








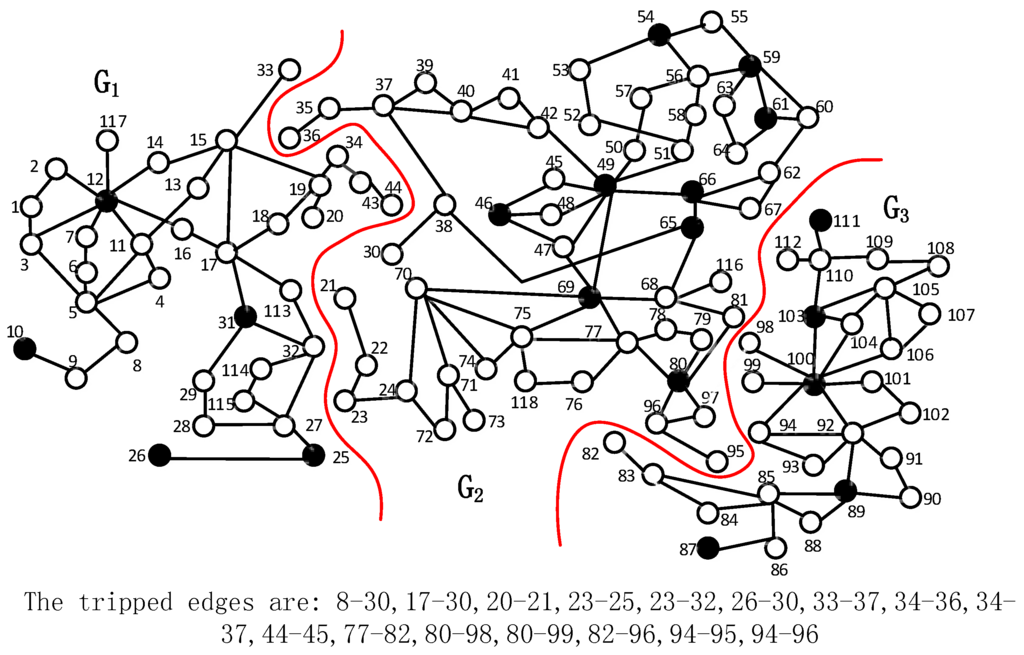
上图展示的是使用禁忌搜索算法解决电力系统孤岛问题。该问题旨在在发生严重扰动后将电力系统划分为几个不同的孤岛,目标是在将相关发电机放置在同一孤岛中并保持每个孤岛的连通性的同时,最小化所有孤岛的总发电负荷不平衡状态。
禁忌搜索(Tabu Search)是由Fred W. Glover在1986年提出的一种基于邻域搜索的元启发式算法。其发展历史可以追溯到20世纪80年代中期,当时Glover在研究组合优化问题时,提出了一种利用禁忌表来记录和避免循环路径的方法,从而跳出局部最优解的陷阱。禁忌搜索通过系统地探索解空间,不断改进当前解,并利用禁忌表防止回溯到先前的解。随着时间的推移,该算法在优化领域得到了广泛的应用和认可,被用于解决各种复杂的优化问题,如旅行商问题、调度问题、网络设计和其他组合优化问题,逐步发展成为一种重要的优化工具。
禁忌表(Tabu List)是禁忌搜索算法中的一个关键数据结构,用于记录最近一段时间内访问过的解或移动,防止搜索过程回到这些解或重复这些移动。禁忌表的引入旨在避免局部最优解陷阱和循环,从而促进更广泛的搜索空间探索。禁忌表具有一定的长度,超出长度的旧解或移动会被移除,使搜索过程动态适应问题的复杂性。通过在禁忌表中存储禁忌条件,可以有效地控制搜索路径,提高算法的全局优化能力。
数学原理
禁忌搜索的基本思想是通过在搜索过程中引入“禁忌表”(Tabu List),记录近期访问的解,并禁止这些解在一定时间内再次被访问,从而促进搜索空间的更广泛探索。其核心步骤如下:
-
初始解生成:随机生成一个初始解 。
-
邻域搜索:在当前解 的邻域中搜索最优解。
-
禁忌表更新:将当前解 加入禁忌表,并更新禁忌表的内容,保持禁忌表的长度不超过预设值。
-
解的接受准则:若找到的邻域解 比当前解 更优,则接受该解,否则检查其是否在禁忌表中,若不在禁忌表中也接受该解。
-
迭代停止条件:若达到预设的最大迭代次数或其他停止条件,则停止搜索,返回最优解。
邻域搜索公式
在禁忌搜索中,解的邻域通常通过一些局部操作生成。例如,对于旅行商问题,可以通过交换路径上的两个城市来生成邻域解。设当前解为 ,邻域解为 ,则有:
是通过一次交换操作得到的解
禁忌条件
禁忌条件是禁忌搜索的重要组成部分,用于避免搜索过程中的循环和局部最优解陷阱。若邻域解 在禁忌表中,则拒绝该解。禁忌条件通常表示为:
评价函数
评价函数用于衡量解的优劣,通常定义为目标函数值。设目标函数为 ,则对于解 ,其评价值为:
评价函数的具体形式取决于所要解决的问题。在旅行商问题中,目标函数通常是路径的总长度,目标是最小化这个长度。在其他优化问题中,目标函数可能是成本、时间或其他需要最小化或最大化的量。禁忌搜索通过不断优化评价函数的值,来寻找问题的最优解。
停止条件
禁忌搜索的停止条件可以是预设的最大迭代次数 或者目标函数值在若干迭代中未能显著改善等。
应用场景
禁忌搜索算法具有广泛的应用场景,主要包括但不限于以下领域:
-
旅行商问题(TSP):通过禁忌搜索优化城市巡回路径,寻找最短路径。
-
生产调度:用于制造业中的生产计划和调度优化,减少生产成本和时间。
-
图着色问题:优化图的着色方案,减少所需颜色数量。
-
组合优化问题:解决各种组合优化问题,如装箱问题、分配问题等。
-
网络路由:优化计算机网络和通信网络中的路由选择,提高网络效率。
Python 可视化实现
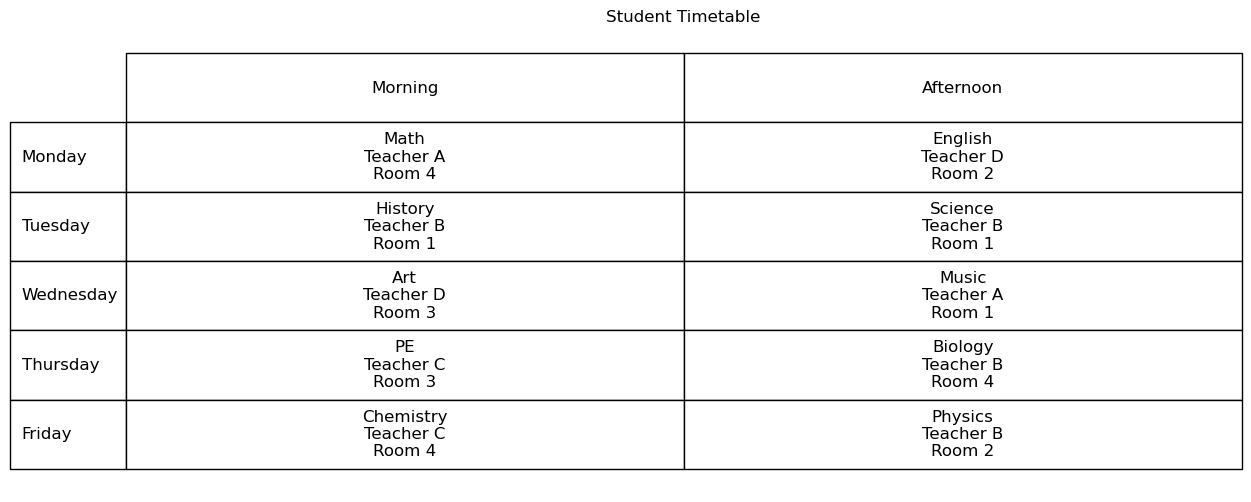
我们假设有一个排课问题,其中有4位教师(假设每位老师所有课程都可以教)、10门课程、4间教室,每周5天,每天有上午和下午两个时间段。通过禁忌搜索算法,生成无冲突的课程表,确保每门课程安排在不同的时间段和教室内,并使用Python进行可视化。
import numpy as np
import random
