







 本文全面介绍了数据库开发周期,包括需求定义、概念设计等阶段。深入探讨了E-R模型及其转换为关系模型的方法,讲解了键、参与约束的概念,并讨论了数据库物理设计、事务管理等内容。
本文全面介绍了数据库开发周期,包括需求定义、概念设计等阶段。深入探讨了E-R模型及其转换为关系模型的方法,讲解了键、参与约束的概念,并讨论了数据库物理设计、事务管理等内容。
文章目录
- 数据库开发周期(Database Development LifeStyle)
- 需求定义和分析(Requirements Defination and Analysis)
- 概念设计(Conceptual Design)
- 逻辑设计
- 物理设计
- 应用设计
- 实现(implementation)
- MySQL构建数据库模型
- 关系代数 (relational algebra)
- SQL 语言
- 存储和索引
- (cost + result size)数据库开销 + 表格尺寸计算
- Normalization
- Database Transaction(数据库事务)
- 数据库管理(Database Administration)
- Data Warehousing(数据仓库)
数据库开发周期(Database Development LifeStyle)
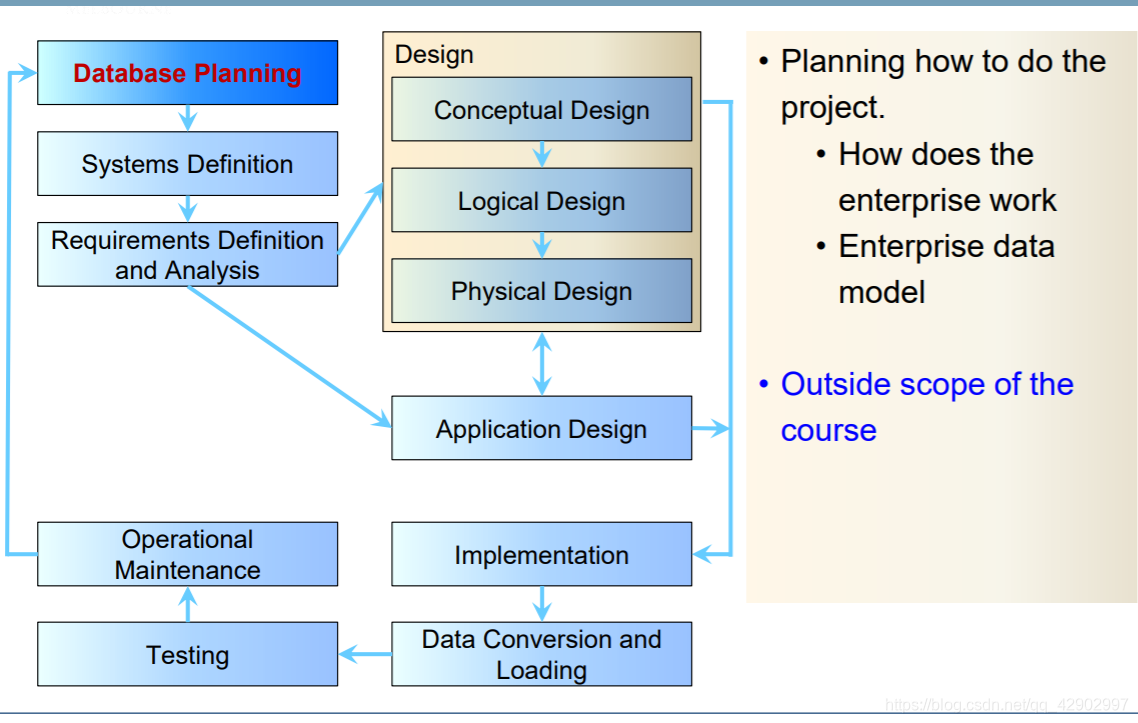
需求定义和分析(Requirements Defination and Analysis)

概念设计(Conceptual Design)

○ E-R 模型(E-R 图)
结构介绍
- 基本结构:实体、关系、属性
- 附加结构:弱实体

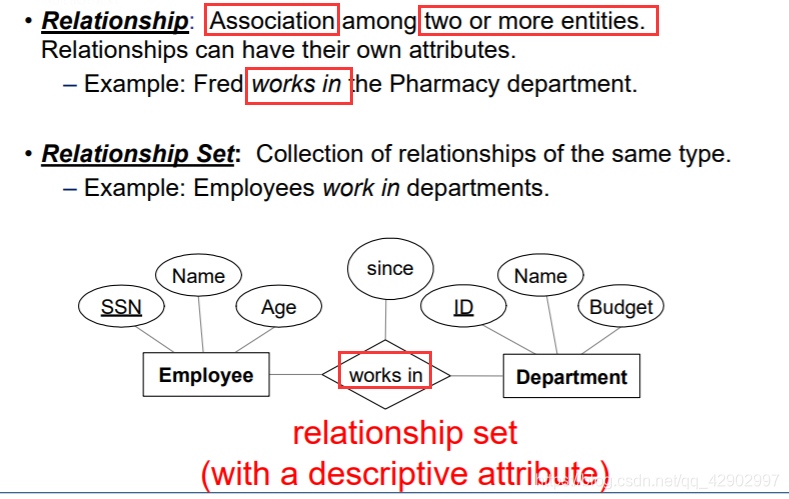
实体、实体集(entities)

关系、关系集(relationships)
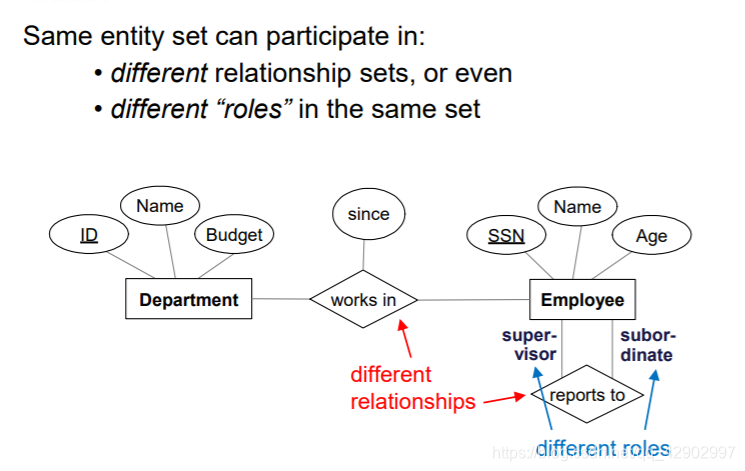
约束(key constrains)
多对多
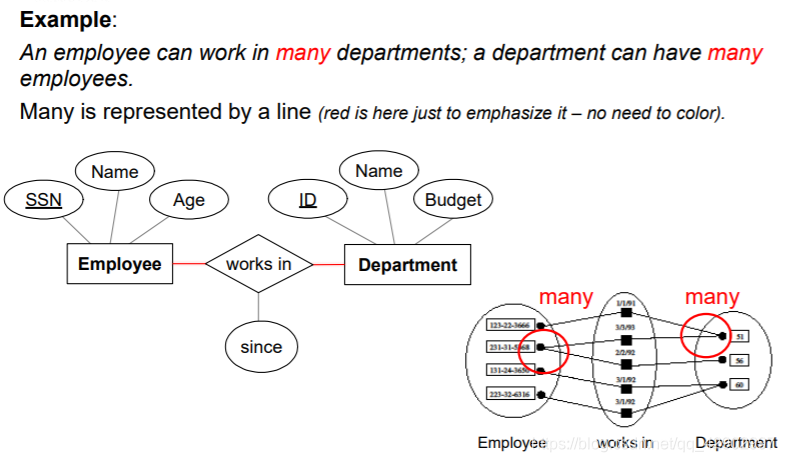
一对多
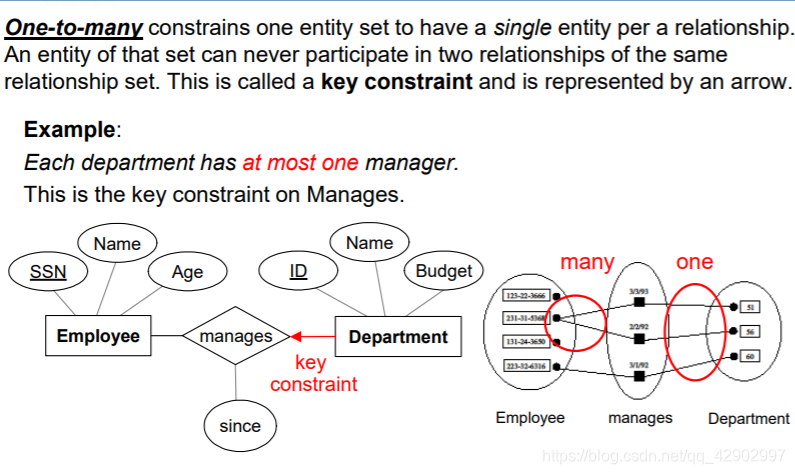
参与约束(participation constrains)
- 完全参与
- 不完全参与
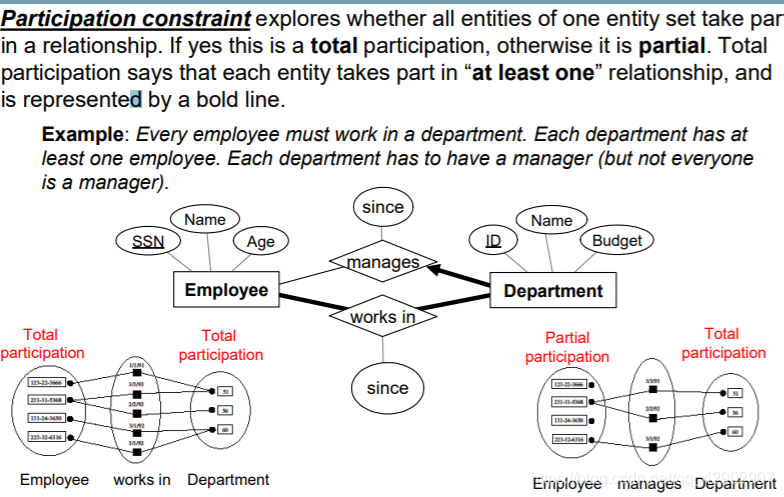
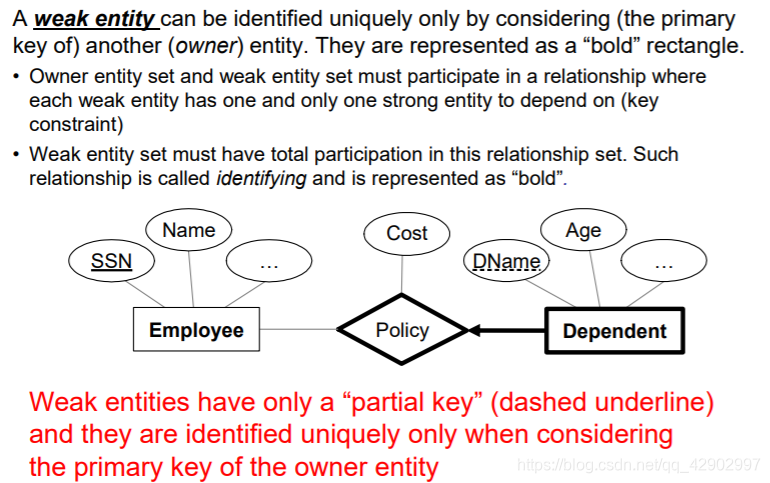
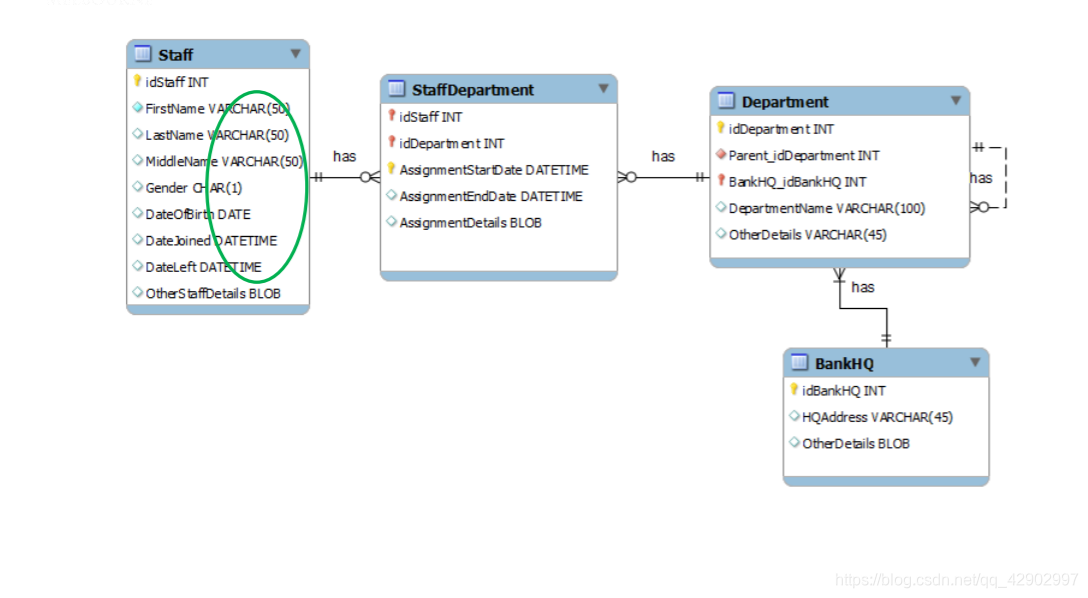
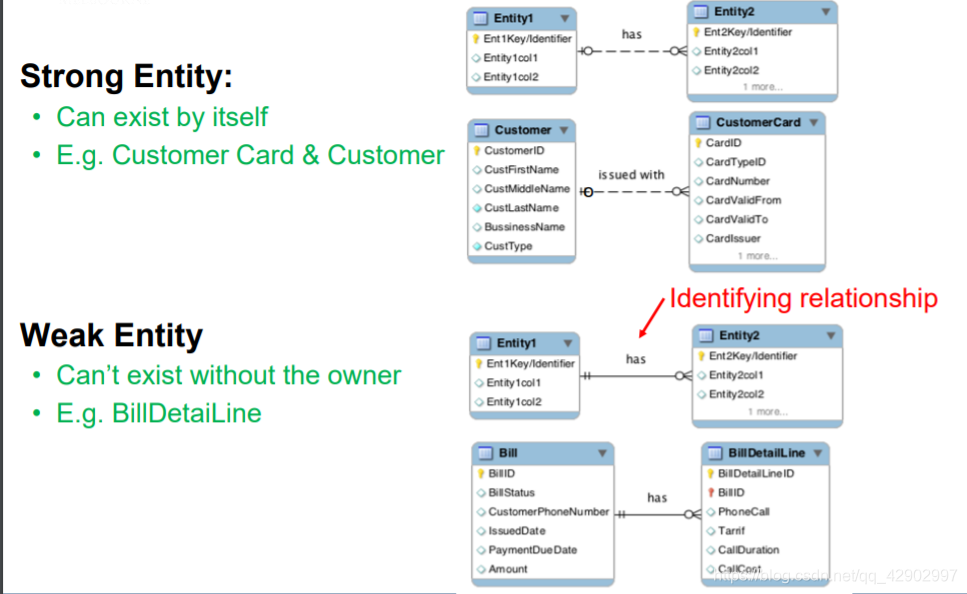
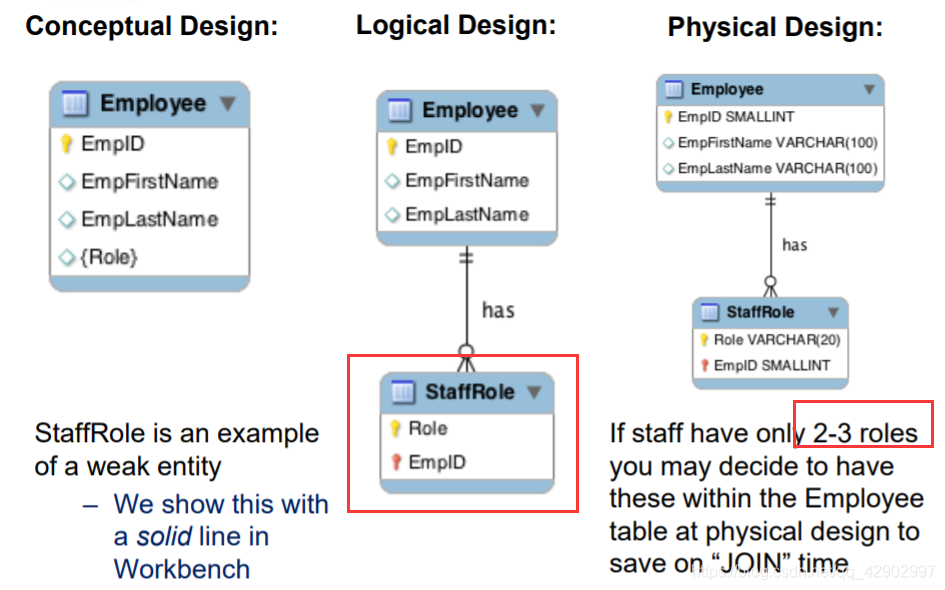
弱实体
- 由于弱实体一定是完全依附于另外一个实体集,因此,弱实体的出现常常伴随着一对多的关系。
- 弱实体没有严格意义上的主键,只有部分键(partial key);只能依附于其他实体的主键,并且和它的 owner 实体的主键一起组成可以唯一标识 “行” 的键
- 弱实体的 partial key 使用下划的虚线表示
- 弱实体使用加粗的长方形表示
- 弱实体和强实体之间的关系也用加粗的线框表示,被称为 “identifying(标识)”
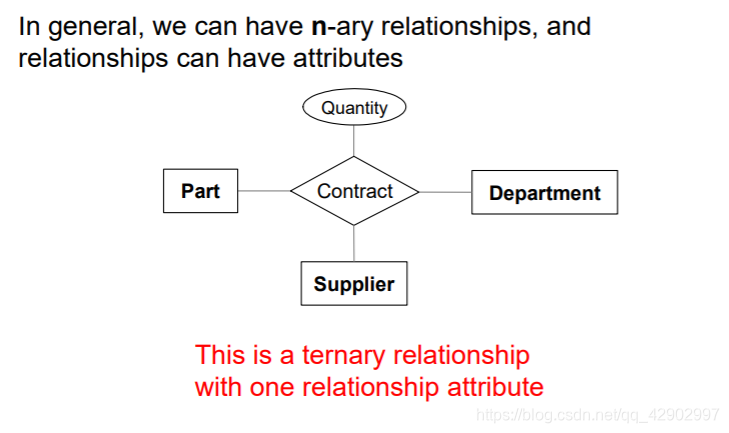
多元关系
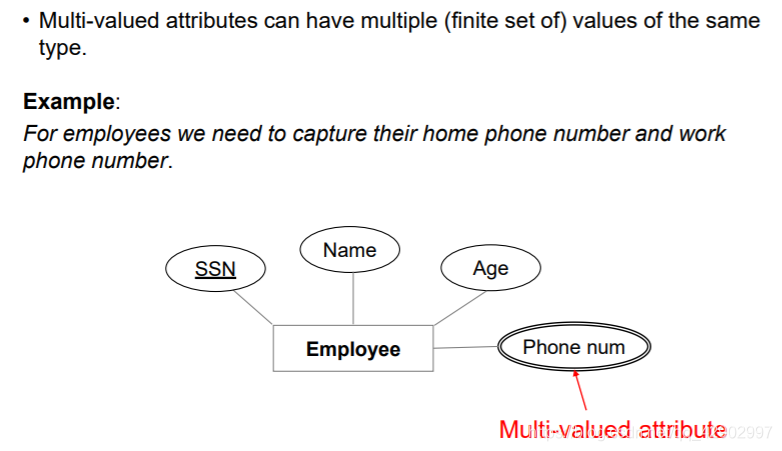
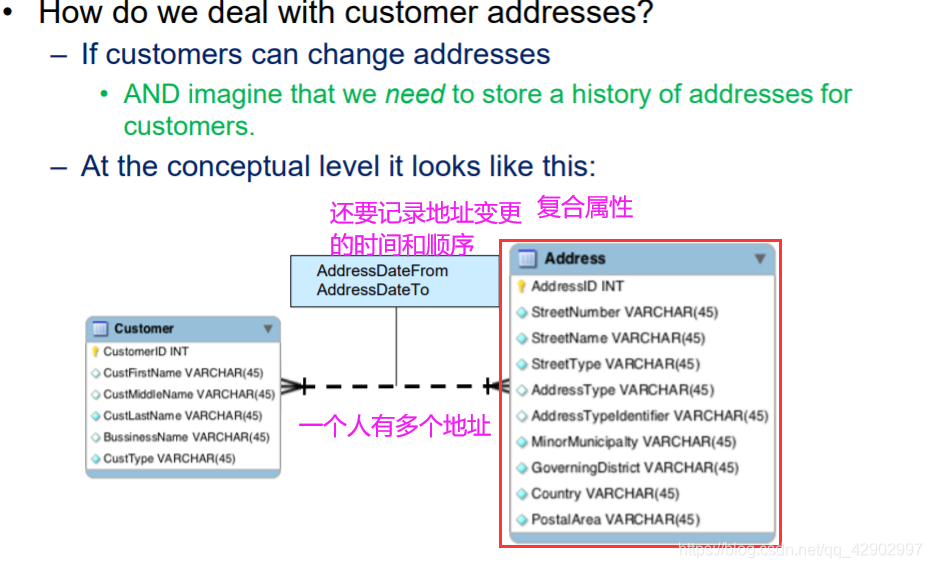
多值属性(Multi-Valued Attributes)
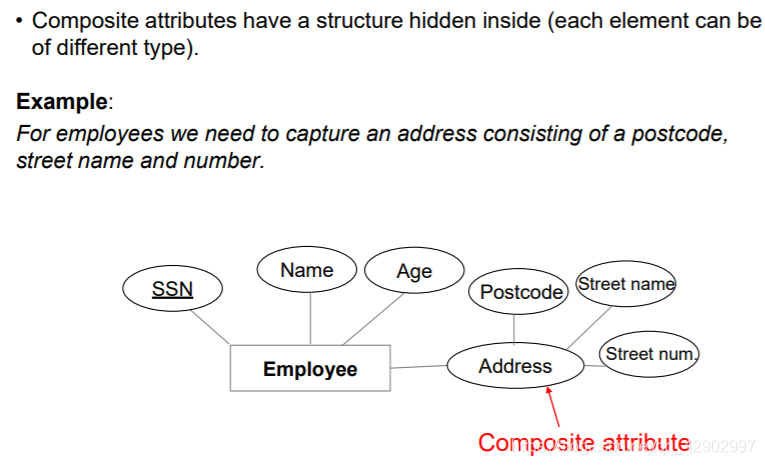
复合属性(Composite attributes)
E-R图设计步骤


