







一、防止过度拟合
过度拟合问题:
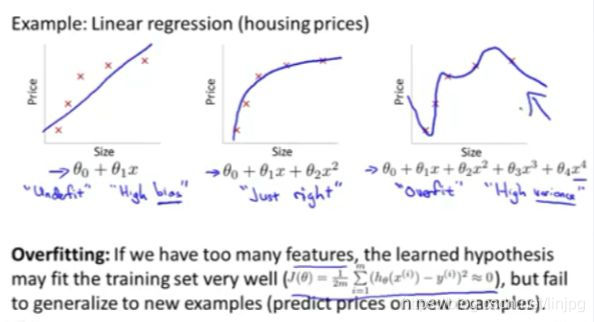
例如:那个用线性回归来预测房价的例子,我们通过建立以住房面积为自变量的函数来预测房价,我们可以对该数据做线性回归,以下为三组数据做线性拟合的结果:
①第一个图我们用直线去拟合,这不是一个很好的模型。
我们看看这些数据,很明显,随着房子面积增大,住房价格的变化应趋于稳定,或者越往右越平缓。
因此该算法没有很好拟合训练数据,我们把这个问题称为欠拟合(underfitting),这个问题的另一个术语叫做高偏差(bias) 。
②第二个图我们用二次函数来拟合它,这个拟合效果很好 。
③第三个图我们拟合一个四次多项式,因此在这里我们有五个参数 θ0到θ4 这样我们可以拟合一条曲线,通过我们的五个训练样本,你可以得到看上去如此的一条曲线。
这条回归直线似乎对训练数据做了一个很好的拟合,因为这条曲线通过了所有的训练实例。但是这仍然是一条扭曲的曲线。事实上,我们并不认为它是一个预测房价的好模型。
所以 这个问题我们把他叫做过度拟合或过拟合(overfitting),另一个描述该问题的术语是高方差(variance)。 高方差是另一个历史上的叫法,但是从第一印象上来说,如果我们拟合一个高阶多项式,那么这个函数能很好的拟合训练集,能拟合几乎所有的训练数据。这就面临可能函数太过庞大的问题、变量太多。
如果我们没有足够的数据去约束这个变量过多的模型 那么这就是过度拟合。
概括地说:过度拟合的问题,将会在变量过多的时候,发生这种时候训练出的方程总能很好的拟合训练数据。所以你的代价函数实际上可能非常接近于0或者就是0。 但是这样的曲线,它千方百计的拟合于训练数据,这样导致它无法泛化到新的数据样本中,以至于无法预测新样本价格。
在这里术语"泛化" 指的是一个假设模型能够应用到新样本的能力,新样本数据是没有出现在训练集中的房子。
在上图中,我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











