







零基础爬取哔哩哔哩信息
该博客将我爬取哔哩哔哩网站数据的过程中遇到的问题及整体爬取思路做详细阐述,希望能帮助到有需要的码农们,有问题可私信问我。
源代码
话不多说直接上代码:
import requests
from lxml import etree
import xlwt
import time
import random
data = []
def get_info():
i=0
while(i<=50):
i+=1
time.sleep(1)
#获取html页面
if(i==1):
url = 'https://search.bilibili.com/all?keyword=%E7%96%AB%E8%8B%97%E7%A7%91%E6%99%AE&from_source=nav_search&spm_id_from=333.851.b_696e7465726e6174696f6e616c486561646572.9'
else:
url='https://search.bilibili.com/all?keyword=%E7%96%AB%E8%8B%97%E7%A7%91%E6%99%AE&from_source=nav_search&spm_id_from=333.851.b_696e7465726e6174696f6e616c486561646572.9&page='+str(i)
head=[
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
]
headers={
'user-agent':random.choice(head),
'Referer':'https://www.bilibili.com/',
'cookie':"_uuid=38505D66-5836-7006-B441-D8A7F44B081255211infoc; buvid3=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; sid=jtgdj478; LIVE_BUVID=AUTO5015857997467736; rpdid=|(~u|RmYY)J0J'ul)l~mm~R~; LIVE_PLAYER_TYPE=2; blackside_state=1; fingerprint=b7046ad02d6444e63a99648735729cdc; buvid_fp=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; buvid_fp_plain=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; DedeUserID=319136001; DedeUserID__ckMd5=c2fd54a2f5fbb92c; SESSDATA=edc55d5a%2C1629375534%2Caf07a*21; bili_jct=fcc932e20010531a42957e154977371f; CURRENT_FNVAL=80; bsource=search_google; finger=-166317360; arrange=list; PVID=1"
}
res = requests.get(url=url,headers=headers)
res.encoding = 'utf-8'
html = res.text
#解析页面,提取目标信息
tree = etree.HTML(html)
lis = tree.xpath('/html/body/div[3]/div/div[2]/div/div[1]/ul/li')
print(lis)
for li in lis:
info = []
#提取视频名
name = li.xpath('./a/@title')[0]
info.append(name)
#提取链接
link = li.xpath('./a/@href')[0]
info.append(link)
#提取播放量
play_num = li.xpath('./div/div[3]/span[1]/text()')[0]
