







题目: 分布式系统负载均衡策略分析与研究
2021年 12 月
摘 要
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指将请求/数据均匀分摊到多个操作单元上执行,负载均衡的关键在于平均整体节点间的负载。常见的分布式系统的扩展可分为纵向(垂直)扩展和横向(水平)扩展。纵向扩展是指增强单机处理能力的角度来增强整体集群的处理能力,然而更为广泛的,更适用于分布式处理系统中的方式是横向扩展,即添加更多节点的方式来增强集群处理能力。能够便捷、快速、稳定的增减集群节点数量是现代分布式系统的核心功能之一,同时这个能力也满足了高可用性与可管理性的要求。分布式系统的负载均衡问题研究已经有数十年的研究历史,然而其本质上是一个NP完全问题,由于节点的异构型和集群通信的复杂性,开发人员难以准确量化节点工作负载和处理能力,也难以找到最优的负载调度和负载分发策略。本文首先从朴素的负载均衡策略出发介绍了负载均衡的基本思想,然后介绍并总结了近几年国内外最新的分布式系统负载均衡策略。
关键词 分布式计算 分布式存储 负载均衡
一、负载均衡的基本概念
随着数据库技术的发展以及大数据时代的海量数据到来,传统架构的单机处理能力显得力不从心,分布式的集群计算和存储成为了许多公司的选择。计算机软硬件的发展使得并行与分布式计算越来越流行,同时,计算机硬件成本的降低和快速网络的出现又使得基于网络的集群和网格计算流行起来[1]。使用多台计算机对于一个大规模事务的数据进行处理和存储就是分布式集群出现的最初目的。
然而,在目前真实的分布式计算环境中存在资源利用率低下或者处理能力不足的问题,一方面可能存在负载较低而导致的硬件资源浪费,另一方面又可能存在负载过高而造成的大规模处理缓慢,这也就要求分布式集群能够根据负载做出动态的调整。在分布式的集群环境下,提升计算性能的方法分为水平扩展和垂直扩展,水平扩展往往作为提升集群性能的第一选择,同时水平扩展也满足分布式系统对于高可用性和可管理性的要求,因此能够更好的管理集群中的大量节点是一个分布式操作系统的基本功能和要求。
当一个新的事务被提交到集群中时,如何分配这个任务到各个节点,以达到降低整体处理时延或者提高整体系统吞吐率的问题,就是负载均衡问题。负载均衡是提高 系统资源利用率和并行计算性能的一个关键技术,大致上可分为静态负载均衡和动态负载均衡两类,如果负载可以在运行之前确定并事先将负载划分,则属于静态负载均衡问题;若只能在运行时测量负载并动态确定负载划分,则属于动态负载均衡(Dynamic Load Balance, DLB)问题。
二、分布式负载均衡架构
负载均衡是高可用集群基础架构的关键组件,通常用于将工作负载分布到多个服务器来提高网站、应用、数据库或其他服务的性能和可靠性。
在没有负载均衡的CS结构中,用户直接与服务器交互,如果服务器宕机就会使得整个集群对于该用户而言变得不可用,或者如果同时有很多用户同时试图访问服务器,超过了其能处理的极限,就会低吞吐和高延迟的情况。这样的架构一方面可能发生大量用户都访问某个单节点而造成的负载偏斜问题,另一方面也不便于增加新的节点到集群中,关键节点的宕机会造成整个集群对外的服务中止,这显然是不满足服务的高可用性和可管理性的要求的。
因此,在这个基础上,将服务器集群通过一个负载均衡器封装起来,对外访问和暴露的接口都是通过这个负载均衡器来进行,从而实现了不同服务器节点之间进行负载调度和分发的可行性。
一个最基础、最朴素的架构是DNS轮询,也就是在访问时,通过DNS轮询不同服务器节点的方式提供服务,从而实现多台服务器水平扩展的目的。其好处是基本上没有成本,只需要在域名解析时操作即可。然而不能保障高可用,即使某个节点宕机也无法被检测到,还是会继续向客户提供服务,并且DNS更新缓慢,不能适应不同处理能力的节点做出变化。事实上,大型网站总是部分使用DNS域名解析,作为第一级负载均衡手段,然后再在内部做第二级负载均衡。
另一个与此类似的方法是NAT(Network Address Translation),NAT是一种外网和内网地址映射的技术。NAT模式下,网络数据报的进出都要经过LVS的处理。LVS需要作为RS(真实服务器)的网关。当包到达LVS时,LVS做目标地址转换(DNAT),将目标IP改为RS的IP。但由于所有请求响应的数据包都需要经过负载均衡服务器,因此负载均衡的网卡带宽成为系统的瓶颈。
另一种常用的负载均衡架构是使用Nginx作为反向代理负载均衡,反向代理的作用是保护节点安全,所有事务的请求都必须经过代理服务器,整个集群对外暴露的接口只有反向代理服务器。因此就可以在反向代理服务器上实现负载均衡和事务调度。当然,缺点同样是可能会成为性能瓶颈。
由于反向代理节点也有失效的可能,为了实现集群的高可用[2],一般选择部署反向代理集群,使用多台节点组成反向代理集群,在增强可用性的条件下无疑也增大了资源开销。
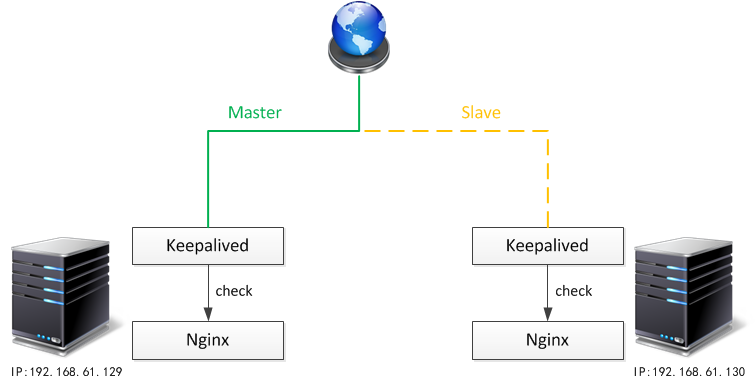
