







 本文详细解析了线程池组件(核心线程、最大线程、阻塞队列)的作用,重点讲解了keepAliveTime的含义和在实际场景中的应用。通过实例说明了线程池的运行流程和调优策略,包括并发处理能力、拒绝策略触发时机以及空闲线程的管理。
本文详细解析了线程池组件(核心线程、最大线程、阻塞队列)的作用,重点讲解了keepAliveTime的含义和在实际场景中的应用。通过实例说明了线程池的运行流程和调优策略,包括并发处理能力、拒绝策略触发时机以及空闲线程的管理。
线程池调优,深入理解,线程池各个参数的含义(keepAliveTime 展开说说?)目录
ThreadPoolExecutor,多线程并发利器

线程池核心组件
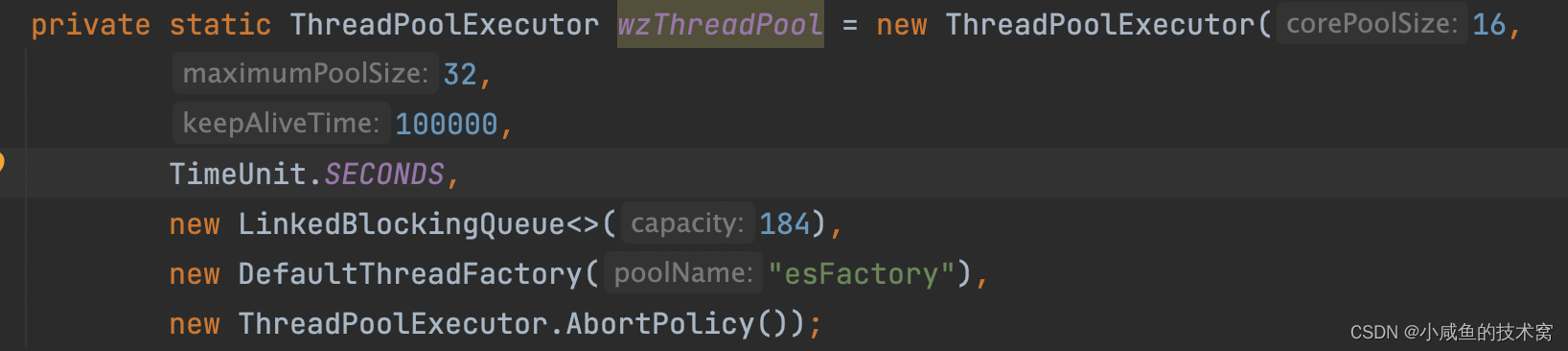
- 拒绝策略:没啥好说的拒绝策略字面理解,大家都知道,就是任务被线程池拒绝后的处理策略,但是 拒绝策略生效时机是在什么时候?,一问这个可能很多人就不知道了,接下来我结合我工作中真实业务举个例子,如下当时的线程池配置。