







 本文介绍了如何在Java中使用Es进行全文检索,包括时间范围查询、多字段高亮处理、Trans接口的使用以及如何处理EsMap转对象的复杂映射。作者详细展示了如何实现高亮文本略缩处理,避免了numOfFragments和fragmentSize参数可能带来的问题。
本文介绍了如何在Java中使用Es进行全文检索,包括时间范围查询、多字段高亮处理、Trans接口的使用以及如何处理EsMap转对象的复杂映射。作者详细展示了如何实现高亮文本略缩处理,避免了numOfFragments和fragmentSize参数可能带来的问题。
如何实现 Es 全文检索、高亮文本略缩处理
前言
最近手上在做 Es 全文检索的需求,类似于百度那种,根据关键字检索出对应的文章,然后高亮显示,特此记录一下,其实主要就是处理 Es 数据那块复杂,涉及到高亮文本替换以及高亮字段截取,还有要考虑到代码的复用性,是否可以将转换代码抽离出来,提供给不同结构的索引来使用。
技术选型
像市面上有的 Spring Data,码云上面的 GVP 项目 (EasyEs)等其他封装框架。使用起来确实很方便,但是考虑到由于开源项目的不稳定性且 Es 不同版本间语法差异比较大,还有一方面是公司之前用的一直是 Es 6,后续可能会涉及到 Es 的升级改造,于是决定使用原生的 Api。也就是使用 RestHighLevelClient。
JAVA 常用语法说明
查时间范围内的数据 BoolQuery 里面嵌套一个 RangeQuery 即可在RangeQuery 里面指定时间范围。BoolQuery.must() 各位理解为 Mybatis 中的 eq 方法即可,必须包含的意思。
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery(articleRequest.getSortType());
if (StringUtils.isNotEmpty(articleRequest.getBeginTime())) {
rangeQuery.gte(articleRequest.getBeginTime());
}
if (StringUtils.isNotEmpty(articleRequest.getEndTime())) {
rangeQuery.lte(articleRequest.getEndTime());
}
boolQuery.must(rangeQuery);
BoolQuery.should() 方法可以理解为 OR 可包含可不包含,多字段全文检索时应用 shoud。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));
termsQuery 字符精确匹配
QueryBuilders.termsQuery()
字符短句匹配,字符不会进行分词
QueryBuilders.matchPhraseQuery()
分词匹配
QueryBuilders.multiMatchQuery()
分词匹配加高亮对应 EQ(Es 的Sql,我自己给他取的名字!!!!)
GET /articlezzh/_doc/_search
{
"from": 0,
"size": 20,
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "你的购物节",
"fields": [
"title","author","body"
]
}
}
]
}
},
"highlight": {
"pre_tags": [
"<em style='color: red'>"
],
"post_tags": [
"</em>"
],
"fields": {
"body":{},
"author":{}
}
}
}
全文检索开发
核心代码如下
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
if (StringUtils.isNotEmpty(articleRequest.getKeyword())) {
for (int i = 0; i < articleRequest.getKeys().length; i++) {
//根据短句匹配
boolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));
}
}
高亮开发
里面可以指定高亮的字段,以及高亮前缀,尾缀,API的调用,直接 copy 就行。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.highlighter(new HighlightBuilder()
.requireFieldMatch(false)
.field("author")
.field("title")
.field("body")
.field("attachments.filename")
.preTags(EsConstant.HIGHT_PREFIX)
.postTags(EsConstant.HIGHT_END)
//noMatchSize
//返回全部内容,方便后续的截取字符串操作
.fragmentSize(800000)
.numOfFragments(0))
//过滤数据(最少满足一个 should 条件的数据才会被展示,否则过滤)
.query(boolQuery.minimumShouldMatch(1))
.from(articleRequest.getPage() - 1)
.size(articleRequest.getSize());
Es Map 转对象使用
由于索引结构是已 ArticleResponse 格式存储的,查询的时候也需将的得到 SourceAsMap 转换成 ArticleResponse 格式,核心逻辑我都封装到 Trans 接口了。利用反射实现的,当然也可以用其他技术实现,例如 MapStruct 在编译期间就自动生成对应的 get、set 方法,比反射效率高点,毕竟反射是运行期间的属性映射!!!!