info.append(play_num)
#提取弹幕数
discuss = li.xpath('./div/div[3]/span[2]/text()')[0]
info.append(discuss)
#提取时间
up_time = li.xpath('./div/div[3]/span[3]/text()')[0]
info.append(up_time)
#提取up主
up = li.xpath('./div/div[3]/span[4]/a/text()')[0]
info.append(up)
#汇总到data列表中
data.append(info)
def main():
get_info()
#保存数据
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('sheet1')
#写表头
col_name = ('视频名','视频链接','播放量','弹幕量','上传时间','up主')
for i in range(6):
ws.write(0,i,col_name[i])
for r in range(len(data)):
case = data[r]
for c in range(6):
ws.write(r+1,c,case[c])
wb.save('爬取结果.xls')
if __name__ == "__main__":
# execute only if run as a script
main()
爬取思路
这段代码可以直接跑起来运行,改正链接和头部以及想爬取的内容就行。
从网页爬取数据的思路如下:
首先从网页获得网页的链接url和其他header信息,然后requests到整个页面的数据,用etree生成树,定位到想要的信息,然后append 到给定的数组中,最后合成到lxls文件中。
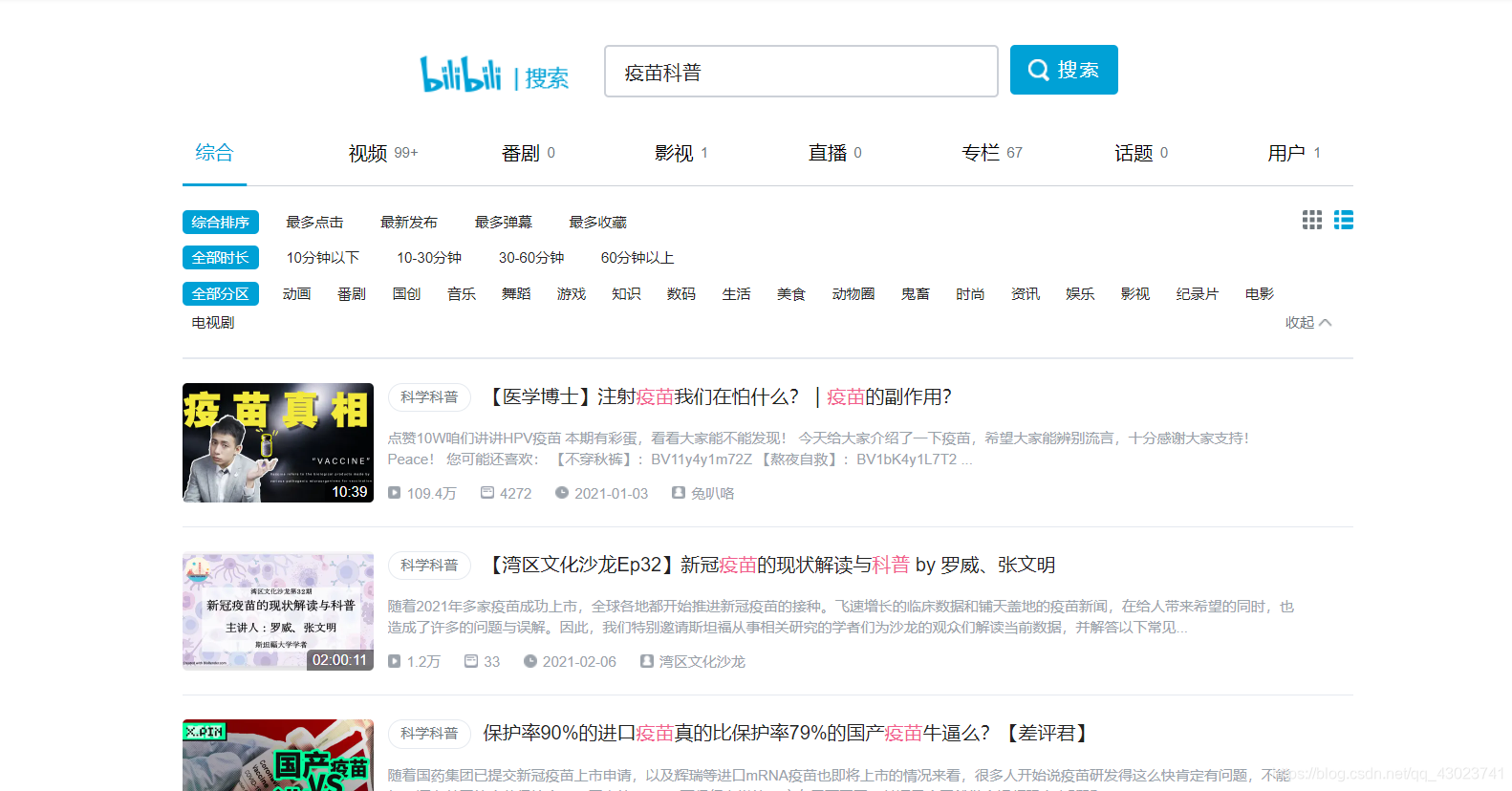
如上图找到相关网站,点击F12按键,检查页面。
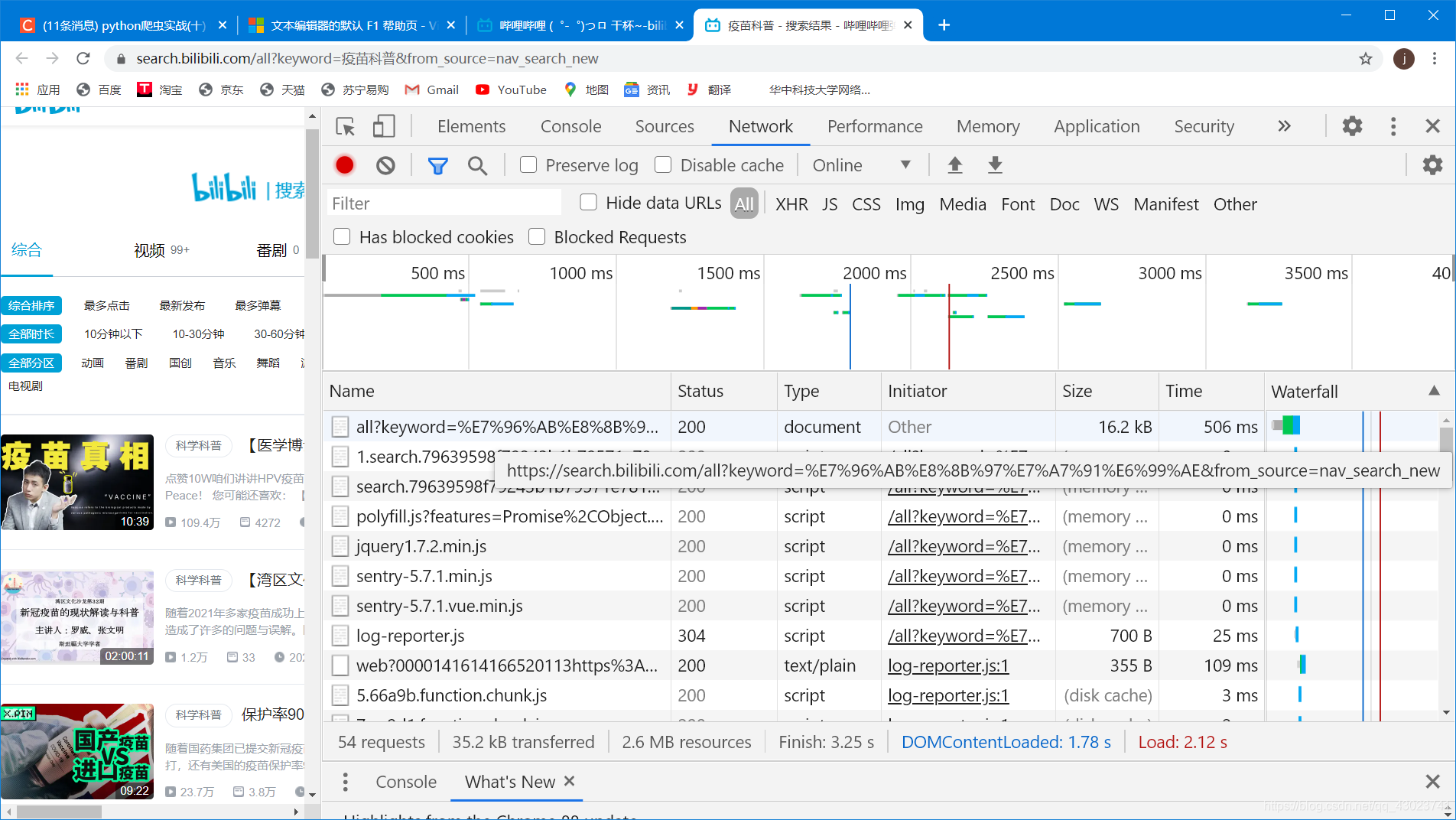