在反向代理集群中,一般情况下只有一个节点对外提供服务,其他节点作为备份。因此就有了keepalived技术。Keepalived的作用是监控集群节点的工作状态,在因为某种原因不能正常提供服务的前提下,完成备机的切换。这里面有两个关键点:监控节点上提供的服务、完成网络切换。也就是说,keepalived本身是不提供业务服务的,只是通过发送heartbeat的方式确保主节点功能正常。所以一般情况下会有Nginx + Keepalived的工作结构和LVS + Keepalived 的工作结构。
三、几种朴素的负载均衡策略
负载均衡的处理流程可以概括为接受事务请求、根据一定的方式分发请求、处理节点处理请求。这里的分发方式大致上分为四种。
轮询方式。轮询方式类似于上一节中的DNS轮询,接收到事务之后,轮询的向处理节点发送事务。这是最基本的配置方法,有点是事务分发绝对公平,而且开销小。如果发现某个处理节点宕机,就会自动跳过这台节点。缺点是不能适应不同节点处理能力不同的情况,有可能造成负载倾斜。
指定权重方式。考虑到应对不同节点有不同的处理能力,所以推出了指定权重的分配方法,也就是运算能力强的节点权重大,反之权重则小,然后通过随机分配的方式,权重作为选中的概率。优点是考虑到了节点的异构型,缺点是需要手动配置权重,而且难以准确的量化节点处理能力。
基于散列的方式,负载均衡器按照基于客户端IP的分配方式,这个方法确保了相同的客户端的请求一直发送到相同的服务器,以保证session会话。这样每个访客都固定访问一个后端服务器,可以解决session不能跨服务器的问题。
除此之外,还有一些根据节点指标进行分配的方式,例如基于最大连接数的分配,基于最短响应时间的分配。这些分配策略的核心都是通过某些指标量化某些节点的负载情况和性能,从而达到集群整体分配均匀的目的。问题在于很难有指标真正的量化节点负载情况,而且为了得到这些指标需要付出额外的开销。
四、复杂的分布式负载均衡策略
以上四种策略可以说是最为简单朴素的分布式负载均衡策略的思想。关于分布式的负载均衡,已经有许多学者做过相关的研究,这一部分就根据这些研究了解一些负载均衡领域最前沿的知识。
前面提到的思想都是比较通用的负载均衡思想,而涉及到更为复杂的情况时,通常都是针对某一领域的负载均衡。负载均衡在分布式环境中是一个常见的要求,在分布式数据库、分布式文件系统、复杂网络结构、云计算环境和分布式计算引擎等领域都有发挥着很重要的作用。
所有负载均衡策略的核心目的在于,当新事务被提交到系统时应该交由哪个或哪些节点处理以到达集群性能目标,这些目标包括降低总体时延、提高集群数据吞吐等。
这里大致的将分布式的负载均衡策略目的分为两个大的类别。
4.1 分布式数据存储系统负载均衡策略
分布式数据库的负载均衡一般是基于类似于Redis的主从模式实现,也就是所有的操作都需要经过一个中间件进行,而分布式数据库内部的操作,包括选择存储节点、同步数据一致性等具体操作则对用户完全透明。其负载均衡的操作一般也实现于这一中间件上。
与别的均衡策略不同,分布式数据库的负载策略更加偏向于提高IO效率和数据在不同节点间的同步性保证方面。
一方面,数据库的基本运行特征就是大量的IO操作,尤其对于大部分数据库集群而言,读操作要远远多于写操作。因此一个基本的技术就是读写分离技术。读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库服务器,主数据库提供写操作,从数据库提供读操作,其实在很多系统中,主要是读的操作。当主数据库进行写操作时,数据要同步到从的数据库,这样才能有效保证数据库完整性。主数据库另外一个功能就是负责将事务性查询导致的数据变更同步到从库中,也就是写操作。
另一方面,分布式数据库的另一大特性就是分布式存储和备份。为了数据的安全和充分利用集群资源,分布式数据库不会把大量的数据都存储在少数几个节点上。通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。拆分的方法包括将不同的表存储在不同节点(纵向拆分)或者将同一个表的数据进行分块保存到不同的数据库中(水平拆分),这些数据库中的表结构完全相同。
在分布式文件系统,例如GFS中,面临的挑战也主要在高并发的读操作和数据的强一致性保障上,往往以包含千兆字节的文件和包含千兆字节信息和数百万个对象的数据为特征[3]。GFS采用单Master节点的模式,HDFS采用NameNode存储文件原数据,这些文件系统的负载均衡策略也是在主节点上进行执行。此外,针对不同特性的特殊文件存储系统,例如超大文件存储系统[4]等还有独特的分布式文件系统设计。
总结而言,分布式数据库系统如Hbase与很多分布式文件系统如HDFS和GFS等专注于数据存储的分布式系统都是专注于数据IO的高并发以及数据的一致性保障。这一类的分布式系统往往会承担大量数据的存储、读写以及备份和同步要求,因此在提高IO并发性以及保障数据强一致性和分区容错性上有较多的设计。
4.2 分布式数据处理系统负载均衡策略
与分布式的数据存储系统负载均衡策略完全不同的另一个领域是分布式的数据处理系统的负载均衡策略。在数据处理的分布式系统中,负载均衡策略更像是一种调度策略,其核心往往是通过向不同节点分发子任务使得充分利用集群计算资源,计算并发度提高从而降低处理时延或者增大吞吐量。
