







吴恩达机器学习教程学习笔记 (5/16)
吴恩达教授(Andrew Ng)的机器学习可以说是一门非常重视ML理论基础的课程,做做一些简单的笔记加上个人的理解。本笔记根据吴恩达的课程顺序,以每章内容作为节点进行记录。(共18章,其中第3章“线性代数回顾”与第5章“Octava教程”的笔记就不总结了)
第七章 正则化(Regularization)
1、过拟合的问题
如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集(代价函数可能几乎为0),但是可能会不能推广到新的数据。
例子
下图是一个回归问题:
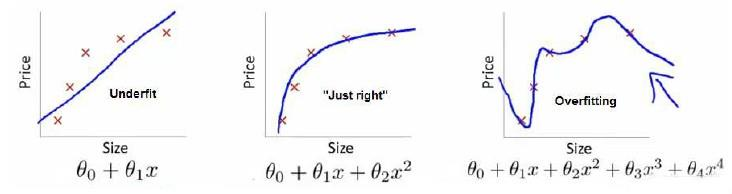
第一个模型是一个线性模型:欠拟合,不能很好地适应我们的训练集;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合。虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
下图是一个分类问题:

就以多项式理解,x 的次数越高,拟合的越好,但相应的预测的能力就可能变差。
如果我们发现了过拟合问题,可以利用正则化的手段来处理。
2、代价函数
回归问题中如果我们的模型是:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
2
+
θ
3
x
3
3
+
θ
4
x
4
4
h θ (x) = θ_0 + θ_1 x_1 + θ_2 x_2^2 + θ_3 x_3^3 + θ_4 x_4^4
hθ(x)=θ0+θ1x1+θ2x22+θ3x33+θ4x44
我们可以从之前的事例中看出,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于 0 的话,就能很好的拟合了。
所以要做的就是在一定程度上减小这些参数θ的值,这就是正则化的基本方法。我们决定要减少θ3和θ4的大小,我们要做的便是修改代价函数,在其中θ3和θ4设置一点惩罚。这样做的话,我们在尝试最小化代价时也需要将这个惩罚纳入考虑中,并最终导致选择较小一些的θ3和θ4 。
修改后的代价函数如下:
m
i
n
θ
1
/
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
1000
θ
3
2
+
10000
θ
4
2
]
min_θ 1/2m [∑^m _{i=1}(h_θ(x^{(i)}) - y^{(i)})^2 + 1000θ^2_3 + 10000θ^2_4]
minθ1/2m[i=1∑m(hθ(x(i))−y(i))2+1000θ32+10000θ42]
通过这样的代价函数选择出的θ3和θ4对预测结果的影响就比之前要小许多。假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。这样的结果是得到了一个较为简单的能防止过拟合问题的假设:
J
(
θ
)
=
1
/
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
J(θ) = 1/2m [∑^m _{i=1}(h_θ(x^{(i)}) - y^{(i)})^2+λ ∑^n_{j=1}θ^2_j]
J(θ)=1/2m[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]其中λ又称为正则化参数(Regularization Parameter)。
注:根据惯例,我们不对θ0进行惩罚。经过正则化处理的模型与原模型的可能对比如下图所示:

