









前面我们看了一大堆的语法,这章不开新东西。主要是展示一些常用的案例o(* ̄▽ ̄*)o
一. cpu 查询
1. 查看cpu使用率
#还记得irate不? 计算区间向量中的最后的两个值来算速率
#我们这里直接去计算cpu的瞬时使用率
irate(node_cpu_seconds_total{instance="192.168.1.21:9100"}[5m])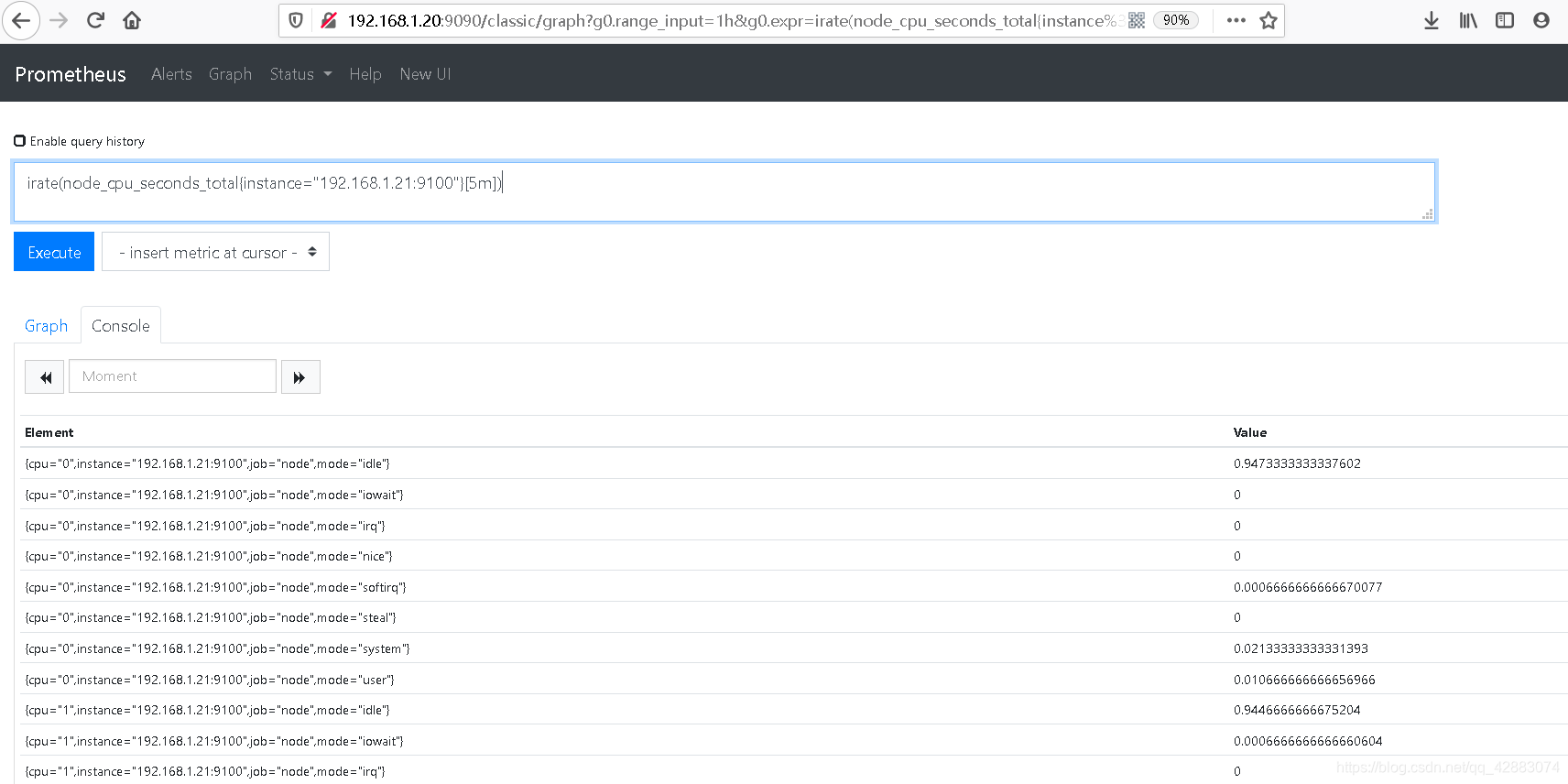
#但是我们得到的数据中cpu的模式比较多,并不方便我们使用
#我们将所有属于192.168.1.21节点的cpu属性聚合起来求他的平均值
avg(irate(node_cpu_seconds_total{instance="192.168.1.21:9100"}[5m])) by (instance)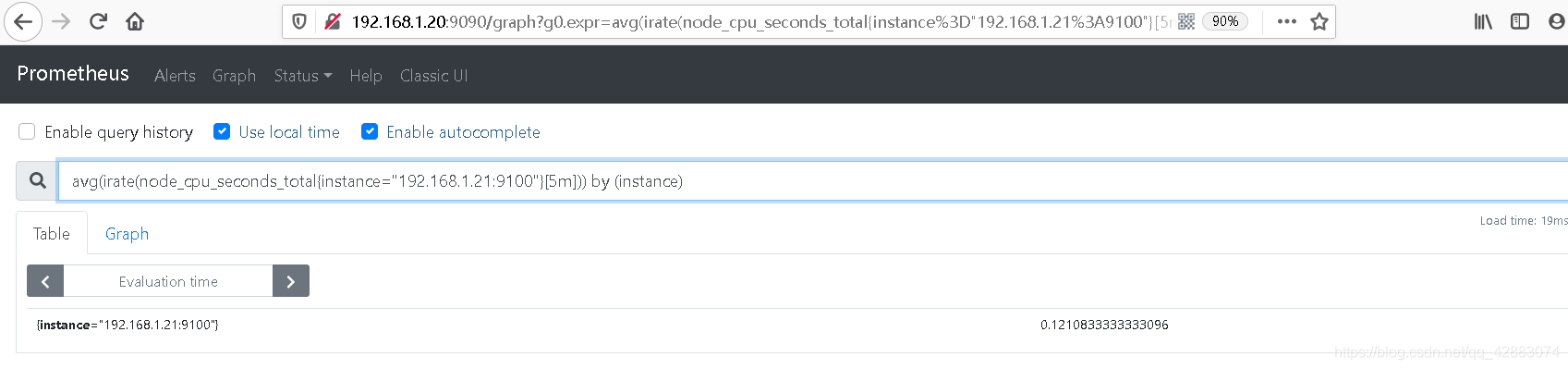
#然后做一下数学运算
avg(irate(node_cpu_seconds_total{instance="192.168.1.21:9100"}[5m])) by (instance) * 100
#下面可以得到我们的cpu使用率是12% 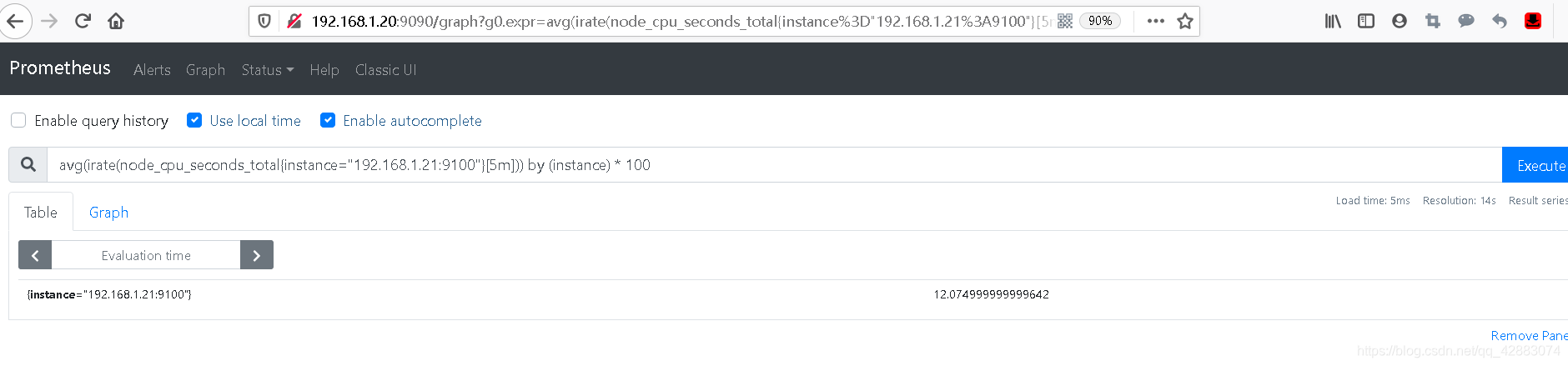
#但这样只能得到单个节点的信息,我们通常会匹配多个节点来获取不同节点的信息