另一个不同的在于分布式数据处理系统更多的会根据从集群节点反馈的数据和集群指标中挑选最佳的处理集群节点,而非像存储系统那样主要是由Master来管理和调度。
一个典型的分布式计算环境是云计算环境。云计算是计算机领域的一项现代技术,可以随时为客户提供服务。在云计算系统中,资源分布在世界各地,以更快地为客户提供服务为目的[5]。云计算的核心技术就是虚拟容器技术[6],物理上的一台节点可以逻辑上被划分为多个节点,而负载均衡策略就虚拟容器进行调度和任务分配。在这方面有着许多的研究和算法,负载均衡器会根据许多指标,包括:吞吐量、响应时间、最大完成时间、可扩展性等,利用强化学习算法[7]或者一些朴素的算法选择最佳的分配负载的策略。
另一个分布式计算环境就是一系列的分布式处理引擎,例如最早期的Mapreduce,以及最新的分布式流处理引擎Flink等。这些部署在集群式上处理引擎有一部分的核心功能就是处理在分布式环境下高可用、高效的完成数据的处理和计算。以Flink[8]为例,其使用Yarn、K8S等资源管理框架调度物理资源,使用基于有向无环图(DAG)的方式在不同节点上均匀负载,以最小时延为目标。
五、总结
本文首先介绍了分布式负载均衡的基本概念,然后讲解了几种朴素的分布式系统负载均衡策略,最后结合近几年相关领域的研究总结了两种大类的分布式负载均衡策略类型。
数据存储类的分布式系统负载均衡策略将更多的重心放在提高IO读取速度和数据的一致性保证上,这类负载均衡策略主要有Master节点实现,使用读写分离和多种高效的同步策略来提高数据存储速度、读写速度,以及更加均匀的分派IO负载和存储硬件资源负载。
数据计算类的分布式系统负载均衡策略更加类似于计算的调度器,其目的在于通过提高计算并行度、更加高效的利用硬件资源、较小通信时延的方式,降低处理时延,提高系统吞吐。
[1] 杨际祥, 谭国真, 王荣生. 并行与分布式计算动态负载均衡策略综述[J]. 电子学报, 2010, 38(5):9.
[2] YU L, RUAN W. Research and Implementation of Load Balance Technology [J][J]. Computer Technology and Development, 2007, 8.
[3] Ghemawat S, Gobioff H, Leung S T. The Google file system[C]//Proceedings of the nineteenth ACM symposium on Operating systems principles. 2003: 29-43.
[4] Liu H, Ding W, Chen Y, et al. Cfs: A distributed file system for large scale container platforms[C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 1729-1742.
[5] Ghomi E J, Rahmani A M, Qader N N. Load-balancing algorithms in cloud computing: A survey[J]. Journal of Network and Computer Applications, 2017, 88: 50-71.
[6] Elveny, Marischa & Winata, Ari & Siregar, Baihaqi & Rahmad Syah, Bayu. (2020). A tutorial: Load balancers in a container technology system using docker swarms on a single board computer cluster. 19. 744-751. 10.17051/ilkonline.2020.04.178.
[7] Asghari A, Sohrabi M K, Yaghmaee F. Task scheduling, resource provisioning, and load balancing on scientific workflows using parallel SARSA reinforcement learning agents and genetic algorithm[J]. The Journal of Supercomputing, 2021, 77(3): 2800-2828.
[8] Carbone P, Katsifodimos A, Ewen S, et al. Apache flink: Stream and batch processing in a single engine[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2017, 36(4).
















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