选择Network,从这里查找到我们想要的信息,点击Name列第一行,
这样就能找到我们所需要的url和useragent等信息,如下图标红的信息
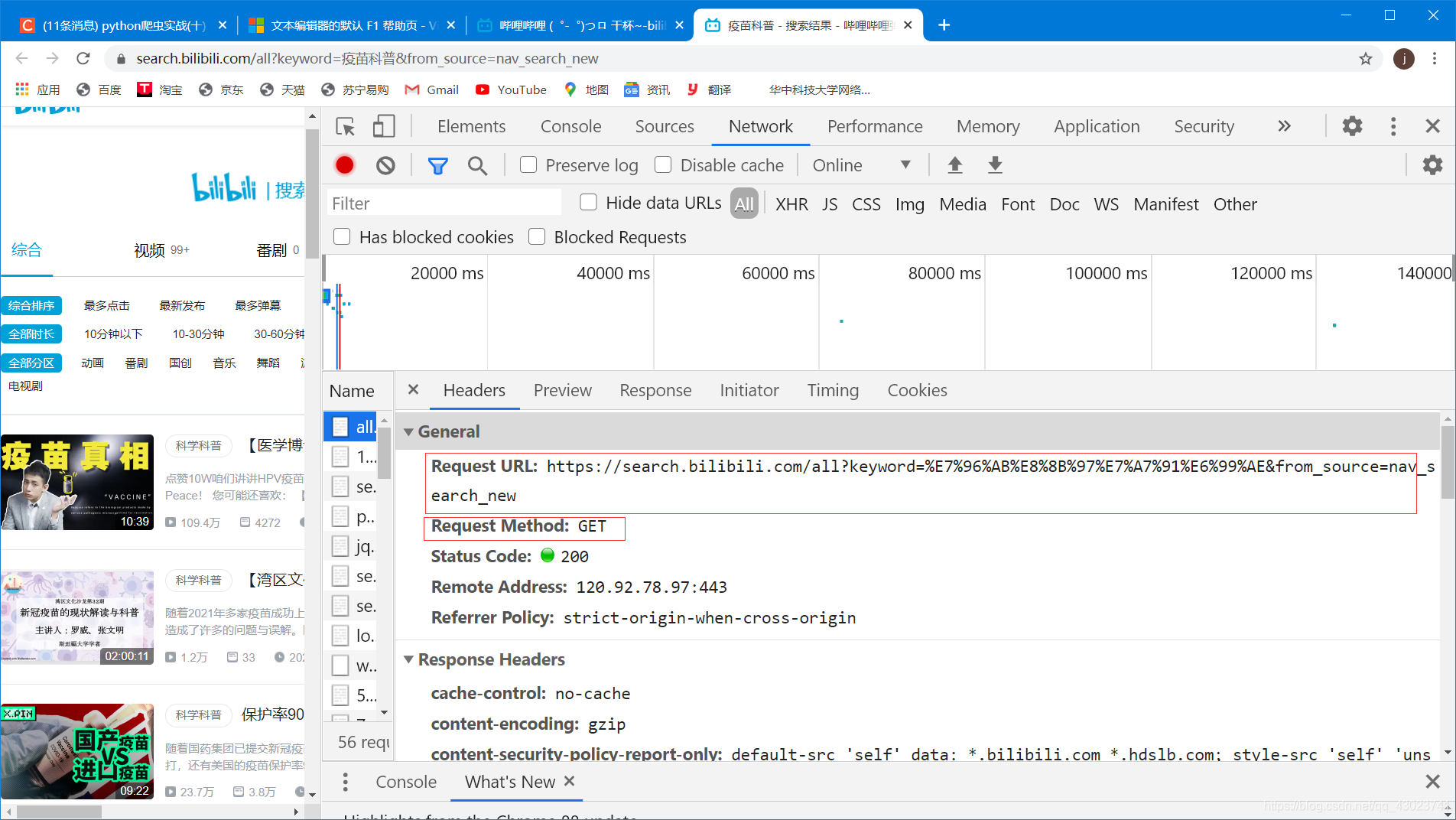
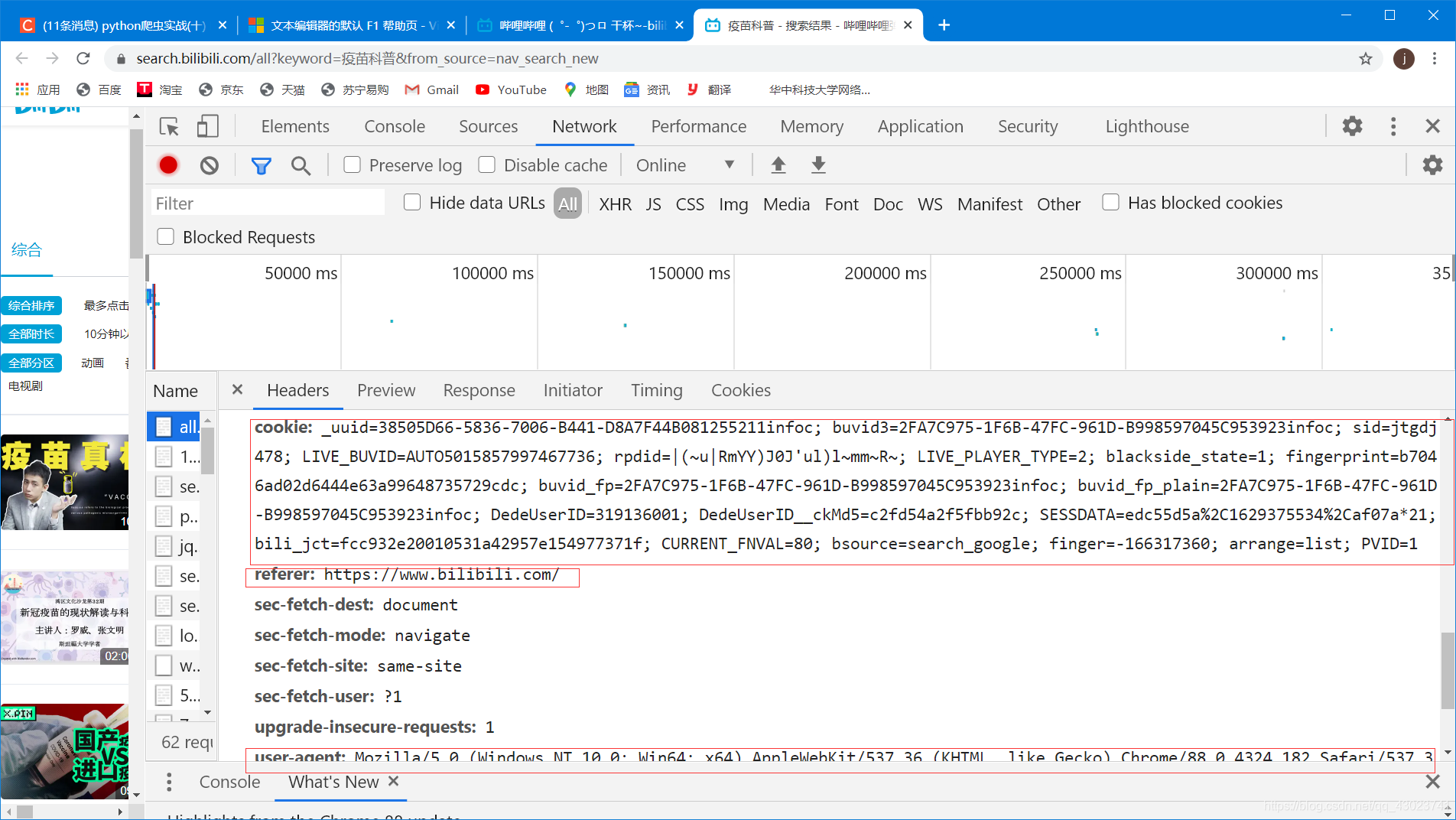
这里要注意requestMethod是get,所以在用requests请求网页信息的时候不要用post。
url肯定是要用网页给出来的url,这里因为我爬取的数据有五十页,而查看不同页的url可以发现他们的区别只是在第一页的url后面加了&page=页码,因此爬取多页时候用for循环就能改变url。
referes和cookie我的建议是直接加到headers里面就行。
i=0
while(i<=50):
i+=1
time.sleep(1)
#获取html页面
if(i==1):
url = 'https://search.bilibili.com/all?keyword=%E7%96%AB%E8%8B%97%E7%A7%91%E6%99%AE&from_source=nav_search&spm_id_from=333.851.b_696e7465726e6174696f6e616c486561646572.9'
else:
url='https://search.bilibili.com/all?keyword=%E7%96%AB%E8%8B%97%E7%A7%91%E6%99%AE&from_source=nav_search&spm_id_from=333.851.b_696e7465726e6174696f6e616c486561646572.9&page='+str(i)
head=[
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
]
headers={
'user-agent':random.choice(head),
