







 介绍TESTR,一种基于Transformers的端到端文本定位方法,适用于弯曲和任意形状的文本检测与识别。TESTR采用单编码器双解码器结构,无需ROI操作,能直接回归文本框控制点。
介绍TESTR,一种基于Transformers的端到端文本定位方法,适用于弯曲和任意形状的文本检测与识别。TESTR采用单编码器双解码器结构,无需ROI操作,能直接回归文本框控制点。
目录
一、Text Spotting Transformers
Abstract
在本文中,我们提出了TExt Spotting TRansformers (TESTR),一个通用的端到端文本定位框架,使用Transformers用于更多的文本检测和识别。TESTR建立在单编码器和双解码器上,用于联合文本框控制点回归和字符识别。除了大多数现有的文献,我们的方法不受感兴趣区域操作和启发式驱动的后处理程序;TESTR在处理弯曲文本框时特别有效,其中需要特别注意适应传统的边界框表示。我们展示了适用于 Bezier曲线和多边形注释中的文本实例的控制点的规范表示。此外,我们还设计了一个边界盒引导的多边形检测(盒到多边形)过程。在弯曲和任意形状的数据集上的实验证明了所提出的TESTR算法的最新性能。
1.Introduction
自然场景中的文本检测和识别,称为文本定位,是计算机视觉中一个活跃的研究领域。文本定位在映射、自动驾驶和图像检索等现实应用中具有重要意义。文本定位问题通常由两个子任务组成:1)文本检测,用来定位自然图像中的文本框,以及2)从检测到的文本中读取字符的文本识别;尽管它具有实际意义和最近观察到的稳步进展,文本定位仍然是一个具有挑战性的问题,需要进一步改进。文本定位的主要困难是由多种因素造成的,包括自然场景图像的字体、大小、样式、颜色、形状、遮挡、失真和布局的巨大变化。
经典文本定位方法[24,38]通常通过两个独立的步骤进行文本检测和识别。在检测模块中,为文本实例检测提出了所感兴趣的区域(ROI)。对齐后,这些特征将在文本识别模块中使用。在自然场景中,文本框通常以任意方向的出现,并且是非矩形的。这给算法开发带来了进一步的挑战,该算法通常需要一些具有中间和后处理步骤的启发式设计。
Transformers在自然语言处理和计算机视觉方面取得了显著的成功。DEtection TRansformers (DETR)通过去除基于滑动窗口的方法中所需要的建议锚点和非最大抑制过程,也对目标检测产生了深远的影响。LETR扩展DETR,采用Transformers直接检测几何结构,如边界框表示之外的线段。
其灵感来自于DETR家族模型,我们提出了TExt Spotting TRansformers(TESTR),一种基于Transformer-based的文本定位方法,在一个统一的框架中执行文本检测和识别。TESTR避免了启发式设计和在许多现有的文本定位方法中所需的启发式设计和中间阶段。
TESTR的贡献如下:
- 我们提出了一个联合执行弯曲文本实例检测和识别的单编码器双解码器框架,其使用超出标准边界框表示范围的Transformers。我们的方法,由于控制点坐标的直接回归,是一种整体的方法,既不需要启发式驱动的后处理程序,也不需要感兴趣的区域操作(ROI)。
- 我们引入了一种盒到多边形的过程,实现检测Transformers中边界盒引导的多边形检测。实验结果表明,其有明显的性能提高。
- 控制点的规范表示使我们的方法同时适用于多边形和Bezier曲线注释。TESTR在具有挑战性的数据集上实现了最先进的性能,即Total-Text和CTW1500。
1.1. Related Works
