






文章目录
一、什么是集成算法?
集成学习(ensemble learning)是时下非常流行的算法,广泛应用于各种竞赛中,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的模型结果。基本上所有的机器学习领域都可以看到集成学习的身影,在现实中,集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源、流失,也可以用作预测疾病的风险和患者的感染性,在现在的各种竞赛中,随机森林,梯度提升树,Xgboost等集成算法随处可见。
集成算法会考虑多个评估器的建模结果,汇总成一个综合的结果,以此来获取比单个模型要好的分类或回归表现。本文着重介绍随机森林和Xgboost两种算法。
二、随机森林RandomForest
2.1 原理介绍
随机森林是属于袋装类(Bagging)集成算法,其核心思想是构建多个相互独立的评估器,然后对其预测结果进行平均或少数服从多数的原则来决定集成评估器的评估结果。原理如下图所示:
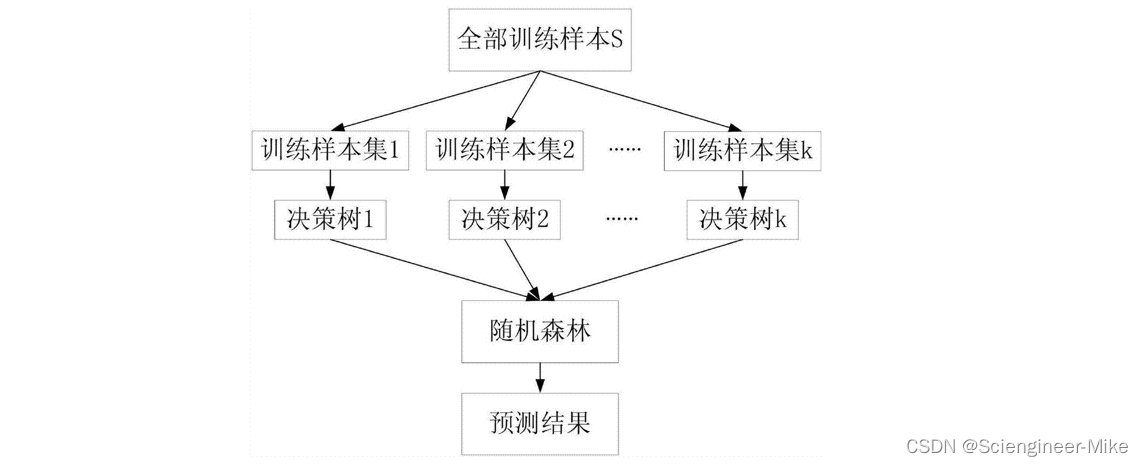
有没有想过随机森林里面的决策树都一样,即只有一颗树,那岂不就是像决策树算法没有区别了。那么,随机森林是怎样保证每个树都不一样的呢?一种很容易理解的方法是使用不同的训练集来进行训练,而袋装法正是通过有放回的随机抽样技术来形成不同的训练数据。在一个含有n个样本的原始训练集中,我们进行随机采样,每次采样一个样本,并在抽取下一个样本之前将该样本
放回原始训练集,也就是说下次采样时这个样本依然可能被采集到,这样采集n次,最终得到一个和原始训练集一样大的,n个样本组成的自助集。由于是随机采样,这样每次的自助集和原始数据集不同,和其他的采样集也是不同的。这样我们就可以自由创造取之不尽用之不竭,并且互不相同的自助集,用这些自助集来训练我们的基分类器,我们的基分类器自然也就各不相同了。
然而有放回抽样也会有自己的问题。由于是有放回,一些样本可能在同一个自助集中出现多次,而其他一些却可能被忽略,一般来说,自助集大约平均会包含63%的原始数据。因为每一个样本被抽到某个自助集中的概率为:
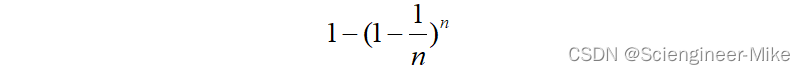
当n足够大时,这个概率收敛于1-(1/e),约等于0.632。因此,会有约37%的训练数据被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简写为oob)。除了我们最开始就划分好的测试集之外,这些数据也可以被用来作为集成算法的测试集。也就是说,在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外数据来测试我们的模型即可。
2.2 sklearn-API介绍
sklearn_API如下:
class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’gini’, max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False,n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
–重要参数:
n_estimators:树的数量。
criterion:选择分类准则,包括信息熵:“entropy"和基尼系数”gini“。
random_state:随机模式。
splitter:用来控制决策树中的随机选项的,包括:“best"和"random”。
max_depth:树的最大深度。
min_samples_leaf:限定一个节点在分支后的每个子节点必须至少包含训练样本的数目。
2.3 代码实现
对比随机森林和决策树的回归结果,代码如下:
# 导入包
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
# 导入boston数据集
X,y = load_wine(return_X_y=True)
# 划分训练集和测试集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=0)
#建模预测(在不调参数的情况下看决策树和随机森林的结果)
clf = DecisionTreeRegressor(random_state=0)
rfc = RandomForestRegressor(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
#查看结果
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("决策树的准确率为:",score_c)
print("随机森林的准确率为:",score_r)
在不调参数的情况下,随机森林的效果明显好于决策树。