'Referer':'https://www.bilibili.com/',
'cookie':"_uuid=38505D66-5836-7006-B441-D8A7F44B081255211infoc; buvid3=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; sid=jtgdj478; LIVE_BUVID=AUTO5015857997467736; rpdid=|(~u|RmYY)J0J'ul)l~mm~R~; LIVE_PLAYER_TYPE=2; blackside_state=1; fingerprint=b7046ad02d6444e63a99648735729cdc; buvid_fp=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; buvid_fp_plain=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; DedeUserID=319136001; DedeUserID__ckMd5=c2fd54a2f5fbb92c; SESSDATA=edc55d5a%2C1629375534%2Caf07a*21; bili_jct=fcc932e20010531a42957e154977371f; CURRENT_FNVAL=80; bsource=search_google; finger=-166317360; arrange=list; PVID=1"
}
接下来就是问题最大的useragent,每个浏览器访问网页的时候是有自己的ip 的,这个ip就是useragent,爬虫的时候短时间重复多次访问数据库容易让网站判定成机器人,从而封禁你的浏览器ip,这样你不仅爬不了数据,浏览器也打不开相关网页。为了避免被封,我找了一堆useragent,列成了一个数组
head=[
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
]
然后在每次访问的时候就用random函数随机挑选一个useranget,伪装成不同浏览器去申请页面信息
headers={
'user-agent':random.choice(head),
'Referer':'https://www.bilibili.com/',
'cookie':"_uuid=38505D66-5836-7006-B441-D8A7F44B081255211infoc; buvid3=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; sid=jtgdj478; LIVE_BUVID=AUTO5015857997467736; rpdid=|(~u|RmYY)J0J'ul)l~mm~R~; LIVE_PLAYER_TYPE=2; blackside_state=1; fingerprint=b7046ad02d6444e63a99648735729cdc; buvid_fp=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; buvid_fp_plain=2FA7C975-1F6B-47FC-961D-B998597045C953923infoc; DedeUserID=319136001; DedeUserID__ckMd5=c2fd54a2f5fbb92c; SESSDATA=edc55d5a%2C1629375534%2Caf07a*21; bili_jct=fcc932e20010531a42957e154977371f; CURRENT_FNVAL=80; bsource=search_google; finger=-166317360; arrange=list; PVID=1"
}
申请网页
上面我们准备好了申请网页所需要的各种信息,然后就用request获得页面数据
res = requests.get(url=url,headers=headers)
res.encoding = 'utf-8'
html = res.text