逻辑设计

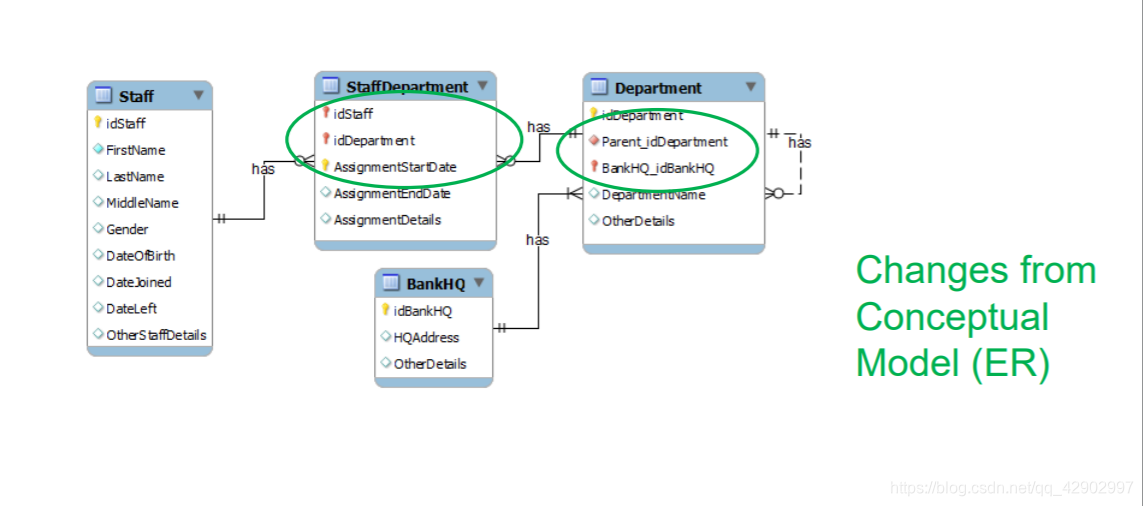
○ 关系模型(Relational Model)

关系(relation)

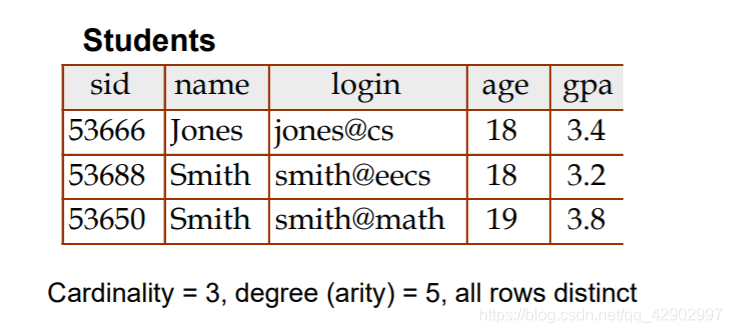
- 基数(cardinality):行数,一个关系中存在的 不同的行数
- 度(degree):列数,相当于 E-R 模型中的 attributes
关系型数据库(relational database)

E-R 图转为 Relation
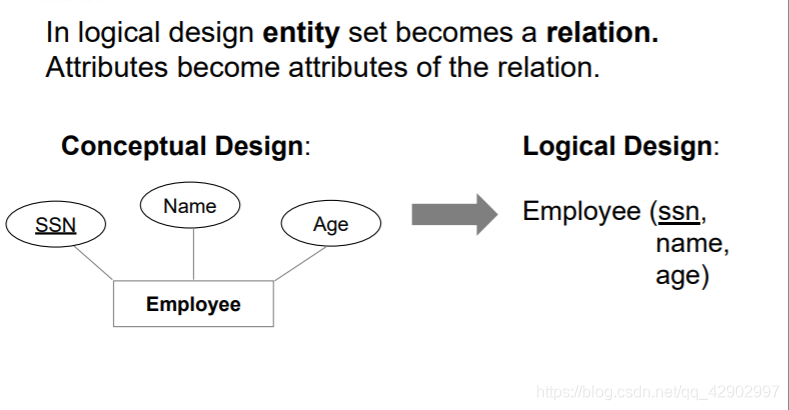
E-R 图 → 逻辑设计 → 物理设计 → 实现 → 创建实例
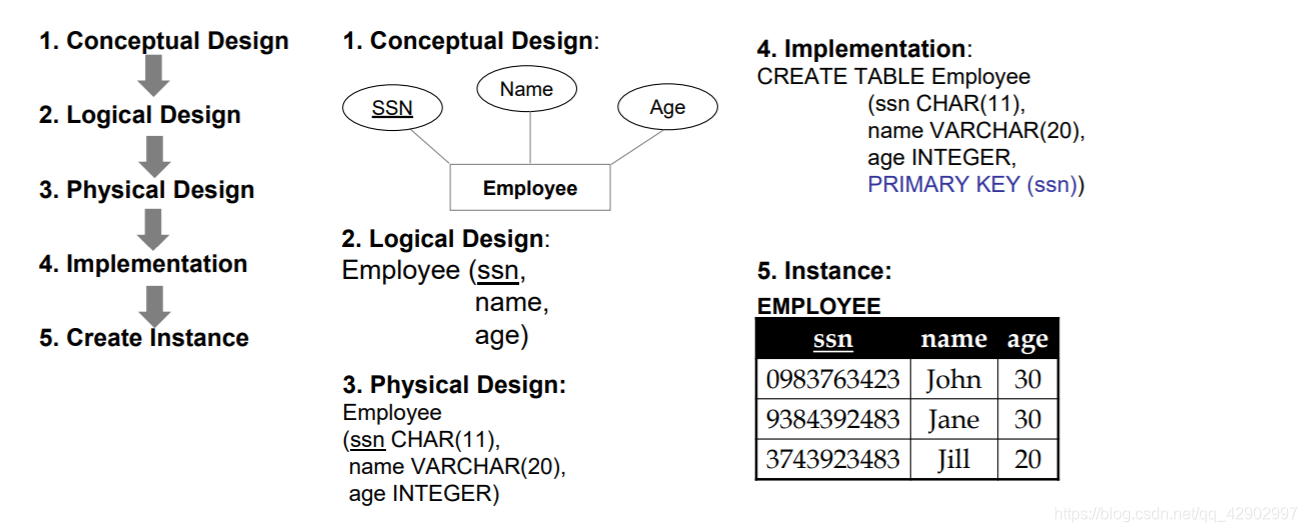
使用 SQL 语句创建一个 Relation

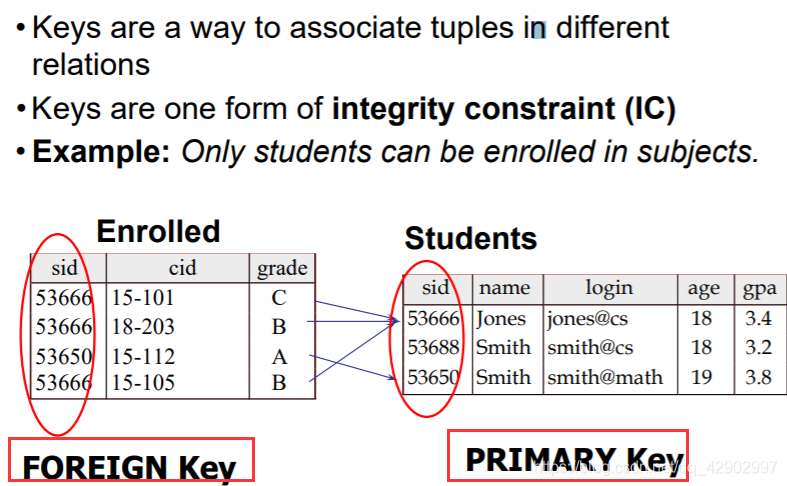
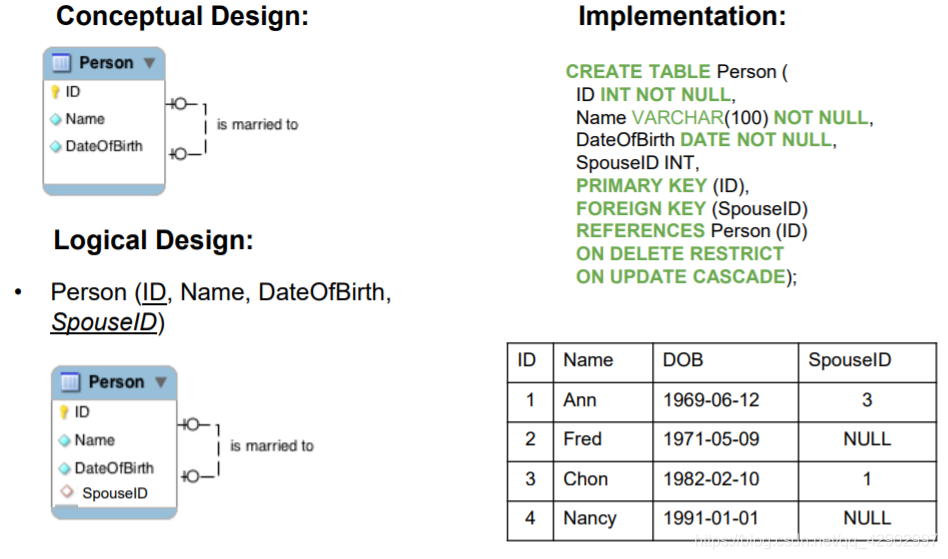
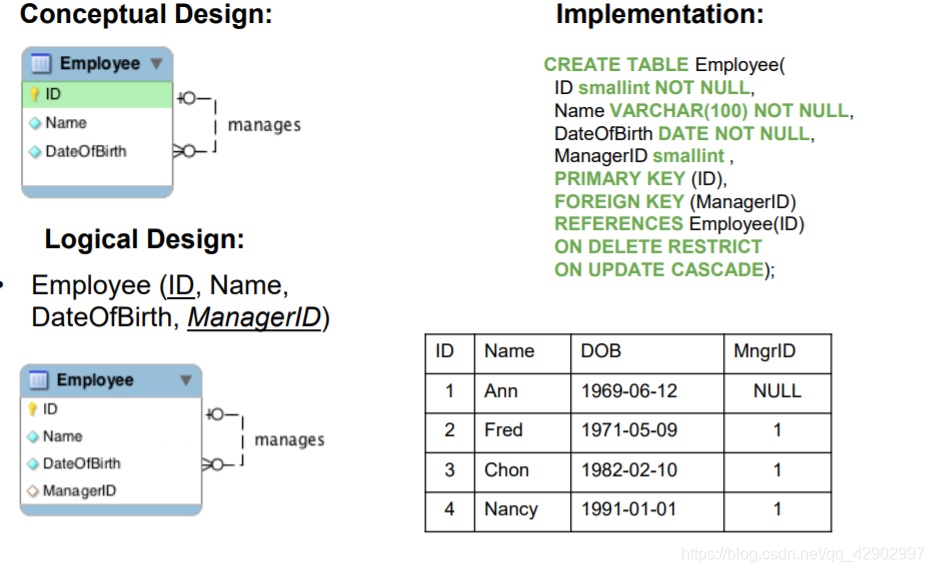
键 和 键的完整性约束(Integrity constrains)
键(key)
- 通过键 key 来创建表项之间的链接,使得我们可以通过一个表查到另一个表
- 键是实现关系模型中 “完整性约束” 的一种重要方式
超键(superkey)

- 超键可以是一个单独的键,也可以是好几项属性组合的键;只要能保证行的唯一性标识即可
键(key)
- 最小的超键叫做键

- 主键(primary key)
- 最小超键中选出一个作为主键(primary key)
- 候选键(candidate key)
- 最小超键中除了主键之外的键叫候选键



外键(Foreign key)


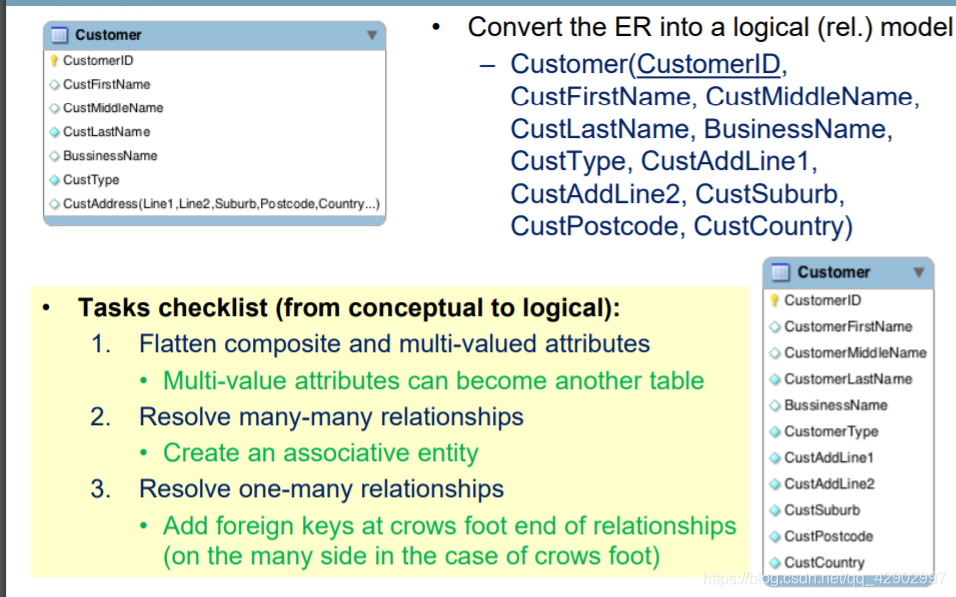
多值属性和符合属性的处理
- 多值属性要进行展开
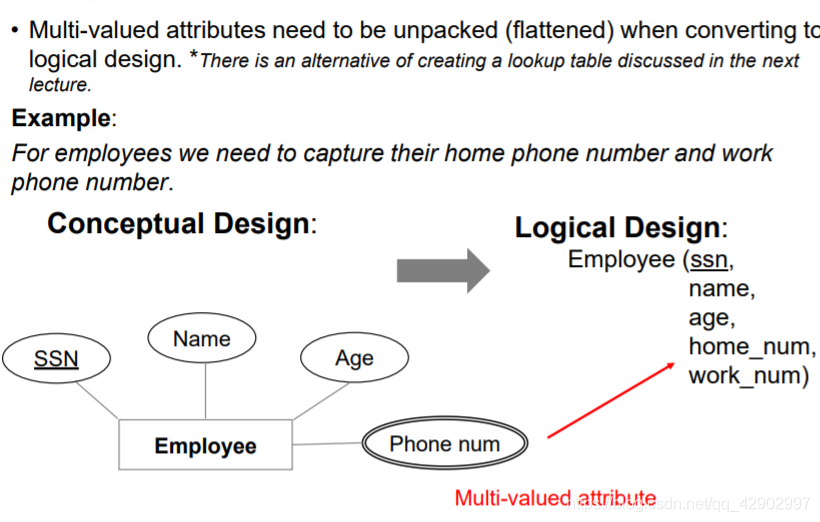
- 复合属性也要展开
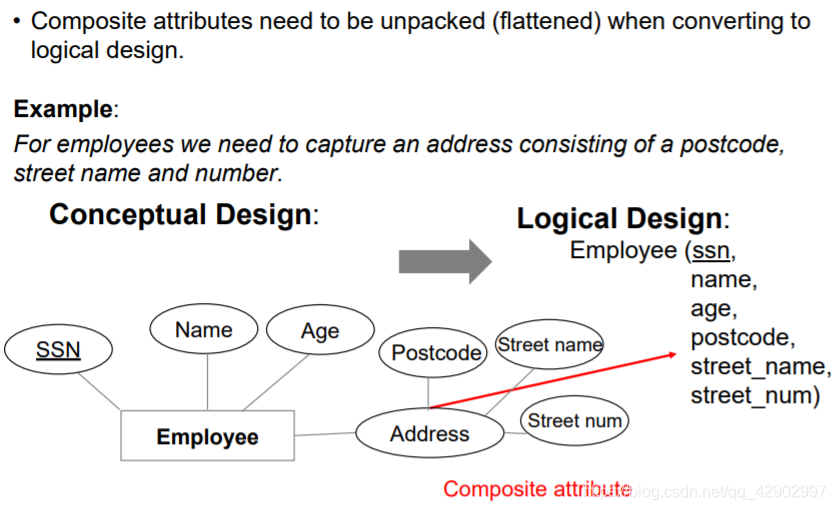
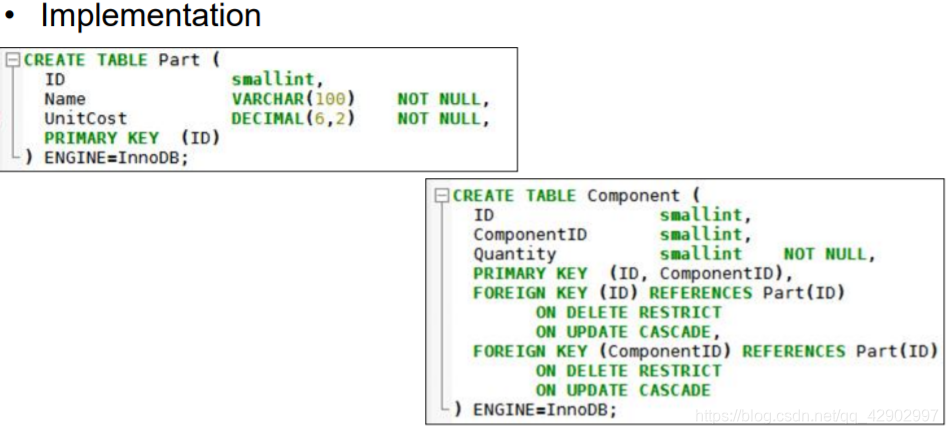
E-R 图转为逻辑设计图的原则
- 建立多对多关系的时候,注意主外键的使用
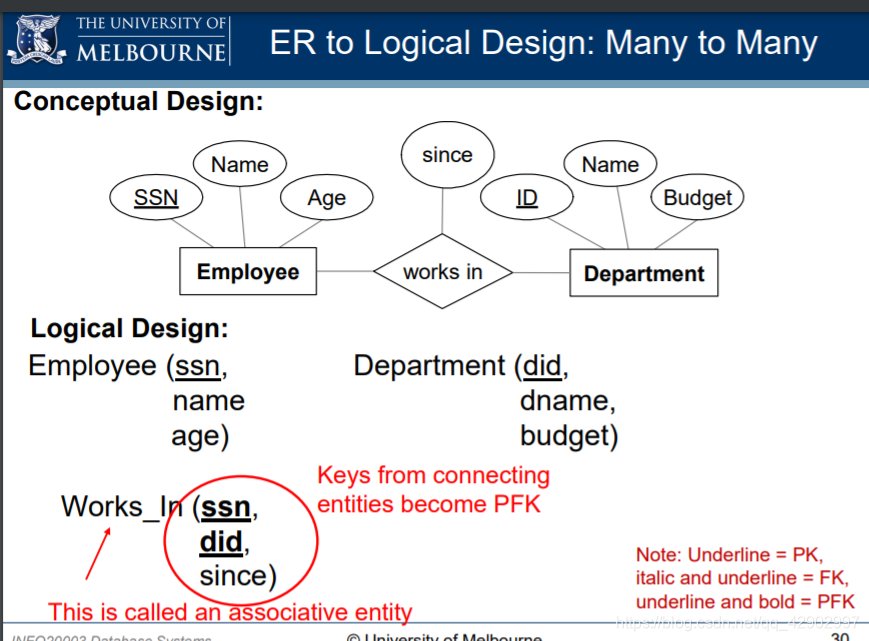


