






引言
搜索提示是搜索框一个比较基础的功能,他赋予了搜索框生命,提高了用户的搜索体验。本文通过仿写 boss 直聘首页职位公司搜索,来实现一个自己搜索提示功能。
需求分析
搜索提示的情况比较多,比如根据拼音全拼、拼音首字母、中文等等,我们看看 boss 直聘 的搜索提示是怎么做的。
中文前缀
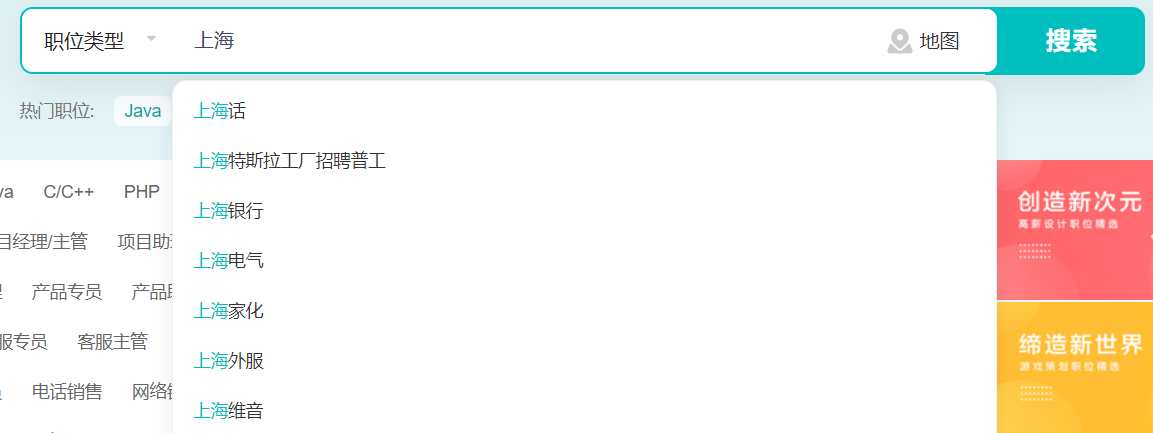
中文中缀
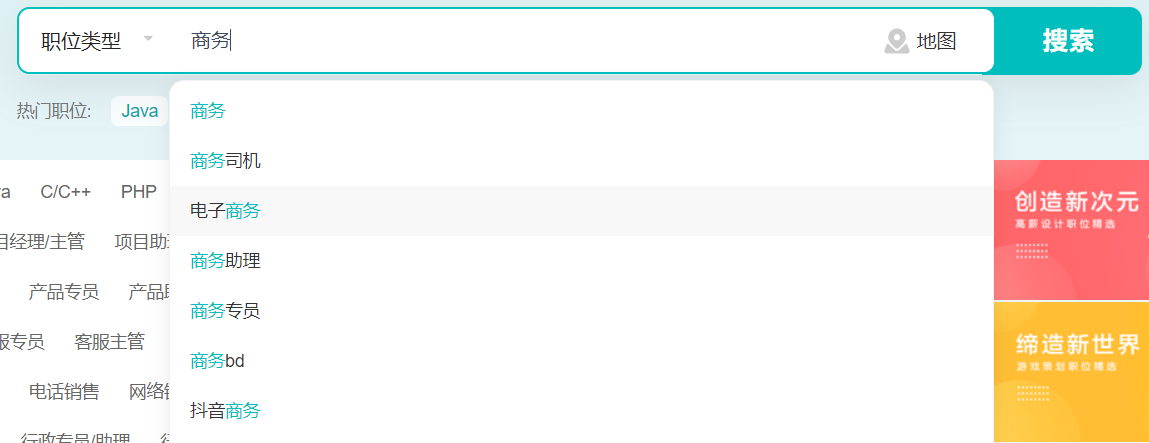
拼音全拼前缀
需要注意的是这里不管是 shanghai 还是 shangha 都能提示出 上海。
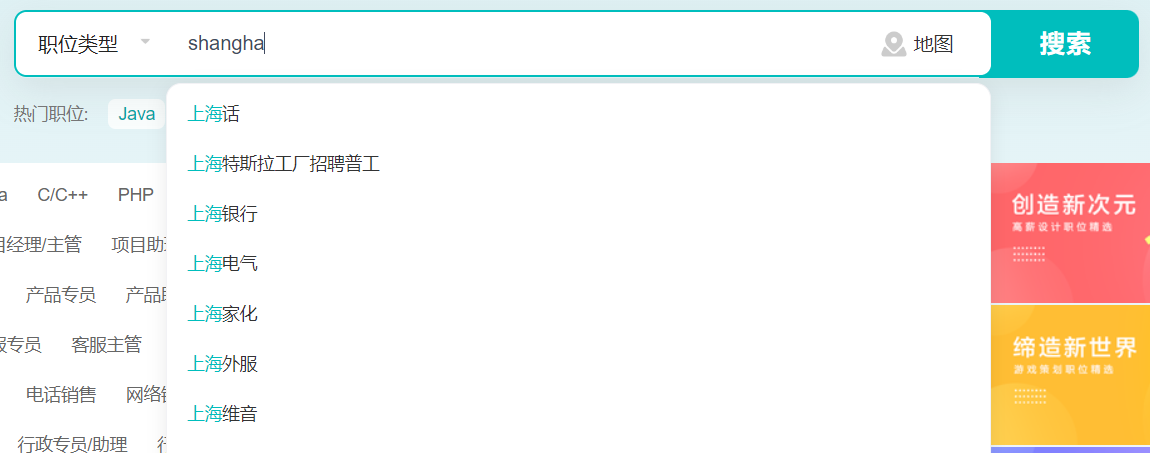
拼音全拼中缀
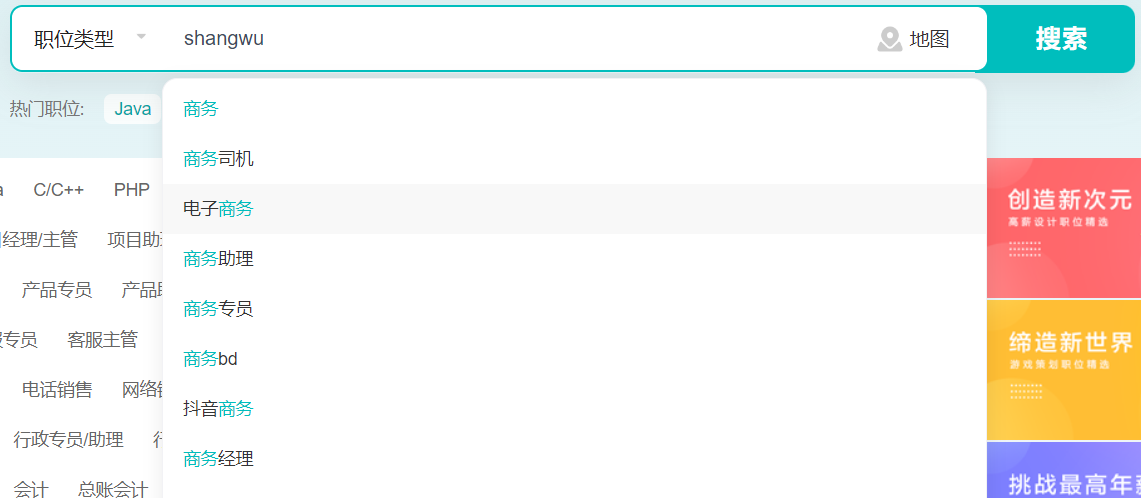
拼音首字母前缀
