




 本文深入探讨Map接口的实现类HashMap和TreeMap,解析它们的特性和通用方法,如put、get、remove等。HashMap依赖hashCode()和equals(),适合非同步环境,而TreeMap遵循Comparable或Comparator,保持键的有序性,适用于需要排序的场景。另外,文章还对比了HashMap与Hashtable的主要区别,包括线程安全性、null处理以及底层实现细节。
本文深入探讨Map接口的实现类HashMap和TreeMap,解析它们的特性和通用方法,如put、get、remove等。HashMap依赖hashCode()和equals(),适合非同步环境,而TreeMap遵循Comparable或Comparator,保持键的有序性,适用于需要排序的场景。另外,文章还对比了HashMap与Hashtable的主要区别,包括线程安全性、null处理以及底层实现细节。
前言:学任何技术不是要把它各个知识点背得滚瓜烂熟或者理解清楚就完了,最最关键的是要想想所学内容的应用场景,什么情况下使用。比如学完了Map
,要想想我在什么情况下去使用Map,把现实生活中的场景与知识相结合才是王道。不是说项目经理叫我用Map我就用Map,自己得学以致用
Map
映射:一一对应的关系 地图也是一种映射
Map[所有键值对集合统一的父接口]
HashMap
SortedMap [主键有序的键值对集合的父接口]
TreeMap
*所有Map通用的那些方法~
添加元素:put(key,value)或者putAll(另一个Map对象)
得到元素个数:size() 它返回的是键值对的数量
通过主键如何得到值对象:get(key) 注意区别它不是List的get(int)
如何删除元素:remove(key)
如何判断是否包含指定的键:containsKey(key)
如何判断是否包含指定的值:containsValue(value)
如何清空整个集合:clear() *:Map集合根本不提供iterator() 没法直接进行遍历
public class Test01 { public static void main(String[] args){
Map<String,Integer> map = new HashMap<>();
//如何添加元素不再使用add() 取而代之的是put(k,v) map.put("小翔",210); map.put("小俐",160); map.put("小黑",720); map.put("大白",638);
//根本不提供Collections.putAll()方法
//但是可以Map象.putAll(anotherMap)
//如何得到元素的个数 System.out.println(map.size()); //4
//获得指定键的值,跟List提供的get(int)方法不同System.out.println(map.get("小黑")); //720
//键值对集合删除元素不需要提供键和值,只需要提供键就足够了 map.remove("大白"); System.out.println(map.size()); //3 //如果我们想知道我们班有没有叫小黑的 - 找键对象 - containsKey(k) System.out.println(map.containsKey("小黑"));//true
//如果我们想知道我们班有没有人考750 - 找值对象 - containsValue(v) System.out.println(map.containsValue(750));//false } }
Map和西瓜的关系~ 如何遍历一个Map集合
keySet():得到所有主键对象组成的Set集合

public class Test02 {
public static void main(String[] args){
Map<String,Integer> map = new HashMap<>();
map.put("小翔",210);
map.put("小俪",160);
map.put("小黑",720);
map.put("大白",638); //第一种刀法:一个西瓜切两半 只拿左边那一半
//左边一半全是键 无序且唯一 所以是一个Set集合
Set<String> set = map.keySet();
for(String s : set){
System.out.println(s);//小俪 小黑 大白 小翔
}
}
}
values():得到所有值对象组成的Collection集合

public class Test03 {
public static void main(String[] args){
Map<String,Integer> map = new HashMap<>();
map.put("小翔",210);
map.put("小俪",160);
map.put("小黑",720);
map.put("大白",638); //第二种刀法 : 一个西瓜切两半 只拿右边那一半 //右边一半全是值 无序不唯一 不能用List,Set集合对象来接收 应该用无序不唯一的父接口来接收 这里是
Collection Collection<Integer> col = map.values();
for(Integer i : col){
System.out.println(i); // 160 720 638 210
}
}
}
entrySet():得到所有键值对对象组成的Set集合
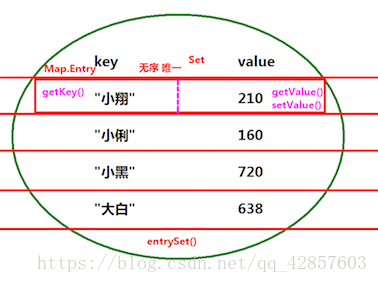
public class Test04 {
public static void main(String[] args){