avg(irate(node_cpu_seconds_total{instance=~".*:9100"}[5m])) by(instance)* 100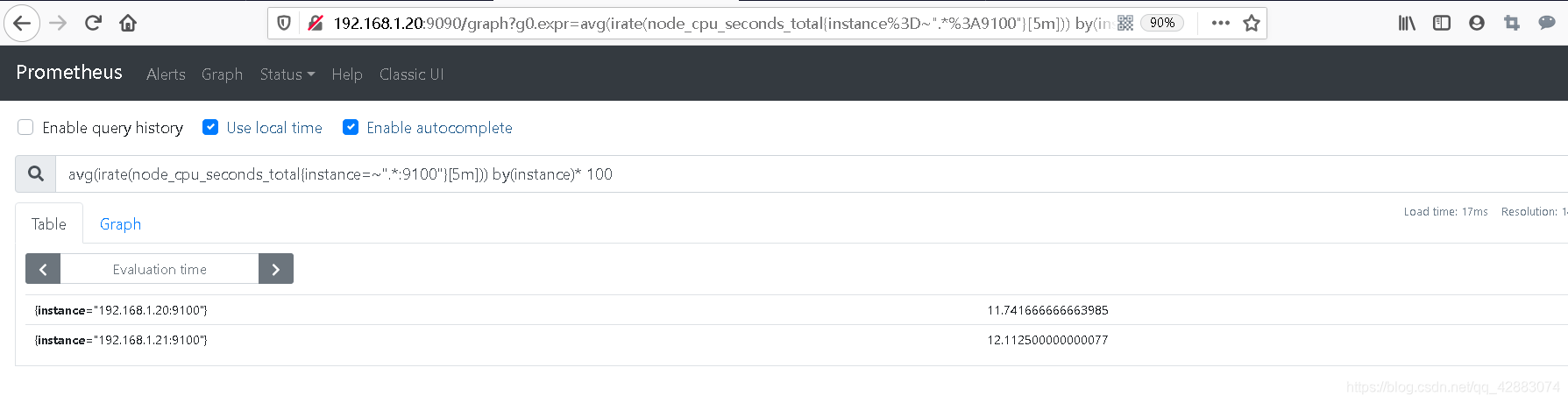
2. 查看cpu 负载
通常查看的是cpu 1、5、15分钟的负载
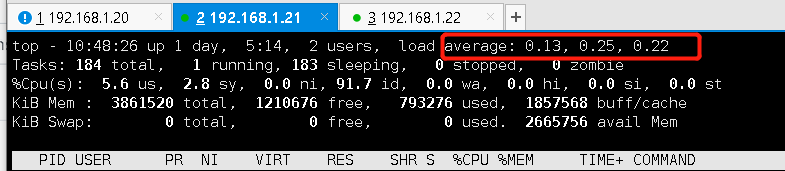
node_load1 #1分钟cpu负载
node_load5 #5分钟负载
node_load15 #15分钟负载3. 计算cpu数量
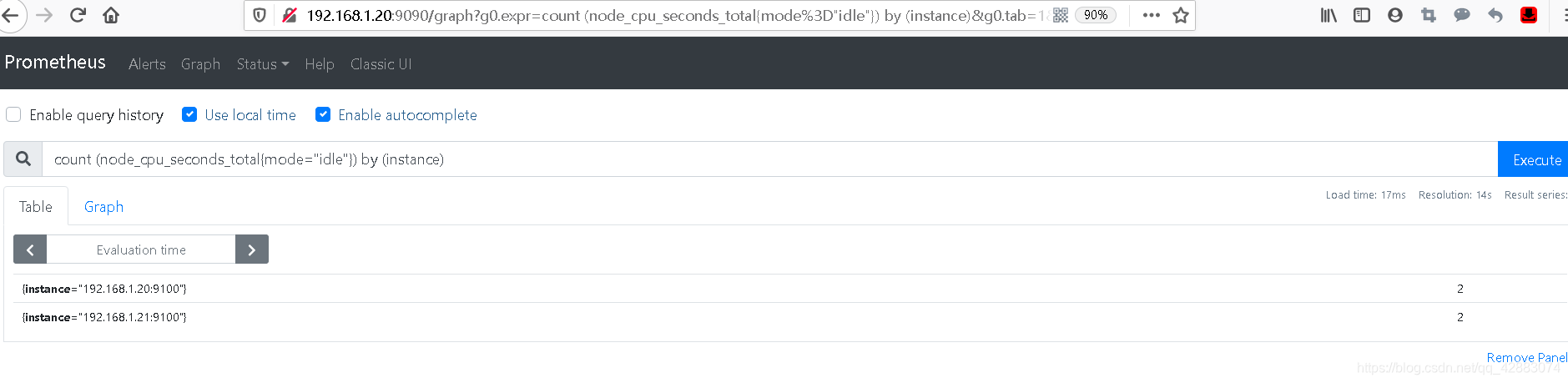
#计算cpu数量
count (node_cpu_seconds_total{mode="idle"}) by (instance)
#我这里虚机是2C的
#在linux 也查看是否正确
[root@k8s-node01 ~]# cat /proc/cpuinfo | grep processor
processor : 0
processor : 1
 4. 综合查询
4. 综合查询
#通过以上的案例综合查询
#查询1分钟内,负载超过主机cpu 2倍负载的值
node_load1 > on (instance) 2* count (node_cpu_seconds_total{mode="idle"}) by (instance)
#当然,,我负载没那么高。没有数据
#不过可以反一下,查询小于2倍负载的值来看看
