







python菜鸟教程
文章目录
基础教程
简介
- Python 是一种解释型语言,需要虚拟机(?)来运行,边运行边解释编译。
编译型语言如C,运行前先完成编译。编译型语言运行的已经是完全的二进制内容,运行起来十分干净利落,所以速度很快。 - python是面向对象语言。三个基本特征是:封装、继承(接口?)、多态(??)。
- python是交互式语言。交互式编辑器
- python可嵌入C++程序中
基础语法(略)
变量类型
标准数据类型
-
Python有五个标准的数据类型:
Numbers(数字) String(字符串) List(列表) Tuple(元组) Dictionary(字典)
数字
-
Python支持四种不同的数字类型:
int(有符号整型)
long(长整型,也可以代表八进制和十六进制)
float(浮点型)
complex(复数) -
math 模块、cmath 模块
Python 中数学运算常用的函数基本都在 math 模块、cmath 模块中。Python math 模块提供了许多对浮点数的数学运算函数。
Python cmath 模块包含了一些用于复数运算的函数。
cmath 模块的函数跟 math 模块函数基本一致,区别是 cmath 模块运算的是复数,math 模块运算的是数学运算。
-
随机数函数
choice(seq) 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。
randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1
random() 随机生成下一个实数,它在[0,1)范围内。
seed([x]) 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。
shuffle(lst) 将序列的所有元素随机排序
uniform(x, y) 随机生成下一个实数,它在[x,y]范围内。
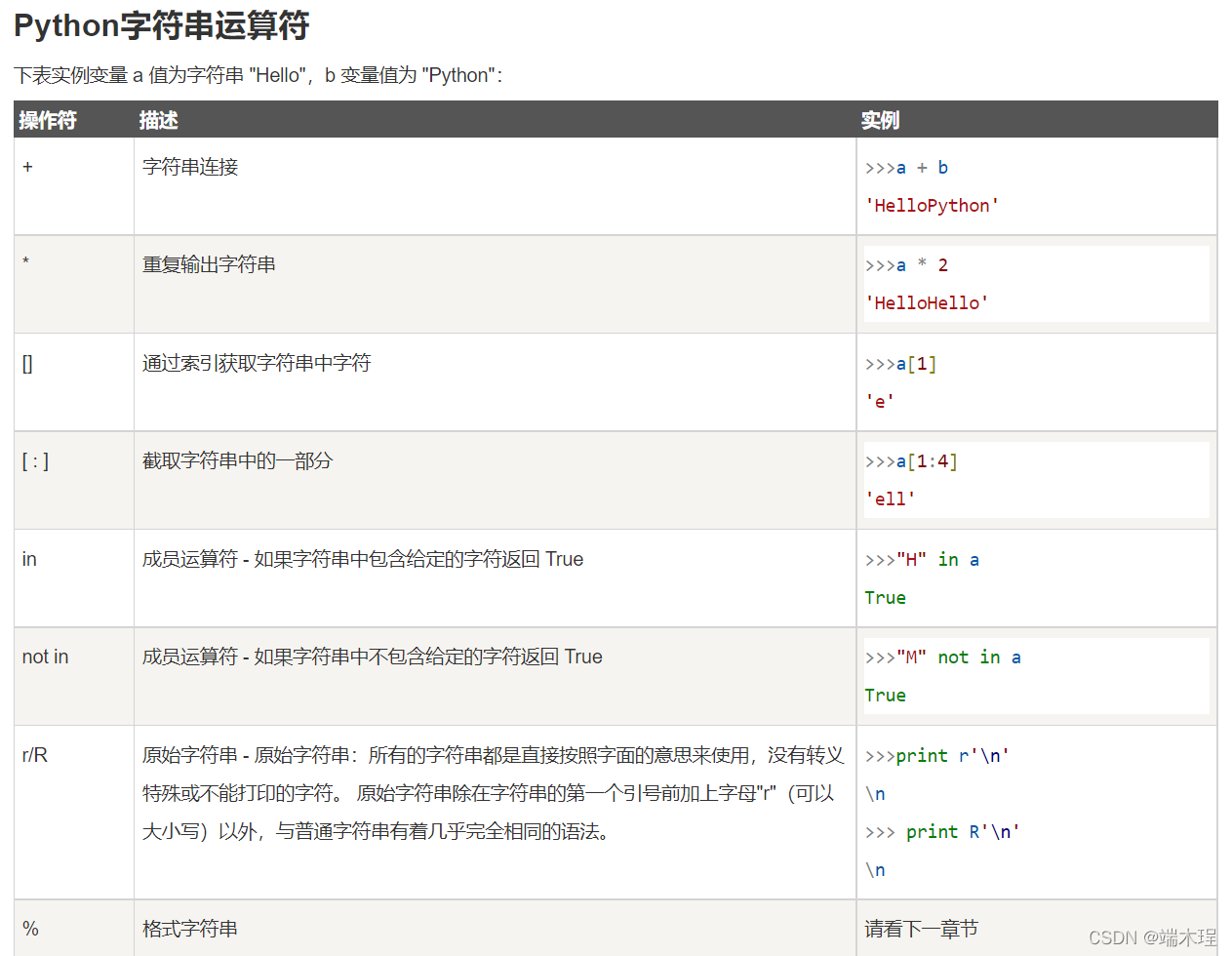
字符串
-
python的字串列表有2种取值顺序:
从左到右索引默认0开始的,最大范围是字符串长度少1
从右到左索引默认-1开始的,最大范围是字符串开头[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
Python 列表截取可以接收第三个参数,参数作用是截取的步长,
以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串。letters[1:4:2],取到2和3两位。
列表
-
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
list = [ ‘runoob’, 786 , 2.23, ‘john’, 70.2 ]
tinylist = [123, ‘john’] -
更新列表 list.append(‘xxx’)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
list = [] ## 空列表
list.append('Google') ## 使用 append() 添加元素
list.append('Runoob')
print list
['Google', 'Runoob']
- 删除列表元素
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000]
print list1
del list1[2]
print "After deleting value at index 2 : "
print list1
['physics', 'chemistry', 1997, 2000]
After deleting value at index 2 :
['physics', 'chemistry', 2000]
元组
-
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表
tuple = ( ‘runoob’, 786 , 2.23, ‘john’, 70.2 )
tinytuple = (123, ‘john’)
字典
-
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
tinydict = {‘name’: ‘runoob’,‘code’:6734, ‘dept’: ‘sales’}
数据类型转换
float(x)
运算符
Python语言支持以下类型的运算符:
算术运算符
比较(关系)运算符
赋值运算符
逻辑运算符
位运算符
成员运算符
身份运算符
运算符优先级
算术运算符
// 取整除 - 返回商的整数部分(向下取整)
>>> 9//2
4
>>> -9//2
-5
赋值运算符
+= 加法赋值运算符 c += a 等效于 c = c + a
-= 减法赋值运算符 c -= a 等效于 c = c - a
*= 乘法赋值运算符 c *= a 等效于 c = c * a
/= 除法赋值运算符 c /= a 等效于 c = c / a