如果选择的正则化参数 λ 过大,则会把所有的参数都最小化了,导致模型变成
h
θ
(
x
)
=
θ
0
h_θ (x) =θ_0
hθ(x)=θ0 ,也就是上图中红色直线所示的情况,造成欠拟合。
但如果我们令 λ 的值很大的话,为了使 Cost Function 尽可能的小,所有θ的值(不包括θ0)都会在一定程度上减小。
所以对于正则化,我们要取一个合理的 λ 的值,这样才能更好的应用正则化。
3、正则化线性回归
正则化线性回归的代价函数为:
J
(
θ
)
=
1
/
2
m
∑
i
=
1
m
[
(
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
)
]
J(θ) = 1/2m ∑^m_{i=1}[((h_θ(x^{(i)}) - y^{(i)})^2+λ ∑^n_{j=1}θ^2_j)]
J(θ)=1/2mi=1∑m[((hθ(x(i))−y(i))2+λj=1∑nθj2)]如果我们要使用梯度下降法令这个代价函数最小化,因为我们未对进行正则化,所以梯度下降算法将分两种情形:
Repeat until convergence{
θ
0
:
=
θ
0
−
a
/
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
−
y
(
i
)
)
)
x
0
(
i
)
θ_0 : = θ_0 − a/m ∑^m_{i=1}(h_θ(x^{(i)}-y^{(i)}))x^{(i)}_0
θ0:=θ0−a/mi=1∑m(hθ(x(i)−y(i)))x0(i)
θ
j
:
=
θ
j
−
a
[
1
/
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
−
y
(
i
)
)
)
x
j
(
i
)
+
λ
/
m
θ
j
]
θ_j : = θ_j − a[1/m ∑^m_{i=1}(h_θ(x^{(i)}-y^{(i)}))x^{(i)}_j+λ/mθ_j]
θj:=θj−a[1/mi=1∑m(hθ(x(i)−y(i)))xj(i)+λ/mθj]
}
Repeat
对上面的算法中j = 1,2, . . . , n 时的更新式子进行调整可得:
θ
j
:
=
θ
j
(
1
−
a
λ
/
m
)
−
a
/
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
−
y
(
i
)
)
)
x
j
(
i
)
θ_j : = θ_j(1-aλ/m)-a/m ∑^m_{i=1}(h_θ(x^{(i)}-y^{(i)}))x^{(i)}_j
θj:=θj(1−aλ/m)−a/mi=1∑m(hθ(x(i)−y(i)))xj(i)可以看出,正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令θ值减少了一个额外的值。
4、正则化逻辑回归

给代价函数增加一个正则化的表达式,得到代价函数:
J
(
θ
)
=
1
/
m
∑
i
=
1
m
[
−
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
−
(
1
−
y
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
]
+
λ
/
2
m
∑
j
=
1
n
θ
j
2
J(θ)=1/m∑^m_{i=1}[-y^{(i)}log(h_θ(x^{(i)}))-(1-y)log(1-h_θ(x^{(i)}))]+λ/2m∑^n_{j=1}θ^2_j
J(θ)=1/mi=1∑m[−y(i)log(hθ(x(i)))−(1−y)log(1−hθ(x(i)))]+λ/2mj=1∑nθj2
Python代码实现:
import numpy as np
def costReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X*theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X*theta.T)))
reg = (learningRate / (2 * len(X))* np.sum(np.power(theta[:,1:the
ta.shape[1]],2))
return np.sum(first - second) / (len(X)) + reg
要最小化该代价函数,通过求导,得出梯度下降算法为:
Repeat until convergence{
θ
0
:
=
θ
0
−
a
/
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
−
y
(
i
)
)
)
x
0
(
i
)
θ_0 : = θ_0 − a/m ∑^m_{i=1}(h_θ(x^{(i)}-y^{(i)}))x^{(i)}_0
θ0:=θ0−a/mi=1∑m(hθ(x(i)−y(i)))x0(i)
θ
j
:
=
θ
j
−
a
[
1
/
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
−
y
(
i
)
)
)
x
j
(
i
)
+
λ
/
m
θ
j
]
θ_j : = θ_j − a[1/m ∑^m_{i=1}(h_θ(x^{(i)}-y^{(i)}))x^{(i)}_j+λ/mθ_j]
θj:=θj−a[1/mi=1∑m(hθ(x(i)−y(i)))xj(i)+λ/mθj]for j = 1,2,…n
}
注:看上去同线性回归一样,但是
h
θ
(
x
)
=
g
(
θ
T
X
)
h_θ (x) = g(θ^TX)
hθ(x)=g(θTX),所以与线性回归不同。
感谢黄海广博士团队的翻译和笔记
END














 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