Map<String,Integer> map = new HashMap<>();
map.put("小翔",210);
map.put("小俪",160);
map.put("小黑",720);
map.put("大白",638); //第三种切法 横向切片 : 一个西瓜横着切 每片都有键和值 无序唯一用Set集合对象来接收,每一片为Map.Entry<> //Map.Entry<>提供getKey() getValue() setValue()三个方法 Set<Map.Entry<String,Integer>> set = map.entrySet(); for(Map.Entry<String,Integer> e : set){
String name = e.getKey(); int score = e.getValue(); System.out.println(name + ":" + score);
/*打印 小俪:160 小黑:720 大白:638 小翔:210 */
}
}
}
HashMap:
HashMap跟HashSet一样一样的机制!hashCode() == equals() 而且不仅仅是添加的时候尊重哦~ HashMap的put() get() remove() containsKey()都尊重这种机制哦~ 也就是说 程序员通过覆盖hashCode()和equals()能够让不相同的主键对象被视作相同的!!
TreeMap:
TreeMap跟TreeSet一样一样一样的机制! 尊重 Comparable compareTo(1) Comparator compare(1,2) 而且不仅仅是添加的时候尊重哦! TreeMap的put() remove() get() containsKey()都尊重这种机制哦 某些时候需求决定compareTo或者compare是不能返回0 此时: 添加/删除/得到/包含 put()永远不会认定元素重复 remove()永远无法成功删除 get()永远返回null containsKey()永远返回false
*:HashMap和Hashtable的区别
1.同步特性不同,多线程是否安全不同 同步特性不同的本质就是Hashtable加锁,而HashMap没加锁 HashMap 线程不安全:同一时间允许多个线程同时进行操作,效率相对较高,但是可能会出现并发错误~这里是指客观上HashMap自己的特点 Hashtable 线程安全:同一时间只允许一个线程进行操作,效率较低,但是不会出现并发错误~
书中所说的HashMap同一时间不允许多个线程同时进行操作,是为了防止出现并发错误,因为HashMap底层是允许多个线程同时操作的。 书中所说的Hashtable 同一时间允许多个线程进行操作,是无论多少个线程来执行,Hashtable底层都同时都只能让一个线程操作 也就是说,书中是来规范我们如何安全地使用HashMap和Hashtable的,这跟他俩本质上的特点刚好相反 *:从jdk5.0开始 集合的工具类Collections当中出现了synchronizedMap()等方法,能够传入一个线程不安全的HashMap 返回安全的Map *
:从jdk5.0开始,并发包当中还提供了在高并发的场景下,效率更高HashMap实现,java.util.concurrent.ConcurrentHashMap//DougLea
ConcurrentHashMap加锁的操作是在每个散列组加锁,允许多个线程操作不同组数,效率更高
2.他们对null的"态度"不同 HashMap 无论主键还是值,都可以存放null 只不过由于主键要求唯一,所以只能添加一个null Hashtable 无论是主键还是值,都不能存放null 如果你敢添加null,他就直接抛出空指针异常
3.他们底层实现的细节不同 - 分组组数 HashMap 默认分为16个小组,可以指定分组,但是最终底层会计算出大于指定分组的最小2的n次方 因为底层采用 &(分组组数-1)来计算散列小组 Hashtable 默认分为11个小组,分组组数可以随意指定 正因为如此,它只能使用%(分组组数)来计算散列小组 4.他们出现的版本不同 HashMap since JDK1.2 Hashtable since JDK1.0 集合两大鼻祖,另外一个[Vector] *:在Map集合添加元素的时候,如果认定了主键对象重复 则新来的键直接舍弃,不会替换原有的键对象 但是新来的值会替换原有的值对象 从而让我们更加轻松的修改已经存在的值
public class Test05 {
public static void main(String[] args){
Map<Student,String> map = new HashMap<>();
Student s1 = new Student("Jay");
Student s2 = new Student("Gay");
map.put(s1,"和傻很天真");
map.put(s2,"灵活死胖子");
System.out.println(map);//{Jay=灵活死胖子
}
map.put(s1,"最帅男老师");
System.out.println(map);//{Jay=最帅男老师}
/* 这样的设计(同一个键,不同的值)
能够帮我们很轻松的去修改一个键值对所对应的值对象 这种设计也有隐藏的问题,如果我们用的是TreeMap 而且需求刚好导致不会返回0 那么这种机制根本没法用!!因为不返回0,就无法添加同样的键,不同的值的对象进去。 只能横向切片然后setValue(…); */ } }
class Student{
String name; public Student(String name){
this.name = name;
}
