







文章目录
前言

作为后端开发应该对整体系统架构有一定了解。所以需要学习有关软件系统架构知识。我采用读书的方式去了解整体软件系统架构,所读书名《从零开始学架构》。
学习目标:
1.架构设计目的及复杂度来源
2.架构设计流程
3.高性能架构
4.CAP理论和FMEA方法
5.高可用架构
6.可扩展架构
7.微服务架构最佳实践
8.互联网架构技术
写此博客的目的:
1.完成学习目标
2.对书中内容进行总结,得到自己的阅读心得
3.方便其他入门小伙伴快速得到干货
4.方便自己回顾架构知识
在上一个帖子:【架构学习(一)】架构设计目的及复杂度来源
架构设计三原则
架构师做需要做的:对已经存在的技术非常熟悉,对已经经过验证的架构模式烂熟于心,然后根据自己对业务的理解,挑选合适的架构模式进行组合,再对组合后的方案进行修改和调整。
架构设计三原则:合适原则、简单原则、演化原则
什么是合适原则?
合适也就是适应当前需要是首位的,连当前需求都满足不了谈不到其他。
什么是简单原则?
“简单优于复杂”
复杂在软件领域的复杂性体现在两个方面:
| 结构的复杂性 | 逻辑的复杂性 |
|---|---|
| 组件越多,就越有可能其中某个组件出现故障,导致系统故障。 | 不能单个组件承担太多业务功能,需要拆分为更多组件。 |
| 某个组件改动,会影响关联的其他组件。 | – |
| 定位一个复杂系统中的问题更加困难。 | – |
什么是演化原则?
宣言:“演化优于一步到位”。
1)设计出来的架构要满足当时的业务需要。
2)架构要不断地在实际应用过程中迭代,保留优秀的设计,修复有缺陷的设计,改正错误的设计,去掉无用的设计,使得架构逐渐完善。
3)当业务发生变化时,架构要扩展、重构,甚至重写;代码也许会重写,但有价值的经验、教训、逻辑、设计等却可以在新架构中延续。
一、架构设计流程:识别复杂度
如何识别复杂度?
复杂度问题列出来,然后根据业务、技术、团队等综合情况进行排序,优先解决当前面临的最主要的复杂度问题。
1)构建复杂度的来源清单——高性能、可用性、扩展性、安全、低成本、规模等。
2)结合需求、技术、团队、资源等对上述复杂度逐一分析是否需要?是否关键?
“高性能”主要从软件系统未来的TPS、响应时间、服务器资源利用率等客观指标,也可以从用户的主观感受方面去考虑。
“可用性”主要从服务不中断等质量属性,符合行业政策、国家法规等方面去考虑。
“扩展性”则主要从功能需求的未来变更幅度等方面去考虑。
3)按照上述的分析结论,得到复杂度按照优先级的排序清单,越是排在前面的复杂度,就越关键,就越优先解决。
二、架构设计流程:设计备选方案
为什么需要备选方案?
知识局限,评估未全面
做架构设计时两种查关键错误方案:
1)设计最优秀的方案
2) 只做一个方案
备选方案需要注意:
1)不要耗费了大量的时间和精力
2)备选方案的差异要比较明显
3)备选方案的数量以 3 ~ 5 个为最佳
4)备选方案的技术不要只局限于已经熟悉的技术
事实上方案的创新绝大部分情况下也都是基于已有的成熟技术,例如:
NoSQL:Key-Value 的存储只是把数据库的索引独立出来做成了一个缓存系统。
Docker 虚拟化,基础是 LXC(Linux Containers)。
LevelDB 的文件存储结构是 Skip List。
三、架构设计流程:评估和选择备选方案
如何评估和选择备选方案?
优先级选择,即架构师综合当前的业务发展情况、团队人员规模和技能、业务发展预测等因素,将质量属性按照优先级排序,首先挑选满足第一优先级的,如果方案都满足,那就再看第二优先级评估和选择备选方案实战。
四、架构设计流程:详细方案设计
如何详细方案设计?