node_load1 < on (instance) 2* count (node_cpu_seconds_total{mode="idle"}) by (instance)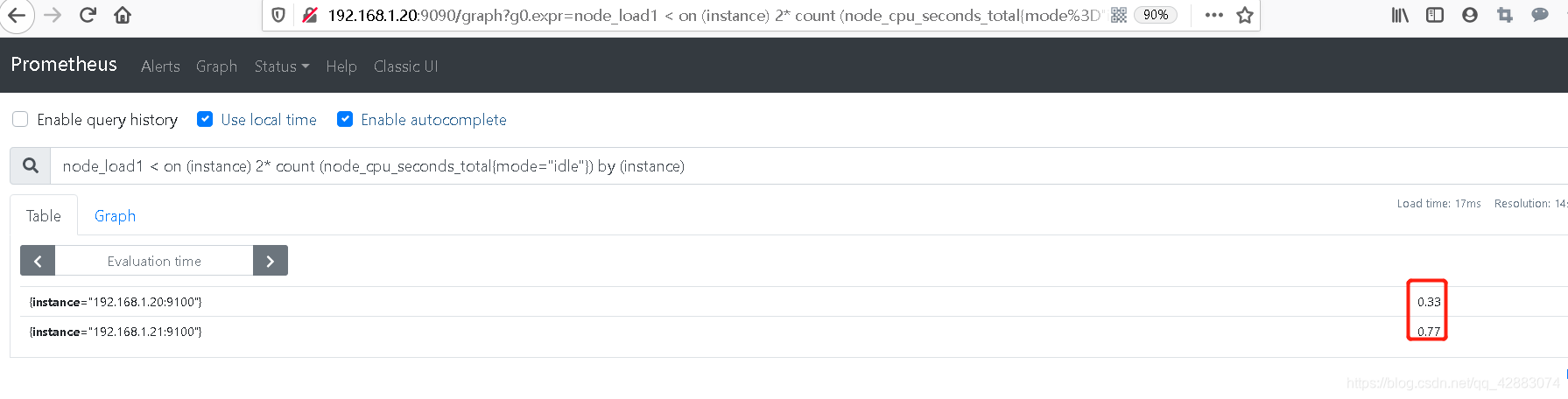
二. 内存查询
#先列一下关于内存的指标名
node_memory_MemTotal_bytes #内存总量
node_memory_MemFree_bytes #空闲内存
node_memory_MemAvailable_bytes #已用内存
node_memory_Buffers_bytes #缓冲区缓存的内存
node_memory_Cached_bytes #页面缓存中的内存1. 计算内存使用率
#总内存减去(可用的内存、缓存区缓存、页面缓存的总和)
#然后除以总内存,就是已经使用的内存的百分比
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100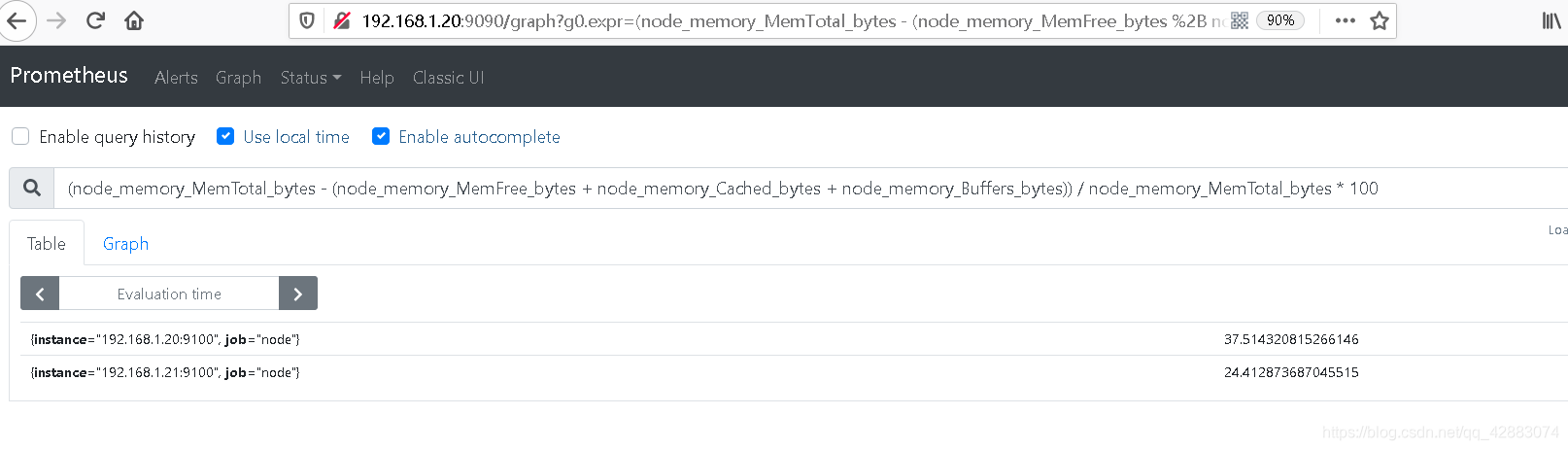
2. 计算内存饱和
#还可用通过检查内存和磁盘的读写来监控内存饱和度
#可用从/proc/vmstat收集两个node expoter指标
1. node_vmstat_pgpgin #系统每秒从磁盘读到内存的字节数
2. node_vmstat_pgpgout #系统每秒从内存写入到磁盘的字节数
#为了获得饱和度指标,对每个指标计算每一分钟的速率,将两个速率相加,然后乘以1024获得字节数