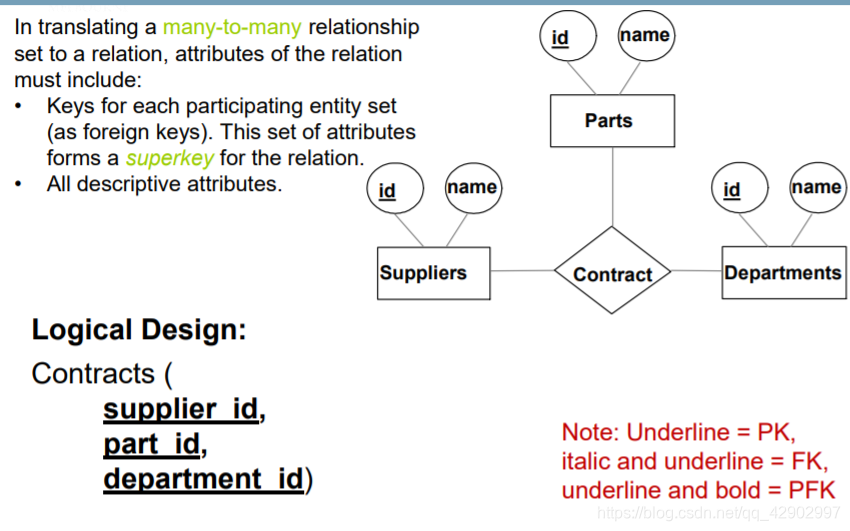
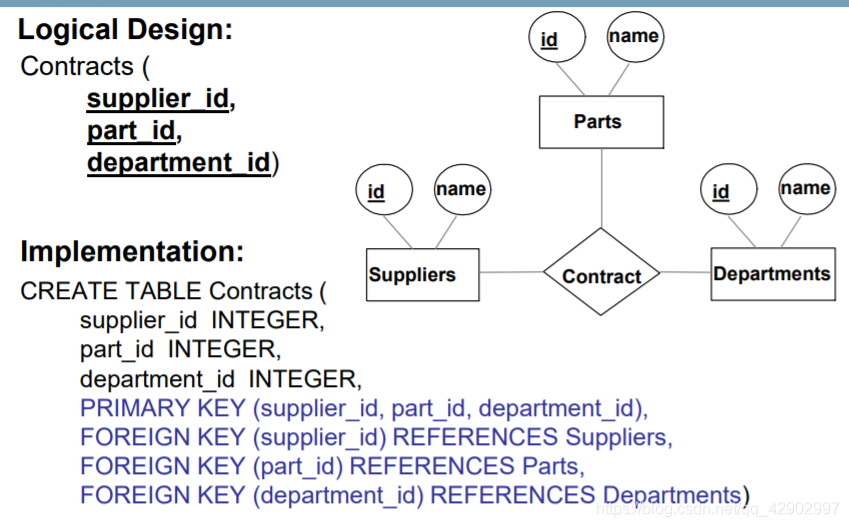
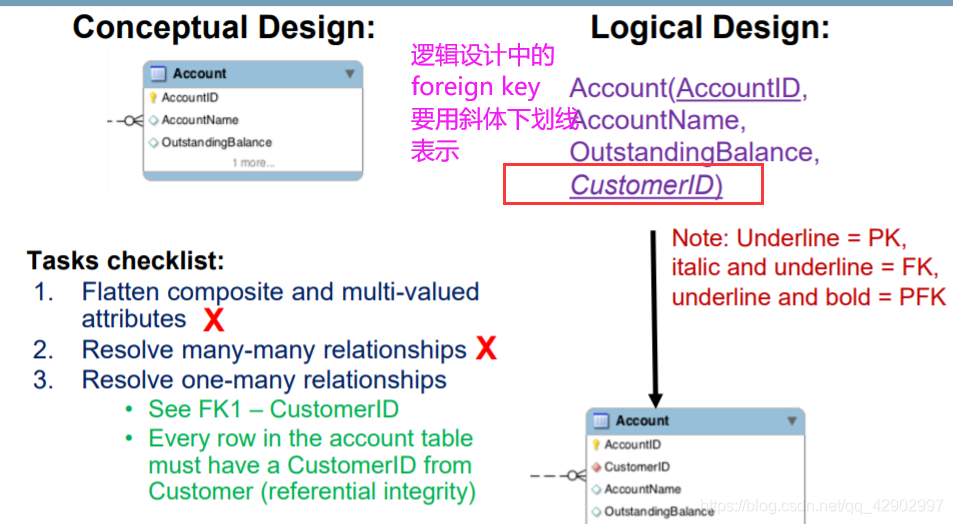
关系图中的键约束(key constraints)
- E-R 图中的键约束如图
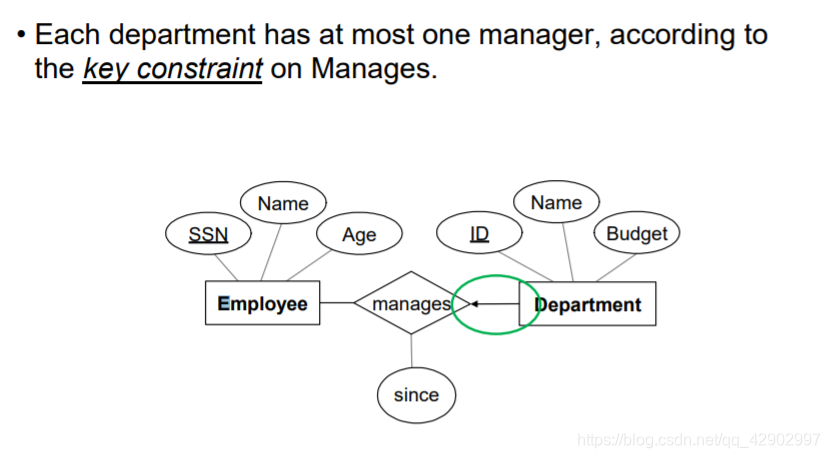
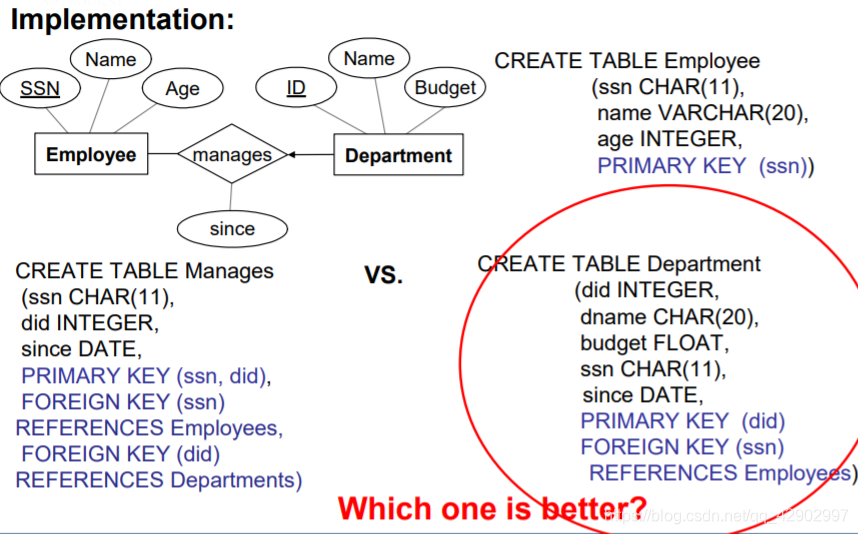
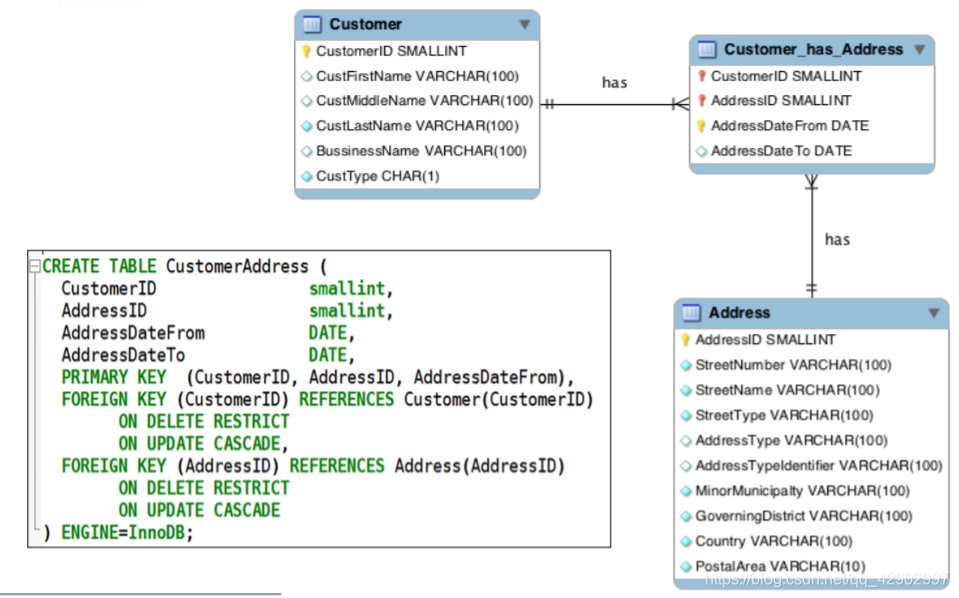
- 当面对键约束的时候我们将外键的引用放在有键约束的 table 中,而不是放在中间的描述关系中。
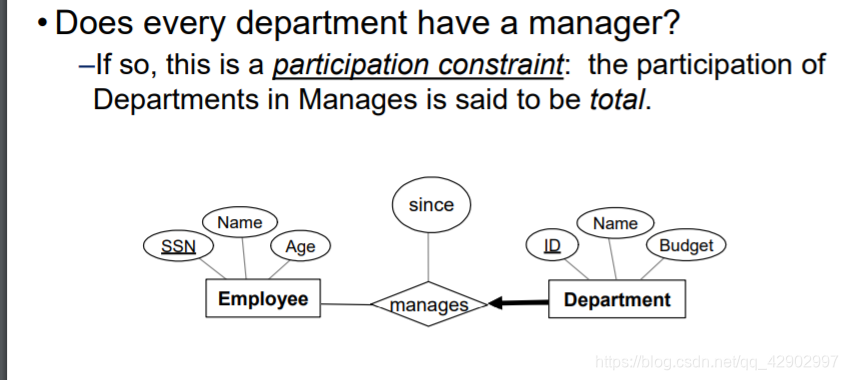
关系图中的参与约束(participation constraints)
- 使用 NOT NULL 来表示完全参与

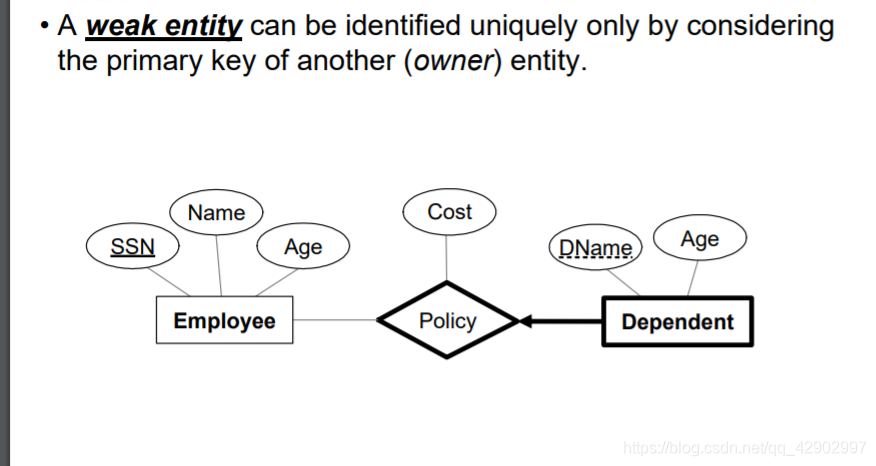
关系图中的弱实体(weak entity)
- 弱实体的键和强实体的键一起组成弱实体的主键
- 通过外键引用强实体主键
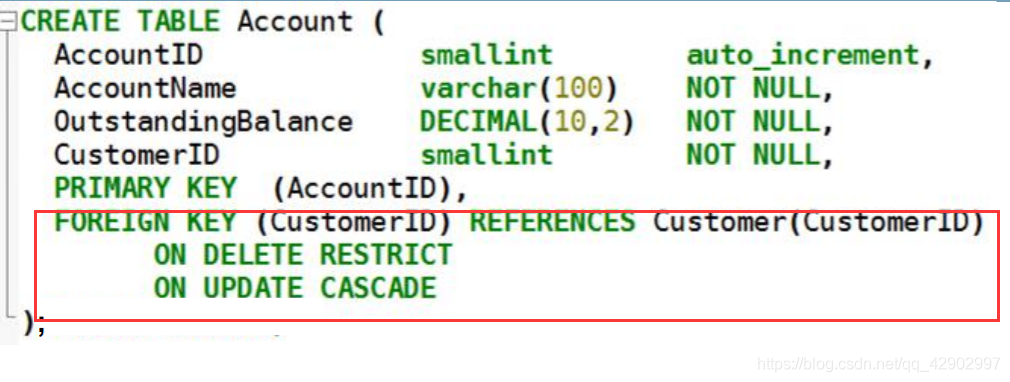
- 通过 ON DELETE CASCADE 来强绑定弱实体和强实体,每次强实体删除弱实体也消失

物理设计

数据类型选择
- 考量标准

- 类型


Look up Table 构建
Normalization / de-Normalization

应用设计

实现(implementation)