1)技术方案选择是很轻量级的,只需要简单根据这些技术的适用场景选择。
2)架构师不但要进行备选方案设计和选型,还需要对备选方案的关键细节有较深入的理解。比如用es需要对es有深入理解。
3)尽量降低方案复杂度。
例如:Nginx 的负载均衡策略
1)轮询(默认)
2)加权轮询
3)ip_hash
4)fair
5)url_hash
根据业务需要,挑选一个合适的即可。例如,比如一个电商架构,由于和 session 比较强相关,因此如果用 Nginx 来做集群负载均衡,
五、例子:前浪微博
识别复杂度
前浪微博有两个功能,第一个用户发微博,主系统会推给多个子系统(审核,广告…)。
第二个是用户vip等级提升,需要通知其他子系统提供服务。
TPS:110 QPS:11010(预估每次功能需要耦合10个子系统)
预估峰值: TPS:330 QPS:33010
拓展峰值: TPS:440 QPS:440*10 (当前峰值的4-10倍)
| 用户发微博 | 用户vip等级提升 |
|---|---|
| 主系统会推给多个子系统(审核,广告…) | 需要通知其他子系统提供服务 |
| TPS:110 | TPS:110 |
| QPS:1100 | QPS:1100 |
| 预估峰值: TPS:330 QPS:3300 | 预估峰值: TPS:330 QPS:3300 |
| 拓展峰值: TPS:440 QPS:4400 | 拓展峰值: TPS:440 QPS:4400 |
这两个功能出现的问题,是各个子系统强耦合,需要完成子系统耦合问题。
于是针对这个系统做一下分析:
1)这个消息队列是否需要高性能 需要(对TPS,QPS进行分析)
2)这个消息队列是否需要高可用性 需要(因为功能需要所有子系统功能都完成)
3)这个消息队列是否需要高可扩展性 不需要(满足两个功能即可)
设计备选方案
“前浪微博”的场景经过复杂度分析,需要高性能,高可用,无需扩展。
- 高性能消息读取
- 高可用消息写入
- 高可用消息存储
- 高可用消息读取
- qps:13800
备选方案 1 采用开源的 Kafka
每秒百万级别,开源
备选方案 2 集群 + MySQL 存储
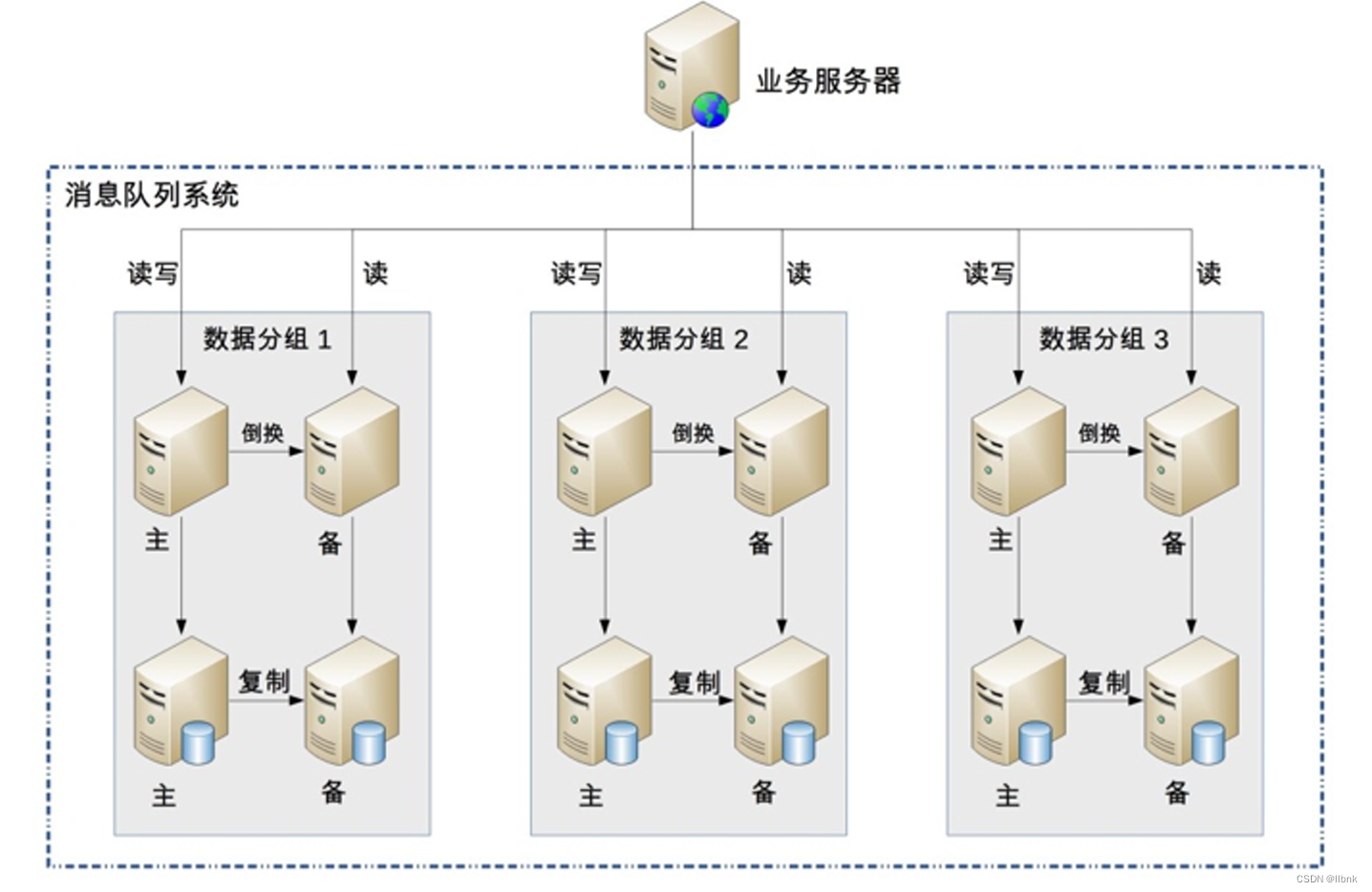
1)为什么选择集群:
首先考虑单服务器高性能,单机采用 Netty 来构建高性能系统不满足如此之高的qps,集群的负载均衡算法采用简单的轮询即可。
2)高性能消息读取怎么满足?
高可用读取(已经写入的消息在单台服务器宕机的情况下可以继续读取。)可以采用主从复制方式。
3)高可用消息存储怎么解决?
MySQL 的主备复制功能来达到“高可用存储“的目的。
备选方案 3:集群 + 自研存储方案
评估和选择备选方案
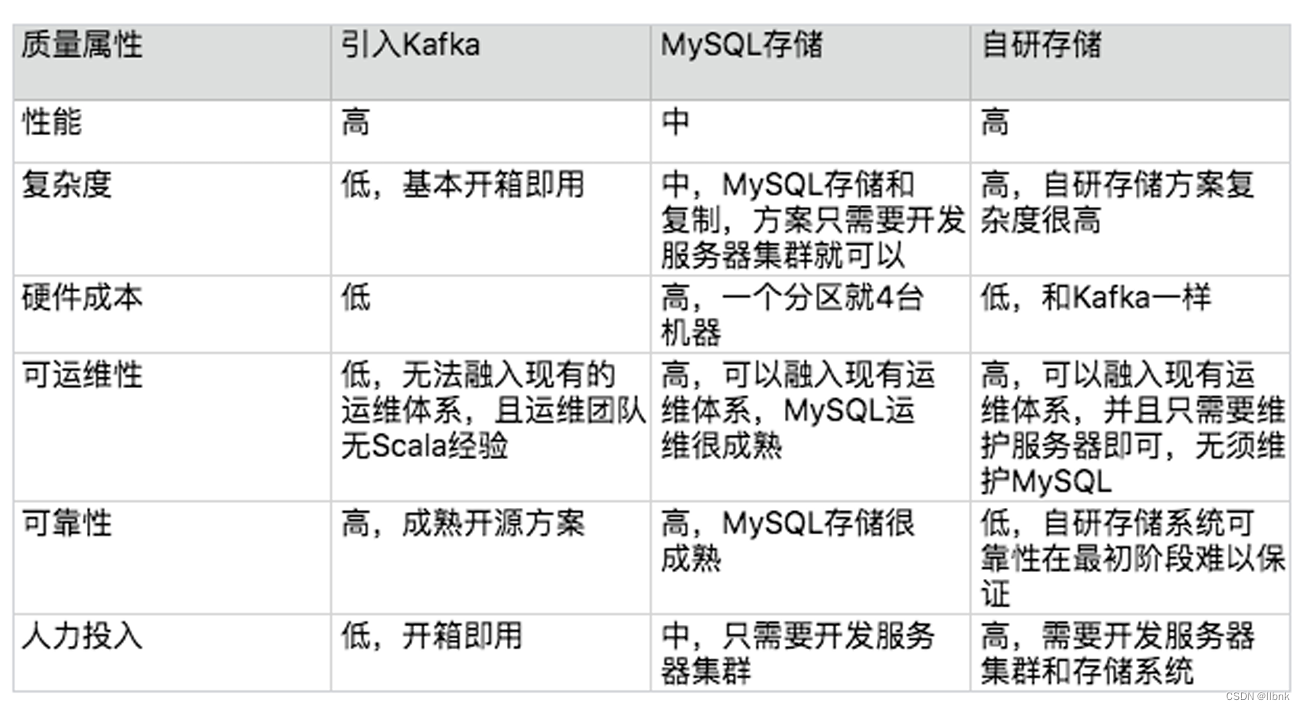
选择方案2的原因
1)可运维性(方案1)(Kafka的业务应用场景主要定位于日志传输)
2)复杂度(方案3)(自研虽然性能,运维好,但是系统可用性差(新系统有bug))
3)满足合适原则
方案2的缺点
1)性能
2)成本(机器成本)
细化设计点
细化设计点 1 数据库表设计
- 怎么设计表?
