






近年来,Transformer在视觉领域吸引了越来越多的关注,随之也自然的产生了一个疑问:到底CNN和Transformer哪个更好?当然是强强联手最好。华为诺亚实验室的研究员提出一种新型视觉网络架构CMT,通过简单的结合传统卷积和Transformer,获得的网络性能优于谷歌提出的EfficientNet,ViT和MSRA的Swin Transformer。论文以多层次的Transformer为基础,在网络的层与层之间插入传统卷积,旨在通过卷积+全局注意力的方式层次化提取图像局部和全局特征。简单有效的结合证明在目前的视觉领域,使用传统卷积是提升模型性能的最快方法。在ImageNet图像识别任务,CMT-Small在相似计算量情况下Top-1正确率达83.5%,远高于Swin的81.3%和EfficientNet的82.9%。
本论文提出了一种CNN和Transformer结合的的通用视觉模型:CMT。在现在这个CNN、Transformer、MLP多种视觉基础框架如雨后春笋般被提出的年代,每当一种新型架构/模块被提出,研究员们不得不在各自的任务/领域上一个个试验这些结构是否能带来效果上的提升。本文简洁有效的证明:在视觉领域中传统卷积和Transformer结合有着1+1>2的效果。我们以目前火热的Transformer为基础,在经典的ViT结构上引入由3x3卷积组成的Conv Stem,以及由Depth-wise 卷积和自注意力机制组合而成的CMT模块,在几乎不增加FLOPs的情况下,大幅度提升视觉网络的现有精度。在ImageNet和下游任务上的大量实验都证明了所提出的CMT架构的优越性。
论文链接:https://arxiv.org/abs/2107.06263
Pytorch代码:Efficient-AI-Backbones/cmt_pytorch at master · huawei-noah/Efficient-AI-Backbones · GitHub
CMT网络主要由CMT(Conv) Stem,四个下采样层,四个Stage,池化层和全连接分类器组成,其中每个Stage由若干个CMT Block堆叠构成。
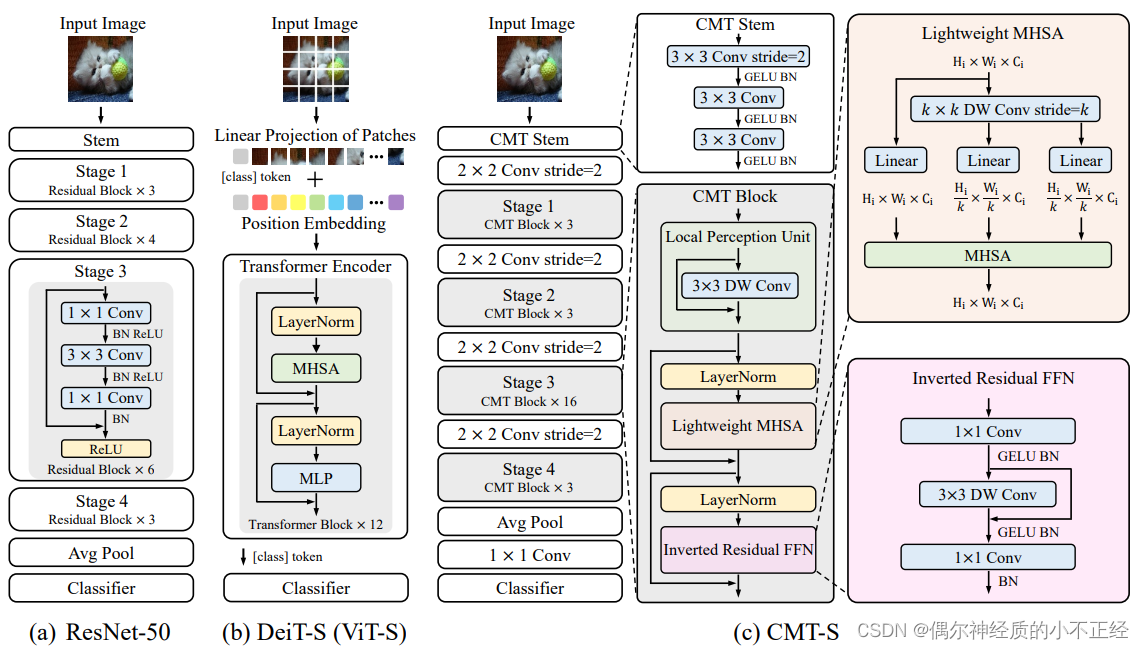
首先,我们看一下CMT Stem。代码如下。
self.stem_conv1 = nn.Conv2d(3, stem_channel, kernel_size=3, stride=2, padding=1,bias=True)
self.stem_relu1 = nn.GELU()
self.stem_norm1 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv2 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True)
self.stem_relu2 = nn.GELU()
self.stem_norm2 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv3 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True) # 224-->112
self.stem_relu3 = nn.GELU()
self.stem_norm3 = nn.BatchNorm2d(stem_channel, eps=1e-5)利用3个3x3卷积堆叠而成的结构来达到下采样及提取细节特征的目的。
第一个3x3卷积
[3, 224, 224] --> [32, 112, 112]
第二个3x3卷积
[32, 112, 112] --> [32, 112, 112]
第三个3x3卷积
[32, 112, 112] --> [32, 112, 112]
图中2x2 Conv Stride=2其实就是Patch Embedding层,卷积核大小和步长均为patch_size。
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size) # img_size = [112, 112]
patch_size = to_2tuple(patch_size) # patch_size = [2, 2]
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0]) # 56 * 56 = 3136
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.img_size = img_size # 112
self.patch_size = patch_size # 2
self.num_patches = num_patches # 3136
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)在PatchEmbed中,首先通过x.shape获取B、C、H、W分别表示batchsize、channel、Height、Weight。之后通过一个卷积层,就是self.proj。卷积后由[B, 32, 112, 112] 变换为[B, 64, 56, 56]。
之后通过flatten(2)将H、W展平,由[B, 64, 56, 56]变为[B, 64, 3136]。之后再通过transpose(1, 2)调换1,2的顺序。即由[B, 64, 3136]变换为[B, 3136, 64]。最后在进行归一化处理。
stage中包含LPU局部感知单元,其实就是一个3x3的DW卷积,可通过指定Conv2d中的groups属性来实现。DW卷积中输入通道和输出通道以及groups的值必须相同。
LPU(local perception unit)局部感知单元:
LPU(X) = DWConv(X) + X
局部感知单元采用3x3的深度分离卷积,将卷积的平移不变形引入Transformer模块,并利用残差连接稳定网络训练。
stage1代码如下:
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=1., qkv_bias=False, qk_scale=None, drop=0.2, attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, qk_ratio=1, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, qk_ratio=qk_ratio, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.proj = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim) # DW卷积
self.bn = nn.BatchNorm2d(dim, eps=1e-5)
self.gelu = nn.GELU()
# self.mhca = MHCA(dim, head_dim=dim // num_heads)
self.ca_att = CoordAtt(dim, dim) # CA Attention
def forward(self, x, H, W, relative_pos):
B, N, C = x.shape
cnn_feat = x.permute(0, 2, 1).reshape(B, C, H, W)
# x = self.proj(cnn_feat) + cnn_feat
# x = self.mhca(cnn_feat) + cnn_feat
x = self.proj(cnn_feat)
x = self.bn(x)
x = self.gelu(x)
x = self.ca_att(x) + cnn_feat
x = x.flatten(2).permute(0, 2, 1)
x = x + self.drop_path(self.attn(self.norm1(x), H, W, relative_pos))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x预知后事如何,请看下回分解~下班了友友们


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