import matplotlib.pyplot as plt
import pandas as pd
# 定义教师、课程、教室和时间段
teachers = ["Teacher A", "Teacher B", "Teacher C", "Teacher D"]
courses = ["Math", "English", "History", "Science", "Art", "Music", "PE", "Biology", "Chemistry", "Physics"]
rooms = ["Room 1", "Room 2", "Room 3", "Room 4"]
days = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday"]
time_slots_per_day = ["Morning", "Afternoon"]
time_slots = [f"{day} {slot}" for day in days for slot in time_slots_per_day]
# 生成初始解
def generate_initial_solution(teachers, courses, rooms, time_slots):
solution = []
for i, course in enumerate(courses):
teacher = random.choice(teachers)
room = random.choice(rooms)
time_slot = time_slots[i % len(time_slots)]
solution.append((course, teacher, room, time_slot))
return solution
# 评估解的优劣
def evaluate_solution(solution):
conflicts = 0
for i, (course1, teacher1, room1, time_slot1) in enumerate(solution):
for j, (course2, teacher2, room2, time_slot2) in enumerate(solution):
if i != j:
if time_slot1 == time_slot2:
if teacher1 == teacher2 or room1 == room2:
conflicts += 1
return conflicts
# 生成邻域解
def generate_neighborhood(solution):
neighborhood = []
for i in range(len(solution)):
for j in range(i + 1, len(solution)):
neighbor = solution[:]
neighbor[i], neighbor[j] = neighbor[j], neighbor[i]
neighborhood.append(neighbor)
return neighborhood
# 禁忌搜索主循环
def tabu_search(teachers, courses, rooms, time_slots, num_iterations, tabu_tenure):
current_solution = generate_initial_solution(teachers, courses, rooms, time_slots)
best_solution = current_solution[:]
best_score = evaluate_solution(best_solution)
tabu_list = []
for iteration in range(num_iterations):