sum((rate(node_vmstat_pgpgin[1m]) + rate(node_vmstat_pgpgout[1m]))) by (instance) * 1024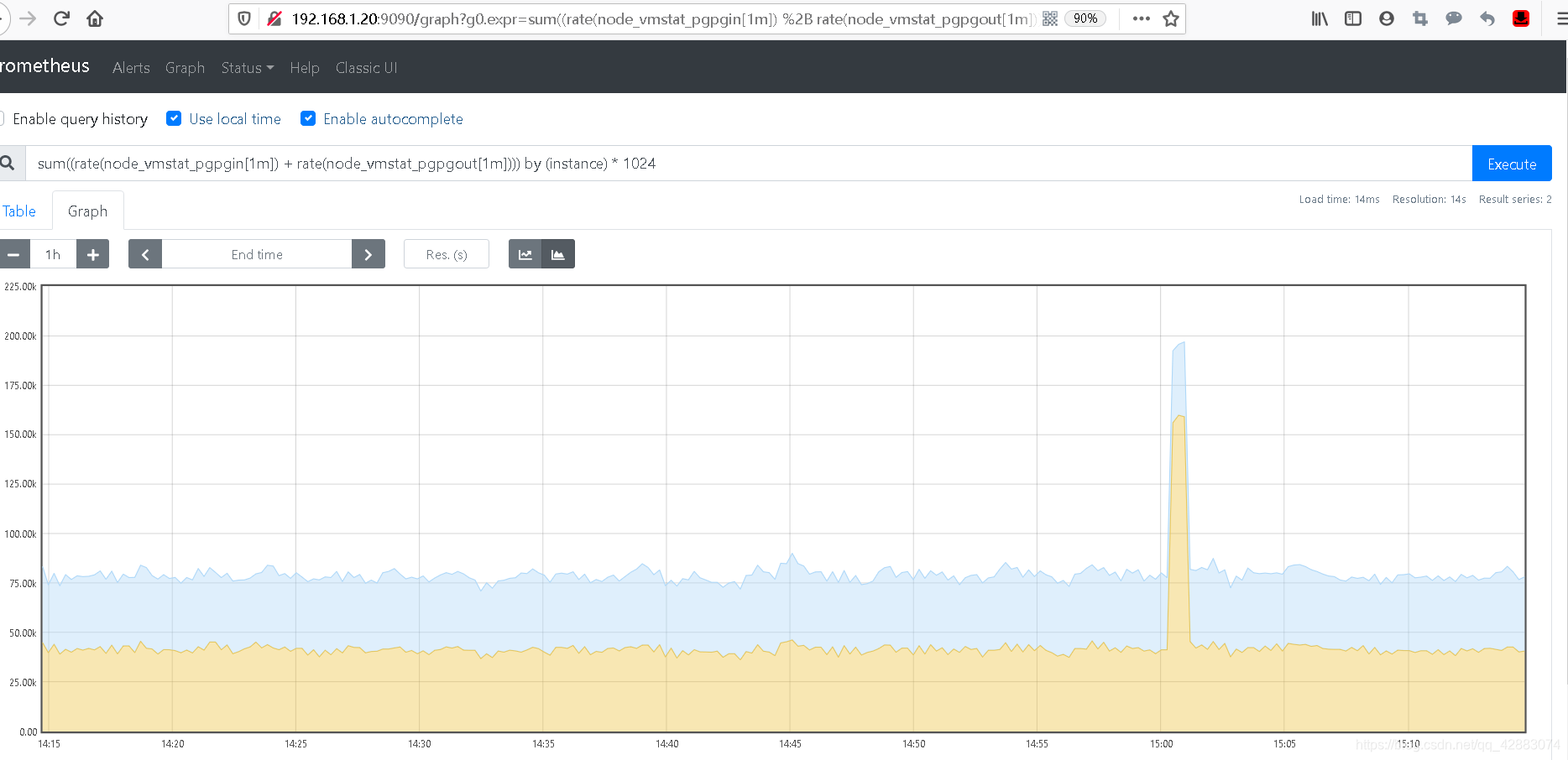
三 磁盘查询
node_filesystem_size_bytes #磁盘总容量
node_filesystem_free_bytes #空闲容量1. 查看磁盘使用率
#总容量减去空闲容量得到已用的值
#利用已用的值去除以总量得到已用的百分比
(node_filesystem_size_bytes{device=~"/.*"} - node_filesystem_free_bytes{device=~"/.*"}) / node_filesystem_size_bytes{device=~"/.*"} * 100
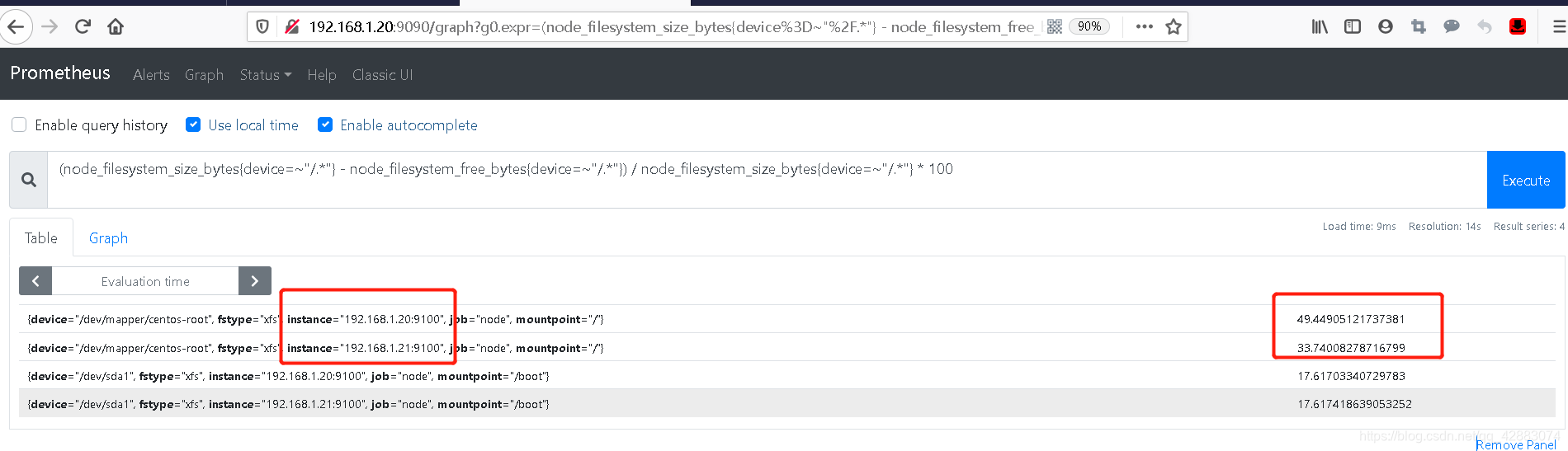
本以为这就完了,可是当我们打开linux检查的时候发现,他得到的信息都差了1%


刚开始的时候,我以为是linux计算四舍五入的原因,但是发现对比大小还是有些出入
本着强迫症的行为开始挖掘, 得知在linux中会将磁盘的容量单独分给root用,防止磁盘写满后root无法操作
#先查看节点上的详细容量大小
[root@k8s-master01 ~]# df
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17811456 8811932 8999524 50% /
#我们对比查询到的数据
#查看总容量大小
