







机器学习中的正则化是一种为了减小测试误差的行为。我们在搭建机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当用比较复杂的模型(比如神经网络)去拟合数据时,很容易出现过拟合现象,这会导致模型的泛化能力下降,这时候我们就需要使用正则化技术去降低模型的复杂度,从而改变模型的拟合度。
1. 过拟合的问题
正则化可以改善或者减少过度拟合的问题。
过拟合的问题就是指我们有非常多的特征,通过学习得到的模型能够非常好地适应训练集(代价函数可能几乎为0),但是推广到新的数据集上效果会非常的差。
图1是一个回归问题的例子:
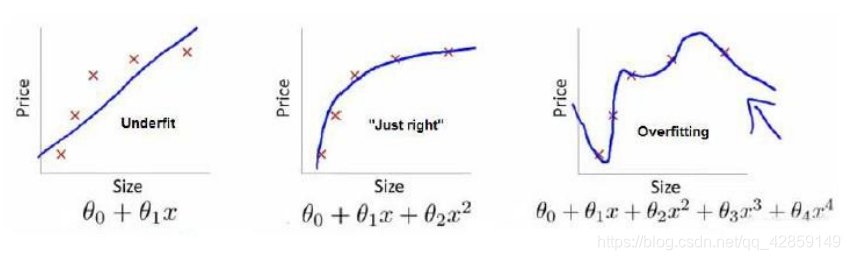
图1中 a)对应的模型是一个线性模型,欠拟合(Underfitting),不能很好地适应我们的训练集;
图1中 c)对应的模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质——预测新数据。我们可以看出,若给出一个新的值让其预测,它将表现的很差,是过拟合(Overfitting),虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;
图1中 b)对应的模型的模型似乎最合适("Just right "),所以其泛化能力将会最好。
分类问题中也存在这样的问题,如图2所示。
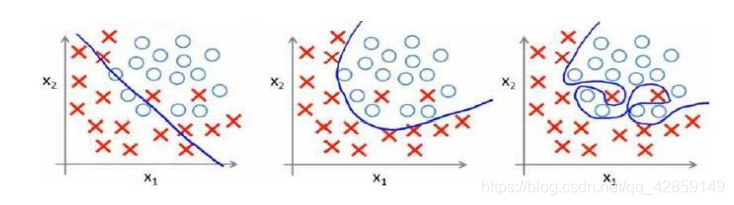
如果我们发现了过拟合问题,应该如何解决?
1.丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA);
2.正则化。 保留所有的特征,但是减少参数的大小。
2. 代价函数
发生过拟合时,我们通过在代价函数中增加惩罚项来防止过拟合:
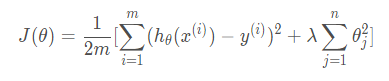
其中
λ
\lambda
λ 又称为正则化参数 (Regularization Parameter)。根据惯例,我们不对
θ
0
\theta_{0}
θ0 项进行惩罚。