MySQL构建数据库模型
基本表示
实体、属性

关系、约束

强实体、弱实体
多元关系的(N-nary relationship)设计原则
- 多值属性和复合属性的项目必要的时候可以单独成表
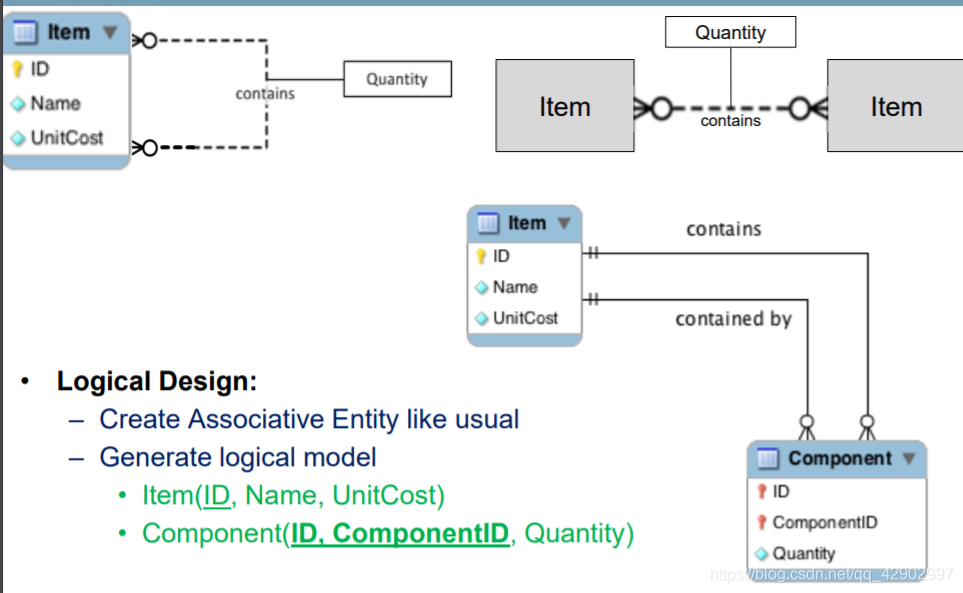
- 多对多的关系,可以在中间引入一个关系实体来解决
- 一对多的关系,可以把外键和关系属性放在 crows foot 中 “many” 的那一端
多值属性的处理原则
- 单独将多值的属性建立一张表
- 如果多值属性只有两到三个不同的值,完全可以放在同一张表里
多对多关系的处理原则
- 如果一个人有多个地址,每个地址有是个复合属性,那么完全可以建立人和地址的多对多关系
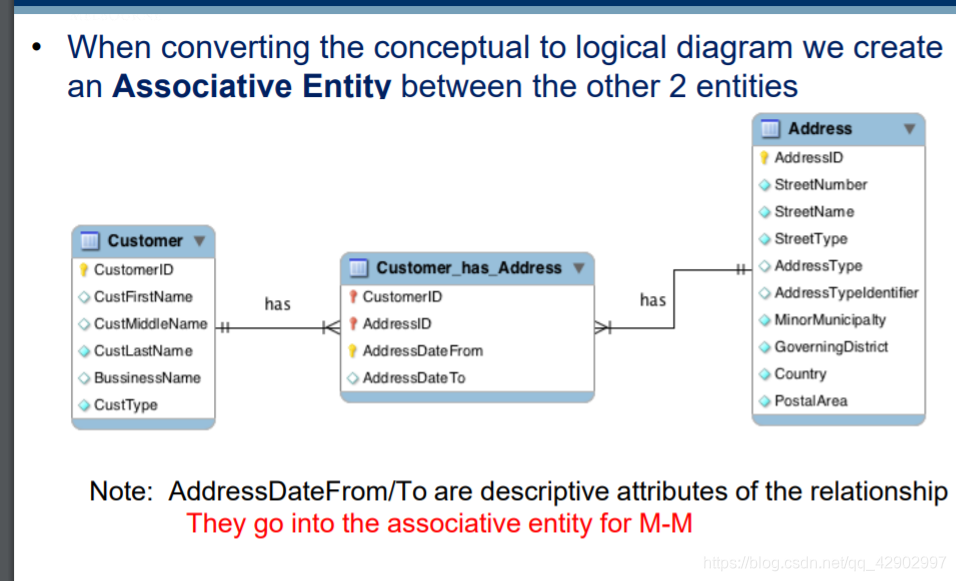
- 多对多逻辑模型
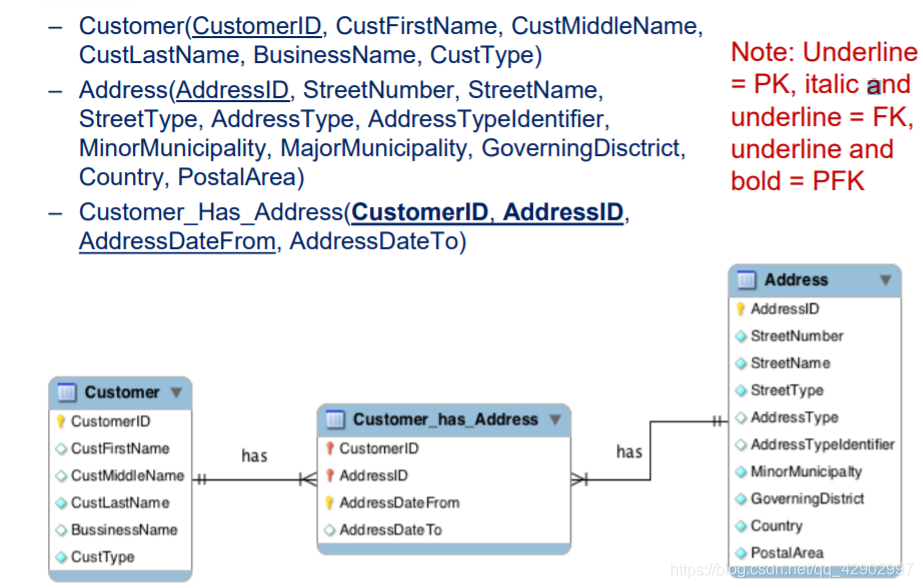
- 多对多关系实现
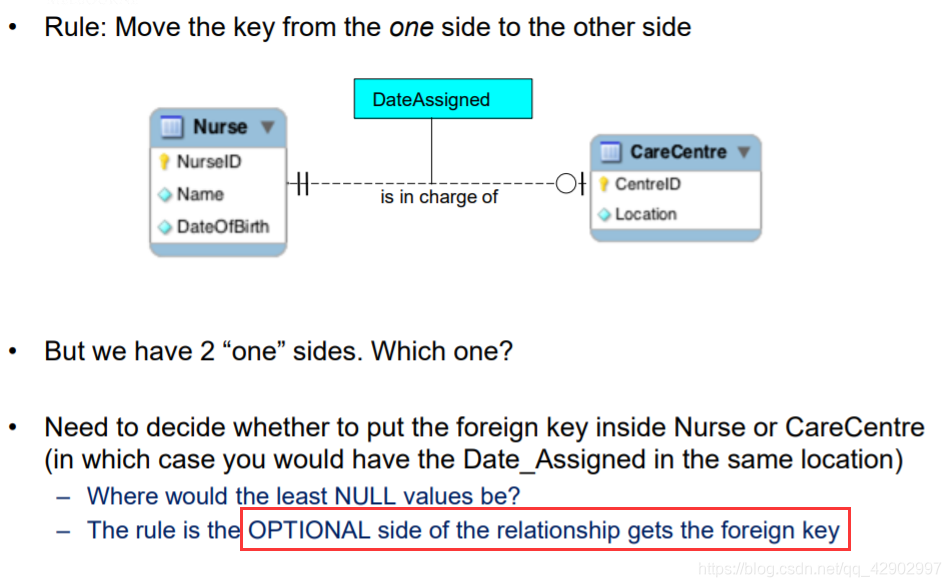
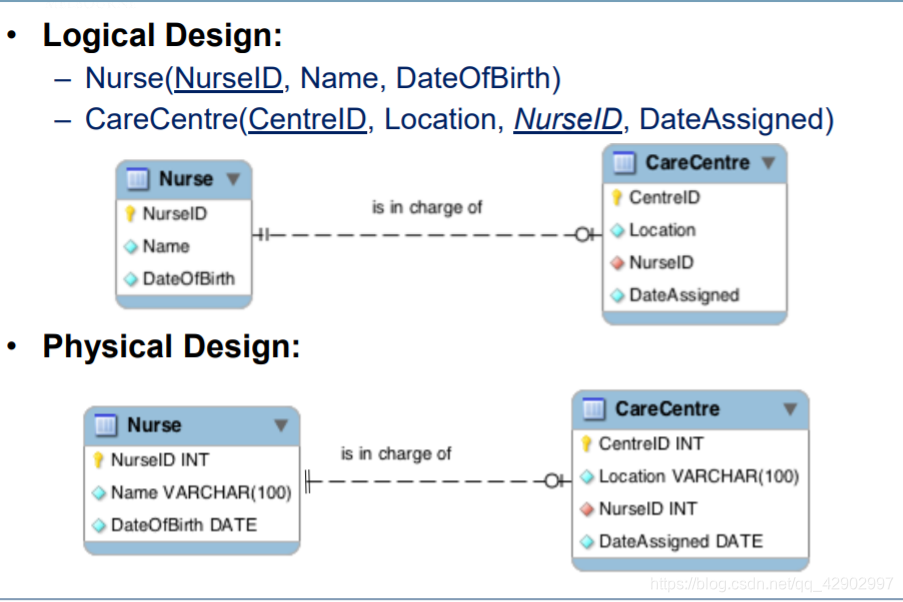
一对多和一对一关系的处理原则
多边(多元)关系处理原则总结(一对一,一对多,多对多)

一元关系(Unary)的处理原则
多对多关系的处理原则
一对一和一对多关系的处理原则
弱实体和强实体关系的原则
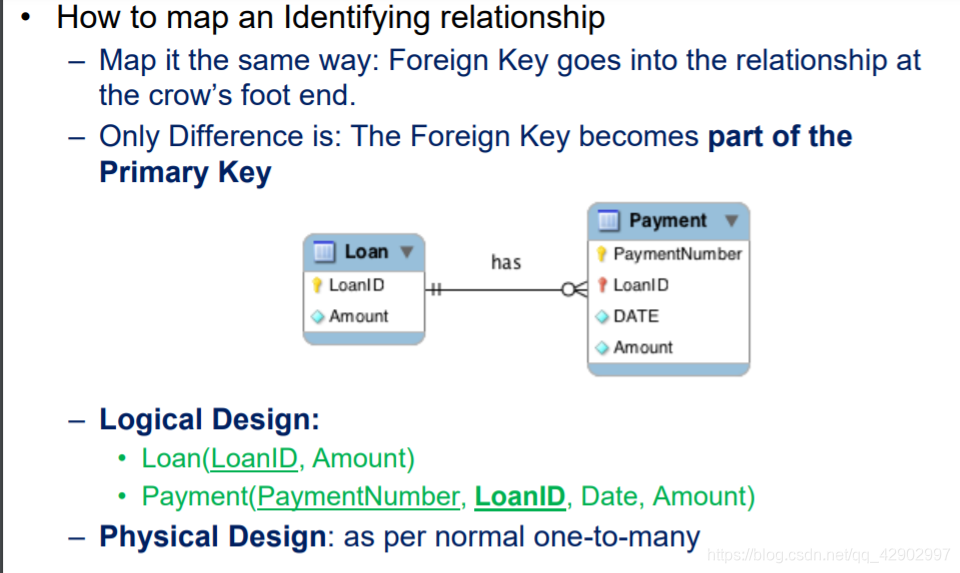
- 和普通的多元一对多的关系类似,外键都放在 “多” 的一变
- 不同的是,外键只是主键的一部分;primary key 是 (PaymentNumber,LoanID)
关系代数 (relational algebra)
关系代数的 5 大基本操作
- 选择(selection)
- 投影(projection)
- 交叉相乘(cross-product)
- 集合做差(set-difference)
- 联合(union)

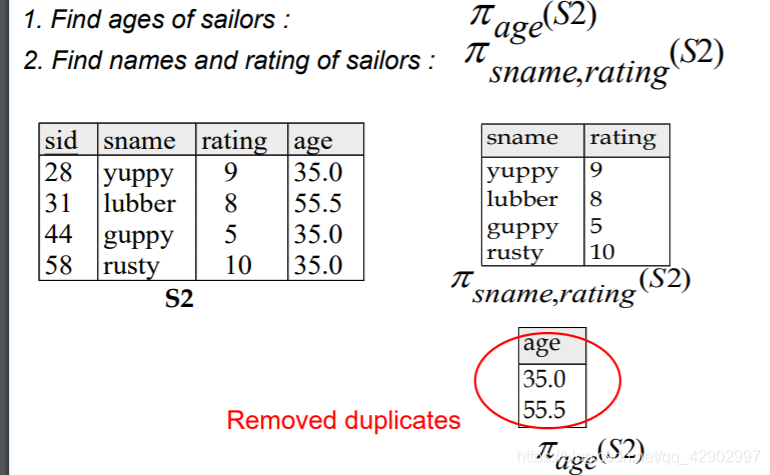
投影(projection π \pi π)
- 对属性进行筛选,即在一个relation 中将一列或者几列的数据筛选出来
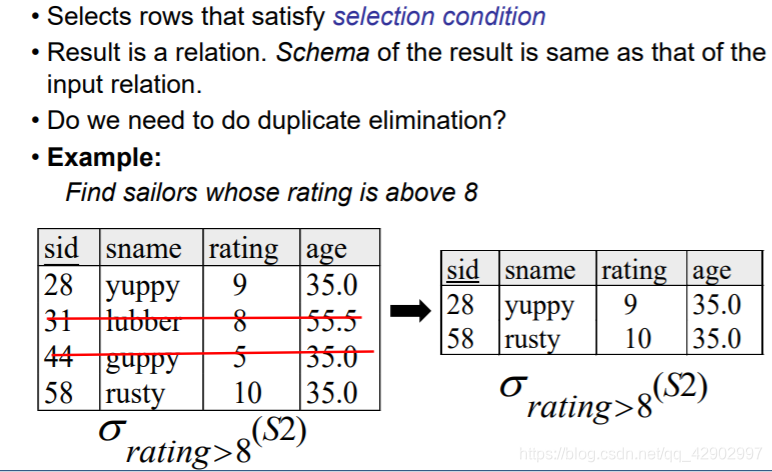
选择(selection σ σ σ)
- 按照条件对 relation 的行进行选择,返回一行或者多行符合条件的数据
筛选条件(condition)

选择+投影的组合(section & projection)

联合 + 集合做差(union + set-difference)

Union-compatible
- 两个进行以上行为的 relation 必须具有相同的列的数量
- 对应列的数据类型必须是一致的

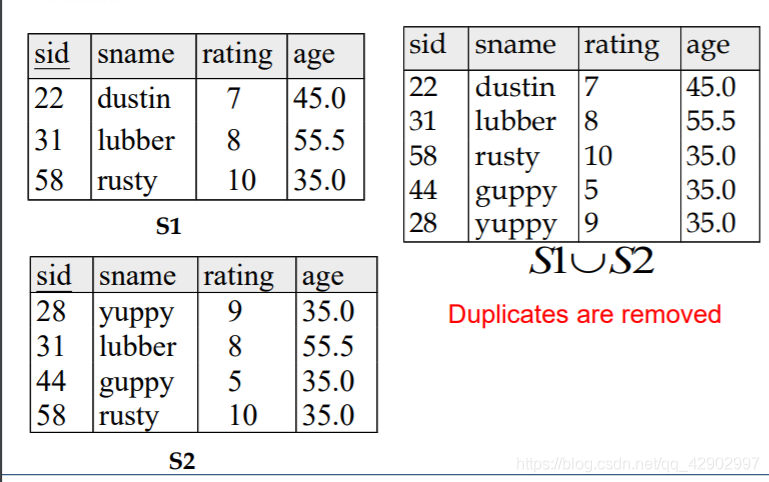
联合(Union)
- 进行联合操作的时候,相同的行会被 删除
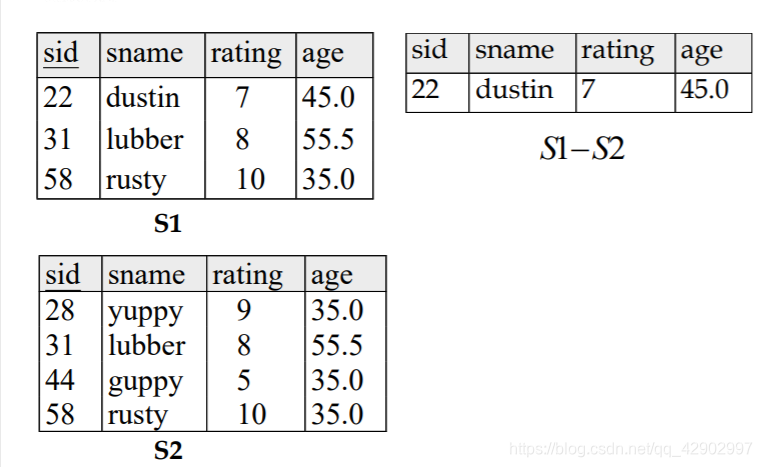
集合做差(Set-difference)
- 集合做差是不对称的,谁在前谁在后很重要
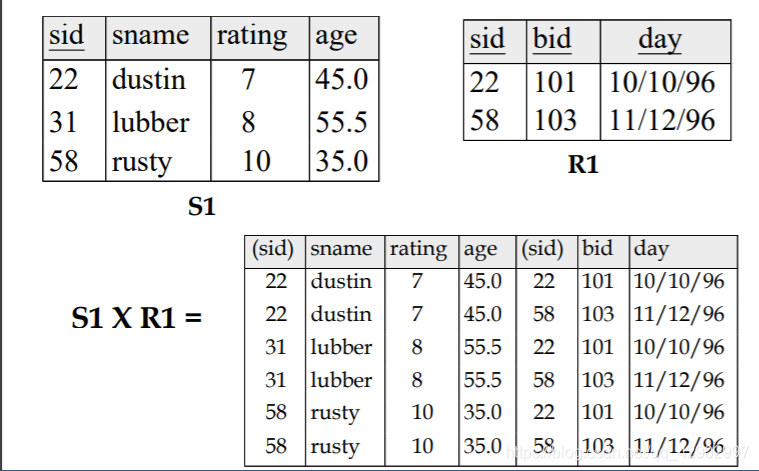
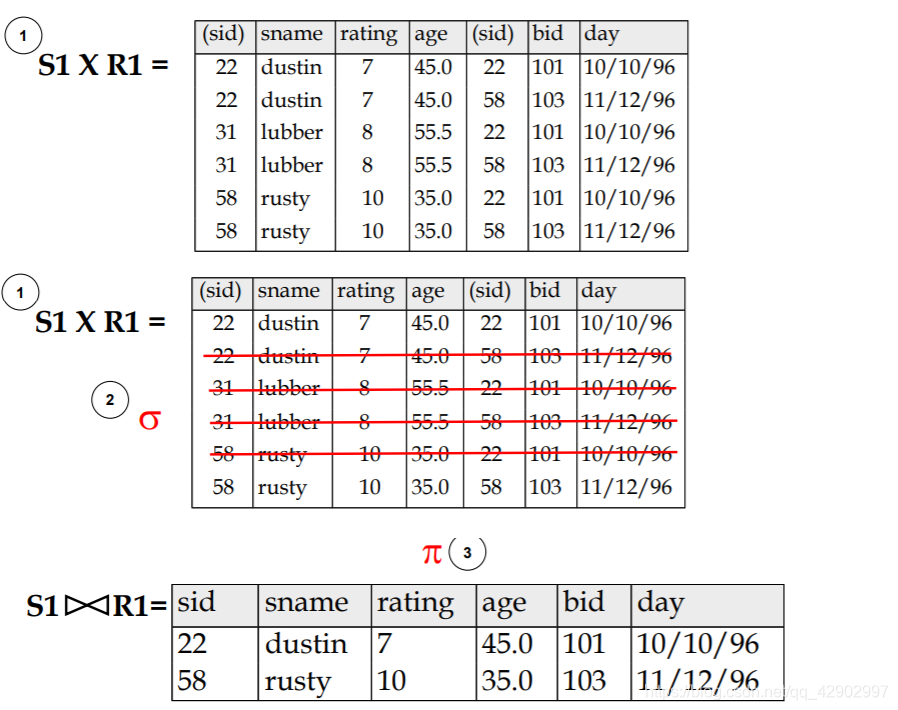
交叉相乘 + 联结(cross product & join)
交叉相乘(cross product)

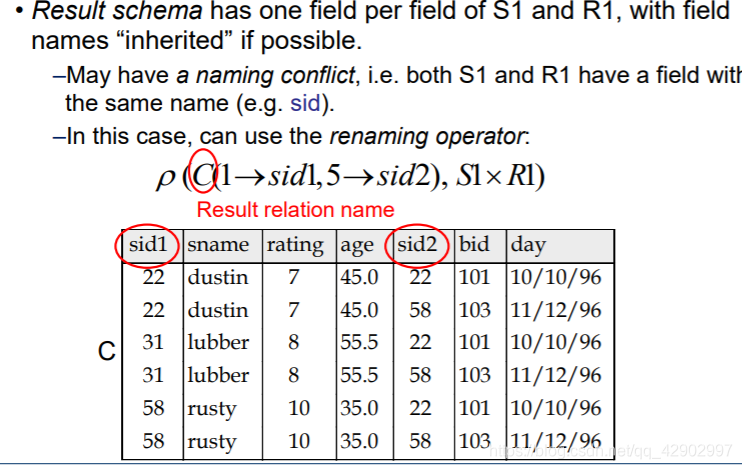
名称冲突处理(name conflicts)
复合操作符(compound operator)
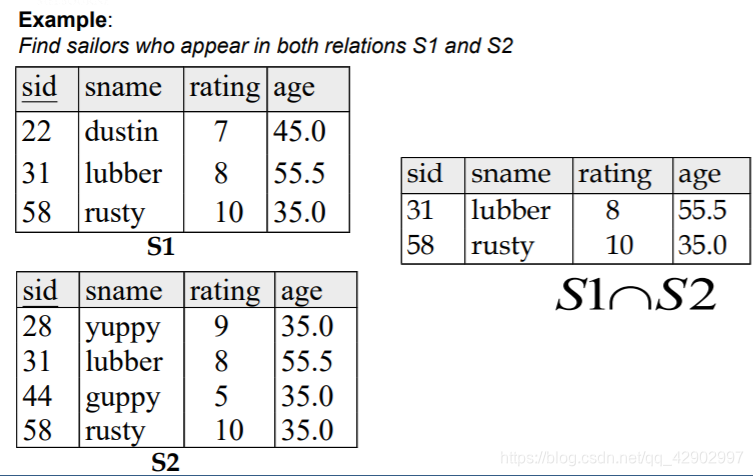
取交集(intersection)