neighborhood = generate_neighborhood(current_solution)
best_candidate = None
best_candidate_score = float('inf')
for candidate in neighborhood:
if candidate not in tabu_list:
candidate_score = evaluate_solution(candidate)
if candidate_score < best_candidate_score:
best_candidate = candidate
best_candidate_score = candidate_score
current_solution = best_candidate[:]
tabu_list.append(current_solution)
if len(tabu_list) > tabu_tenure:
tabu_list.pop(0)
if best_candidate_score < best_score:
best_solution = best_candidate[:]
best_score = best_candidate_score
print(f"Iteration {iteration + 1}/{num_iterations}, Best Score: {best_score}")
return best_solution, best_score
# 参数设置
num_iterations = 1000 # 增加迭代次数
tabu_tenure = 20 # 增加禁忌表长度
# 求解学生课程安排问题
best_solution, best_score = tabu_search(teachers, courses, rooms, time_slots, num_iterations, tabu_tenure)
# 可视化学生课程安排结果
def visualize_timetable(solution):
timetable = pd.DataFrame(index=days, columns=time_slots_per_day)
for course, teacher, room, time_slot in solution:
day, slot = time_slot.split()
timetable.at[day, slot] = f"{course}\n{teacher}\n{room}"
fig, ax = plt.subplots(figsize=(12, 6))
ax.set_axis_off()
table = ax.table(cellText=timetable.values, colLabels=timetable.columns, rowLabels=timetable.index, cellLoc='center', loc='center', fontsize=14)
table.auto_set_font_size(False)
table.set_fontsize(12)
table.scale(1.2, 1.2) # 调整表格大小
# 调整单元格高度
for key, cell in table.get_celld().items():
cell.set_height(0.15)
plt.title("Student Timetable")
plt.show()
# 可视化最佳课程安排
visualize_timetable(best_solution)
最终结果:
以上内容总结自网络,如有帮助欢迎关注与转发,我们下次再见!















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