场景文本定位由文本检测和识别组成。首先开发了两阶段的方法来解决这个任务,它们分别训练检测和识别模块,并在推理过程中简单地连接它们。最近的文献集中在端到端方法上,它在训练过程中通过RoI操作同时处理检测和识别问题。虽然这些方法表现出令人满意的性能,但由于任意形状的文本的流行,文本定位任务仍然是一个挑战。我们将从文本检测、文本识别、常规文本定位和任意形状的文本定位等角度来讨论相关的工作。图2是对示例性工作的概述。

文本检测 重点关注水平文本检测,它可以预测文本实例的矩形边界框。它们构成了明显的局限性,因为在野外的文本大多是多方向的四边形,弯曲的,甚至是任意形状的。已经作出了努力来解决这些具有挑战性的案件。[18,51]同时使用旋转的方框和四边形来实现多方向的四边形文本检测。[1]可以通过预测字符盒来检测任意形状的文本。在实现显著的性能提升时,它需要昂贵的字符级注释和后处理来将检测到的字符分组到文本中。[47]对文本区域使用成对的点表示,但它仅限于rnn的顺序解码。[24,26]引入了一种新的弯曲文本的贝塞尔曲线表示方法,并显著提高了对它们的检测性能。
文本识别 经典方法[30,32,45]采用统计学方法对字符进行分类,并将其分组为单词。基于深度学习的方法[14,40]开创了文本识别的新时代。CRNN [38]集成了CNN和RNN来进行文本识别。但是,它主要适用于常规文本,局限限于任意形状的文本。[22,39]使用空间 transformer将不规则文本转换为矩形形状,然后将它们输入特征提取器和序列解码器进行识别。
常规的端到端场景文本定位 为了进一步提高文本定位的性能,[15]提出了一个端到端可训练的文本定位框架。引入RoI池化来弥补文本检测和识别之间的差距。然而,这种方法仅限于水平文本。其他文献基于其他特殊制作的RoI操作进行四边形文本定位,如Text-Align[11]和 RoI-Rotate[23],同时仍然无法定位任意形状的文本。
任意形状的端到端场景文本定位 在[41]中,生成四边形文本区域建议,然后进行RoI变换。虽然该方法可以识别不规则的文本,但它的四边形表示对于任意形状的文本区域并不是最优的。CharNet [48]在一次传递中执行字符和文本检测,需要字符级注释。TextDragon[8]围绕文本中心线生成多个局部四边形,使用RoISlide操作,用于文本实例中的特征扭曲和聚合。虽然不需要字符级的监督,但它仍然需要执行中心线检测、分组和排序来将局部四边形转换为文本边界。
其他文献集中于基于分割的方法,以实现任意形状的文本定位。Mask TextSpotter建立在Mask R-CNN执行文本级和特征级分割,在得到最终结果之前需要进行进一步的分组。[35]提出了RoI方法,即将分割概率映射与特征相乘,以抑制背景,而[17]则使用二进制映射来缓解分割中的不准确性。虽然这些方法都能获得了良好的性能,但掩模表示需要经过后处理,如多边形拟合和平滑,以获得理想的边界。MANGO [33]开发了Mask注意模块来保留多个实例的全局特征,但它仍然需要中心线分割来指导预测的分组。
最近的工作试图开发出直接捕获文本边界的适当表示。ABCNet和ABCNetV2引入弯曲文本的参数Bezier曲线表示,并为特征提取的Bezier-Align。然而,低阶Bezier曲线在表示严重弯曲或波浪形文本形状时表现出局限性。[34]使用形状变换模块在文本边界周围生成基准点,并纠正不规则文本。PGNet [46]将多边形文本边界转换为中心线、边框偏移量和方向偏移量,并为这些目标执行多任务学习。在消除RoI操作的同时,它仍然使用了一个特殊设计的多边形恢复过程。
相比之下,我们的方法完全依赖于Transformers,它完全不受RoI操作。由于输出是文本实例的多边形顶点或贝塞尔控制点的坐标,以及相应的字符序列,因此不需要进行特殊的后处理。
2. Method
TExt Spotting TRansformers (TESTR)是一个端到端可训练的框架,它以统一的方式处理文本检测和识别。整个体系结构如图3所示。