如果选择的正则化参数
λ
\lambda
λ 过大,则会把所有的参数都最小化了, 导致模型变成
h
θ
(
x
)
=
θ
0
h_{\theta}(x)=\theta_{0}
hθ(x)=θ0, 也就是图3中红色直线所示的情况,造成欠拟合。
那为什么增加一项
λ
∑
j
=
1
n
θ
j
2
\lambda \sum_{j=1}^{n} \theta_{j}^{2}
λ∑j=1nθj2 可以使
θ
\theta
θ 的值减小呢?
因为如果我们令
λ
\lambda
λ 的值很大的话, 为了使代价函数
J
(
θ
)
J(\theta)
J(θ) 尽可能的小,所有的
θ
\theta
θ 的值
(
\left(\right.
( 不包括
θ
0
\theta_{0}
θ0 ) 都会在一定程度上减小。 但若
λ
\lambda
λ 的值太大了,那么
θ
\theta
θ 的值
(
\left(\right.
( 不包括
θ
0
)
\left.\theta_{0}\right)
θ0) 都会趋近于0,这样我们所得到的只能是一条平行于
x
x
x轴的直线。所以对于正则化,我们要取一个合理的
λ
\lambda
λ 值,这样才能更好的应用正则化。
3. 线性回归的正则化
正则化线性回归的代价函数为:
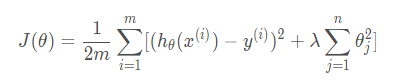
对于线性回归在代价函数最小时参数
θ
θ
\theta θ
θθ的求解,我们之前推导了两种学习算法:一种基于梯度下降,一种基于正规方程。
- 梯度下降
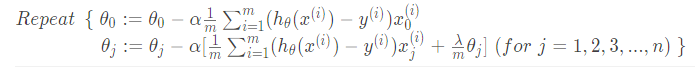
对上面的算法中 j = 1 , 2 , 3 , . . . , n 时的更新式子进行调整可得:
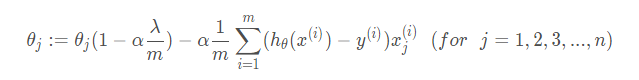
其中, 1 − α λ m 1-\alpha \frac{\lambda}{m} 1−αmλ 是一个略小于1的数。可以看出,当我们进行正则化线性回归时,我们要做的就是每次迭代时都将 θ j \theta_{j} θj 乘以一个略小于1的数,每次都把参数缩小一点,然后进行和之前一样的更新操作。 - 正规方程 使用正规方程来求解正则化线性回归模型:
θ = ( X T X + λ [ 0 1 1 ⋱ 1 ] ) − 1 X T y \theta=\left(X^{T} X+\lambda\left[\begin{array}{lllll} 0 & & & & \\ & 1 & & & \\ & & 1 & & \\ & & & \ddots & \\ & & & & 1 \end{array}\right]\right)^{-1} X^{T} y θ=⎝⎜⎜⎜⎜⎛XTX+λ⎣⎢⎢⎢⎢⎡011⋱1⎦⎥⎥⎥⎥⎤⎠⎟⎟⎟⎟⎞−1XTy
其中, X = [ ( x ( 1 ) ) T ⋯ ( x ( m ) ) T ] , y = [ y ( 1 ) ⋯ y ( m ) ] X=\left[\begin{array}{c}\left(x^{(1)}\right)^{T} \\ \cdots \\ \left(x^{(m)}\right)^{T}\end{array}\right], y=\left[\begin{array}{c}y^{(1)} \\ \cdots \\ y^{(m)}\end{array}\right] X=⎣⎢⎡(x(1))T⋯(x(m))T⎦⎥⎤,y=⎣⎡y(1)⋯y(m)⎦⎤ 。
4. Logistic回归的正则化
正则化Logistic回归的代价函数为
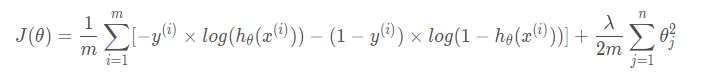
对于Logistic回归在代价函数最小时参数
θ
θ
θ的求解,我们之前学习过两种优化算法:首先学习了使用梯度下降法来优化代价函数
J
(
θ
)
J(\theta)
J(θ) ,然后学习了更高级的优化算法,这些高级优化算法需要我们自己设计代价函数
J
(
θ
)
J(\theta)
J(θ)。
- 梯度下降
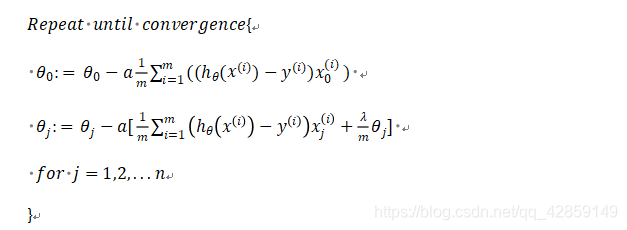
虽然其看上去同线性回归一样,但是Logistic回归的 h θ ( x ) = g ( θ T X ) h_{\theta}(x)=g\left(\theta^{T} X\right) hθ(x)=g(θTX), 所以与线性回归不同。 - 高级优化算法
需要自己设计代价函数 J ( θ ) J(\theta) J(θ) 。














 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