node_filesystem_size_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"} / 1024
#得到17811456
#查看可用的值
node_filesystem_free_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"} / 1024
#返回8999660 (有写入,不准确很正常)
#查看已用的值
node_filesystem_avail_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"} / 1024
#返回8999640这里发现问题了,已用的值要比df查询到的值高一部分。这部分就是我们root占用的内置分区空间
#经过上面得知,使用prometheus获取的已用磁盘是包含root的磁盘分区的
#为了和df对应,我们自己去计算已用的空间(总量-可用空间)
(node_filesystem_size_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"} - node_filesystem_free_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"})
#返回 8811868 正确
#利用返回的值去除以总量
(node_filesystem_size_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"} - node_filesystem_free_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"}) / node_filesystem_size_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"}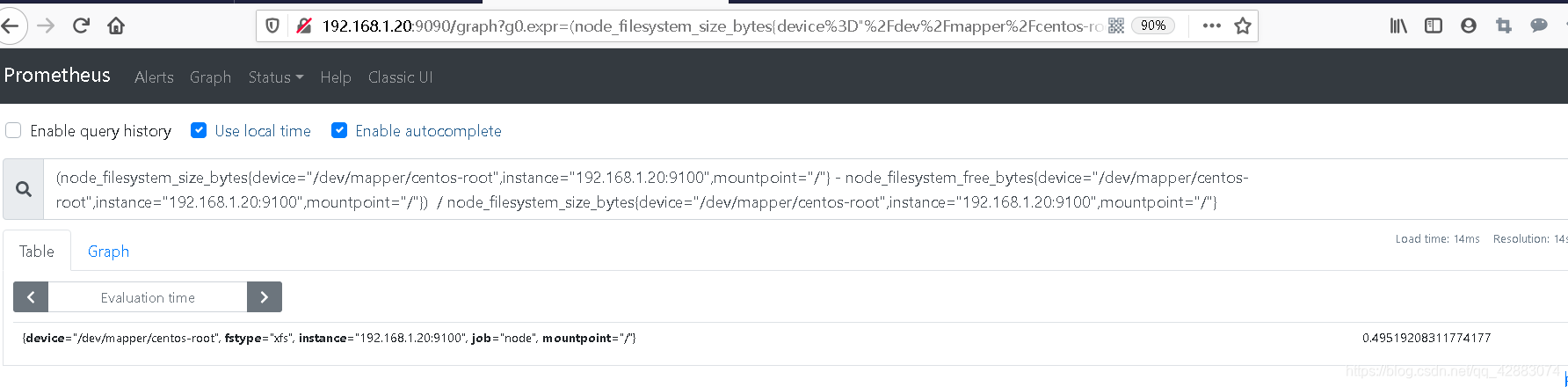
这样一来值就很接近了,我们将他化为百分比显示的话要乘100,然后做个四舍五入
round(((node_filesystem_size_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"} - node_filesystem_free_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"}) / node_filesystem_size_bytes{device="/dev/mapper/centos-root",instance="192.168.1.20:9100",mountpoint="/"}) * 100)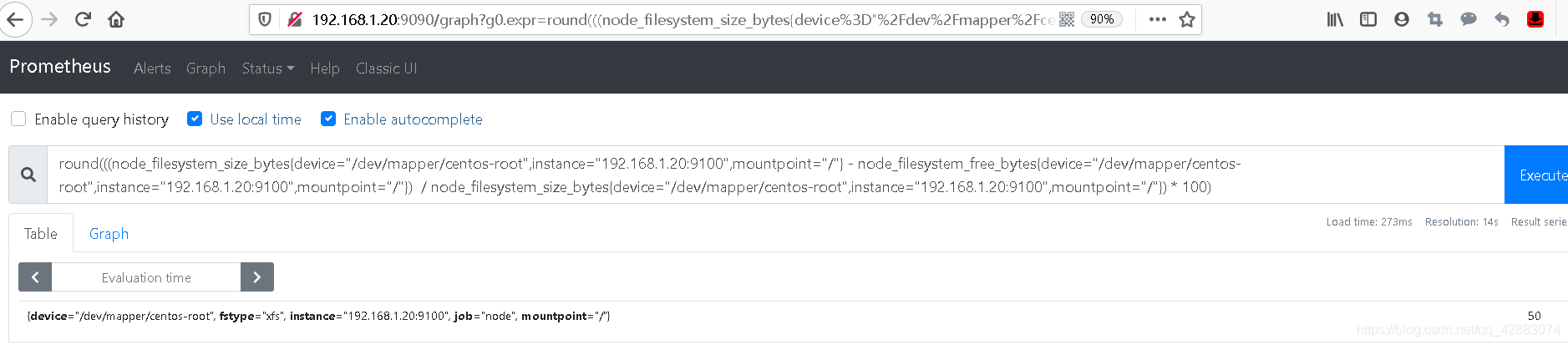
大成功 (≧∀≦)ゞ
2. 监控挂载点
我们可以通过"|" 来设置获取的是那些分区的信息
#通常我们希望去监控某几个挂载点的状态,如下 监控"/"分区的状态
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"}
