






目标网址:2022年统计用区划代码和城乡划分代码

结果预览,爬取了对应的province_code, province_name, city_code, city_name, county_code, county_name, viliage_code, vilage_name
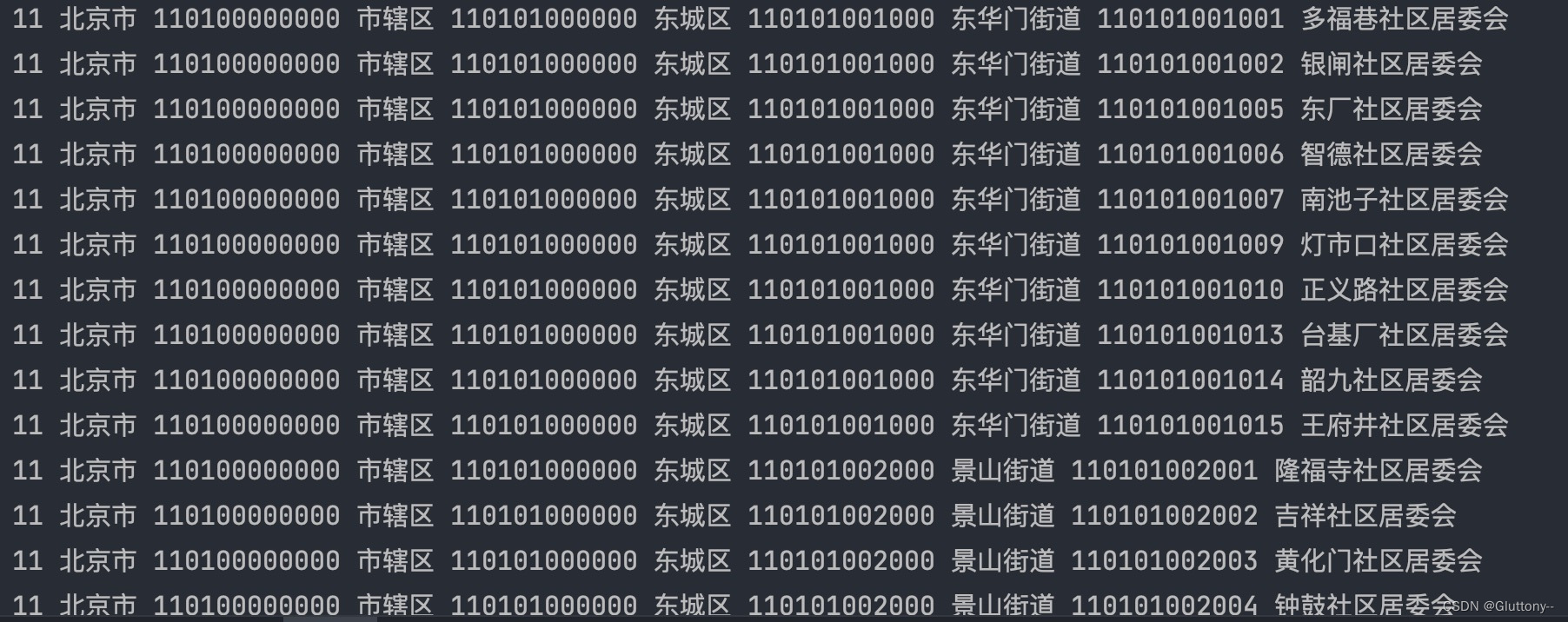
爬取问题:构造多线程爬取,发现短时间频繁对网站发起请求会导致请求不到页面,故直接单线程就慢慢爬吧
代码如下:
from lxml import etree
import requests
import time
import random
def get_html(url):
response = requests.get(url)
response.encoding = "utf8"
res = response.text
html = etree.HTML(res)
return html
base_url = "http://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2022/"
url = base_url + "index.html"
province_html = get_html(url)
province_list = province_html.xpath('//tr[@class="provincetr"]/td')
province_code = province_list[0].xpath('//td/a/@href')
province_name = province_list[0].xpath('//td/a/text()')
province = dict(zip([p.split(".")[0] for p in province_code], province_name))
for p_key in province.keys():
url_city = base_url + p_key + ".html"
time.sleep(random.randint(0, 3))
city_html = get_html(url_city)
if city_html is None:
print("city_html is None", url_city)
continue
city_code = city_html.xpath('//tr[@class="citytr"]/td[1]/a/text()')
city_name = city_html.xpath('//tr[@class="citytr"]/td[2]/a/text()')
city_url = city_html.xpath('//tr[@class="citytr"]/td[1]/a/@href')
for c_num in range(len(city_url)):
county_url = base_url + city_url[c_num]
time.sleep(random.randint(0, 3))
county_html = get_html(county_url)
if county_html is None:
print("county_html is None", county_url)
continue
county_code = county_html.xpath('//tr[@class="countytr"]/td[1]/a/text()')
county_name = county_html.xpath('//tr[@class="countytr"]/td[2]/a/text()')
county_url = county_html.xpath('//tr[@class="countytr"]/td[1]/a/@href')
for t_num in range(len(county_url)):
town_url = base_url + "/" + city_url[c_num].split('/')[0] + "/" + county_url[t_num]
time.sleep(random.randint(0, 3))
town_html = get_html(town_url)
if town_html is None:
print("town_html is None", town_url)
continue
town_code = town_html.xpath('//tr[@class="towntr"]/td[1]/a/text()')
town_name = town_html.xpath('//tr[@class="towntr"]/td[2]/a/text()')
town_url = town_html.xpath('//tr[@class="towntr"]/td[1]/a/@href')
for v_num in range(len(town_url)):
code_ = town_url[v_num].split("/")[1].rstrip(".html")
village_url = base_url + code_[0:2] + "/" + code_[2:4] + "/" + town_url[v_num]
time.sleep(random.randint(0, 3))
village_html = get_html(village_url)
if village_html is None:
print("village_html is None", village_url)
continue
village_code = village_html.xpath('//tr[@class="villagetr"]/td[1]/text()')
village_name = village_html.xpath('//tr[@class="villagetr"]/td[3]/text()')
for num in range(len(village_code)):
v_name = village_name[num]
v_code = village_code[num]
print(p_key, province[p_key], city_code[c_num], city_name[c_num], county_code[t_num],
county_name[t_num], town_code[v_num], town_name[v_num], v_code, v_name)















 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