# 导入包
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
# 导入boston数据集
X,y = load_boston(return_X_y=True)
# 划分训练集和测试集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=0)
#建模预测(在不调参数的情况下看决策树和随机森林的结果)
result = []
for i in range(200):
rfr = RandomForestRegressor(random_state=0,n_estimators=i+1)
rfr = rfr.fit(Xtrain,Ytrain)
#查看结果
score_r = rfr.score(Xtest,Ytest)
result.append(score_r)
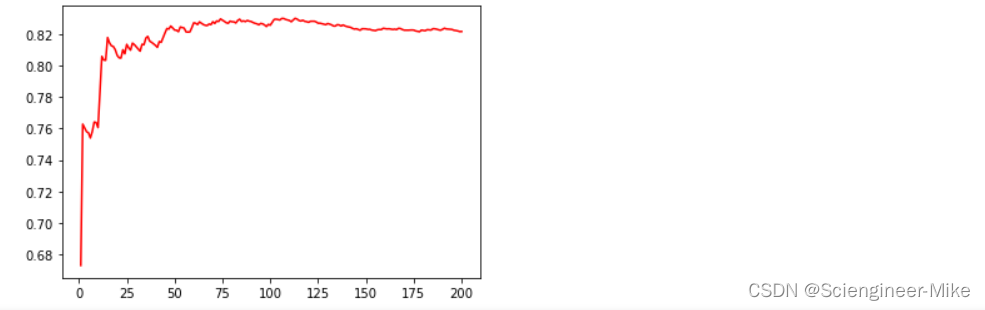
# 绘图,寻找最优参数结果
plt.plot(range(1,201),result,color="red")
plt.show()
结果如下:
三、Xgboost
3.1 原理介绍
Xgboost是属于集成算法中的提升集成算法(Boosting),它是一种串行的算法,根据前一次的结果,进行加权来提高训练效果,如下图所示。提升法的中最著名的算法包括Adaboost和梯度提升树,XGBoost就是由梯度提升树发展而来的。梯度提升树中可以有回归树也可以有分类树,两者都以CART树算法作为主流,XGBoost背后也是CART树,这意味着XGBoost中所有的树都是二叉的。
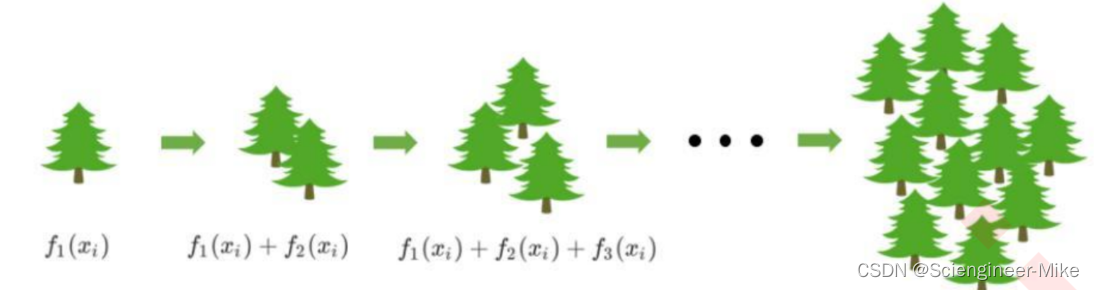
在梯度提升树中,我们每一次迭代都要建立一棵新的树,因此我们每次迭代中,都要有放回抽取一个新的训练样本。不过,这并不能保证每次建新树后,集成的效果都比之前要好。因此我们规定,在梯度提升树中,每构建一个评估器,都让模型更加集中于数据集中容易被判错的那些样本。建模完
毕之后,我们又将判错的样本反馈给原始数据集。下一次迭代的时候,被判错的样本的权重会更大,新的模型会更加倾向于很难被判断的这些样本。如此反复迭代,越后面建的树,越是之前的树们判错样本上的专家,越专注于攻克那些之前的树们不擅长的数据。
3.2 Xgboost-API介绍
Xgboost-API:
class xgboost.XGBRegressor (kwargs,max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,objective=‘reg:linear’, booster=‘gbtree’, n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, importance_type=‘gain’)
– 重要参数:
max_depth:决策树的最大深度。
learning_rate:类似于逻辑回归中的学习率,该值越大,迭代速度越快,算法的极限很快到达,有可能没法收敛到最佳;越小,越有可能收敛到真正的最佳,但迭代速度比较慢。
n_estimators:树的个数。
subsample:随机抽样的抽取样本比例。
objective:损失函数的选择,包括:reg:linear,binary:logistic,binary:hinge,multi:softmax。
reg_alpha:L1正则项参数alpha。
reg_lambda:L2正则项参数lambda。
gamma:复杂度惩罚项。
3.3 代码实现