核心线程 16,最大线程 32,有界阻塞队列 200,拒绝策略是抛出异常,空闲线程存活时间 100s。当时用这个线程池迁移老系统的数据来着,按照时间维度将 2007-2024 年每个月又拆成一个小维度,就有 216 个任务需要线程池来进行处理。需要保证数据完整性,因此每个任务都需要执行到!考虑到任务都是IO密集型,机器是 8 核的,因此核心线程设置 16,但是任务有 216 个完全不够用啊!换拒绝策略?没法处理的任务交给当前线程处理?机器吃不消,决定加大阻塞队列的长度,加到多少合适?1-16 个任务进行肯定先交给核心线程处理,16-200 的任务丢到阻塞队列(长度 184 正好够用,小于 184 直接会被拒绝),200-216 的任务交给空闲线程处理,因为当个任务处理时间长,为了避免线程切换带来的开销,空闲线程设置存活时间为 100s。
-
work:实现了 Runnable 的一个类,work 里面包了一个 thread,当 work 运行的时候本质会执行 work 类中的 run 方法。(说白了 work 就是正在干活的线程)
-
最大线程数:同时干活的 work 的最大个数
-
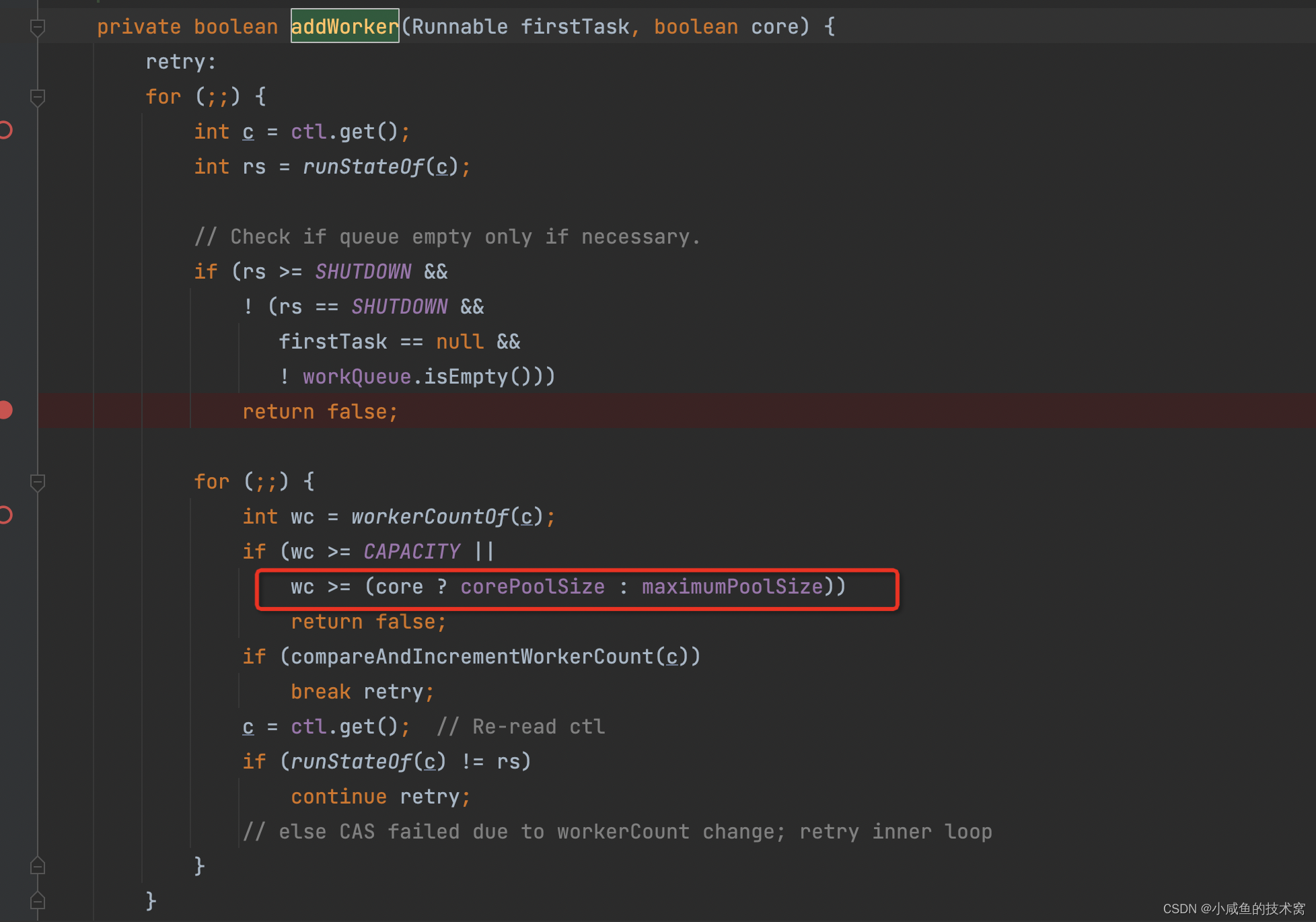
核心线程数:相当于守护进程的个数,核心干活的 work,带编制的 wrok。永远都不会被开除。源码如下
空闲线程数:最大线程数-核心线程数 = 可空闲的线程的最大数
核心线程、最大线程、阻塞队列的关系(重点)
先来讲一个小故事,在互联网还没发展的早期出现一个巨头公司,名字叫做小咸鱼牌小饼干(ThreadPoolExecutor),它里面每天有大量的任务需要处理(threadPoolExecutor.submit(new Task(i))),十分的缺人,现有的骨干完全不够用(核心线程数不够用)。加上有些外包进来的人员流动性大,离职后手上的工作也需要交接进行缓冲(BlockingQueue阻塞队列缓冲),为了让公司做大做强,很多核心骨干自高奋勇,主动去解决外包留下来的交接任务(核心线程做完自己的任务后,会去阻塞队列中拿任务执行),过了一段时间,骨干