- 表之间的存储逻辑?
- 表设计细节?
- 业务怎么读取?
- 归档问题?
1)怎么设计表?
两种表,日志表(用于消息写入时快速存储到 MySQL 中)和消息表(每个消息队列一张表)。
2)表之间的存储逻辑?
业务系统发布消息时,首先写入到日志表,日志表写入成功就代表消息写入成功;后台线程再从日志表中读取消息写入记录,将消息内容写入到消息表中。
3)表设计细节?
日志表表名为 MQ_LOG,包含的字段:日志 ID、发布者信息、发布时间、队列名称、消息内容。消息表表名就是队列名称,包含的字段:消息 ID(递增生成)、消息内容、消息发布时间、消息发布者。(这个消息队列没办法指定发送人!!)
4)业务怎么读取?
从消息表中读取
5)归档问题?
日志表需要及时清除已经写入消息表的日志数据,消息表最多保存 30 天的消息数据
细化设计点 2:数据如何复制?
1)直接采用 MySQL 主从复制即可,只复制消息存储表,不复制日志表。
细化设计点 3:主备服务器如何倒换?
(zookeeper尚未学习,这里感觉方案二的确有点复杂因为不引入kafka,但是还是引入其他第三方中间件了,可能因为zookeeper也是java开发的吧)
1)采用 ZooKeeper 来做主备决策,备机监听主机的节点消息,当发现主服务器节点断连后,备服务器修改自己的状态,对外提供消息读取服务。
细化设计点 4:业务服务器如何写入消息?
1)消息队列系统设计两个角色:生产者和消费者,每个角色都有唯一的名称。
2)消息队列系统提供 SDK 供各业务系统调用,SDK 采取轮询算法发起消息写入请求给主服务器。如果某个主服务器无响应或者返回错误,SDK 将发起请求发送到下一台服务器。
细化设计点 5:业务服务器如何读取消息?
1集群中每组消息队列服务器都会记录消息信息,因为是广播模式,所以需要SDK能拿到集群中所有机器信息轮询一边所有机器,把所有机器没读的信息都返回,而每台机器需要记录当前用户读到那条信息了。
细化设计点 6:业务服务器和消息队列服务器之间的通信协议如何设计?
1)考虑到消息队列系统后续可能会对接多种不同编程语言编写的系统,为了提升兼容性,传输协议用 TCP,数据格式为 ProtocolBuffer
总结
软件设计整体流程分为三部分,第一个刨析复杂度问题,找到几个适合本次需求的合理方案,根据优先级选择法去选择最适合的方案,并对该方案进行详细设计。而整体方案思路是又大到小,需要对设计内容有充分认值和理解(理论和源码)。由此还是需要平时对中间件的学习和积累。
我的目标
希望在年底学习一下内容:
java学习内容:
1.tomcat源码
2.dubbo源码
3.zookeeper源码
4.netty源码
go学习内容:
1.gin框架学习
2.简单go项目
3.go基础知识进阶(gmp,gc,channel,map,slice源码等)
中间件学习内容:
1.kafka使用及源码
框架学习内容:
1.从零开始学架构
算法学习内容:
1.复习leetcode中top 100
我平时喜欢没事还打游戏,因为有宝宝所以希望在平时时间能尽量完成上述学习内容(希望能戒掉游戏哈哈哈)。
也希望有和我一样的一起学习的小伙伴共同学习进步,我建一个qq后端交流群:279868576,希望小伙伴们加入共同督促进步。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