@Override
public String toString(){
return name;
}
@Override
public boolean equals(Object obj){
/*if(obj == null)return false;
if(!(obj instanceof Student))return false;
if(obj == this)return true;*/
return true;
}
@Override
public int hashCode(){
return 1;
}
}
- 无论大家使用keySet() 还是values() entrySet()所得到的集合 事实上都不是一个新的集合,而是原本的Map换了个角度呈现给我们而已 所以如果我们对得到的单值集合进行了删除操作 则原本Map当中整个一行键值对都没了!!!! 同理 如果在遍历那个得到的单值集合的过程中 对整个Map进行删除操作 也会触发CME哦~
public class Test06 {
public static void main(String[] args){
Map<String,Integer> map = new HashMap<>();
map.put("小翔",210);
map.put("小俐",160);
map.put("小黑",720);
map.put("大白",638);
for(Iterator<String> car = map.keySet().iterator();
car.hasNext();){
String s = car.next();
if("大白".equals(s)){ car.remove();
}
}
System.out.println(map);//{小黑=720, 小俐=160, 小翔=210}
}
}
- Map集合的键是唯一的,所以要修改键对象中的元素需要先删除,再修改,再重新添加, 这里可以使用另外一个Map暂存要修改的记录,但是这里要注意,在调用car.remove()删除元素 之后,再调用getKey() getValue() setValue()方法,获取的可能是下一个Map.Entry对象的键和值了,所以一定要car.remove()前得到键和值,然后进行操作
public class Test07 {
public static void main(String[] args){
//keySet() values() entrySet() Map.Entry
//getKey() getValue() setValue()
//size() remove() Iterator
TreeMap<Student,String> map = new TreeMap<>(new MyComparator());
Student s1 = new Student("昊昊",27);
Student s2 = new Student("磊磊",24);
Student s3 = new Student("龙龙",24);
Student s4 = new Student("晖晖",27);
Student s5 = new Student("超超",25);
Student s6 = new Student("超超",22);
Student s7 = new Student("嵩嵩",27);
map.put(s1,"0531-66532154");
map.put(s2,"0531-66666661");
map.put(s3,"0532-88888888");
map.put(s4,"0538-6678111");
map.put(s5,"0531-55555511");
map.put(s6,"0531-55555522");
map.put(s7,"0538-3434596");
//1st.打印当前通讯录总共收录了多少个联系人
//2nd.晖晖有个人生重要的考试 请假三天 暂时删除联系人 两种不同的方法实现
//3rd.嵩song嵩过生日了 已经28岁了 修改收录的年龄信息 一种做法
//4th.泰安市发展迅速 电话号码升位 开头+8
//5th.请显示所有居住在济南的学生姓名
//6th.打印所有同学所在的城市
//7th.所有年龄低于25岁的同学 改用昵称 小X
//1st. 打印当前通讯录总共收录了多少个联系人 System.out.println(map.size());
//2nd.晖晖有个人生重要的考试 请假三天 暂时删除联系人 两种不同的方法实现
//第一种
/*for(Iterator<Student> car = map.keySet().iterator();
car.hasNext();){ Student s = car.next();
if("晖晖".equals(s.name)){ car.remove(); } }
System.out.println("2nd : " + map);*/
//第二种
for(Iterator<Map.Entry<Student,String>> car = map.entrySet().iterator();car.hasNext();){
Map.Entry<Student,String> e = car.next(); if("晖晖".equals(e.getKey().name)){ car.remove(); } } System.out.println("2nd : " + map); //3rd.嵩song嵩过生日了 已经28岁了 修改收录的年龄信息 一种做法 Map<Student,String> temp = new HashMap<>();//暂存不需要排序,所以不需要用TreeMap for(Iterator<Map.Entry<Student,String>> car = map.entrySet().iterator();car.hasNext();){ Map.Entry<Student,String> e = car.next();