%= 取模赋值运算符 c %= a 等效于 c = c % a
**= 幂赋值运算符 c **= a 等效于 c = c ** a
//= 取整除赋值运算符 c //= a 等效于 c = c // a
位运算符(?)
按位运算符是把数字看作二进制来进行计算的。
逻辑运算符
以下假设变量 a 为 10, b为 20:
x and y 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 (a and b) 返回 20。
x or y 如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值。 (a or b) 返回 10。
not x 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 not(a and b) 返回 False
成员运算符 in/not in
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
in
not in
身份运算符 is/is not
身份运算符用于比较两个对象的存储单元
is 是判断两个标识符是不是引用自一个对象 x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False
is not 是判断两个标识符是不是引用自不同对象 x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。
注: id() 函数用于获取对象内存地址。
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间,一个变量俩名字?), == 用于判断引用变量的值是否相等。
运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
运算符 描述
** 指数 (最高优先级)
~ + - 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@)
* / % // 乘,除,取模和取整除
+ - 加法减法
>> << 右移,左移运算符
& 位 'AND'
^ | 位运算符
<= < > >= 比较运算符
<> == != 等于运算符
= %= /= //= -= += *= **= 赋值运算符
is is not 身份运算符
in not in 成员运算符
not and or 逻辑运算符
条件语句 if (): elif (): else:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 例2:elif用法
num = 5
if num == 3: # 判断num的值
print 'boss'
elif num == 2:
print 'user'
elif num == 1:
print 'worker'
elif num < 0: # 值小于零时输出
print 'error'
else:
print 'roadman' # 条件均不成立时输出
循环语句
while
while 判断条件(condition):
执行语句(statements)……
for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
for iterating_var in sequence:
statements(s)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
for letter in 'Python': # 第一个实例
print("当前字母: %s" % letter)
fruits = ['banana', 'apple', 'mango']
for fruit in fruits: # 第二个实例
print ('当前水果: %s'% fruit)
fruits = ['banana', 'apple', 'mango']
for index in range(len(fruits)):
print ('当前水果 : %s' % fruits[index])
print ("Good bye!")
break
continue
pass 空语句,是为了保持程序结构的完整性。
函数
模块
高级教程
面向对象
正则表达式
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
re.search 扫描整个字符串并返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
findall在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
re.finditer和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
split 方法按照能够匹配的子串将字符串分割后返回列表。














 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