SearchHits hits = restHighLevelClient.search(
new SearchRequest().indices(indexname).source(searchSourceBuilder)).getHits();
for (SearchHit hit : hits) {
result.add(new ArticleResponse().trans(hit.getSourceAsMap(),
hit.getHighlightFields(),
Collections.singletonList("attachments.filename")));
使用的话只需让 ArticleResponse 类实现 Trans 接口,即可调用里面的 trans 方法。

核心代码 Trans 接口(支持父类属性的复杂映射)
主要逻辑就是挨个拿到本身、然后递归获取父类的所有字段名称、字段类型放到一个 Map(nameTypeMap) 中,然后遍历 SourceAsMap 挨个进行字段类型匹配校验,如果是 String 类型直接进行反射填充属性。

非 String 类型,进行类型转换然后再进行属性填充。
以及高亮字段文本略缩的处理,主要就是用了下 Jsoup 中去除 Html 标签的 Api,本来想着让前端自己去找插件看能不能处理下的,无奈说处理不了,想了个取巧的方法,高亮标签我用特殊字符,然后去除所有的 html 标签后,我的特殊字符还存在,之后将特殊字符再次替换回高亮 Html 标签,这样就得到了只存在我自定义高亮 Html 标签的一段文本了,同时高亮标签里面我塞了一个 id,之后根据高亮标签中的 id 截取字符即可,即可实现文本略缩的效果,同事直呼秒啊哈哈哈哈

/**
* map 转对象
* author:zzh
*/
public interface Trans<T> {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Class getTargetClass();
/**
* 逻辑写的太多了,可以搞几个抽象类抽分功能
*
* @param SourceAsMap 原始数据
* @param highlightFieldsSource 高亮数据
* @param highLightFields 高亮字段
*/
default Object trans(Map<String, Object> SourceAsMap, Map<String, HighlightField> highlightFieldsSource, List<String> highLightFields) throws IntrospectionException, InstantiationException, IllegalAccessException {
Object o = getTargetClass().newInstance();
Class tclass = getTargetClass();
HashMap<String, Class> nameTypeMap = new HashMap<>();
//找到父类的所有字段
do {
Arrays.stream(tclass.getDeclaredFields()).forEach(field -> {
field.setAccessible(true);
//key:字段名称,value:字段类型
nameTypeMap.put(field.getName(), field.getType());
});
tclass = tclass.getSuperclass();
} while (!tclass.equals(Object.class));
PropertyDescriptor[] propertyDescriptors = Introspector.getBeanInfo(o.getClass()).getPropertyDescriptors();
Arrays.stream(propertyDescriptors).forEach(propertyDescriptor -> {
if (!"targetClass".equals(propertyDescriptor.getName()) && !Objects.isNull(SourceAsMap.get(propertyDescriptor.getName()))) {
try {
Method writeMethod = propertyDescriptor.getWriteMethod();
if (null != writeMethod) {
if (!Modifier.isPublic(writeMethod.getDeclaringClass().getModifiers())) {
writeMethod.setAccessible(true);
}
Object sourceValue = SourceAsMap.get(propertyDescriptor.getName());