2.1.Multi-Scale Deformable Attention
文本定位任务的一个障碍是图像中普遍的小文本实例。目前的文献试图通过利用多尺度的特征图来克服这一限制,如特征金字塔网络(FPN)。为了利用这些特征图,我们采用了[52]中的多尺度可变形注意模块。给定一组L级的多尺度特征映射
U
l
l
=
1
L
{U_l}^L_{l=1}
Ull=1L,每个级别都是
U
l
∈
R
C
×
H
l
×
W
l
U_l\in R^{C×H_l×W_l}
Ul∈RC×Hl×Wl,p (q)作为query q的参考点的归一化坐标,多尺度可变形注意可以表示为
M
S
D
e
f
o
r
m
A
t
t
n
(
q
,
p
(
q
)
,
U
l
l
=
1
L
)
=
∑
h
=
1
H
W
h
∑
l
=
1
L
∑
k
=
1
K
A
h
l
k
(
q
)
⋅
W
h
′
U
l
[
ϕ
l
(
P
(
q
)
)
+
p
h
l
k
(
q
)
]
MSDeformAttn(q,p(q),{U_l}^L_{l=1})=\sum ^{H}_{h=1}W_h{ \sum ^{L}_{l=1} \sum ^{K}_{k=1}A_{hlk}(q)·W'_hU_l[\phi _{l}(P(q))+p_{hlk}(q)]}
MSDeformAttn(q,p(q),Ull=1L)=h=1∑HWhl=1∑Lk=1∑KAhlk(q)⋅Wh′Ul[ϕl(P(q))+phlk(q)]
其中,h、l、k分别为注意头、输入特征水平和采样点的指标。
A
h
l
k
A_{hlk}
Ahlk表示查询q的注意权重,对K个采样点进行归一化。
ϕ
l
\phi _{l}
ϕl将标准化坐标映射到第1级特征映射的比例尺,并且∆p为查询生成一个适当的采样偏移量。它们都被添加进来,以形成特征图
U
l
U_l
Ul的采样位置。
W
h
′
W'_h
Wh′和
W
h
W_h
Wh是可训练的权重矩阵,与原始多头注意力中出现的权重矩阵相似。
与依赖原始注意需要在特征图中的
H
×
W
H×W
H×W点采样,多尺度可变形注意样本LK点,很大程度上减少了计算开销,并能够使用多尺度特征图。我们将在实验部分中说明它的效率。
2.2.Dual Decoders
我们将整体文本定位任务表述为一个集合预测问题.给定一个图像I,我们需要输出一组点字符元组,定义为
Y
=
(
P
(
i
)
,
C
(
i
)
)
i
=
1
K
Y={(P_{(i)},C_{(i)})}^K_{i=1}
Y=(P(i),C(i))i=1K,其中,i是每个文本实例的索引,
P
(
i
)
=
(
p
1
(
i
)
,
…
,
p
N
(
i
)
)
P^{(i)}=(p^{(i)}_1,…,p^{(i)}_N)
P(i)=(p1(i),…,pN(i))是N个控制点的坐标,
C
(
i
)
=
(
c
1
(
i
)
,
…
,
c
M
(
i
)
)
C^{(i)}=(c^{(i)}_1,…,c^{(i)}_M)
C(i)=(c1(i),…,cM(i))是文本中的M个字符。
为了解决这个问题,我们提出了一种用于预测不同模式的双解码器范式,用于检测的位置解码器(预测
P
(
i
)
P ^{(i)}
P(i))和用于识别的字符解码器(预测
C
(
i
)
C ^{(i)}
C(i))。
位置解码器 我们将原始DETR [2]中的查询扩展到复合查询,以预测每个实例的多个控制点。我们有Q个这样的查询,每个查询都对应于一个文本实例,如
P
(
i
)
P ^{(i)}
P(i)。每个查询元素都由子查询
p
j
p_j
pj组成,其中
P
(
i
)
=
(
p
1
(
i
)
、
⋅
⋅
⋅
、
p
N
(
i
)
)
P^{ (i)} =(p^{(i)}_1、···、p^{(i)}_N)