#但当我们去模糊匹配时过滤又会比较麻烦
node_filesystem_size_bytes{mountpoint=~".+"}
#如下,通常我们不希望去获取tmpfs的信息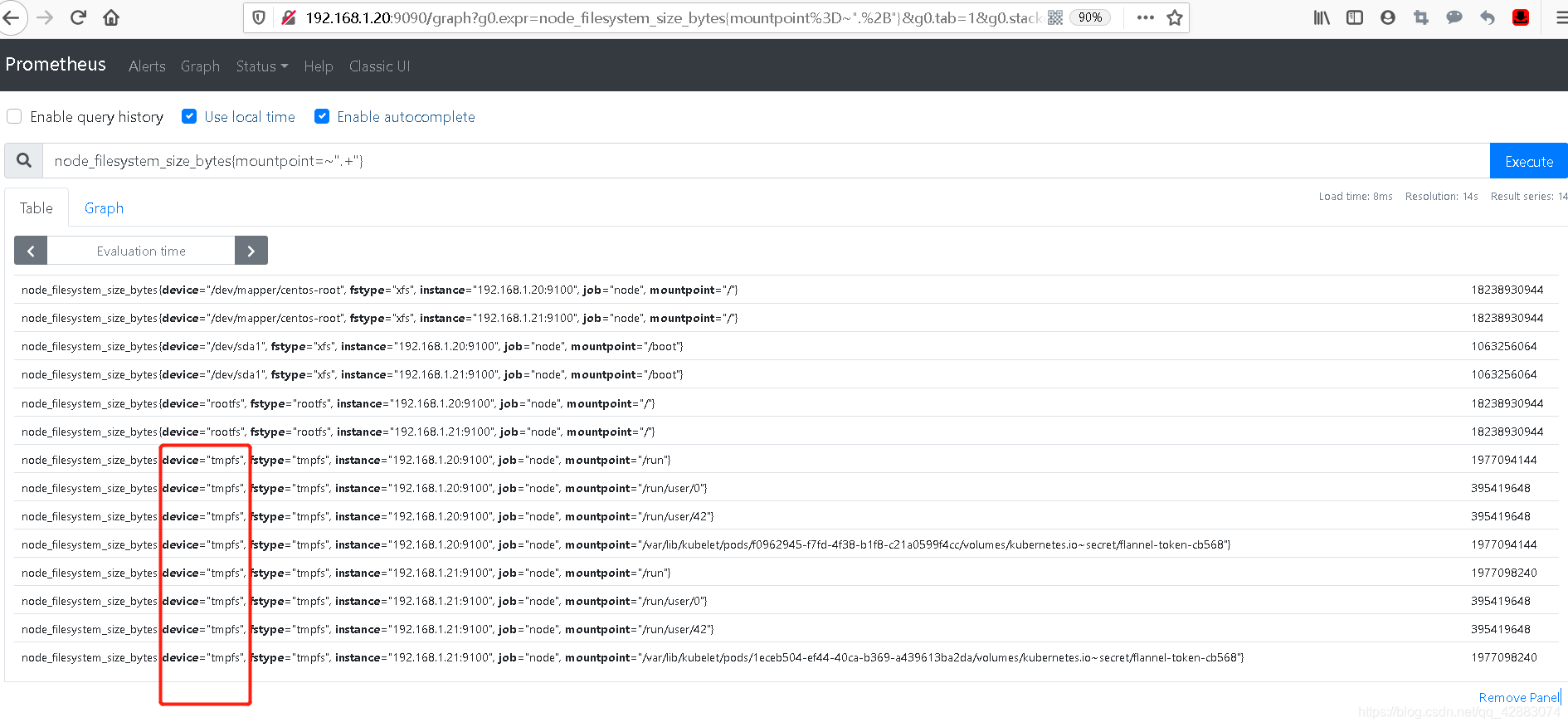
#我们可以利用"|"号去决定匹配信息,如
node_filesystem_size_bytes{mountpoint=~"/|/boot"}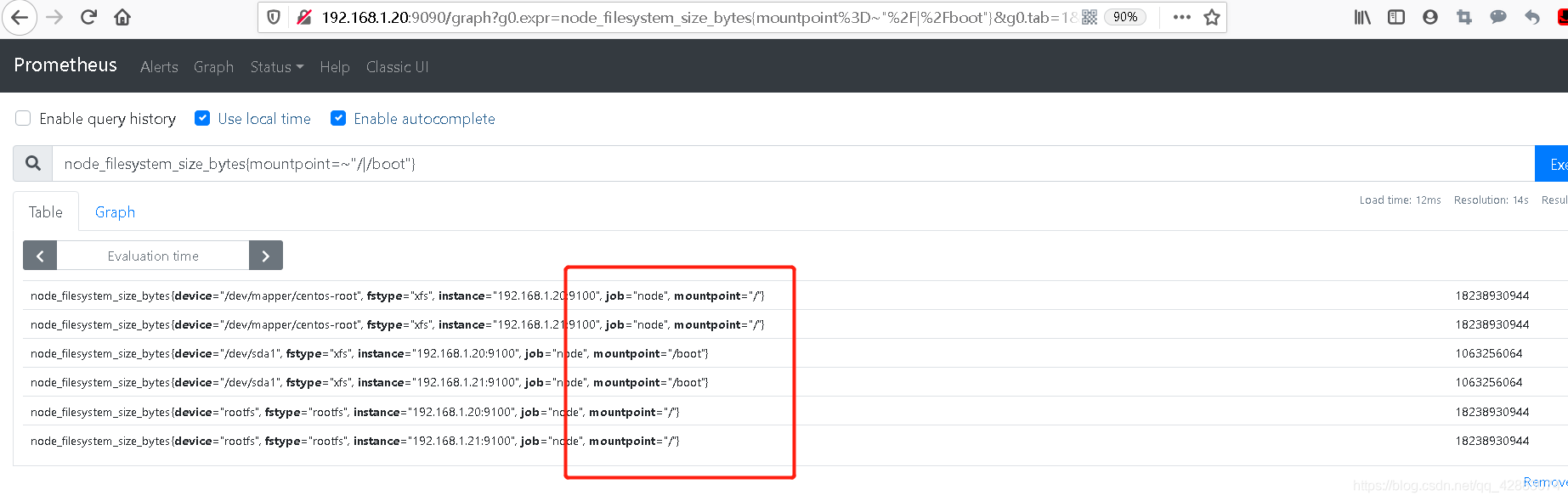
3. 磁盘使用空间预测
通过predict_linear函数 基于一段时间内的写入效率来预测多久磁盘会占满
#基于5分钟的写入速率预测可用磁盘空间在4个小时后空间大小的值是否大于100
predict_linear(node_filesystem_free_bytes{instance="192.168.1.21:9100",mountpoint="/"}[5m],4*3600) > 100
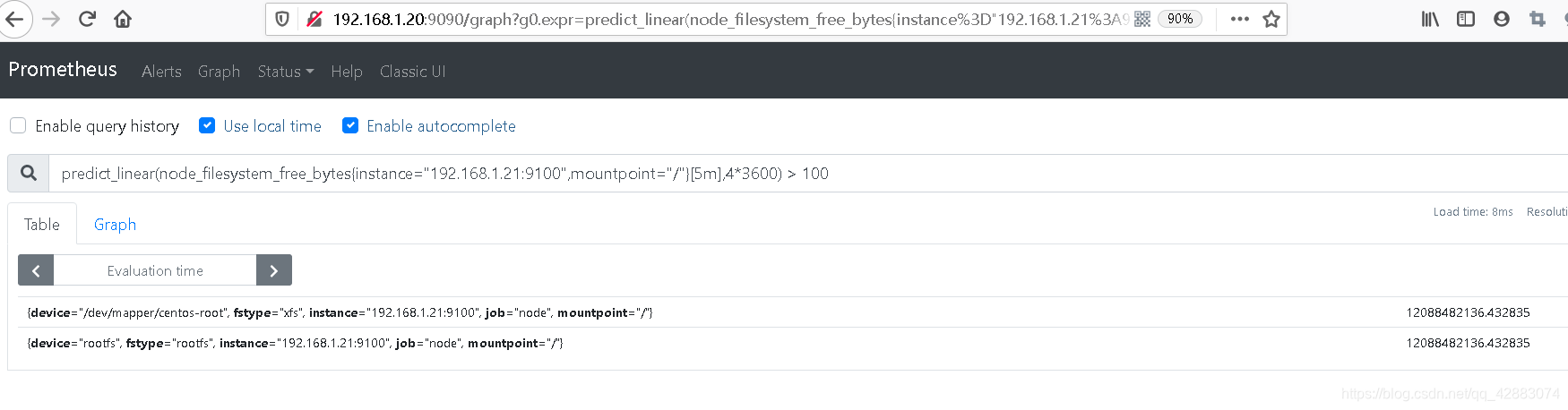
#可以看到是有数值的,这个数值是经过4个小时后可用空间的大小
#为了方便验证,我们写入一些大文件来测试
#我们这里在192.168.1.21节点写入5个G的文件
dd if=/dev/zero of=test4 bs=1M count=5000 seek=100000
#然后我们将语句改一下 大于改为小于
#查看4个小时候可用空间的容量如下