联结(join)
Natural Join

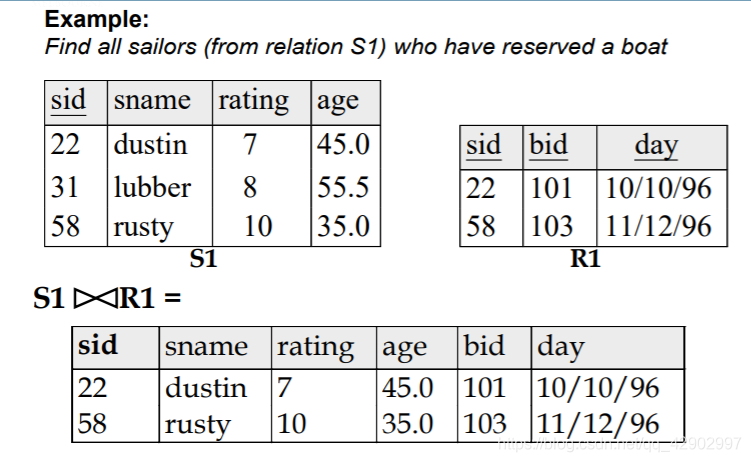
- 可以把列的冗余去掉
Theta Join (condition join)

- 不去冗余
Equi Join

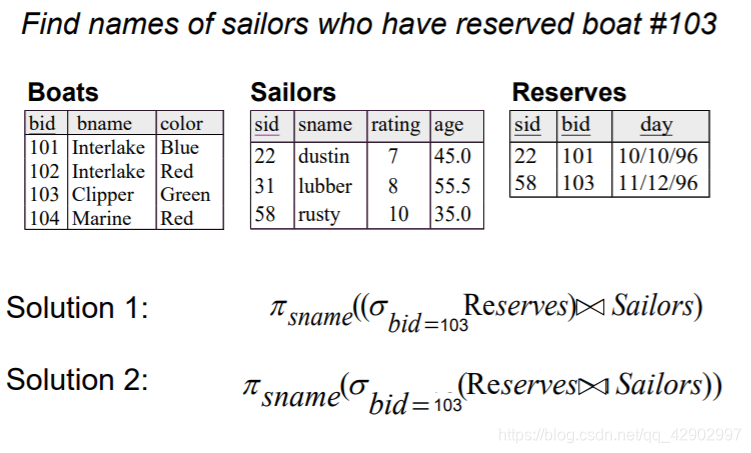
SQL 语言
SQL 四大主要方面功能
- 数据定义语言(Data Definition Language)
- 数据操作语言(Data Manipulation Language)
- 数据控制语言(Data Control Language)
- 其他指令

SQL 的作用
实现数据库

使用数据库

SQL 具体操作
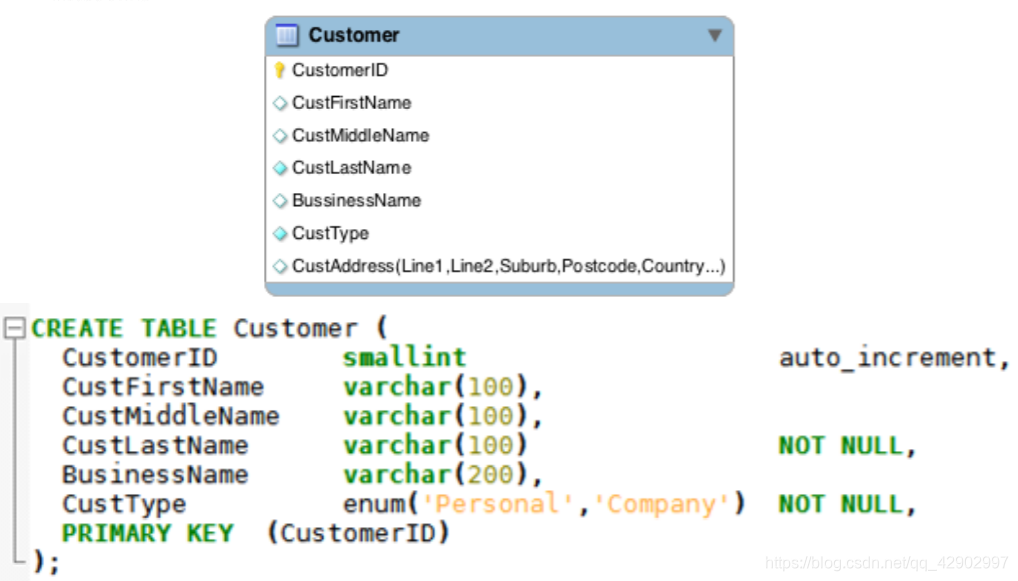
创建表
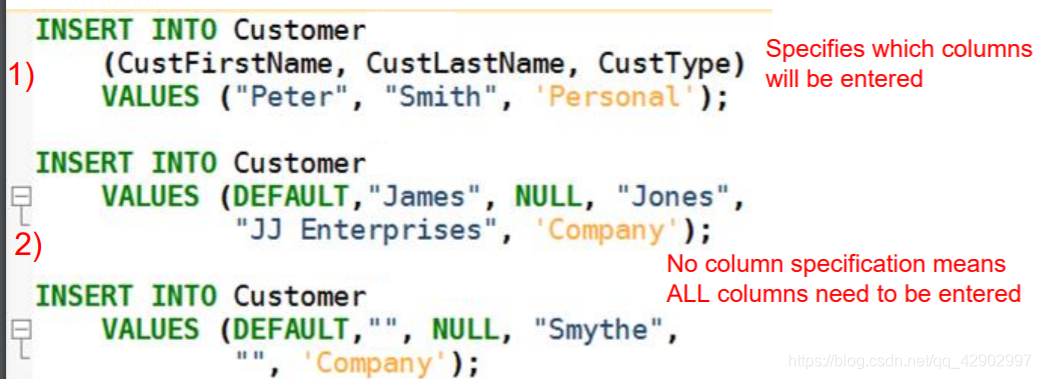
插入数据
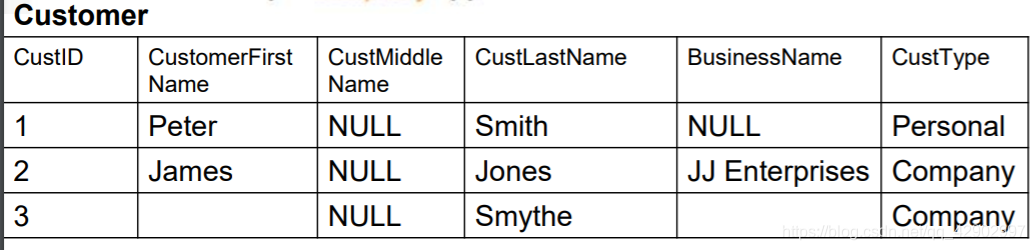
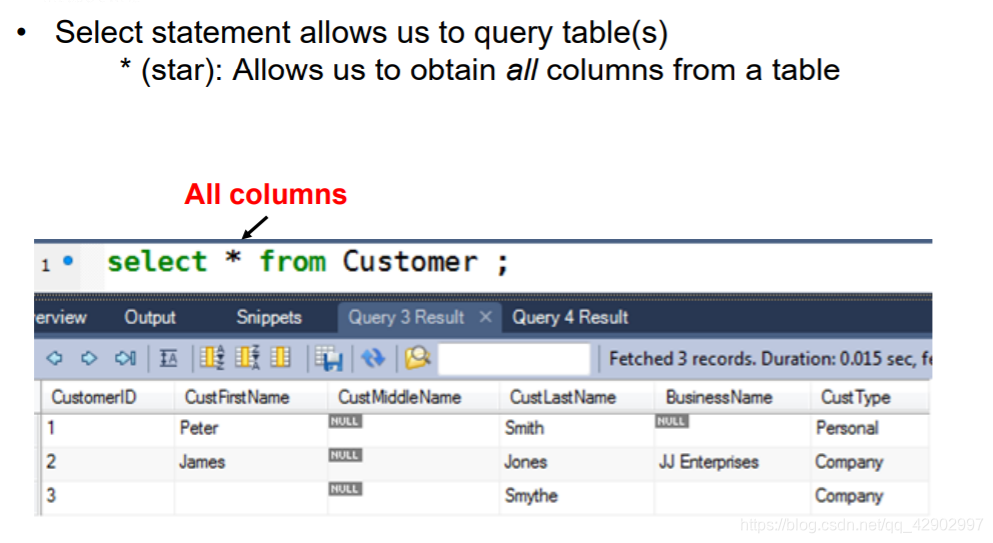
SELECT
FROM
WHERE
GROUP BY
HAVING
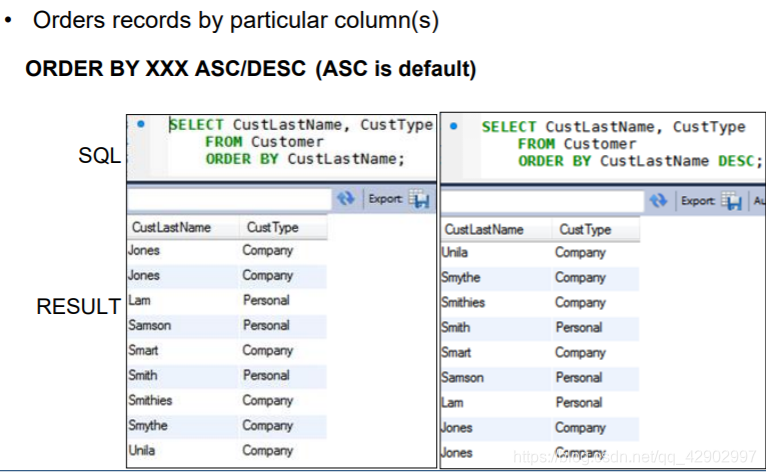
ORDER BY
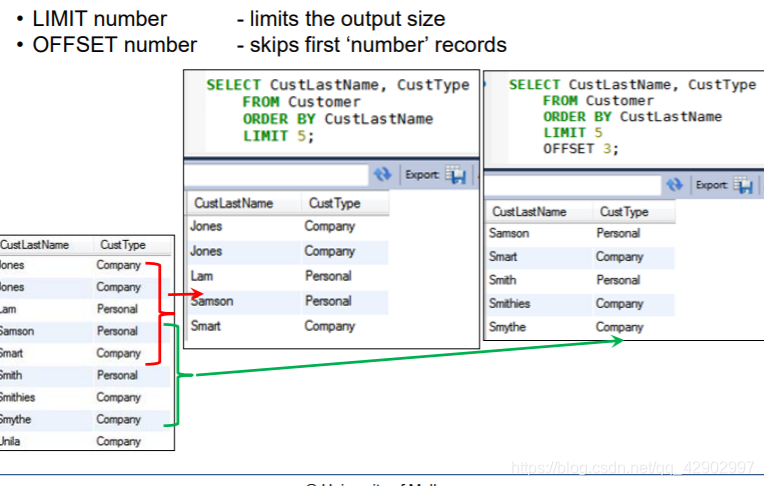
LIMIT

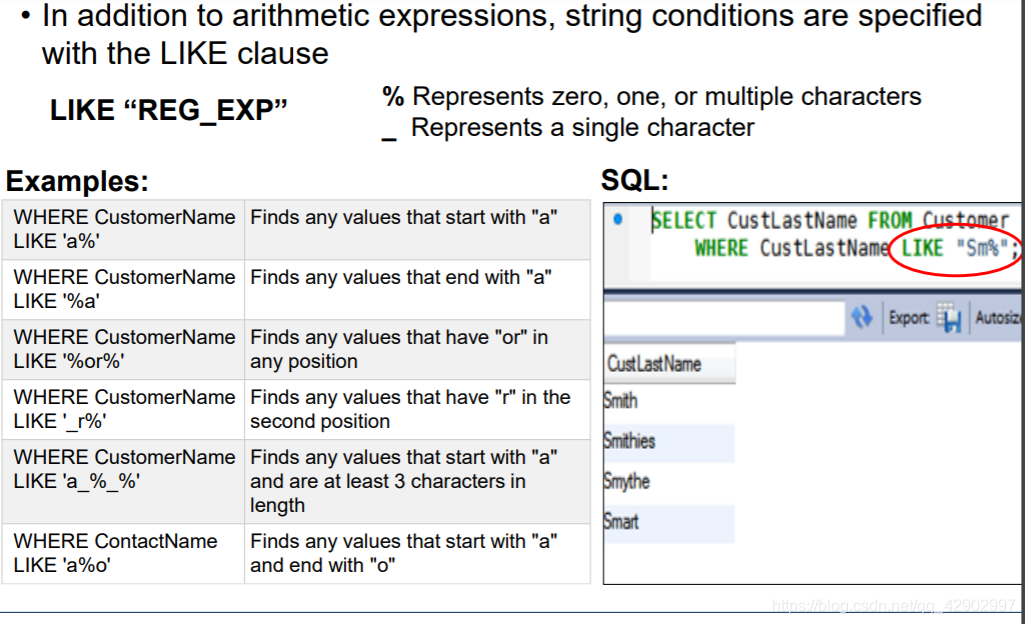
LIKE
%
- 零个、一个或多个匹配字符
_
- 只匹配一个字符
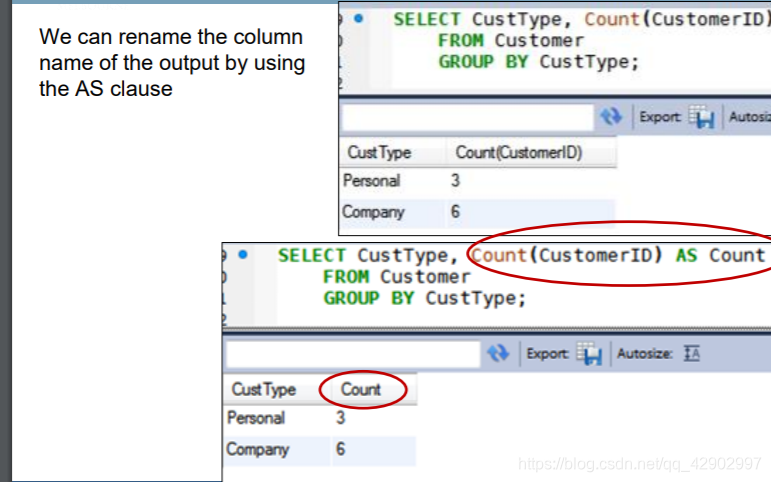
AS (Renaming)
Aggregation Functions

AVG()
COUNT()
MIN()
SUM()
MAX()


ASC / DESC (ORDER BY XXX ASC / DESC)
LIMIT & OFFSET
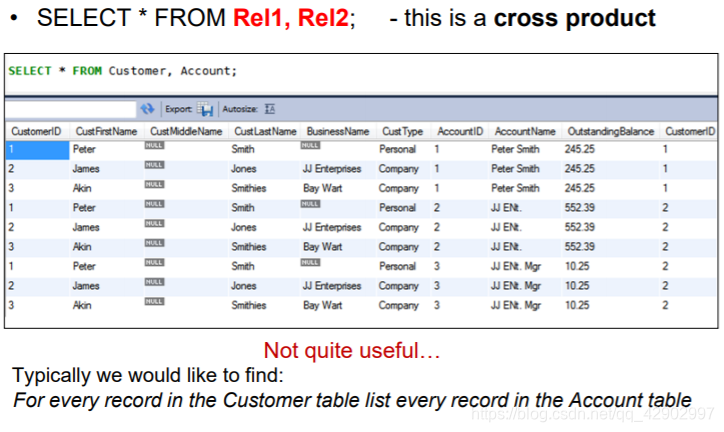
REL1, REL2 (cross product)
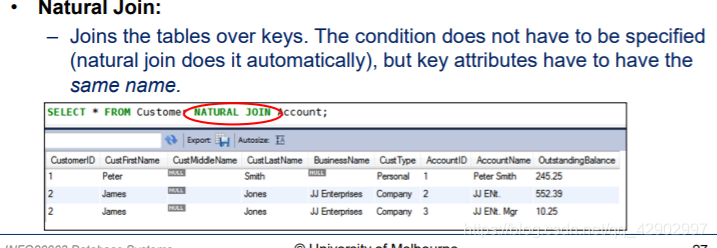
NATURAL JOIN
- 名称必须一致
- 去掉冗余列
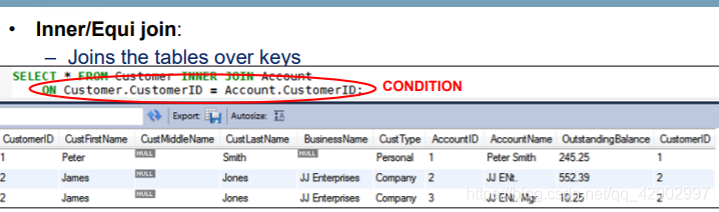
INNER JOIN
- 不去冗余
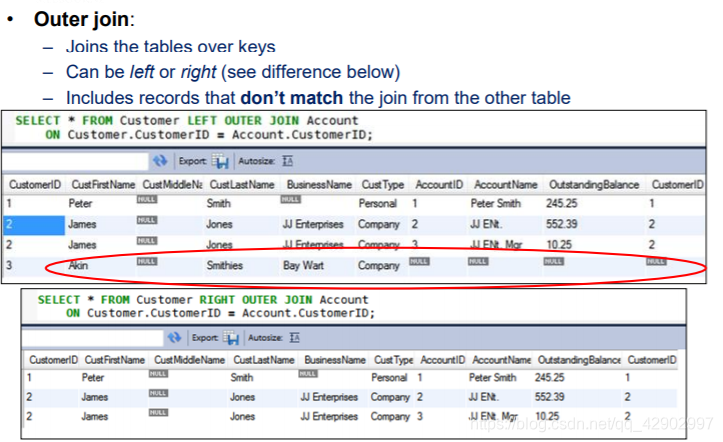
LEFT OUTER JOIN
RIGHT OUTER JOIN
FULL OUTER JOIN


SQL 总结
大小写

逻辑和比较运算符

集合操作

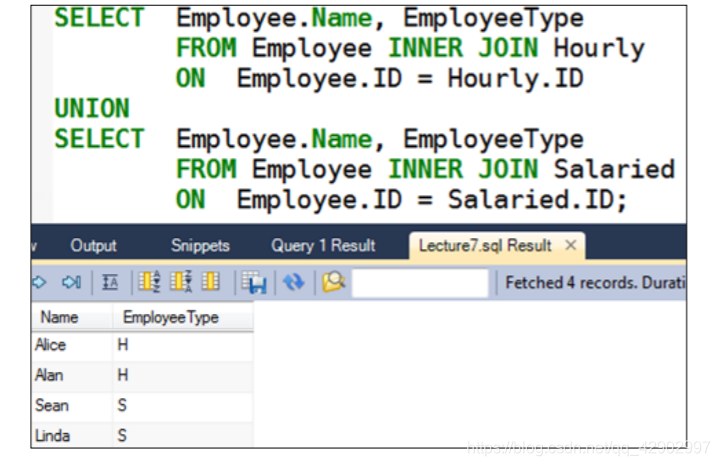
嵌套查询(subquery)

嵌套查询常用运算符

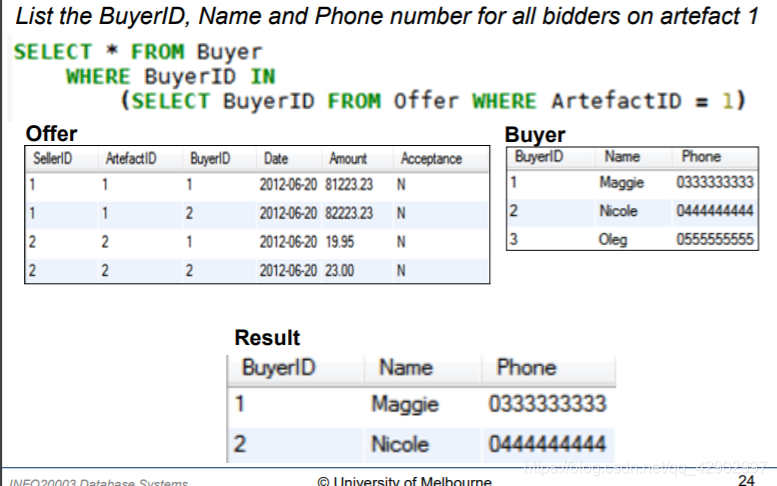
IN
NOT IN
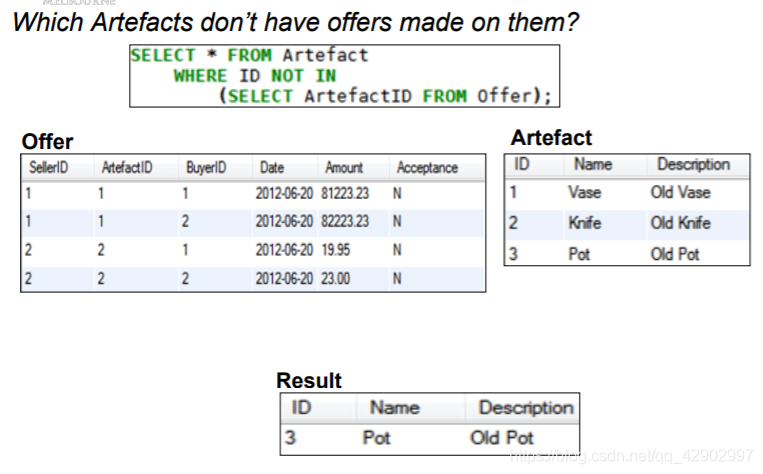
联合查表效率更高