P(i)=(p1(i)、⋅⋅⋅、pN(i))。为了以一种结构性的方式捕获单个文本实例中不同文本实例之间和不同子查询之间的关系,我们利用了因素分解的自注意。因式分解的自我注意由组内注意,即属于
P
(
i
)
P^{ (i)}
P(i)的子查询内的自我注意和组间注意组成,这是一个不同查询的
p
j
p_j
pj之间的自我注意。
初始控制点查询被输入到位置解码器中。经过多层解码过程后,最终由分类头预测置信度,2通道回归头输出每个控制点的归一化坐标。
这里预测的控制点可以是N个多边形顶点,也可以是Bezier曲线的控制点,如[24]中所述。对于多边形点,我们使用从左上角开始并以顺时针顺序移动的序列。
对于Bezier控制点,可以使用伯恩斯坦多项式[27]来构造参数曲线
c
(
t
)
=
∑
j
=
1
N
p
j
B
(
j
−
1
)
,
(
N
−
1
)
(
t
)
,
t
∈
[
0
,
1
]
c(t)=\sum ^{N}_{j=1} p_j B_{(j-1),(N-1)}(t),t\in[0,1]
c(t)=j=1∑NpjB(j−1),(N−1)(t),t∈[0,1]
其中伯恩斯坦基多项式的定义为
B
(
i
,
n
)
(
t
)
=
n
i
t
i
(
1
−
t
)
n
−
i
B_{(i,n)}(t)=\begin{matrix}n \\ i \\ \end {matrix} t^i(1-t)^{n-i}
B(i,n)(t)=niti(1−t)n−i
在[24]之后,我们对单个文本实例使用两条三次贝塞尔曲线,对应于文本的两个可能弯曲的边。我们可以通过t进行采样,将Bezier曲线转换回多边形。
字符解码器 字符解码器遵循大部分的位置解码器,控制点查询被字符查询
C
(
i
)
C^{ (i)}
C(i)取代。初始字符查询包括一个可学习的查询嵌入和一维正弦位置编码,并在不同的文本实例之间共享。具有相同索引的字符查询
C
(
i
)
C^{ (i)}
C(i)和控制点查询
P
(
i
)
P^{ (i)}
P(i)属于同一个文本实例,因此共享多尺度可变形交叉注意的参考点,以确保它们从图像特征中得到相同的上下文。分类头通过最终的字符查询来预测多个字符类之间的查询。
2.3.Box-to-Polygon Detection Process
解码器对我们的集合预测问题的贝叶斯推理过程P(Y |I)∝P(I|Y)P (Y)建模,其中P(I|Y)通过交叉注意捕获假设(查询)和输入I之间的关系,而P (Y)通过自注意对Y的配置先验建模。我们认为,当Y是复杂的,在复合查询中,P (Y)很难学习。因此,我们提出了一种从盒到多边形的检测方法,该方法利用文本实例的边界框来指导多边形检测。这个过程,利用与具体图像I相关的信息来形成特定于输入的先验,便于多边形控制点回归的训练。
该框架从图3中的引导生成器开始,它是一个输出粗糙的边界候选框以及可能性选择具有top-Q概率的盒子,它们的坐标表示为
w
i
i
=
1
Q
{w^i}^Q_{i=1}
wii=1Q。2.2中描述的初始控制点查询的形式为:
P
(
i
)
=
φ
(
w
(
i
)
+
p
1
,
…
,
p
N
)
P^{(i)}=\varphi (w^{(i)}+p_1,…,p_N)
P(i)=φ(w(i)+p1,…,pN)
其中
(
p
1
,
⋅
⋅
⋅
,
p
N
)
(p_1,···,p_N)
(p1,⋅⋅⋅,pN)是控制点查询嵌入,跨Q查询共享,对与特定边界框位置无关的控制点之间的一般关系进行建模。
φ
\varphi
φ是正弦位置编码函数,然后是一个线性和归一化层,因此是完全可微的。
φ
(
w
(
i
)
)
\varphi(w^{(i)})
φ(w(i))作为编码的边界框信息,在单个实例中的N个子查询中共享,从而建模文本实例的总体位置和规模。
