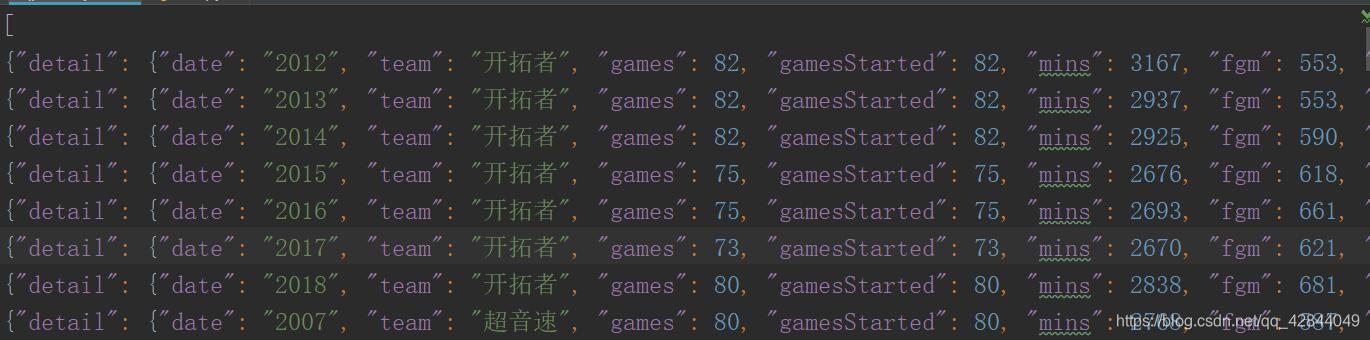
以上就是抓取Ajax动态加载数据的全过程,明后天我会继续写通过pandas或mapreduce+hive 对数据进行简单清洗和分析并将结果通过echarts图表的形式展示出来,如果有想看的同学可以继续关注!
虽然湖人没进季后赛但我还是想说一句:湖人总冠军!

















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