EXISTS
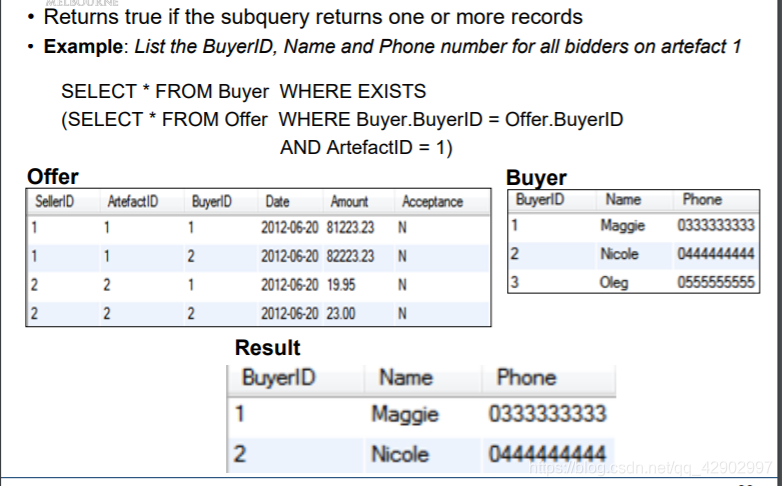
ANY / ALL / EXISTS
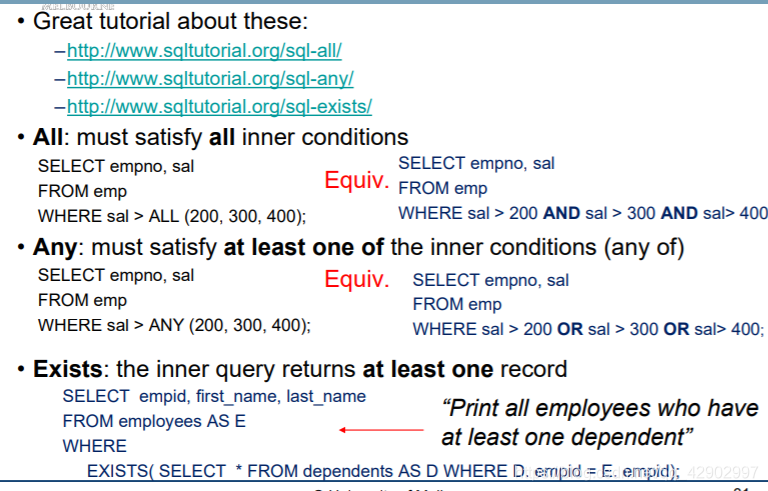
INSERT
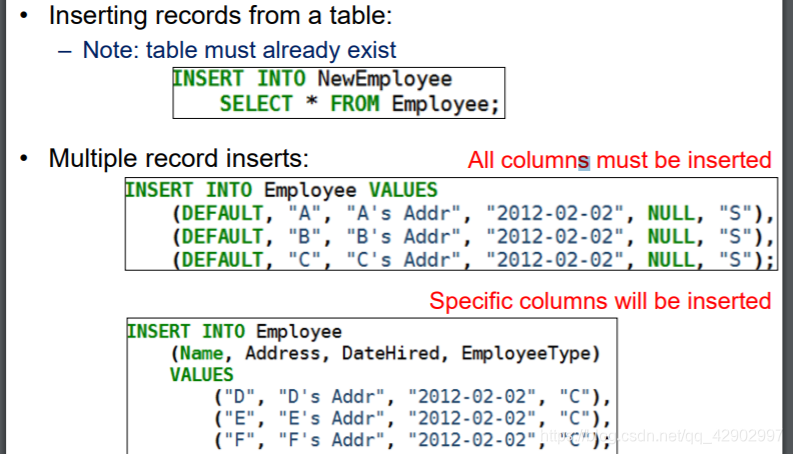
UPDATE
CASE

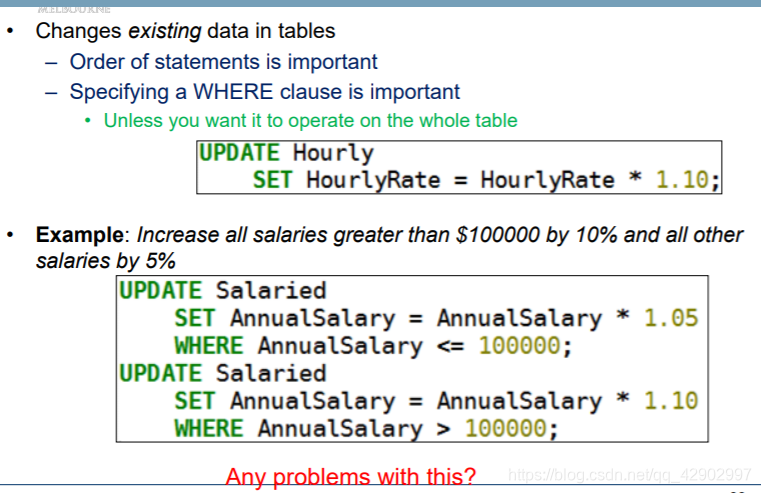
DELETE / REPLACE

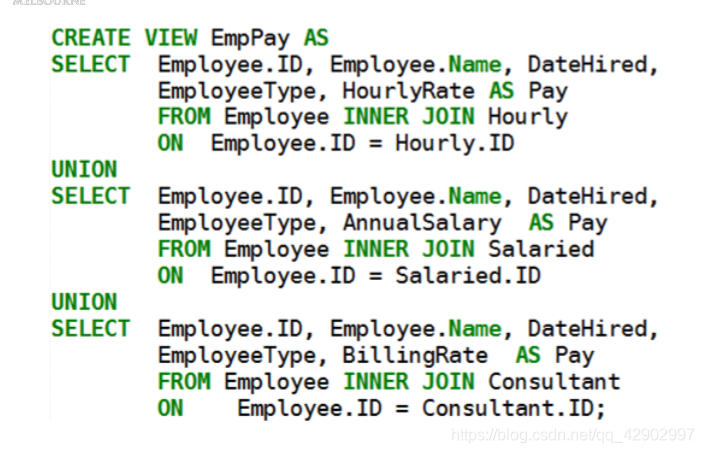
VIEW

ALTER / RENAME

TRUNCATE(截断)/ DROP

其他的数据库管理语句

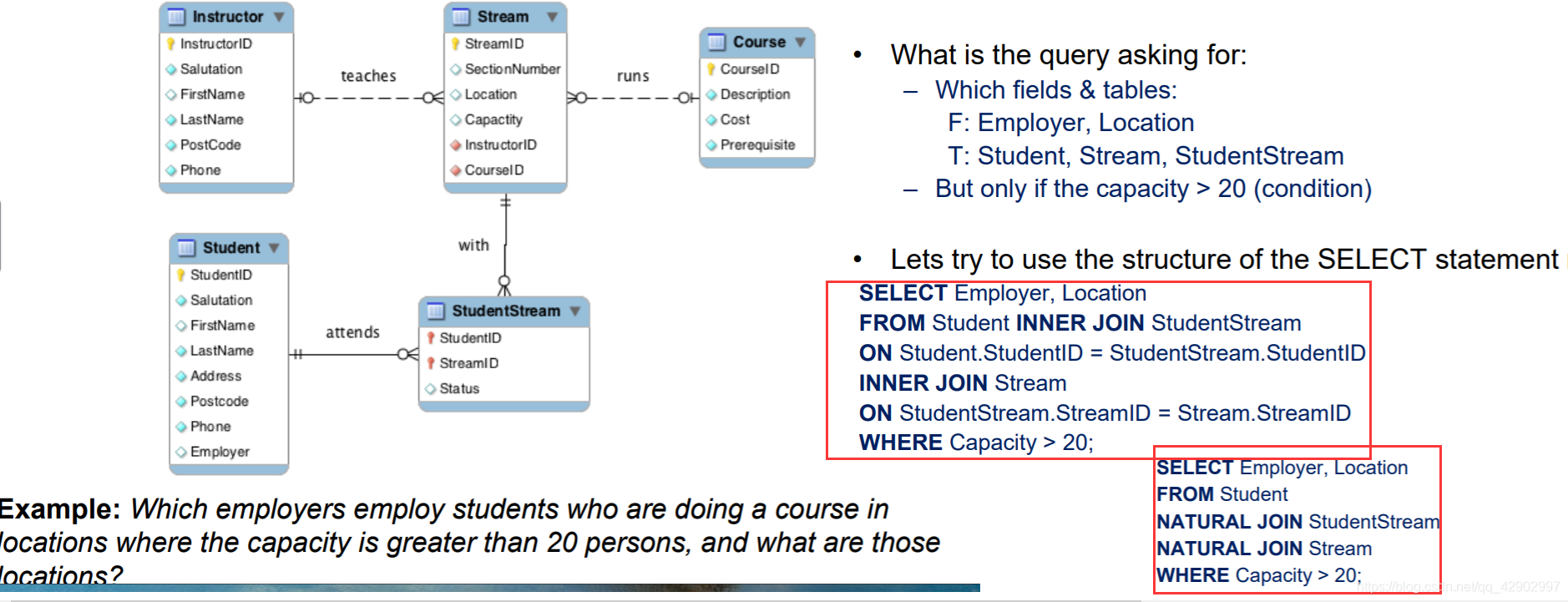
存储和索引

文件组织形式(File Organization)

Heap

Sorted Files

Cost


Index File organization

索引文件 & 索引
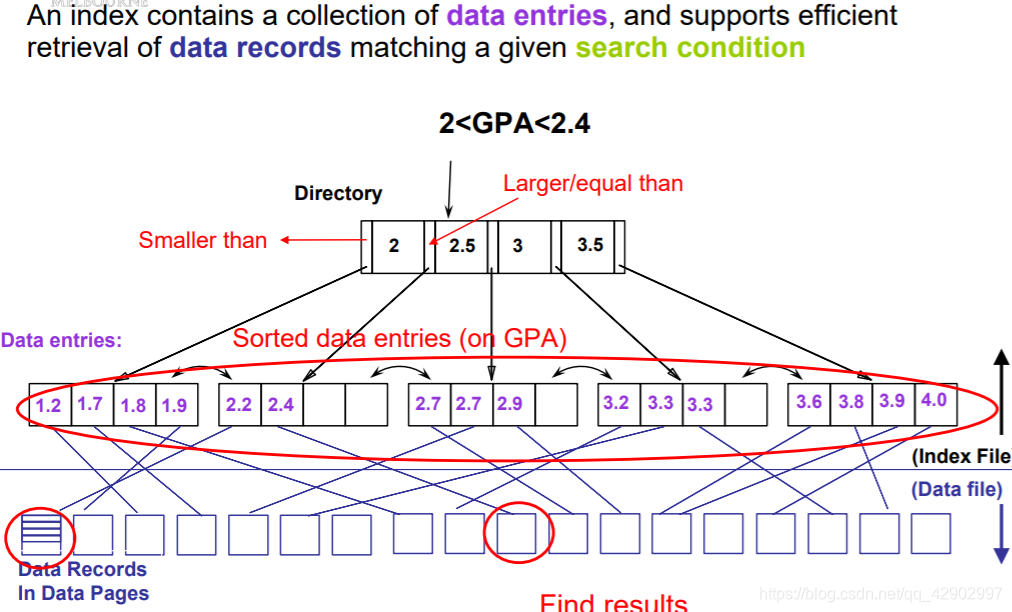
索引分类
Clustered / Unclustered
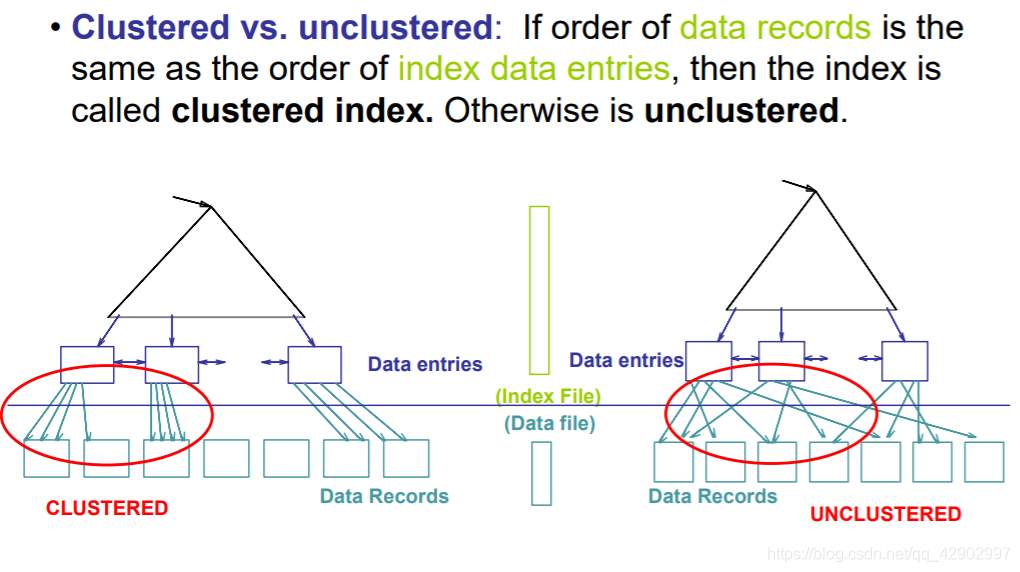

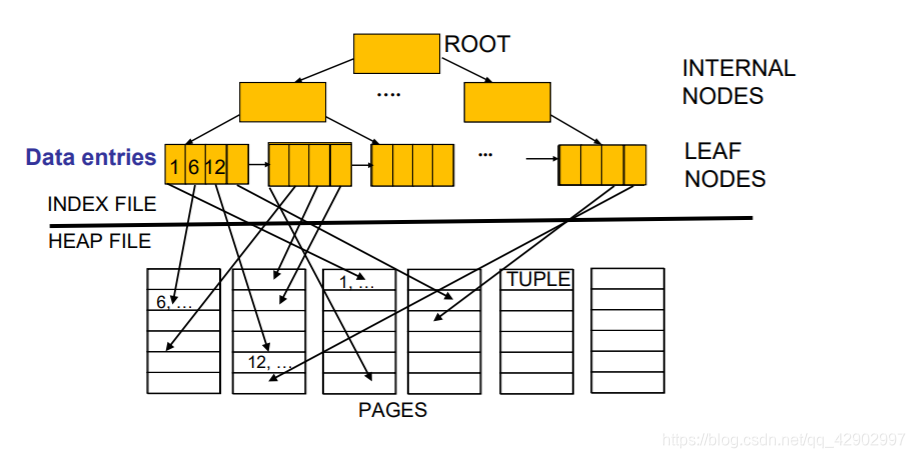
clustered 性质
- 只能建立最多一个 key 来进行 clustered 索引
- clustering 和 unclustering 的 cost 差距很大
- clustered 查询便宜,维护贵

Primary / Secondary
Single Key / Composite
索引技术:Tree-Based、Hash based、other
(cost + result size)数据库开销 + 表格尺寸计算
selection 的开销
Heap scan

B+ tree

Hash

Result Size 的计算

Join 的开销

Projection 的开销

Normalization
部分依赖: A,B 共同决定了 C , C 对于 A, B 都是部分依赖的
完全依赖: A, B 共同决定了 C, C 对于 (A,B) 是完全依赖的
Armstrong’s Axioms

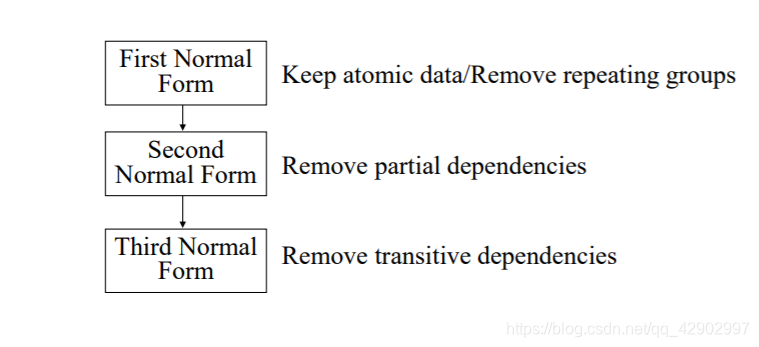
First Normal Form(第一范式):去掉重复的属性

Second Normal Form(第二范式):去掉部分依赖

Third Normal Form(第三范式)

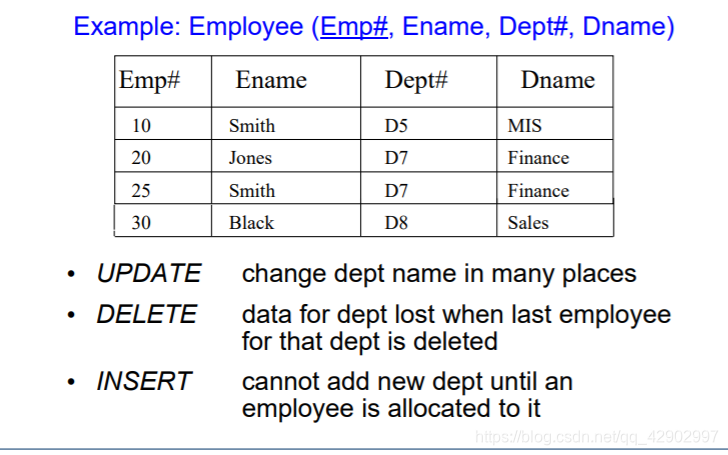
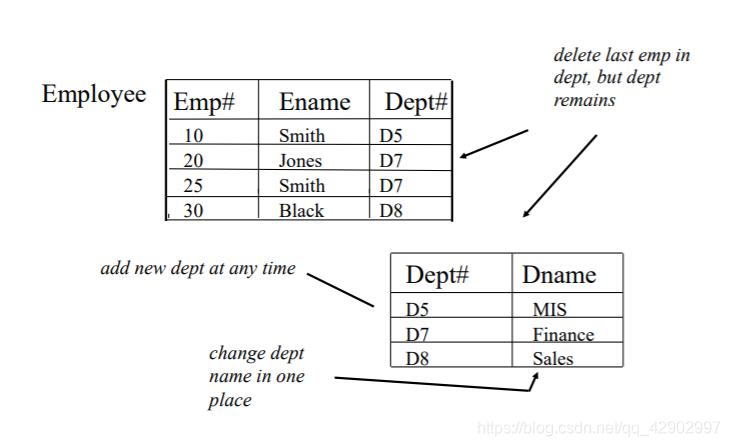
Normalization VS. Denormalization

Database Transaction(数据库事务)


数据库事务的性质(ACID)
Atomicity(原子性:不可再分)
Consistency(一致性:事务前后的约束一致、并发访问的数据一致)
Isolation(独立性:一个事务在完成之前对其他的访问不可见)
Durability(耐久性:一个事务完成之后,改变是永久性的,即使系统失败)

