









一、作者

二、摘要
提出一种端到端可训练Fast Oriented Text Spotting网络,同时检测识别。RoIRotate共享检测和识别的卷积特征。本方法没有重复计算消耗,并学习到更多通用特征,因此优于two-stage方法。在ICDAR2015、ICDAR2017MLT和ICDAR2013达到state-of-the-art。达到实时的任意方向text spotting,22.6fps在ICDAR2015 text spotting task超出state-of-the-art五个百分点。

三、介绍
因为特征提取是最耗费时间的,本文收缩计算到单个检测网络,见图1。ROIRotate是连接检测和识别的关键,通过方向检测bounding boxes从feature maps获取特征。
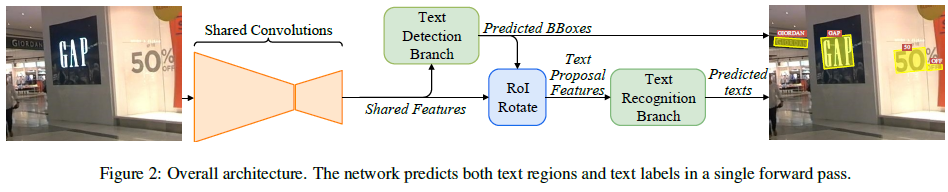
流程见图2,首先用共享卷积层提取feature maps;基于全卷积网络的方向文本检测分支来预测检测bounding boxes;RoIRotate运算符从feature map提取检测结果对应文本proposal特征;然后文本proposal特征进入RNN编码器和CTC解码器去文字识别。因为网络可微,整个网络可以端到端训练。这是第一个任意方向文本检测识别端到端网络。非常好训练,没有复杂的预处理和超参数。
四、方法细节
FOTS有四个步骤:共享卷积、文本检测分支、RoIRotate运算、文本识别分支。
- 整体流程
共享卷积网络如图3,其backbone是ResNet-50,受FPN(Feature pyramid networks for object detection.2016)启发,我们连接低level和高level语义特征图。输出1/4图像。

文本检测分支输出稠密的逐像素预测结果,是任意方向的文本区域proposals,提出RoIRotate转换相应共享卷积到固定高度特征,同时保持原始区域宽高比。CNN和LSTM去编码文本序列,CTC解码。识别分支结构如下表1。

- 文字检测分支
受EAST(旷世CVPR2017)启发,本文采用全卷积网络作为文字检测器。因为有很多小文字,我们共享卷积层采用1/4而不是1/32的降采样。输出稠密的逐像素单词预测值。第一个通道计算每个像素为正样本的概率,如同EAST文本中心区域像素才为正样本;其他4通道表示当前像素与四边的距离;最后一个通道表示bounding box的方向。最后结果使用阈值和NMS。
在实验中发现篱笆、围墙这种很像文字的难以分类,我们使用online hard example mining(OHEM)来区分和解决类间不平衡问题。F值提升2个点。
(注:OHEM为R-CNN的作者写的CVPR2016< Training Region-based Object Detectors with Online Hard Example Mining - cvpr 2016 oral>,是bootstrapping在dl中的应用。简单来说就是从ROI中选择hard,而不是简单的采样。具体的方法就是先让所有样本通过dl计算出loss,以loss大为hard example的标准,选择B/N个进行反向传播。直觉想到的方法就是将那些未被选中的ROI的loss直接设置为0即可,但这实际上还是将所有的ROI进行反向传播,时间和空间消耗都很大,所以作者在这里提出了本文的网络框架,用两个网络,一个只用来前向传播,另一个则根据选择的ROIs进行后向传播,的确增加了空间消耗(1G),但是有效的减少了时间消耗,实际的实验结果也是可以接受的。kaiming he提出了一种新的方法 focal loss, 直接在loss上进行变换,不需要像ohem一样forward两遍,看起来即简洁又实用。)
检测分支的loss方程有两部分:文本分类部分和bounding box回归部分。文本分类部分可看做降采样score map的逐像素分类loss。只有文本区域中心被认为正样本,Bounding box内的非中心区域被认为not care。
(注:FCN for Sementic Segmentation对每一个pixel都求了score,所以最后一张图片对一个类得到的是一个score map)
分类loss用交叉熵loss。回归loss用IoU loss(Unitbox:An advanced object detection network.2016)和rotation angle loss(East: An efficient and accurate scene text detector.2017),因为他们对目标形状、尺度和方向变换很鲁棒。![]() 。超参数是为了平衡两个loss,本文设为1。
。超参数是为了平衡两个loss,本文设为1。
- RoIRotate
用于将方向特征区域变换为axis-aligned feature maps,如图4。输出固定高度,保持宽高比。相比于RoI pooling(fast r-cnn)和RoIAlign(mask r-cnn),RoIRotate在regions of interest提取特征时提供更通用的操作。