//父类以及自己所有字段类型
Class aClass = nameTypeMap.get(propertyDescriptor.getName());
//String 类型以及高亮直接赋值
if (sourceValue.getClass().equals(aClass)) {
HighlightField highlightObject = highlightFieldsSource.get(propertyDescriptor.getName());
//如果高亮字段是 body,为了避免高亮文本处于文章末尾搜索页显示不到的问题,因此采用截取字符串将高亮字段偏移至前面
if (EsConstant.HIGHT_FILED.equals(propertyDescriptor.getName()) && null != highlightObject) {
String highlightString = highlightObject.getFragments()[0].toString();
//去除所有 html 标签,并将自定义高亮前缀替换 span 标签,这样就实现了只保留高亮标签的目的了
highlightString = Jsoup.parse(highlightString).body().text()
.replaceAll(EsConstant.HIGHT_PREFIX, EsConstant.HIGHT_PREFIX_HTML)
.replaceAll(EsConstant.HIGHT_END, EsConstant.HIGHT_END_HTML);
//高亮字段前 50 个字到文章末尾
highlightString = highlightString.substring((highlightString.indexOf(EsConstant.HIGHT_HTML_ID) - EsConstant.HIGHT_SIZE) < 0
? 0 : (highlightString.indexOf(EsConstant.HIGHT_HTML_ID) - EsConstant.HIGHT_SIZE));
writeMethod.invoke(o, highlightObject != null ? highlightString : SourceAsMap.get(propertyDescriptor.getName()));
} else if (EsConstant.HIGHT_FILED.equals(propertyDescriptor.getName()) && null == highlightObject) {
//非高亮的 body 字段,也去除下 Html 标签
writeMethod.invoke(o, Jsoup.parse(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))).body().text());
} else {
//非 body 的其他高亮字段正常替换高亮文本
writeMethod.invoke(o, highlightObject != null ? highlightObject.getFragments()[0].toString()
.replaceAll(EsConstant.HIGHT_PREFIX, EsConstant.HIGHT_PREFIX_HTML)
.replaceAll(EsConstant.HIGHT_END, EsConstant.HIGHT_END_HTML) : SourceAsMap.get(propertyDescriptor.getName()));
}
}
/**
* 类型不一致强转,这里可以搞个策略模式优化优化
*/
else {
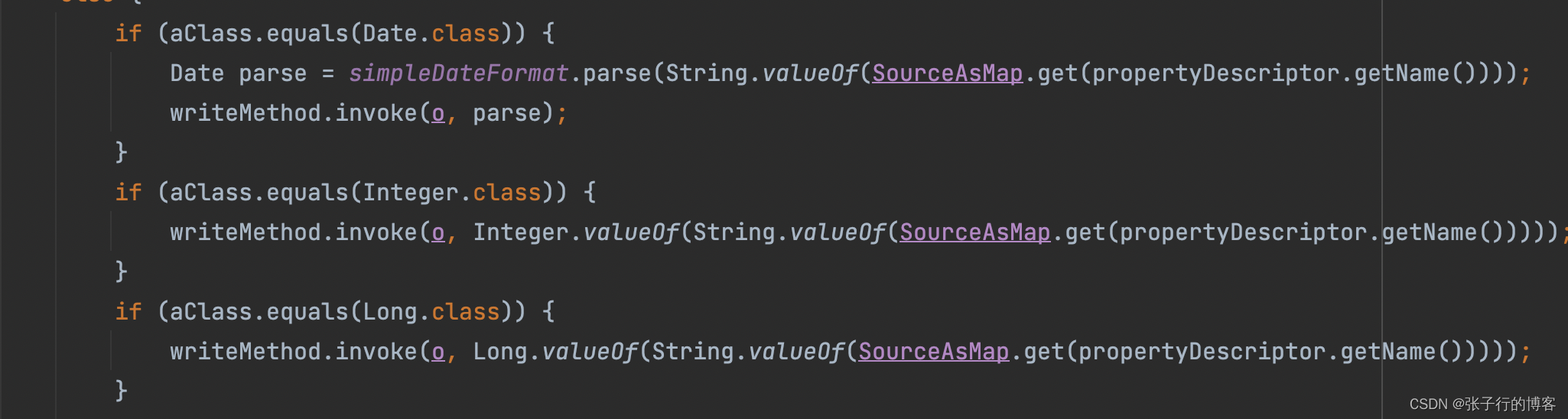
if (aClass.equals(Date.class)) {
Date parse = simpleDateFormat.parse(String.valueOf(SourceAsMap.get(propertyDescriptor.getName())));
writeMethod.invoke(o, parse);
}
if (aClass.equals(Integer.class)) {
writeMethod.invoke(o, Integer.valueOf(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))));
}
if (aClass.equals(Long.class)) {
writeMethod.invoke(o, Long.valueOf(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))));
}
if (aClass.equals(List.class)) {
//获取指定属性的 List