数据库事务解决的两类问题

问题一:Unit of Work




问题二:并发访问的同步问题
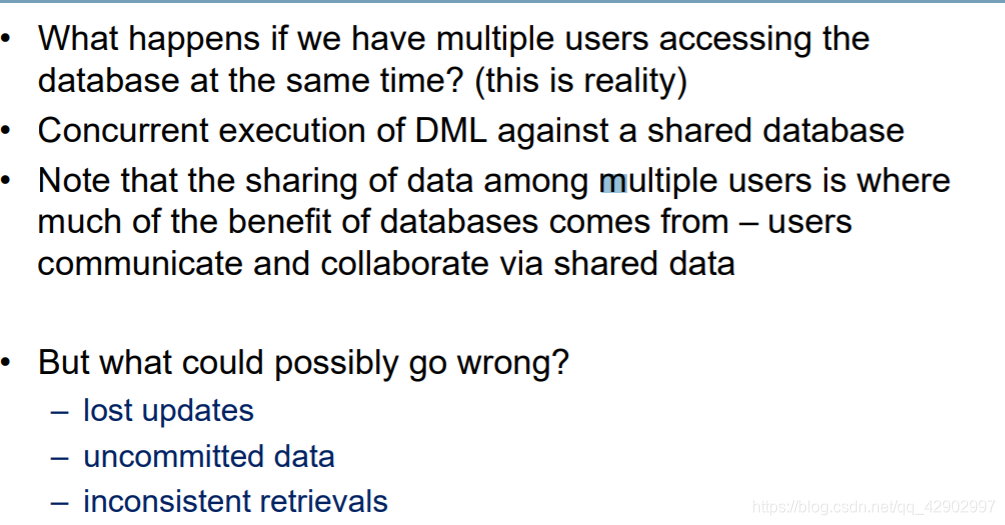
Lost Update Problem

Uncommited Data Problem
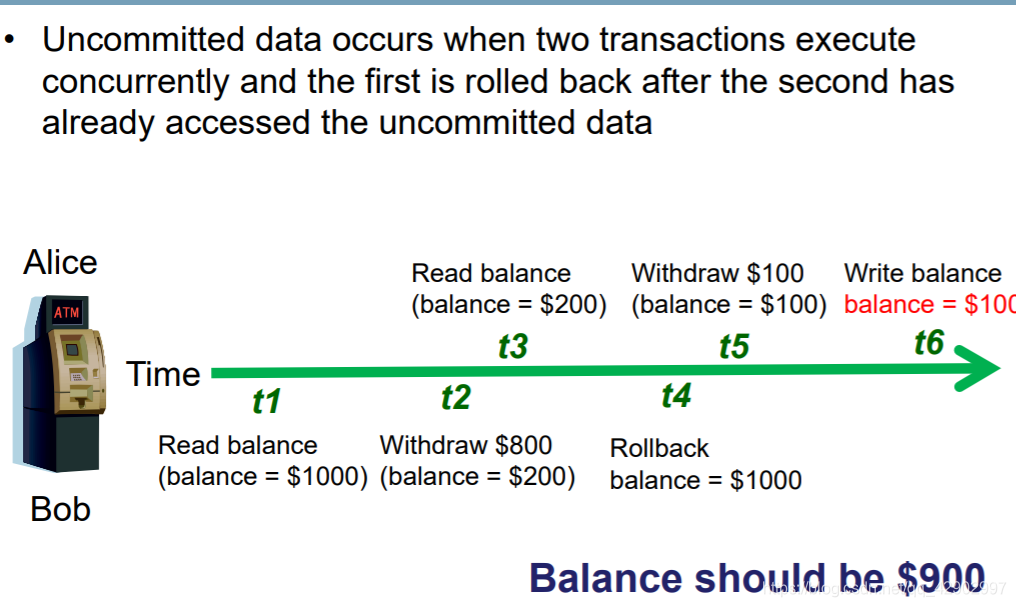
Inconsistent Retrieval Problem(检索不一致问题)

解决的方法:序列化(serializability)

并发控制机制(Concurrency control method)
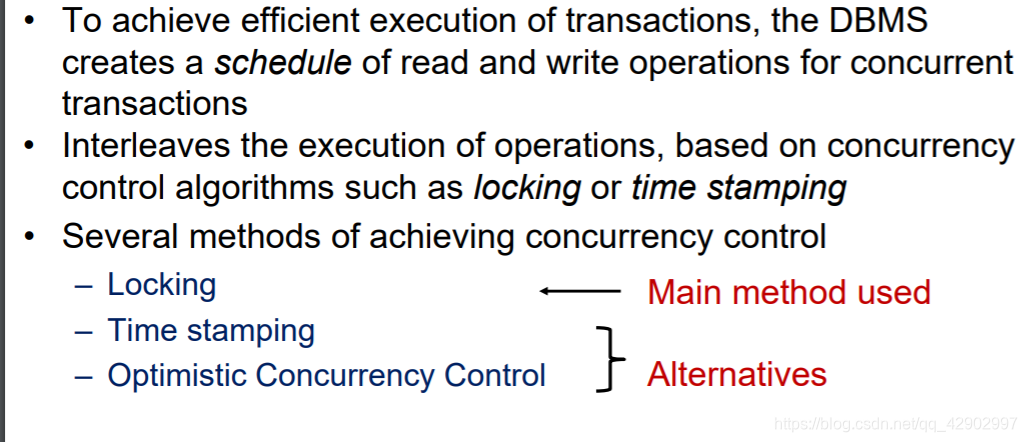
锁(Locking):主要方式

Lock 的粒度
Database-level Lock

Table-level Lock

Page-Level Lock

Row-level Lock

Field-level Lock

Lock 的种类
Binary Lock(二元锁)
- 主要解决的就是“Lost Update” 的问题

Shared and Exclusive Locks (共享锁和独占锁)
- 独占锁和共享锁是互斥的
- 共享锁和共享锁是可以共存的
- 独占锁和独占锁也是互斥的


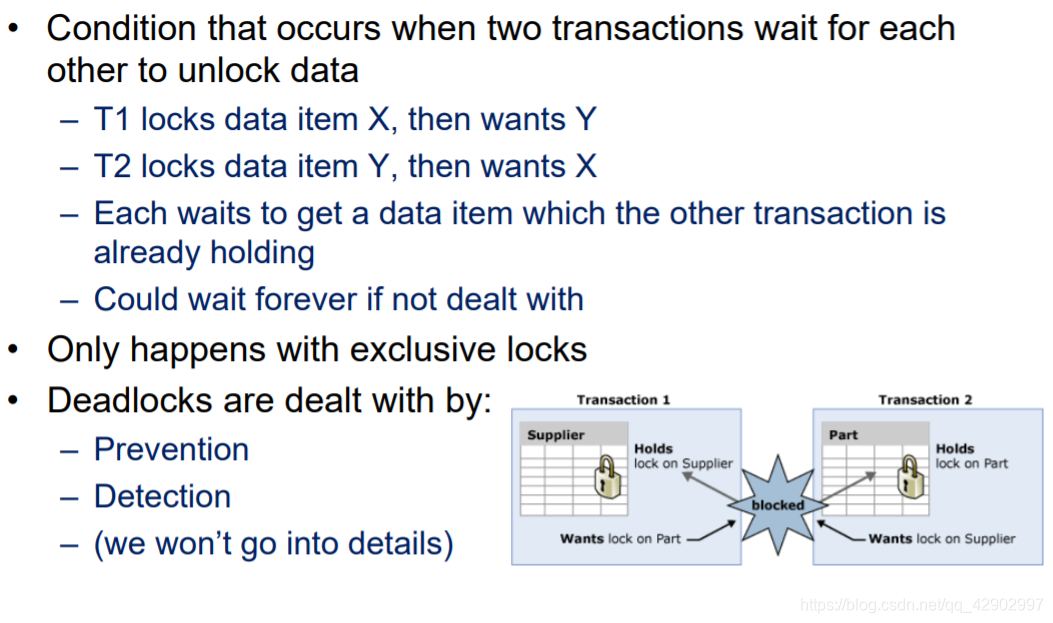
DeadLock(死锁)
Optimistic Concurrency Control(乐观并发控制)

Time Stamping(时间戳)

Logging transactions(记录事务)

数据库管理(Database Administration)

Capacity Planning (容量规划)

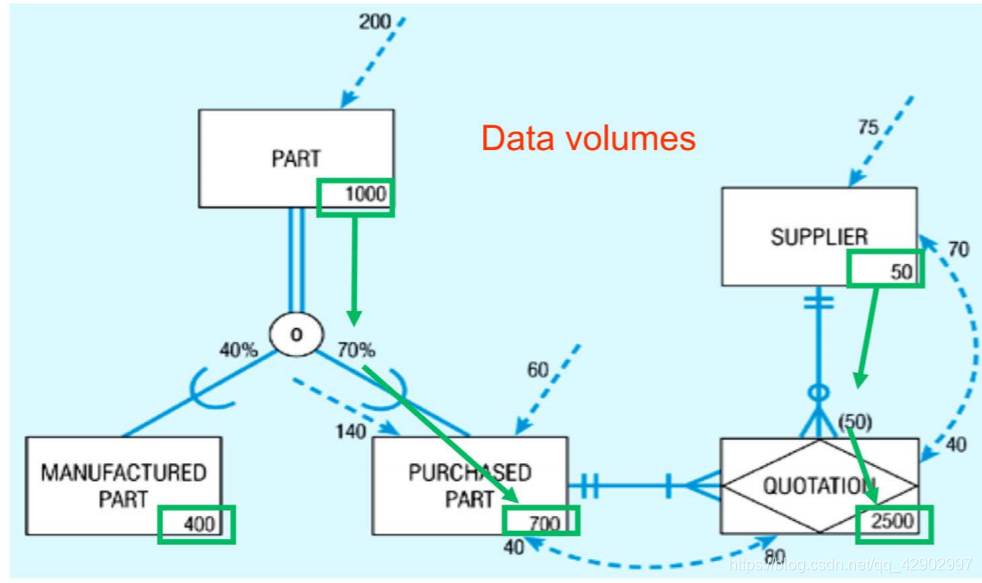
Data Volumes(数据规模)
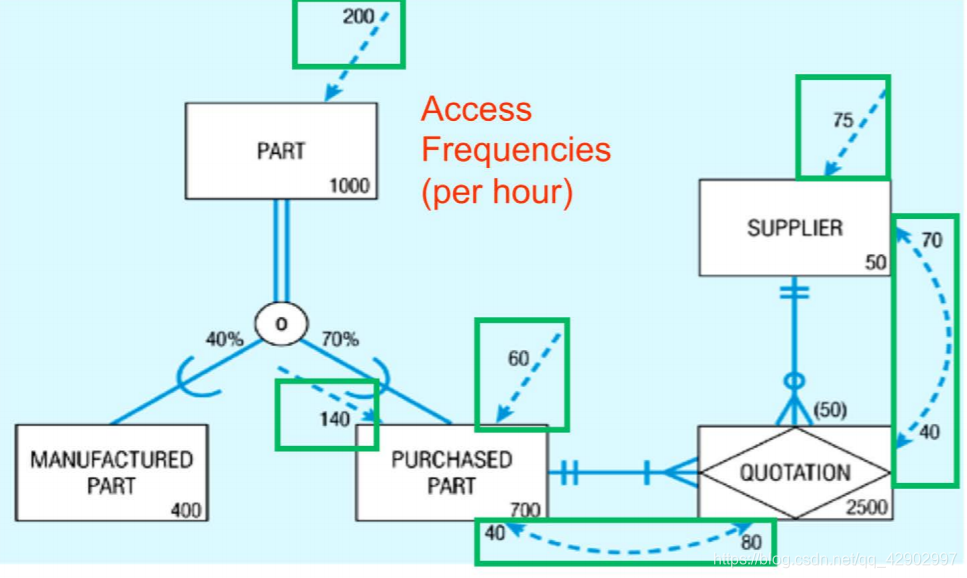
Access Frequencies per hour(吞吐量)
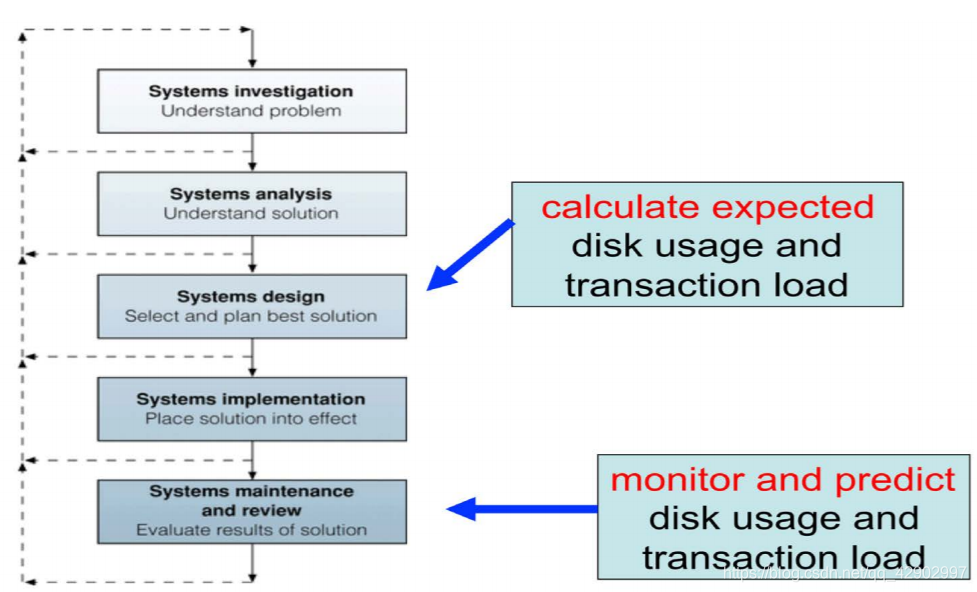
Life Cycle(生命周期)
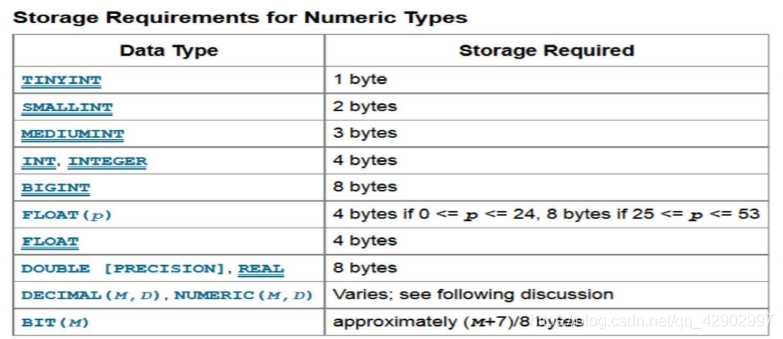
硬盘容量需求计算(Disk space requirement estimation)



表格项目的增长速度(table growth estimation)


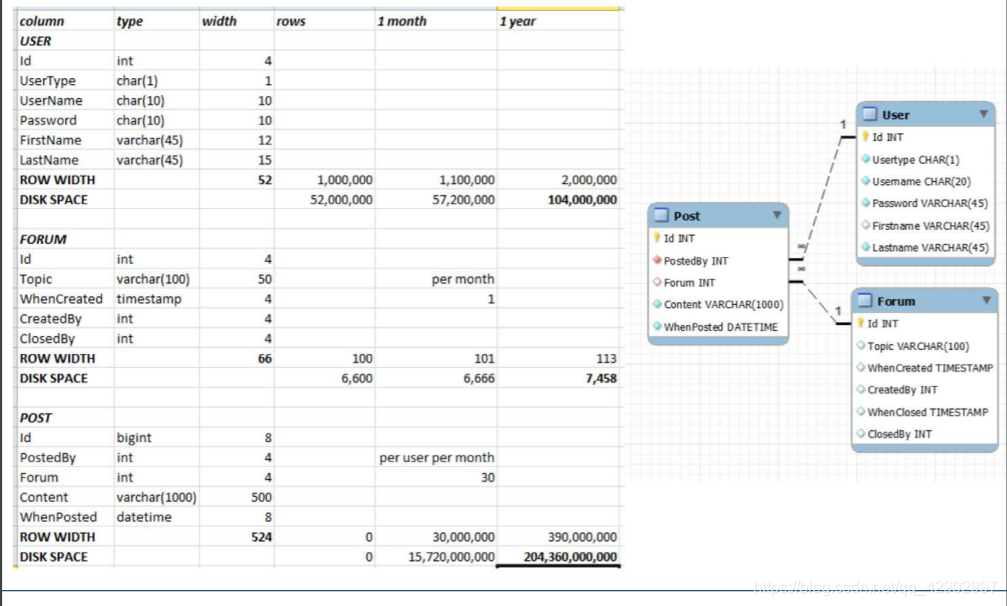
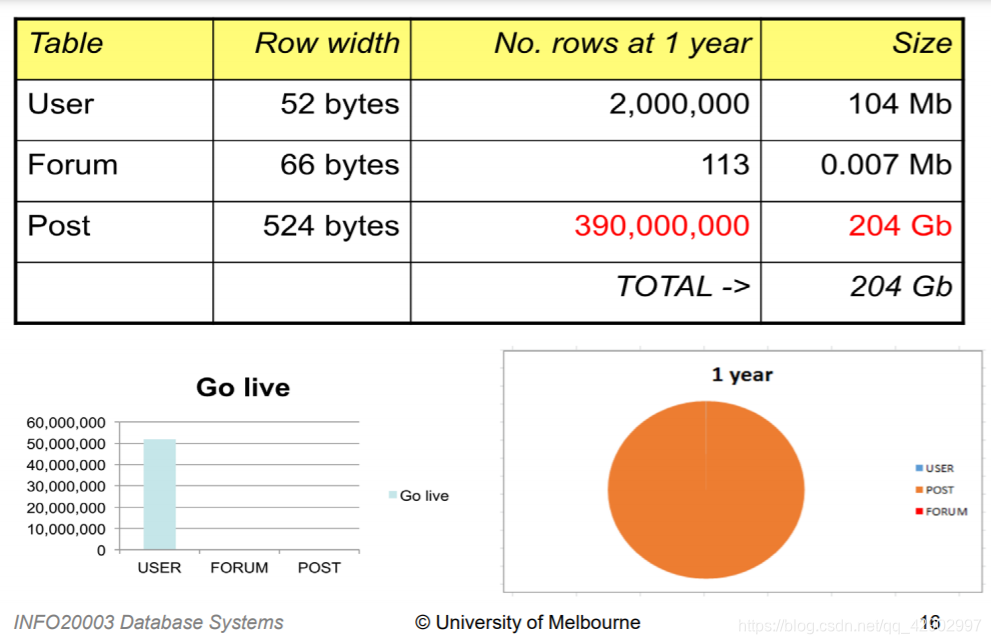
估算事务负载(Estimating transaction load)


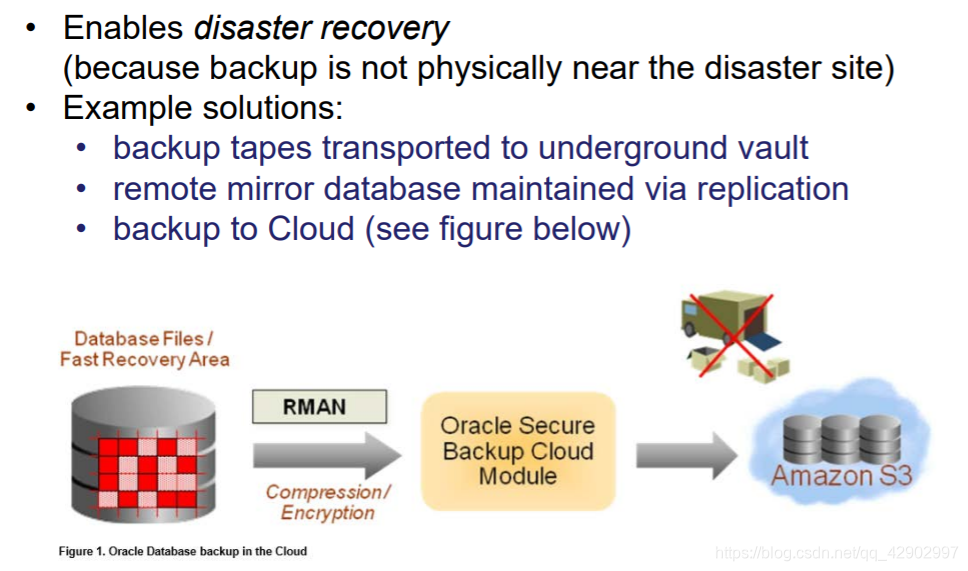
Backup and recovery(备份和恢复)