们吃不消了,开始每天骂骂咧咧的,公司看不下去了,想着去招聘点外包解决遗留下来的任务,招聘前先看看自己包里的经费够不够,发现经费够(阻塞队列满了、核心线程满了、空闲线程数还有位置),于是招了几个外包进来,咔嚓咔嚓的一顿弄,终于在外包、骨干的一顿努力下。遗留下来的交接任务干完了(阻塞队列中没任务了)。这个时候外包合同到期了(keepAliveTime到期),既然没活了,外包们就地解散,骨干留下就行。 妈的看完这个源码我直冒冷汗,难道这就是人生的底层逻辑吗。

简化版描述就是:核心线程满了,后续的任务会放到阻塞队列,阻塞队列满了后,会安排空闲线程处理任务,当空闲线程加核心线程的总数,大于了最大线程数时,将会触发拒绝策略
最大线程=核心线程+空闲线程 公司规模=骨干+外包
空闲线程产生的条件 = 核心线程满了、阻塞队列满了后,新来的 task 都会被新开的线程执行,新开一个线程的前提条件是:最大线程数 - 核心线程 > 0
线程池调优(运行流程)
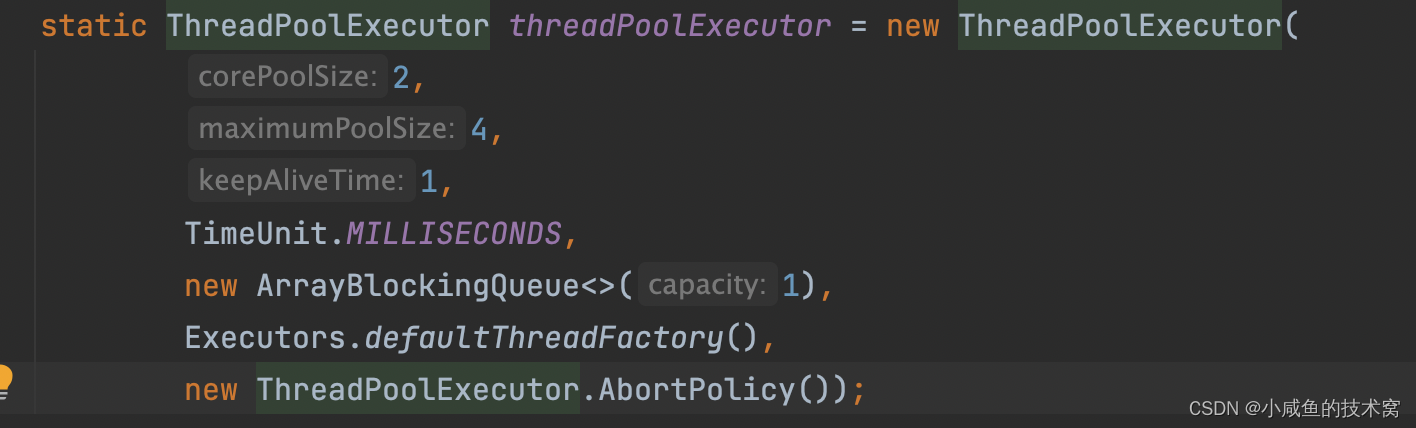