Student s = e.getKey(); String v = e.getValue();
//一定要在remove()之前用e.getKey() e.getValue()
car.remove();
s.age = 28;
temp.put(s,v);
}
}
map.putAll(temp);
System.out.println("3rd : " + map);
//4th.泰安市发展迅速 电话号码升位 开头+8
//这里不需要删除,所以可以用foreach遍历
for(Iterator<Map.Entry<Student,String>> car = map.entrySet().iterator();car.hasNext();){
Map.Entry<Student,String> e = car.next();
if(s.startsWith("0538")){
e.setValue("0538-8" + s.substring(s.indexOf("-") + 1));
}
}
System.out.println("4th : " + map);
//5th.请显示所有居住在济南的学生姓名
//横向切片之后foreach int count = 0;
for(Iterator<Map.Entry<Student,String>> car =
map.entrySet().iterator();car.hasNext();){
Map.Entry<Student,String> e = car.next();
if(e.getValue().startsWith("0531")){
count++;
System.out.println((count == 1 ? "5th : 居住在济南的学生有 ": " ")+ e.getKey().name + "-" + e.getKey().age + "岁");
}
}
//6th.打印所有同学所在的城市
//这道题应该用Map、学任何技术的技术要问问自己什么场景我要用它,不然迟早要忘掉,一定要知道啥时候用它
Map<String,String> newMap = new HashMap<>();
newMap.put("0531","济南");
newMap.put("0532","青岛");
newMap.put("0538","泰安");
for(Iterator<Map.Entry<Student,String>> car = map.entrySet().iterator();
car.hasNext();){
Map.Entry<Student,String> e = car.next();
Student k = e.getKey();
String v = e.getValue();
String num = v.substring(0,v.indexOf("-"));
System.out.println(k.name + "居住地" + newMap.get(num));
}
//7th.所有年龄低于25岁的同学 改用昵称 小X
System.out.println(map);
Map<Student,String> tempMap = new HashMap<>();
for(Iterator<Map.Entry<Student,String>> car = map.entrySet().iterator();
car.hasNext();){
Map.Entry<Student,String> e = car.next();
if(e.getKey().age < 25){
Student s = e.getKey();
//一定要在remove()之前赋值给s,否则打印结果会出错
String v = e.getValue();
car.remove(); s.name = "小" + s.name.charAt(0);
}
}
map.putAll(tempMap);
System.out.println("7th : " + map);
}
class Student{
String name; int age; public Student(String name,int age){
this.name = name; this.age = age;
@Override
public String toString(){
return name + ":" + age;
}
//这个规则要求 先按名字排序 名字相同按照年龄
//名字年龄都相同 则按照先来后到的顺序
}
class MyComparator implements Comparator<Student>{
@Override
public int compare(Student s1,Student s2){
if(!s1.name.equals(s2.name))return s1.name.compareTo(s2.name);
//这里的compare方法始终不返回0,也就是无法认定相等,所以remove() get() containsKey()无法操作
}
}
在要遍历Map时,考虑如下两步即可: //第一步:需求涉及到用那种刀法,用左半还是右半 //第二步:需要执行删除操作么,不需要的话用foreach 需要删除的话用Iterator

















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









