







参考文章:https://blog.csdn.net/wcy23580/article/details/84957471
参考内容:https://blog.csdn.net/wcy23580/article/details/84873088
keras只能接受长度相同的序列输入。数据处理需要使用pad_sequences(),将序列转化为经过填充以后的一个长度相同的新序列。
语法结构:
keras.preprocessing.sequence.pad_sequences(sequences,
maxlen=None,
dtype='int32',
padding='pre',
truncating='pre',
value=0.)
sequences:浮点数或整数构成的两层嵌套列表
maxlen:None或整数,为序列的最大长度。大于此长度的序列将被截短,小于此长度的序列将在后部填0.
dtype:返回的numpy array的数据类型
padding:‘pre’或‘post’,确定当需要补0时,在序列的起始还是结尾补`
truncating:‘pre’或‘post’,确定当需要截断序列时,从起始还是结尾截断
value:浮点数,此值将在填充时代替默认的填充值0
返回的是一个二维张量,其中序列长度均为maxlen
例子:
来源知乎:https://zhuanlan.zhihu.com/p/269884974
1.导入数据
from keras.datasets import imdb
from keras.preprocessing import sequence
(X_train, y_train), (X_test, y_test) = imdb.load_data()
2.查看第0篇文本长度和第10篇文本长度
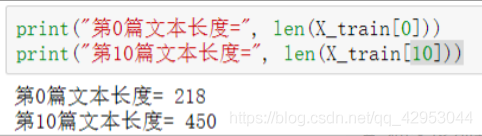
3.使用pad_sequences()使各序列长度为400
# 使各序列长度都为400
max_sequence_len = 400
X_train = sequence.pad_sequences(X_train, maxlen=max_sequence_len)
4.查看填充后的第0篇文本(默认前面补0)
















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