ArrayList<Map<String, Object>> oraginSources = (ArrayList<Map<String, Object>>) SourceAsMap.get(propertyDescriptor.getName());
//复杂对象高亮字段映射
if (null != oraginSources && 0 != highlightFieldsSource.size()) {
for (int i = 0; i < oraginSources.size(); i++) {
for (int j = 0; j < highLightFields.size(); j++) {
try {
if (highlightFieldsSource.containsKey(highLightFields.get(j))) {
oraginSources.get(i).put(highLightFields.get(j).split("\\.")[1],
highlightFieldsSource.get(highLightFields.get(j)).getFragments()[j].toString()
.replaceAll(EsConstant.HIGHT_PREFIX, EsConstant.HIGHT_PREFIX_HTML)
.replaceAll(EsConstant.HIGHT_END, EsConstant.HIGHT_END_HTML));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
writeMethod.invoke(o, oraginSources);
}
if (aClass.equals(int.class)) {
writeMethod.invoke(o, Integer.parseInt(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))));
}
}
} else throw new RuntimeException(propertyDescriptor.getName() + "~ writeMethod is null!!!!!");
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
});
return o;
}
}
Trans 接口可优化的点
- 优化点一:策略模式扩展多数据类型转换那部分的代码,这里就不贴出来了。
- 优化点二:支持多高亮字段略缩处理,也就是将这行代码改成 List 集合判断,但是我感觉没必要,一个字段略缩就够用了。
EsConstant.HIGHT_FILED.equals(propertyDescriptor.getName())
- 配置文件也可以用策略模式,或者利用 Spi 机制动态加载。(针对项目要开源的情况下说的),这块的内容可以看我以往写过的 Spi 文章。
- 可以搞个文章内容里面涉及到关键字的地方就略缩一下,举个例子,查(地瓜)的时候,返回的数据是这样的( …地瓜…地瓜),而现在的效果是(地瓜…),希望别让我改!!!!我觉得我现在这样也够用了。
- 代码逻辑再次解耦,可以利用抽象类的性质,按照功能细分职责,毕竟很多框架源码就是这么干的,一堆的抽象类封装通用逻辑
高亮全局配置类如下
为了方便后期维护,将用到的配置封装了一下,大家可自行替换用 Nacos 配置中心也好,还是用枚举类也好,修改一下代码即可
public class EsConstant {
//高亮前缀唯一 id,可自行定义
public static String HIGHT_PREFIX = "zzhSatat";
//高亮尾缀唯一 id,可自行定义
public static String HIGHT_END = "zzhEnd";
//高亮尾缀
public static String HIGHT_END_HTML = "</span>";
//高亮标签 id,可自行定义
public static String HIGHT_HTML_ID = "zzh";
//截取高亮字段前字符串长度
public static int HIGHT_SIZE = 50;
//高亮前缀
public static String HIGHT_PREFIX_HTML = "<span style='color:red',id='" + HIGHT_HTML_ID + "'>";
//略缩字段
public static String HIGHT_FILED = "body";
}
真实项目落地效果

复杂对象高亮字段替换效果
为什么不用 numOfFragments、fragmentSize 参数控制略缩?
数据库中的文章内容直接存的 Html 页面,用这俩参数截取字符串的话,截取到的文本会含残缺的 Html 标签,效果直接 Pass,当然对于纯文本类型的字段可以用这俩个参数进行控制,不用写截取字符串的逻辑!


















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