申请到网页数据以后赋值给res,utf-8编码,再用.text将res变成文本数据赋值给html。
tree = etree.HTML(html)
然后用etree函数将html的文本信息变成树状列表信息,这样就实现了网页数据的下载和格式变换
定位想要的数据
这里我每个页面有二十多个视频,每个视频就是一个li,首先获得所有视频的整个列表
lis = tree.xpath('/html/body/div[3]/div/div[2]/div/div[1]/ul/li')
lis是我们定义的一个数组,通过xpath找到所有的视频信息赋值给lis
括号里面是每个视频的路径,获取方式如下:
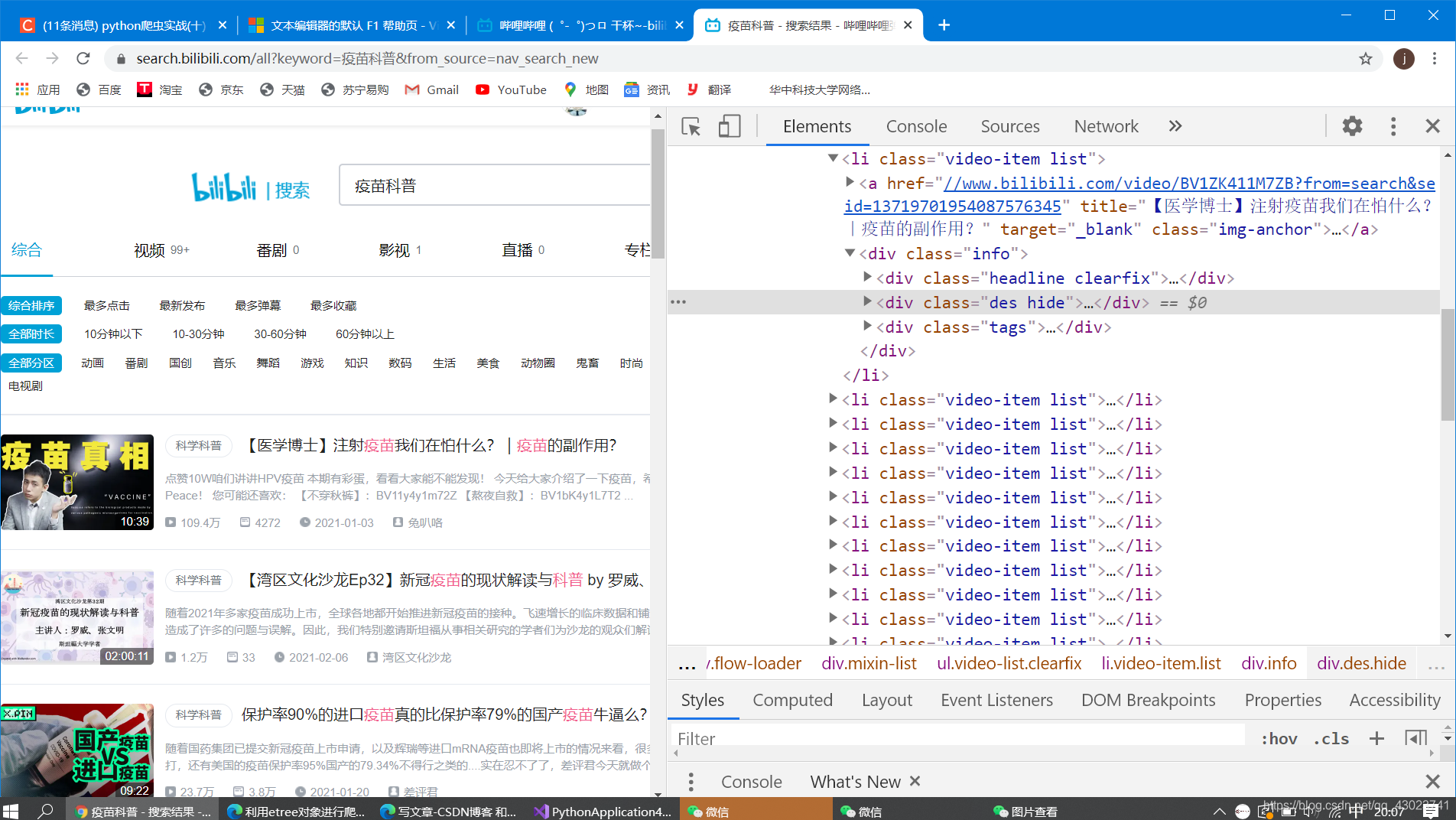
任选一个视频然后右键,点击检查就能在源代码中定位到相应的位置
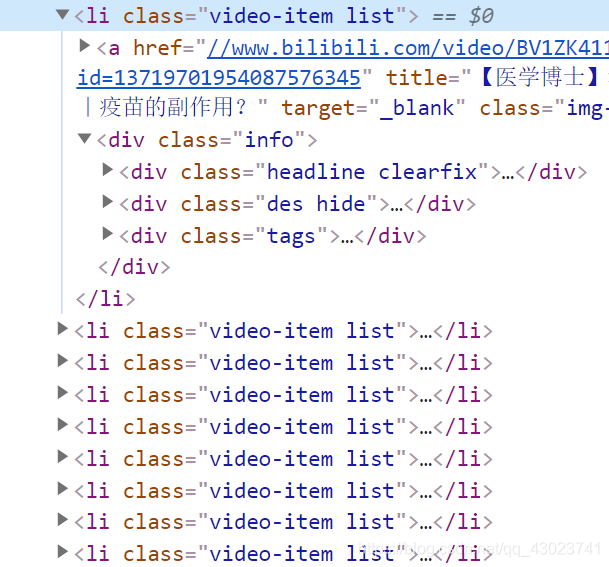
可以看到这里有一列li,每一个li就是一个视频信息,选中其中一个li,右键,copy,选择copy fullxpath,这样就能复制到完整的路径了,填入括号中即可。
得到了所有视频的数据后就开始一个个分析,从里面获得想要的信息
for li in lis:
info = []
#提取视频名
name = li.xpath('./a/@title')[0]
info.append(name)
#提取链接
link = li.xpath('./a/@href')[0]
info.append(link)
#提取播放量
play_num = li.xpath('./div/div[3]/span[1]/text()')[0]
info.append(play_num)
#提取弹幕数
discuss = li.xpath('./div/div[3]/span[2]/text()')[0]
info.append(discuss)
#提取时间
up_time = li.xpath('./div/div[3]/span[3]/text()')[0]
info.append(up_time)