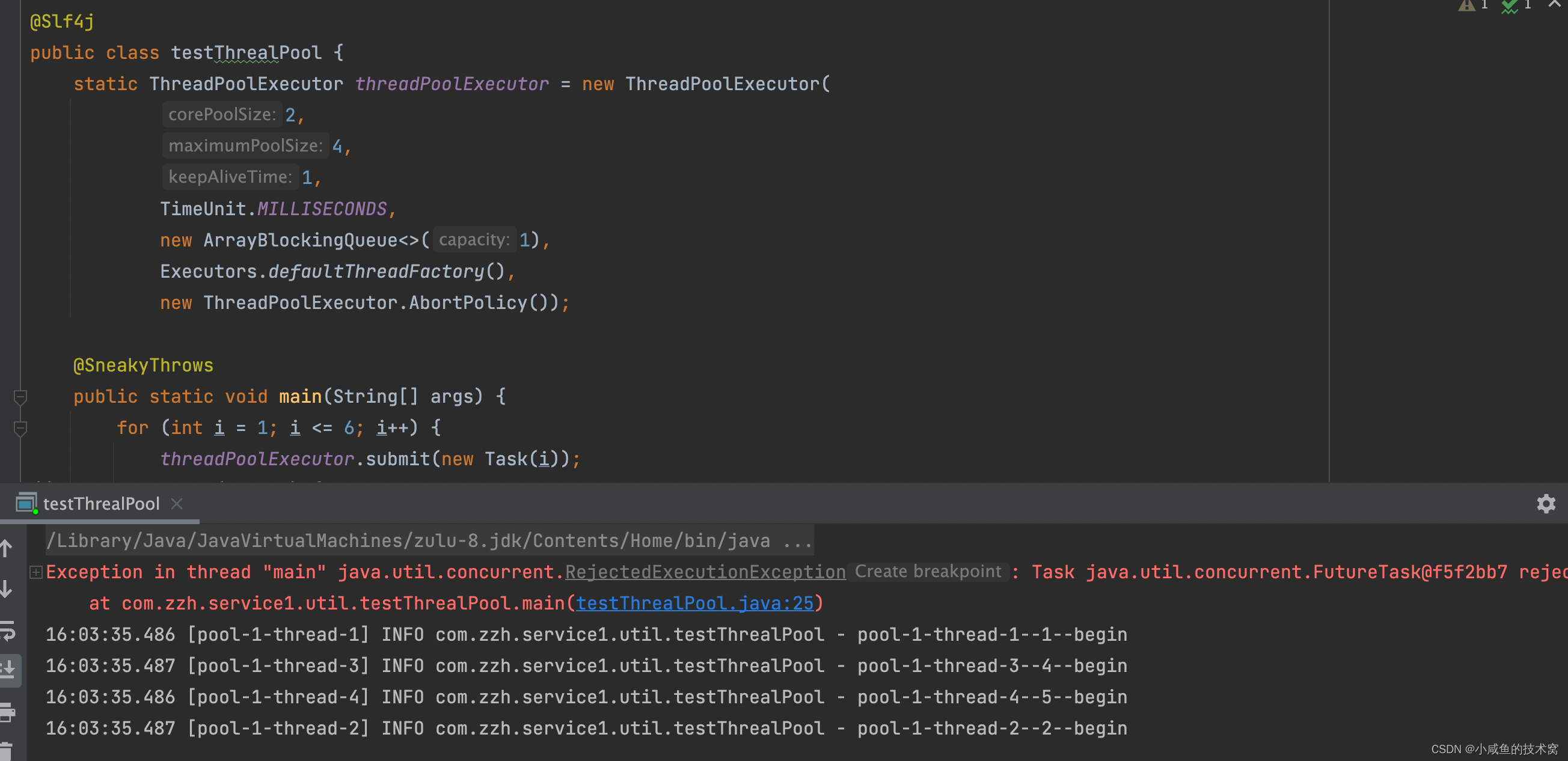
简单写一个如下线程池,根据你对线程池的理解,说说一说它能抗最大并发是多少?答案是可以顺时并发处理 5 个任务(超一个任务都会被拒绝)。但是只有 4 个线程去处理任务。还有一个任务在阻塞队列里面。
公式就是:线程池可瞬时处理的任务数量 = 最大线程数+阻塞队列长度
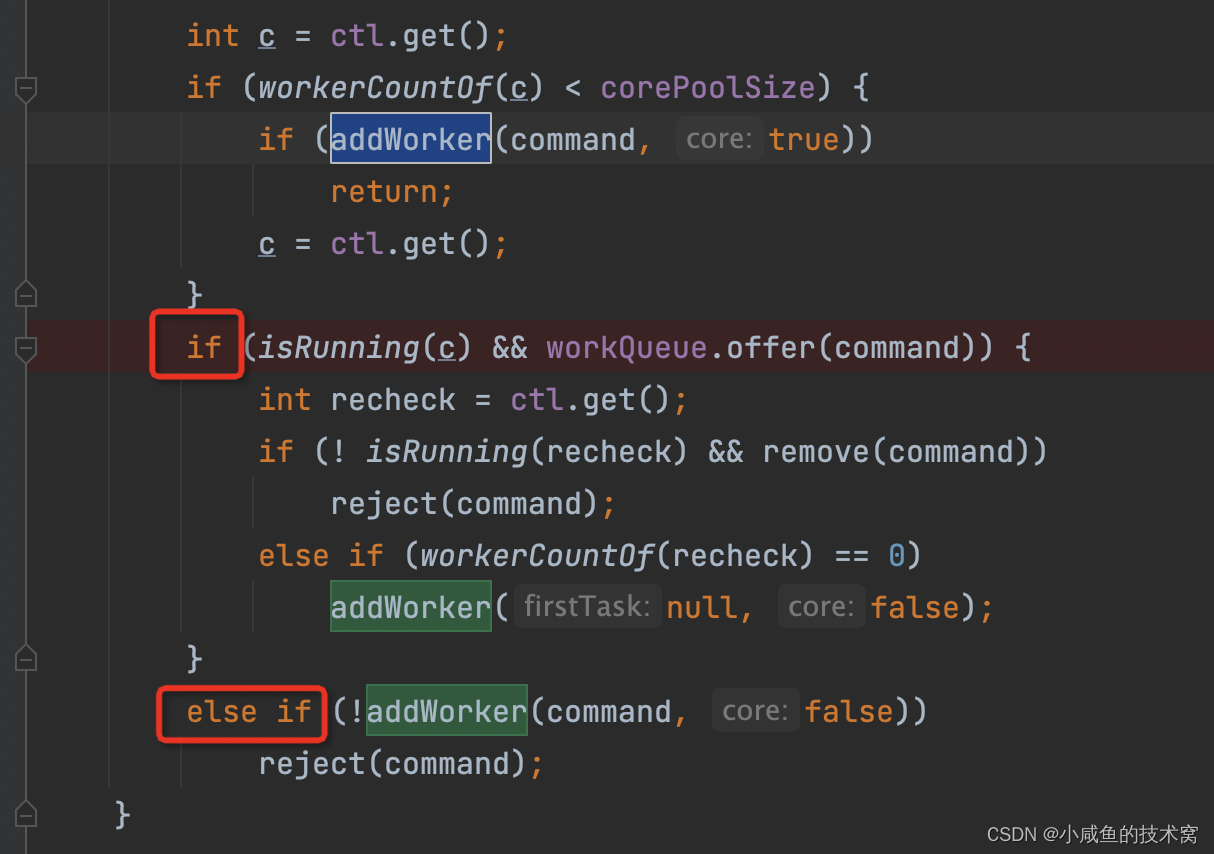
线程池可瞬时处理的任务数量 = 最大线程数+阻塞队列长度这个公式靠谱吗怎么来的?编写测试用例,发 6 个请求过来,可以看到有一个被拒绝了。就从这个请求被拒绝的流程来展开讲讲吧。
任务 1、2进来的时候被俩个核心线程处理,直接被 addWork 了,此时的工作线程数是 2。
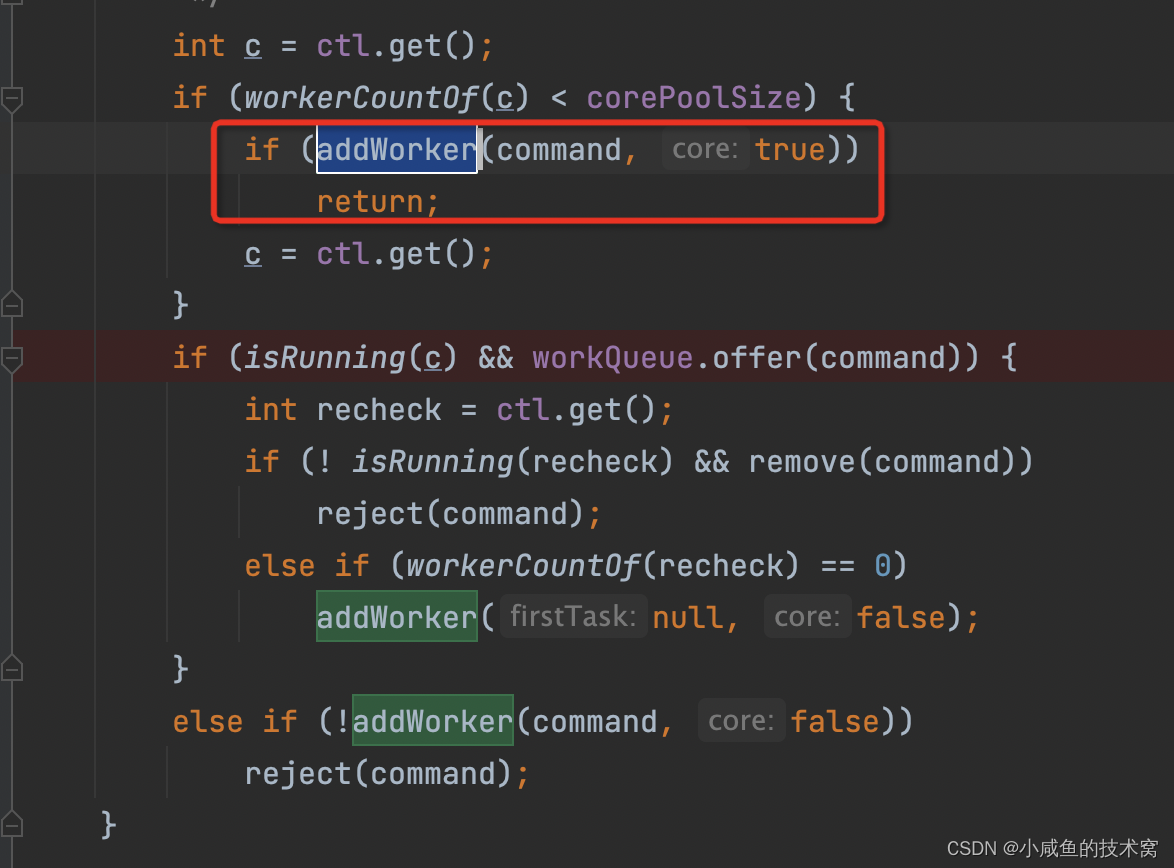
第 3 个任务进来的时候,走如下分支,发现核心线程数满了,直接丢到阻塞队列中。并且后续判断 work 的数量是否等于 0 ,发现不满足,任务 3 仅仅是丢到阻塞队列中了而已。