操作分两步,根据ground truth坐标或者预测值坐标计算每个text proposal的仿射变换参数;在shared feature maps的每个region分别仿射变换,从而获得feature maps中的规范水平text proposal。本文高度为8。总之,RoIRotate输入是共享卷积,输出所有text proposals的固定高度,宽高比不变的feature maps。
不同于目标分类,文字识别对检测噪声很敏感。一个文本区域的小检测错误会割掉若干字符,对训练有坏处,所以训练时我们使用文本区域gt代替预测值。在测试阶段,应用阈值和NMS去过滤文本区域。RoIRotate后,变换feature maps送入文本识别分支。
- 文字识别分支
使用共享卷积网络生成的、RoIRotate变换后的区域特征来预测文本label。输入特征到LSTM,上面提到降采样4倍,因为有的紧密笔画的字符,降采样容易导致笔画消失。文本识别网络类似VGG,卷积、pooling、一个双向LSTM、一个全连接层和最后的CTC解码。
后略。
最终多任务loss方程:![]() ,超参数用来平衡两个loss,本文设为1。
,超参数用来平衡两个loss,本文设为1。
- 实现细节
使用ImageNet预训练模型。训练过程分两步,先用Synth800k dataset(Synthetic data for text localisation in natural images.2016CVPR)训练10个epochs,再用真实数据去finetune直到收敛。不同训练数据集应用于不同任务。
数据增广对于深度神经网络的鲁棒性非常重要,特别是真实数据很少。首先,图像长边resize从640到2560;其次,图像随机在[-10°,10°]旋转;然后,宽度不变,高度在[0.8,1.2]倍缩放;最后,从以上变换图像里随机切割采样640*640图像;
使用OHEM提升性能。对每幅图像,512个困难负样本、512个随机负样本、所有正样本被选中来分类。结果,正负比例从1:60提升到1:3。对于bounding box回归,每幅图我们选择128个困难正样本和128个随机正样本来训练。
测试时,文本检测后,RoIRotate使用阈值和NMS过滤,然后再进入识别分支获取最后结果。对于多尺度测试,所有尺度结果结合后再NMS去获得最后结果。
五、实验结果
- 与Two-stage方法比较
文本检测和识别一起训练,可以相互受益。为了验证,我们建立了一个two-stage系统,检测和识别模型分开训练,识别网络的训练样本直接从原图切割。实验证明在各数据集上Fots比单独检测或识别模型训练,能够提升1到2个百分点。因为检测更关注整体文字特征,而识别帮助网络学习字符级特征的细节,遇到文本区域内在变化较大,或者文字区域与背景区域相似,识别能够强制模型学习字符细节。Fots学习到语义信息:同一单词的不同字母有不同模式,也加强了与相似背景的区分。
- 与state-of-the-art方法比较
对于单尺度测试,长边在三个数据集上分别resize至2240、1280、920得到最好结果。采用3到5个尺度做多尺度测试。
- 速度和模型尺寸
端到端比two-stage速度提升一倍,大小降低一倍。
为了达到实时,我们将ResNet-50替换为ResNet-34,使用1280*720作为输入。使用TITAN-Xp GPU训练Caffe。















 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