w
(
i
)
w^{(i)}
w(i)也可作为多尺度可变形交叉注意的初始参考点。
图4提供了这个过程的说明,以及引导生成器的详细信息。第3.4节中的消融研究表明,这一过程显著提高了识别精度。
2.4. Training Losses
Bipartite matching 由于TESTR输出一个固定数量的预测,而不像ground truth实例的实际数量(G),我们需要在它们之间找到一个最优的匹配来计算损失。
Instance classification loss 我们采用焦点损失作为文本实例的分类损失。
Control point loss 控制点坐标回归采用L-1距离损失。
Character classification loss 我们认为字符识别是一个分类问题,每个类被分配一个特定的字符。
Bounding box intermediate supervision loss 为了使第2.3节中的建议更加准确,我们还在编码器侧对它们进行了中间监督。采用相同的二部匹配方案将这个边界框方案与地面真相进行匹配。
3. Experiments
3.2. Implementation Details
我们使用ResNet-50 [10]作为所有实验的特征骨干。多尺度的特征图是直接从没有FPN的ResNet的最后三个阶段中绘制出来的。可变形transformer的参数与[52]相似,有H = 8头和K = 4采样点作为可变形注意,我们使用了6层编码器和解码器。
Data augmentation 训练过程中的数据增强是通过1)随机调整大小,较短的边缘在480到896之间,最长的边缘保持在1600以内;2)实例感知的随机裁剪,确保裁剪尺寸大于原始尺寸的一半,且文本不被切割。在测试期间,我们将较短的边调整为1600,同时将最长的边保持在1892内。
Pre-training 该模型在SynthText 150k、MLT 2017[31]和total-text的混合物上进行预训练,进行440k迭代。多边形变体的基本学习率为
1
×
1
0
−
4
1×10^{-4}
1×10−4,在第340k次迭代时衰减了0.1倍。对于用于预测参考点、多尺度可变形注意和特征主干的线性投影,学习率为0.1倍。采用AdamW [28]作为优化器,β1 =为0.9,β2 =为0.999,重量衰减为10‘4。我们使用Q = 100复合查询。最大文本长度M为25,多边形控制点数N为16。造成损失的加权因子为
λ
c
l
s
=
2.0
λ_{cls} = 2.0
λcls=2.0、
λ
c
o
o
r
d
=
5.0
λ_{coord} = 5.0
λcoord=5.0、
λ
c
h
a
r
=
4.0
λ_{char} = 4.0
λchar=4.0、
λ
g
I
o
U
=
2.0
λ_{gIoU} = 2.0
λgIoU=2.0。我们设置α = 0.25,γ = 2.0作为焦点损失。对于模型的Bezier变体,我们有N个=8个控制点,基本学习率的两倍,一半
λ
c
h
a
r
λ_{char}
λchar用于平衡。在8个RTX 2080Tigpu上的预训练过程大约需要3天,图像批大小为8。
Finetuning 在评估之前,该模型对特定数据集进行微调,以减轻不同数据集之间的差异。对于Total-Text和ICDAR 2015数据集,我们微调了20k次迭代的模型,基本学习率为0.1。对于CTW1500,为了处理数据集中出现的较长文本,最大文本长度M设置为100,因此模型需要200k次迭代,比其他两个所需的要大。
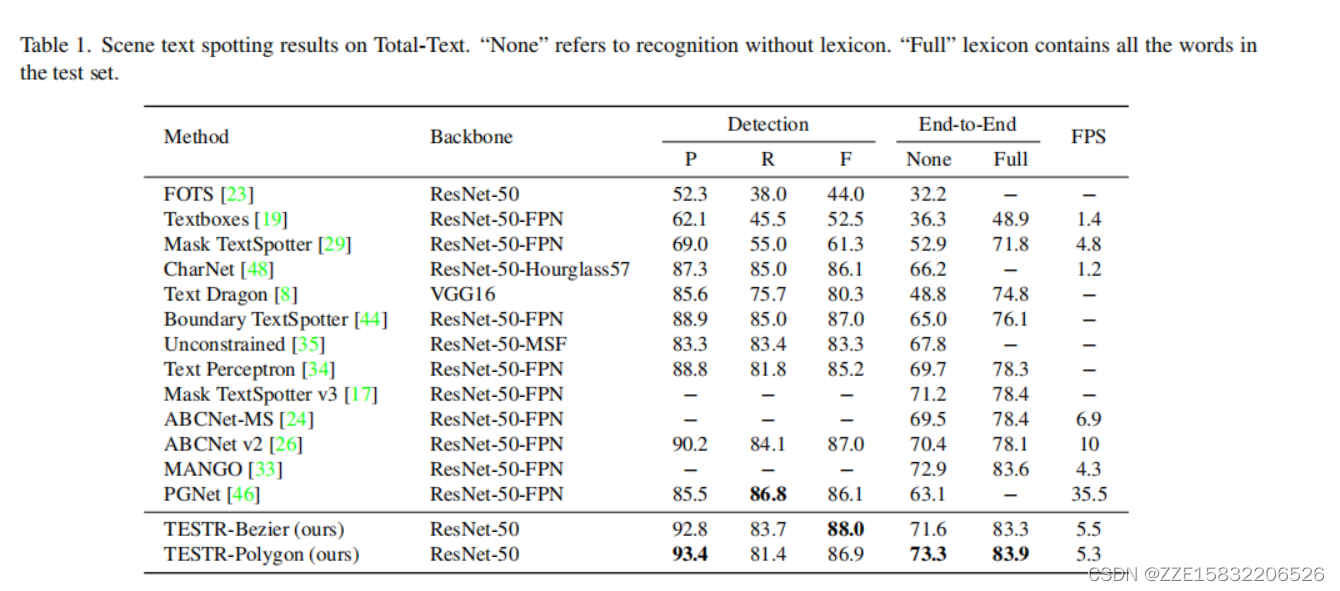
4. reslut

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