xgboost训练数据集代码如下:
# 导入包
import numpy as np
import matplotlib.pyplot as plt
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import KFold, cross_val_score as CVS, train_test_split as TTS
from sklearn.metrics import r2_score
# 导入数据boston房子数据集
X,y = load_boston(return_X_y=True)
#划分训练集和测试集
Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)
# 打包数据
dtrain = xgb.DMatrix(Xtrain,Ytrain)
dtest = xgb.DMatrix(Xtest,Ytest)
#设定参数,对模型进行训练
param = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"eta":0.05
,"gamma":20
,"lambda":3.5
,"alpha":0.2
,"max_depth":4
,"colsample_bytree":0.4
,"colsample_bylevel":0.6
,"colsample_bynode":1}
num_round = 180
#训练
bst = xgb.train(param, dtrain, num_round)
#测试
r2_score(Ytest,bst.predict(dtest))
准确率达到了0.9014。

代码Pickle打包:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE, r2_score
import pickle
import xgboost as xgb
X,y = load_boston(return_X_y=True)
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
#注意,如果我们保存的模型是xgboost库中建立的模型,则导入的数据类型也必须是xgboost库中的数据类型
dtest = xgb.DMatrix(Xtest,Ytest)
#导入模型
loaded_model = pickle.load(open("xgboostonboston.dat", "rb"))
print("Loaded model from: xgboostonboston.dat")
#做预测
ypreds = loaded_model.predict(dtest)
r2_score(Ytest,ypreds)
结果如下:

四、总结
本文主要对集成学习两个经典的算法RandomForest和Xgboost进行了简单的原理介绍,并使用sklearn和xgboost-API为大家直观的呈现了两种算法的实现过程,希望对大家有所帮助。
链接: 【机器学习之逻辑回归】sklearn+python逻辑回归详解
链接: 【机器学习之特征工程】数据预处理、特征选择、降维及不平衡处理
链接: 【机器学习之聚类算法】KMeans原理及代码实现
链接: 【机器学习之线性回归】多元线性回归模型的搭建+Lasso回归的特征提取
链接: 【机器学习之决策树】决策树原理介绍及代码实现sklearn


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