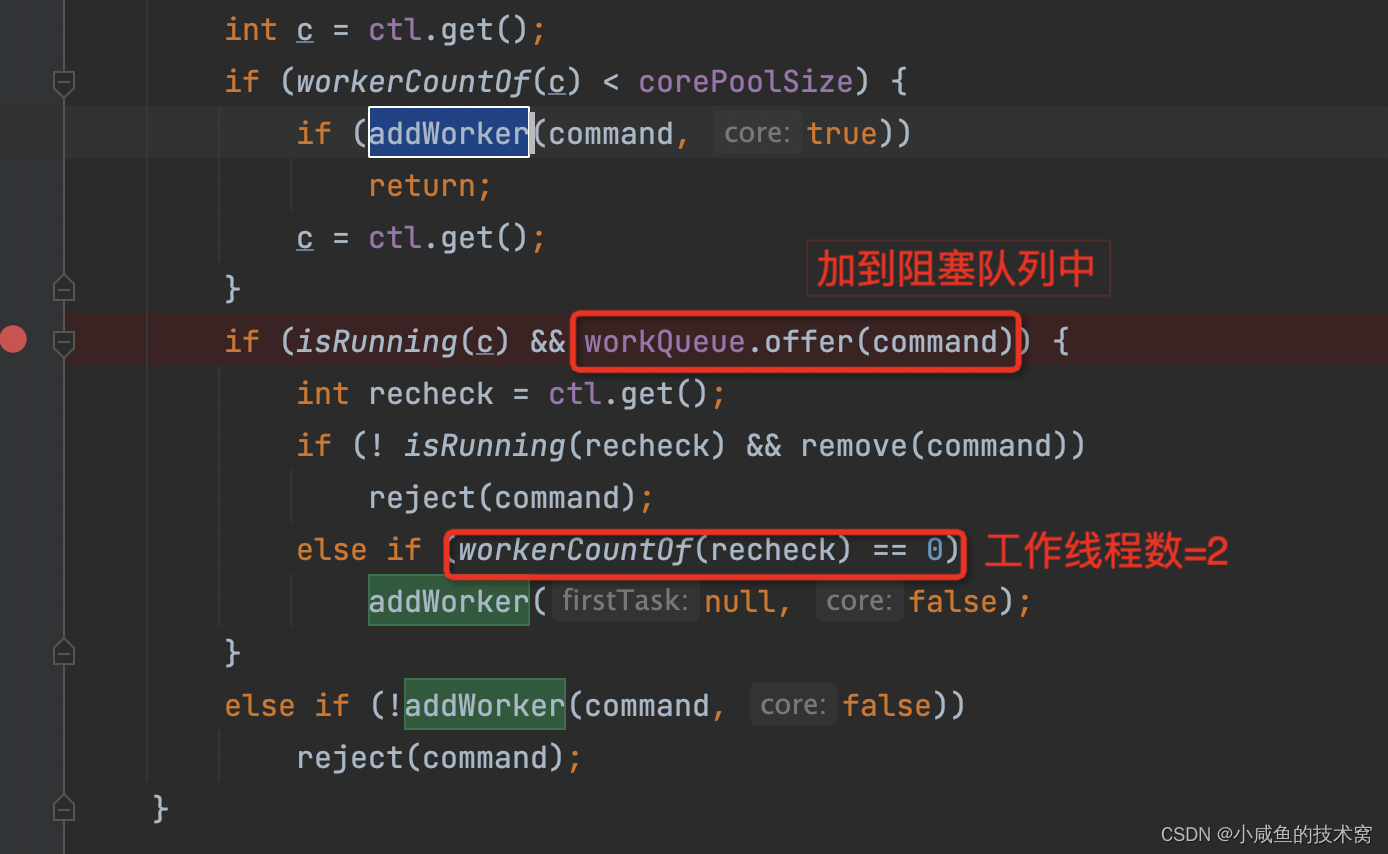
此时任务 4、5 过来了,发现核心线程满了、阻塞队列满了,执行下面圈红的第三个分支,进行 addWork(command,false)。注意传的是 false!!!!里面会拿,正在工作的 work 数量与最大线程数比较,发现:正在工作的 work 数量 < 最大线程数。接着开辟空闲线程去处理任务 4、5。
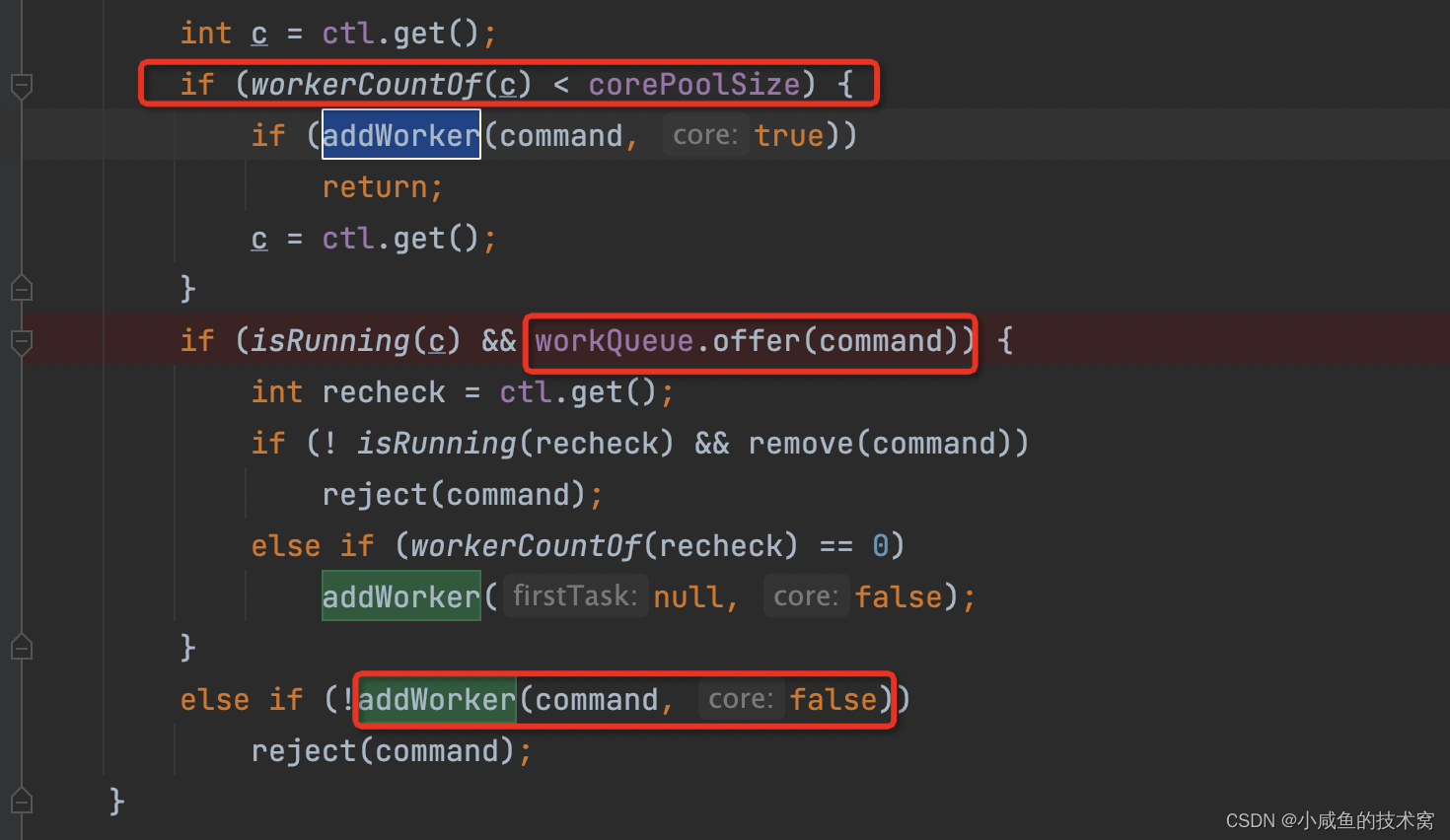
此时任务 6 过来了,发现: 正在工作 work的数量 = 最大线程数。此时正在工作的 work 有(任务 1、2、4、5)4 个。然后直接被拒绝触发拒绝策略。整个流程就是这样的。搞清楚各个参数的触发时机后,心中有粮调优不慌。
keepAliveTime是个啥?
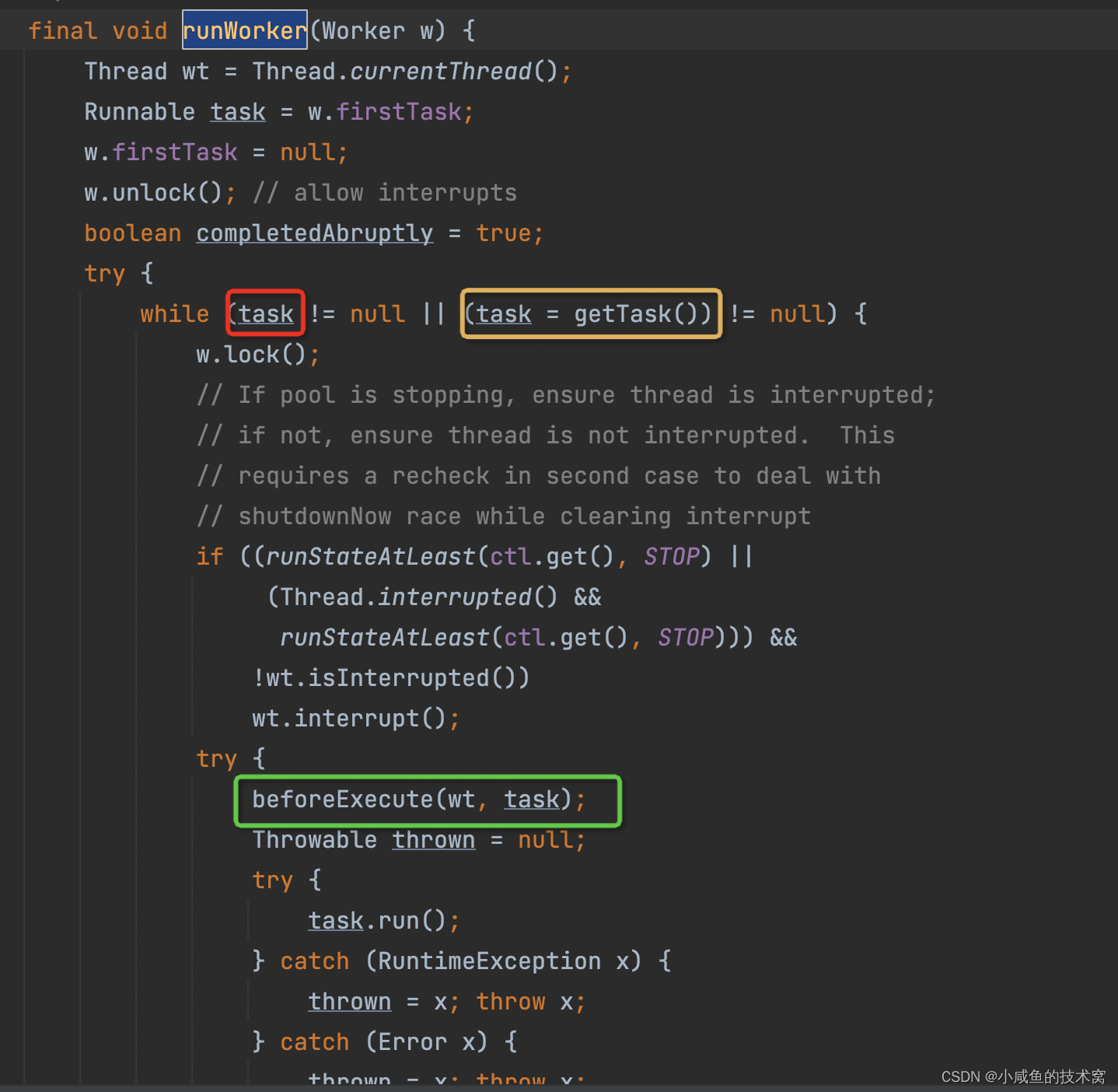