predict_linear(node_filesystem_free_bytes{instance="192.168.1.21:9100",mountpoint="/"}[5m],4*3600) < 100
#下图中我们可以看到,4个小时后可用空间的值为负数说明他的使用空间会溢出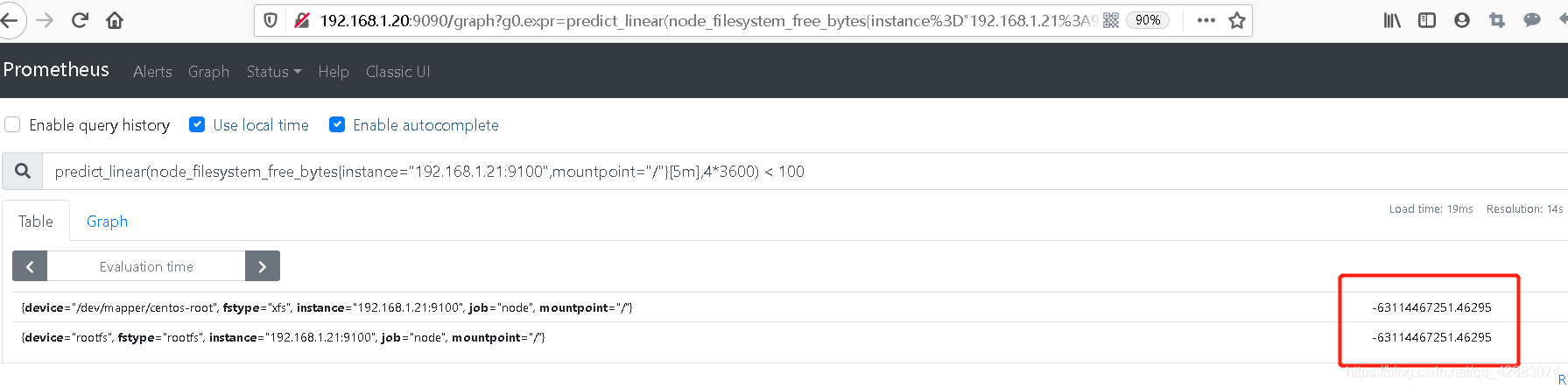
四. 服务查询
通过对服务的状态进行监控报警
1. 查询服务运行状态
#查看服务的状态
node_systemd_unit_state{instance="192.168.1.21:9100", name="docker.service"}
#当服务处于某个状态时,该状态的数值为1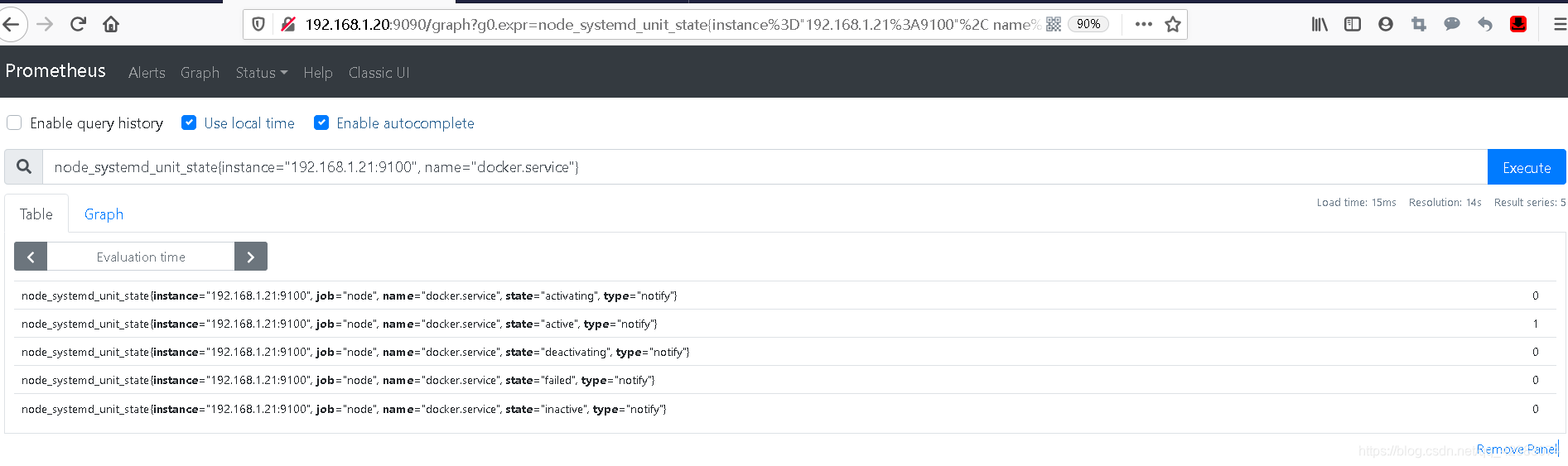
#我们可以去对比该制来判断服务处于一个什么状态
node_systemd_unit_state{instance="192.168.1.20:9100",name="docker.service"} == 1
#如下状态为 state="active" 运行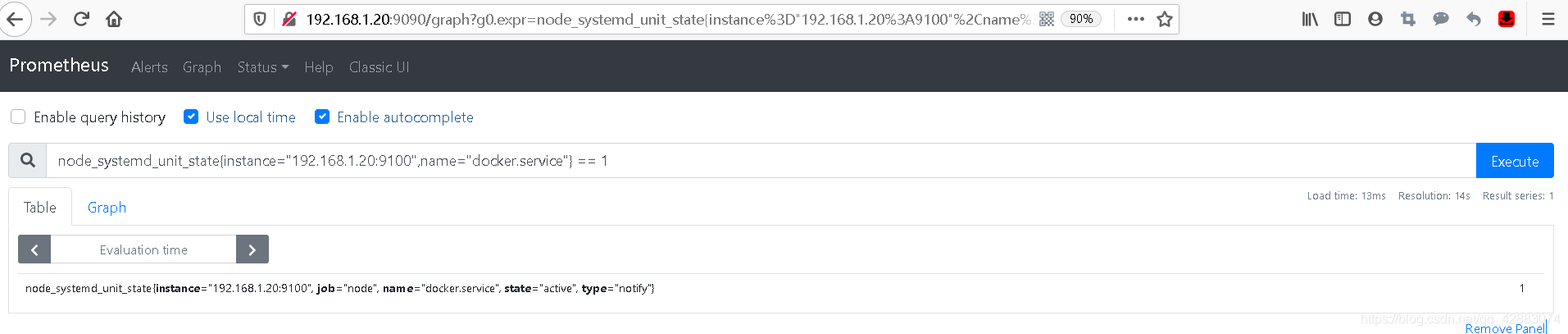
2. 查看服务节点运行状态
#通过up指标可以查询prometheus监控的节点的状态
up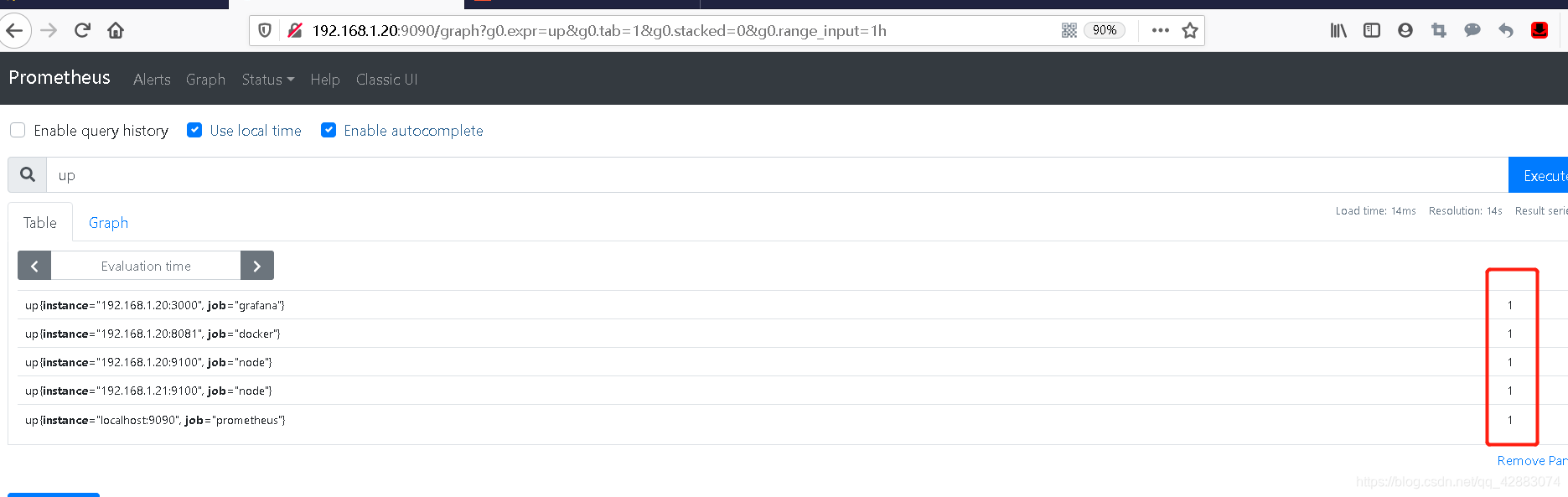


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