#提取up主
up = li.xpath('./div/div[3]/span[4]/a/text()')[0]
info.append(up)
这里如果获取的是文本信息就在完整的路径后面加/text,其他的像链接或者标题等加相应内容即可。这里路径的获取方式同上,在网页上某个视频的想要的信息如作者处右击检查,然后代码中定位到想获取的信息右键copy,得到相应的路径,前面相同的路径可用li.xpath()来简写,具体见代码。
得到具体信息后用append赋值给临时变量info,再append给全局变量data。
#汇总到data列表中
data.append(info)
数据保存
最后得到的data数组里面包含着我们想要的信息
get_info()
#保存数据
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('sheet1')
#写表头
col_name = ('视频名','视频链接','播放量','弹幕量','上传时间','up主')
for i in range(6):
ws.write(0,i,col_name[i])
for r in range(len(data)):
case = data[r]
for c in range(6):
ws.write(r+1,c,case[c])
wb.save('爬取结果.xls')
这里用xlwt库生成一个excel表,写上表头,把data里面数据写入到表里面
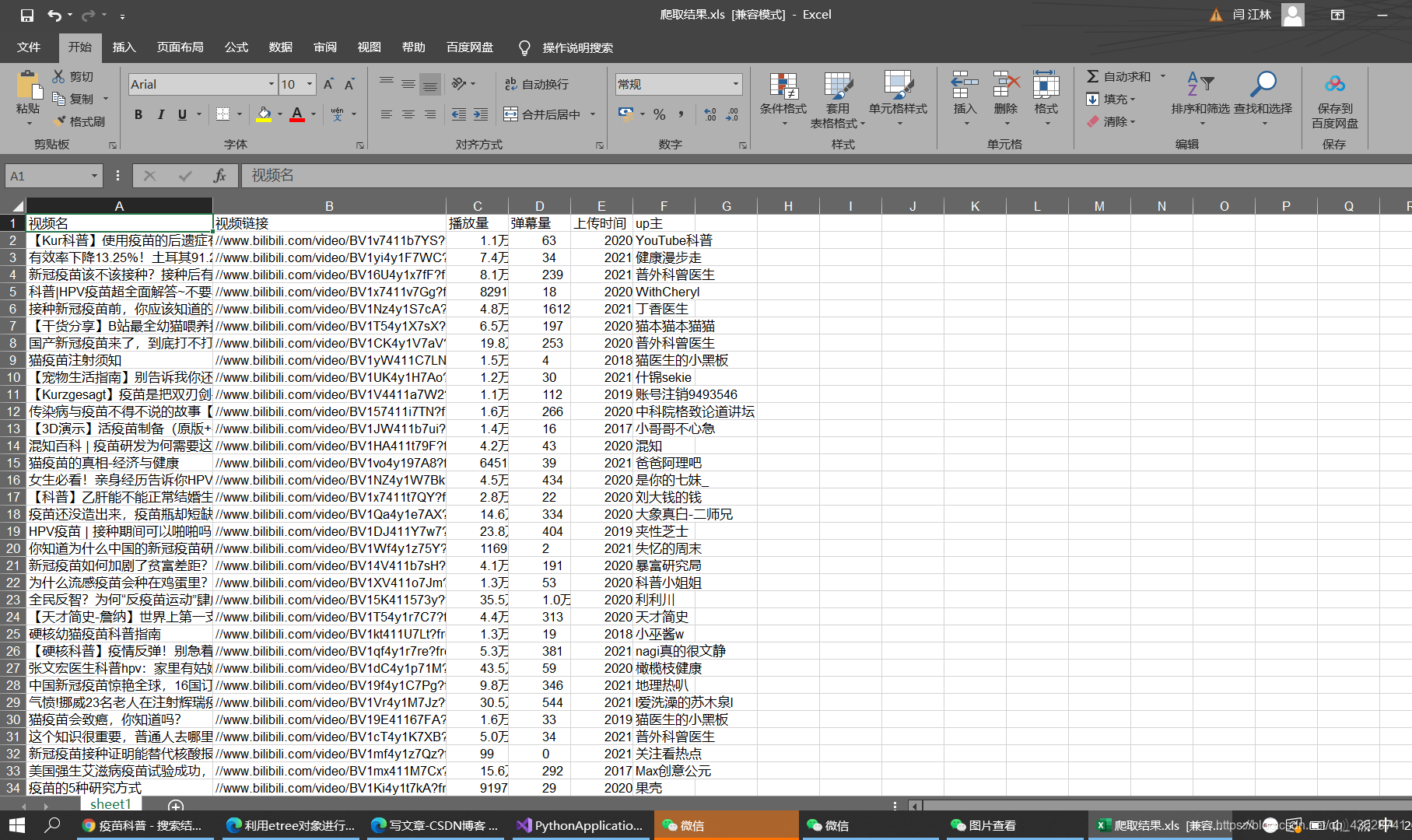
保存生成xls表格,这样爬取就完成了。最后结果如图:
写在最后
爬虫其实是挺简单的一件事,方式有很多很多种,我比较优柔寡断,两天时间里换了十几篇博客一个个试想找最简单的,这样其实很浪费时间,找一个确定能跑出来的案例,在这个基础上直接改就行了。调代码最怕的不是解决问题而是逃避问题,往往约逃避问题就会越多。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