其实不管是核心线程还是什么空闲线程还是最大线程,这么一大堆乱七八糟的概念,本质最终都是需要进行处理任务的,处理任务的逻辑在runWork()中。如下图
- 圈红的 task:当前 work 本职的工作任务
- 圈黄的 task:从阻塞队列中拿出来的工作任务
- 圈绿的地方:执行任务具体Runnable 中的 run 方法。
从源码图中是不是印证了我一开始的那个小故事,骨干员工干完了分配给自己的活后,主动为公司解决超量的任务
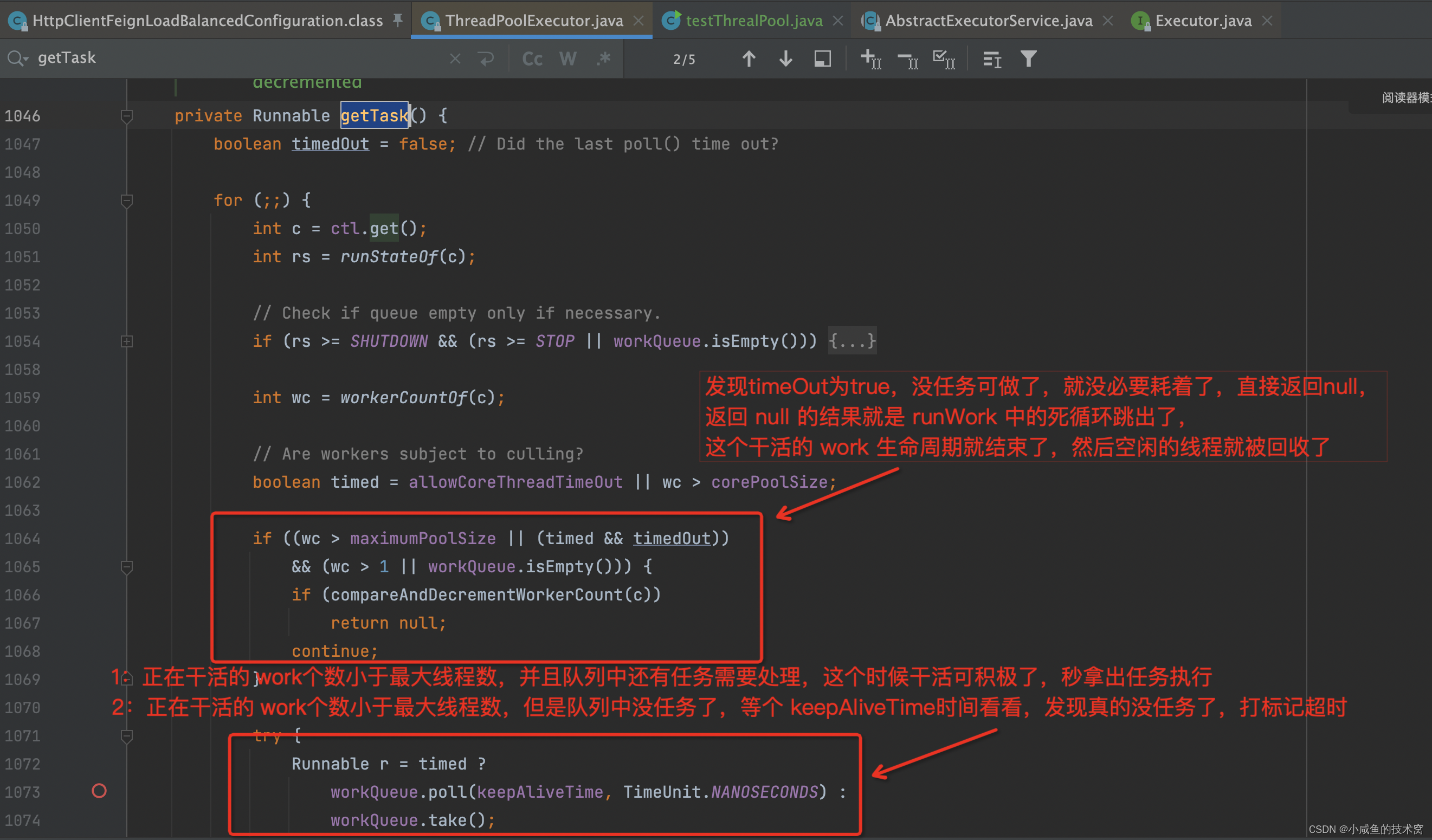
而 keepAliveTime 这个参数就在 getTask 方法里面进行体现,其实就是调用的阻塞队列中的 poll 方法,当队列中的任务为空时,等待 keepAliveTime 时间后再去取任务,还取不到任务就返回 null。
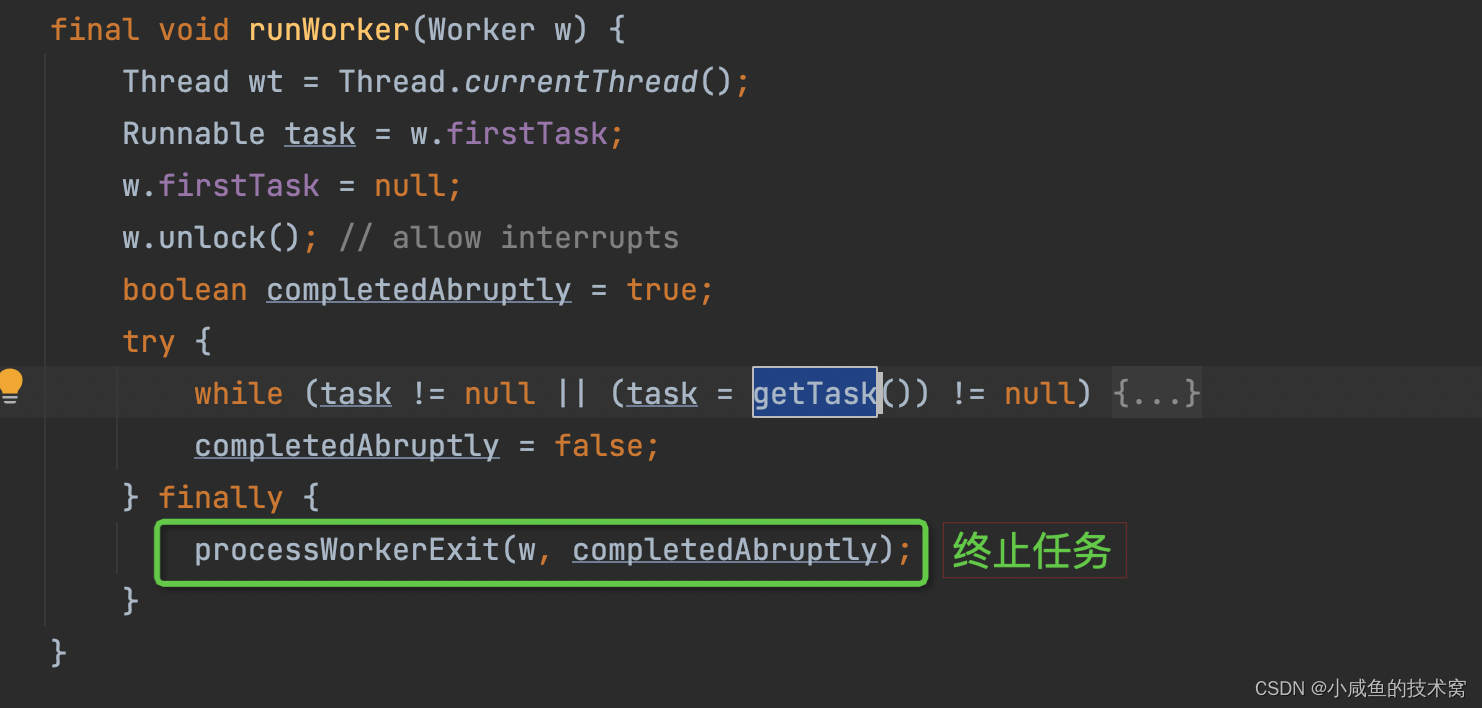
空闲线程拿不到任务结果就是,task 拿到的是 null,触发 processWorkerExit(w, completedAbruptly); 逻辑,空闲线程就被销毁了。因此叫做空闲线程的最大存活时间是这么来的!
总结
- 核心线程满了,后续的任务会放到阻塞队列,阻塞队列满了后,会安排空闲线程处理任务,当空闲线程加核心线程的总数,大于了最大线程数时,将会触发拒绝策略
- 核心线程满了,后续的任务会放到阻塞队列,阻塞队列满了后,会安排空闲线程处理任务,当最大线程数-核心线程数>0,此时会安排空闲线程处理进来的这个任务。
- 当阻塞队列中的任务没有了的时候,由于底层是通过调用 poll 方法拿阻塞队列中的任务的,过了keepAliveTime时候后,还拿不到任务,这个空闲线程就最终会被销毁。
不说了,大家赶紧去看看线上的线程池配置是否合理,后续主页持续更新:如何合理针对计算密集型、io 密集型、自定义拒绝策略收集异常日志,常见业务进行线程池参数设置以及调优~这里是小咸鱼的技术窝,欢迎拜访

推荐好文:
















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