需要备份的原因(为什么会造成数据的损坏和故障)

备份方式

Physical & Logical
物理备份方式:
- 常常需要关停机器(DBMS系统)
- 真实的文件和数据副本
- 机器的配置要一致,文件格式要一致
- 备份需要保存日志文件(logs)
- 适合大规模的数据库快速恢复的情况

逻辑备份: - 通过 SQL 语句来构造逻辑从而实现备份
- 比物理备份要慢
- 输出的总量要大于物理备份
- 不包含日志文件和配置文件
- 独立于系统和机器(不需要统一的平台)
- 可以不关机进行备份(online)

Online & Offline
线上备份:
- 不关闭系统
- 客户对于备份没有感觉
- 需要特定的锁来保证数据的完整一致性

线下备份:
- 机器和系统关停
- 为了最大化用户的可用性,从复制服务器而不是活动服务器进行备份
- 操作更加简单
- 这种方式是最好的,但并不是在所有情况下都可用

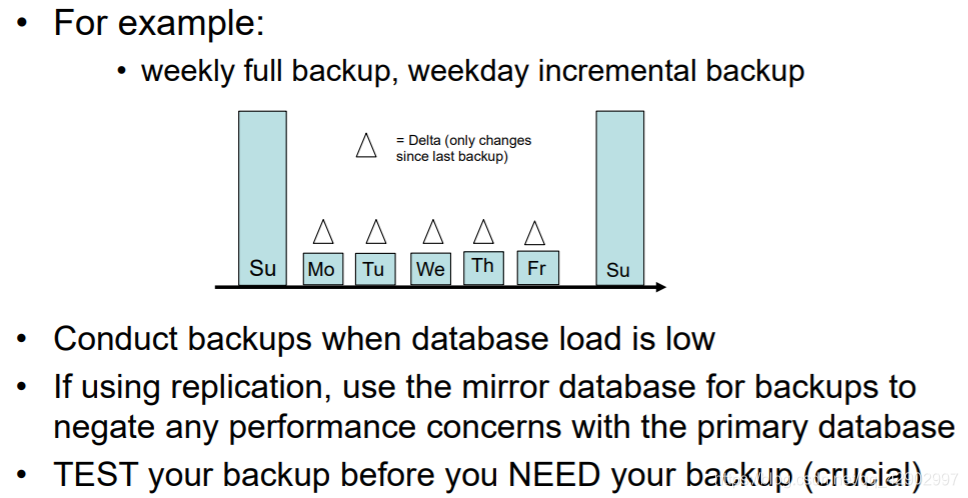
Full & Incremental
完整备份:
- 每次备份整个数据库

增量备份:
- 每次只进行最后更改的备份
- 对很多数据库来说意味着只备份日志文件(logs)

Onsite & Offsite
实地备份:
备份策略(backup strategies)
- 通常吞吐量大的时候采用增量备份
- 吞吐量较小的时候采用完全备份
- 如果使用副本,则使用镜像数据库进行备份,以消除主数据库的任何性能问题
- 在需要备份之前测试备份(至关重要)

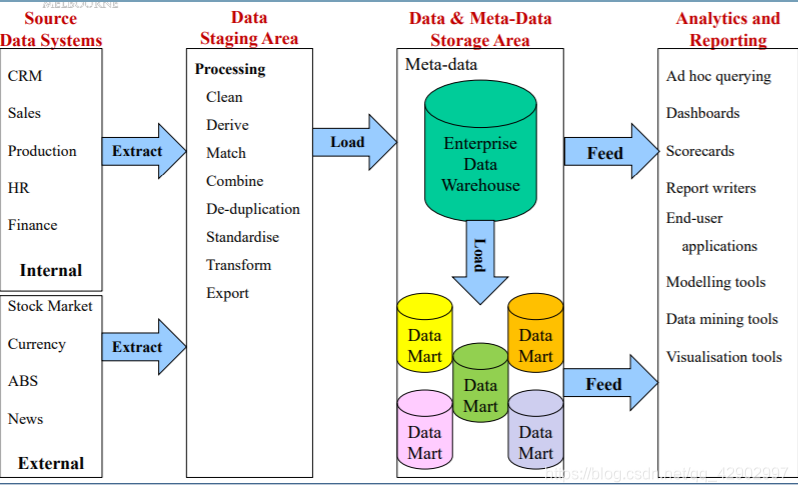
Data Warehousing(数据仓库)
事务型数据库(transaction database)和信息型数据库(Data warehouse)的区别
我们为某个程序创建的特定的数据库一般称为事务型数据库(Transaction Database), 它Data Warehouse(DW)还是有很大差别的.
- 事务数据库帮助人们执行活动,而数据仓库帮助人们做计划。例如,事务数据库可能显示航班的哪些座位是空的,这样旅客可以进行预定。而数据仓库用于展示空座率情况的历史信息,以让航班管理员决定在未来是否要调度航班。
- 事务数据库关注细节,而数据仓库关注高层次的聚集。例如,一个大人只想购买最流行的儿童图书而不关心它的库存情况。但负责图书在书架上排列的管理员也关心图书的销售情况和变化趋势。这之间的不同的隐含区别在于数据仓库中的数据通常都是数值类型,它可用于汇总。
- 事务数据库通常为特定的程序而设计,而数据仓库用于整合不同来源的数据。例如订单处理程序——数据库会包含每笔订单的折扣信息,但不会包含产品的成本超支情况。相应地产品管理程序会包含详细的成本信息但不会包含销售折扣。但可以把这两样信息组合到一个数据仓库中,你就可以计算产品的实际销售利润。
- 事务数据库关注现在,而数据仓库关注于历史。例如一个银行帐户,每一次事务——即每次的存款与取款都会改变帐户余额的值,但事务系统很少会维护历史余额。但在数据仓库中,你可以存储很多年的事务数据(可能被汇总的),还会存储余额快照。这样允许你把当前值与历史进行比较。在进行决策时,可以查看历史趋势。
- 事务数据库是可变的,这很容易理解。但数据仓库是稳定的;它的信息会以固定的间隔进行更新(可能是每月,每星期或每小时),而且理想情况下,更新只会为新的时间段添加新值,而不会改变先前存储的值。
- 事务数据库必须提供对详细信息的快速获取和更新,而数据仓库必须对高汇总信息的快速获取或更新。所以事务数据库的设计优化与数据仓库的设计优化可能不同。而且,以管理目的查询一个事务数据库生成报表可以会导致该事务程序运行性能下降
数据仓库介绍

- 数据仓库是一个 informational database 信息型数据库,而不是事务型(transactional) 数据库
- 数据仓库中数据的来源是多渠道的(from multiple sources)
- 管理者和用户都是可以访问的
- 用来支持分析和决策
数据仓库的性质
Subject-Oriented 面向主题(任务)的
Validated, Integrated 数据是经过验证的、整合的
Time variant 时变的(包含历史数据的)
Non-volatile 非易失的(用户只能读、由指定程序自动处理)


数据仓库结构(structures)
维度建模(Dimentional Modelling)



事实、事实表(Facts & Fact table)
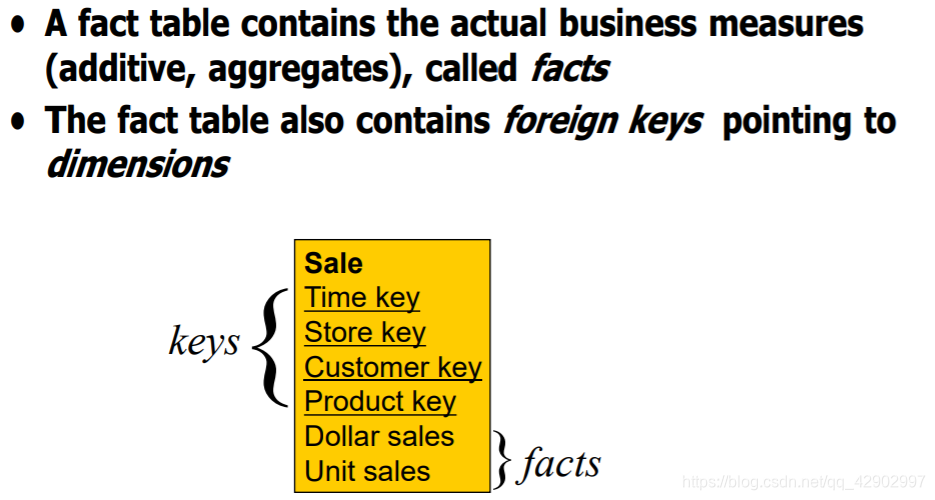
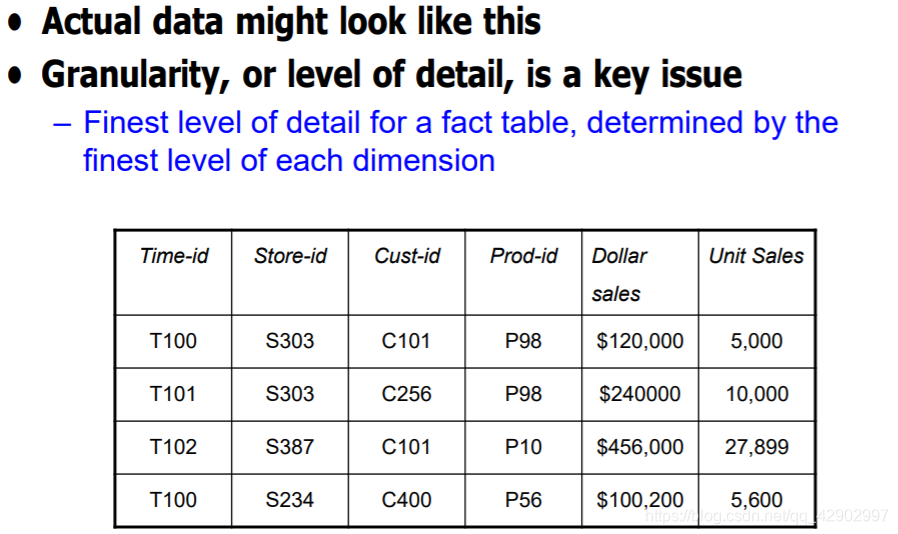
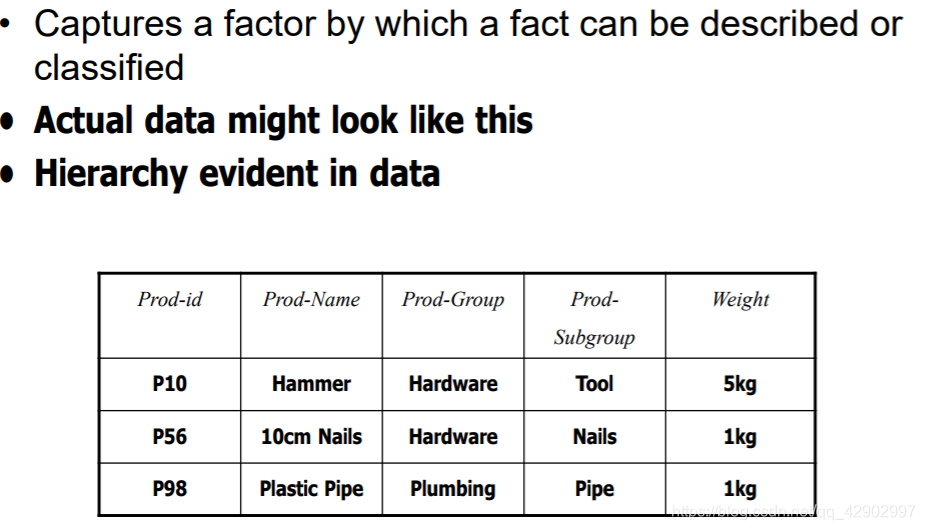
维度层级(dimension hierarchies)
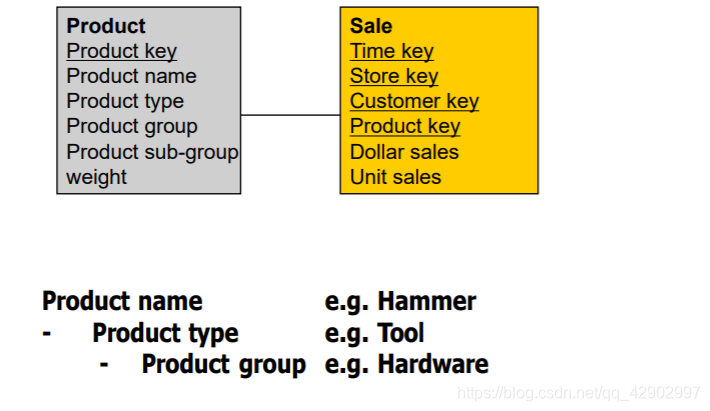
维度、维度表(Dimension & Dimension Table)
星型模型(Star Schema)
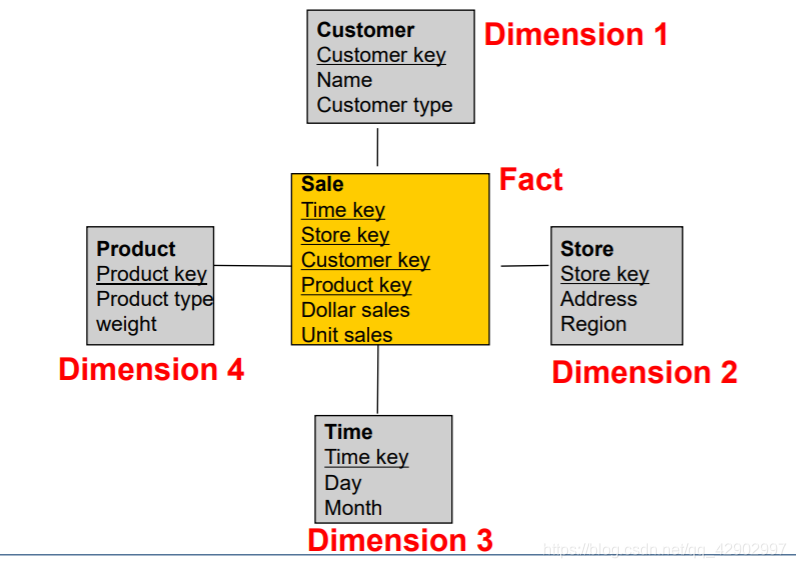
- 星型模型中的 事实表,本质上就是一个中间的联合表;和其他的维度表的关系都是一对多的
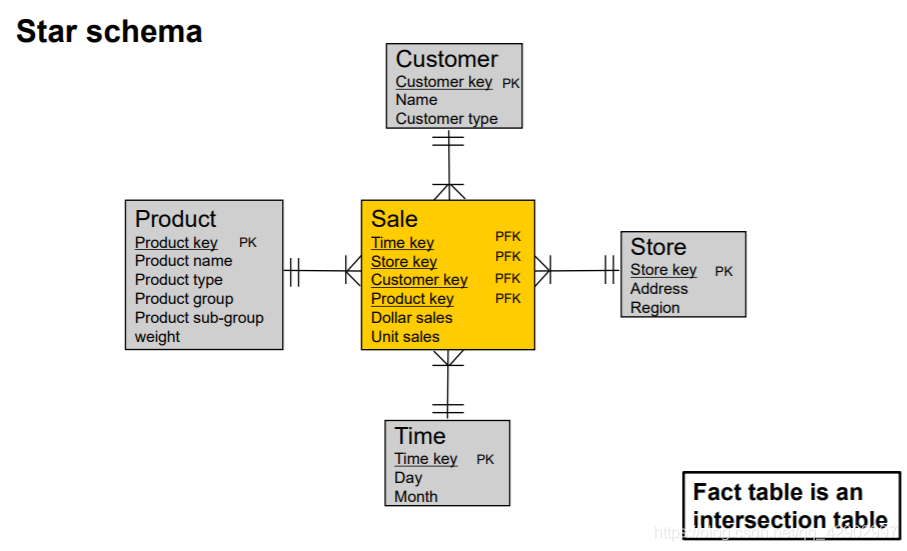
设计维度模型的步骤
- 选定一个商业过程
- 选择一个可以被测量的事实(通常是数字的,附加的数量)
- 决定事实表的粒度
- 决定使用哪些维度表
- 完成整个维度表

维度表中嵌入层次结构(embedded hierarchies in dimensional tables)
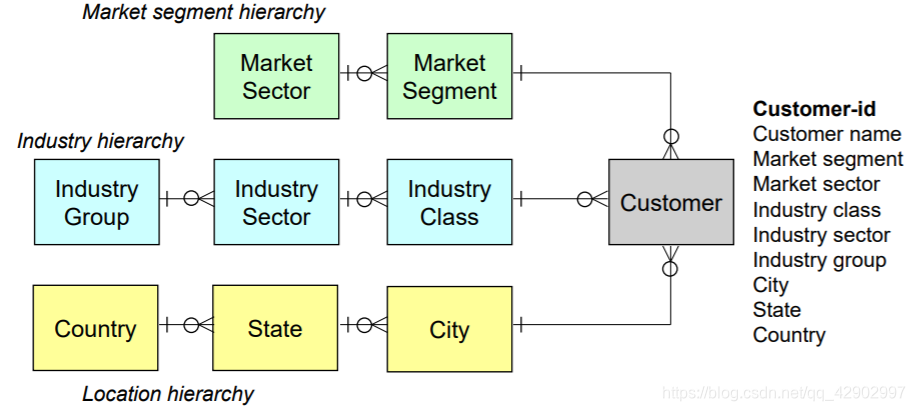
雪花模型(Snowflake schema)
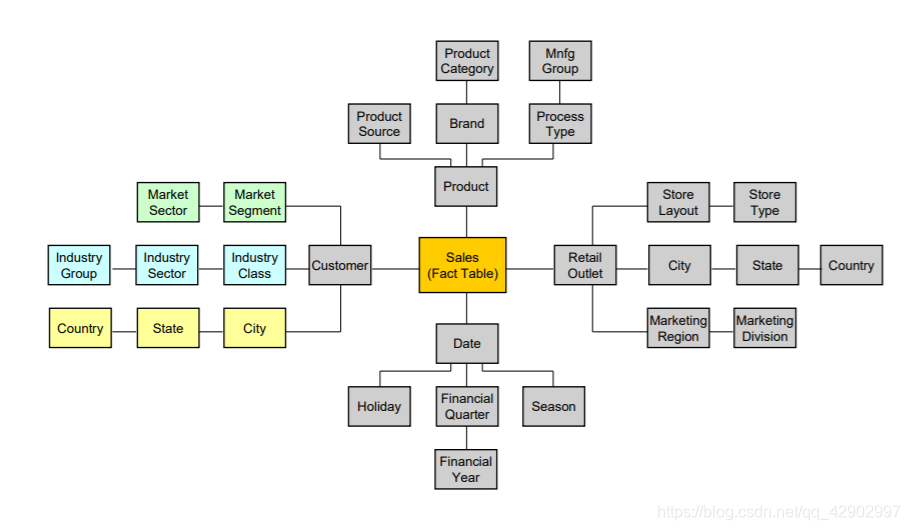
Normalization / Denormalization




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