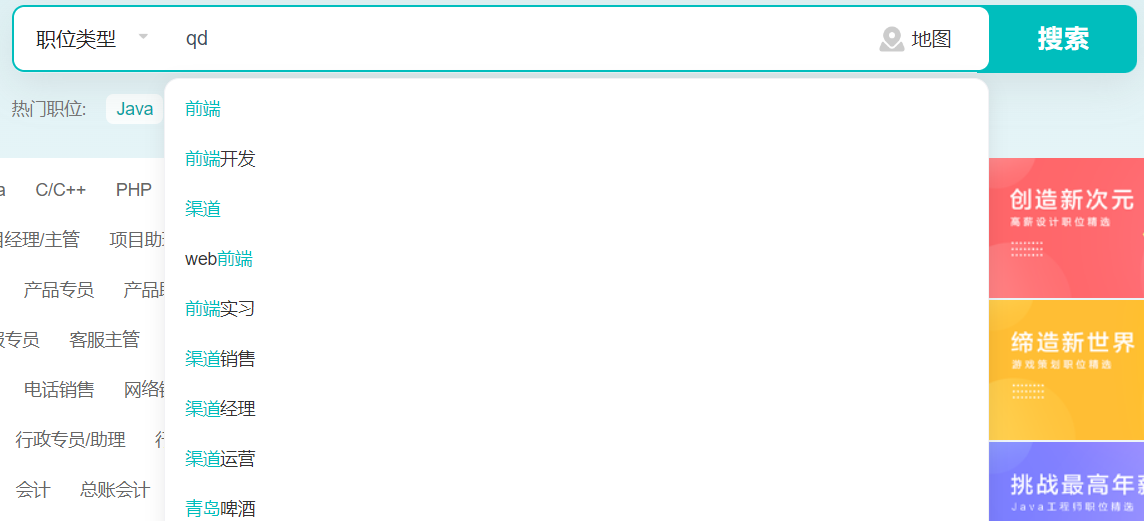
拼音首字母中缀
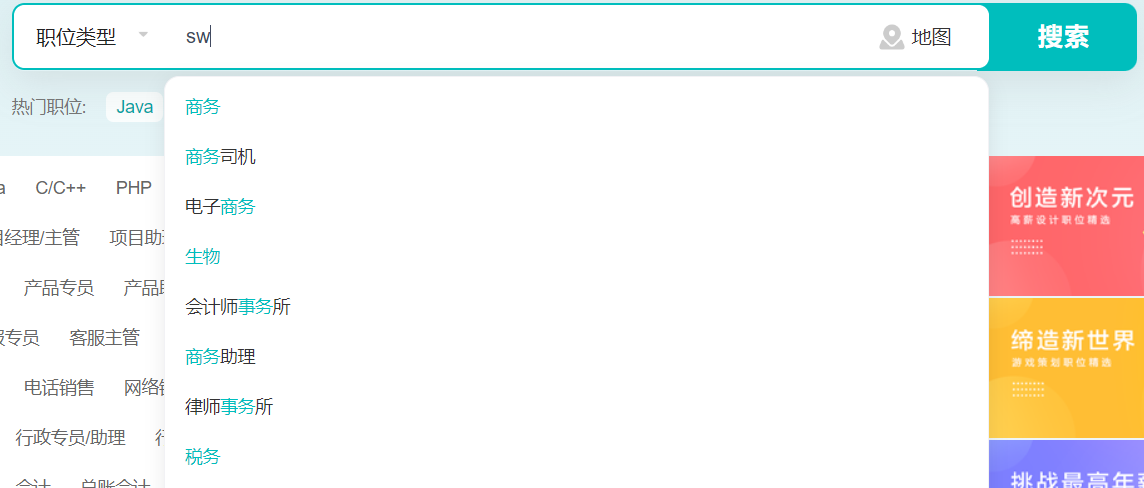
拼音全拼 + 中文


实现分析
本次实现中文搜索提示功能分 4 步走:
- 同步数据到 ElasticSearch:通过自己封装 CDC 框架,同步 MySQL 数据库数据到 ElasticSearch
- ElasticSearch 索引设计:设计支持中文搜索的 mapping
- ElasticSearch DSL 编写
- 代码实现
同步数据到 Elastic Search
我们想要实现搜索,首先需要将 MySQL 中的存量数据和增量数据同步到ES 中,目前常用的做法是通过 CDC (Change Data Capture)。
CDC 简介
什么是 CDC
CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
CDC 使用场景
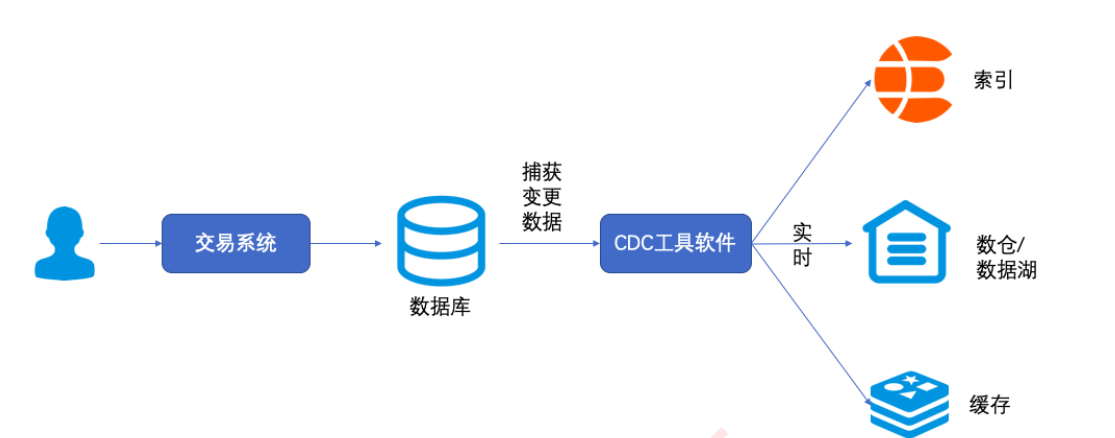
CDC 的种类
实现CDC即捕获数据库的变更数据有两种机制
| 基于查询实现CDC | 基于日志实现CDC | |
|---|---|---|
| 典型产品 | Sqoop、DataX等 | Canal、Debezium等 |
| 执⾏模式 | 批处理 | 流处理 |
| 捕获所有数据变化 | NO | YES |
| 低延迟 | NO | YES |
| 不增加数据库负载 | NO | YES |
| 不侵⼊业务(不需要lastUpdate字段) | NO | YES |
| 捕获删除事件 | NO | YES |
| 捕获旧记录的状态 | NO | YES |
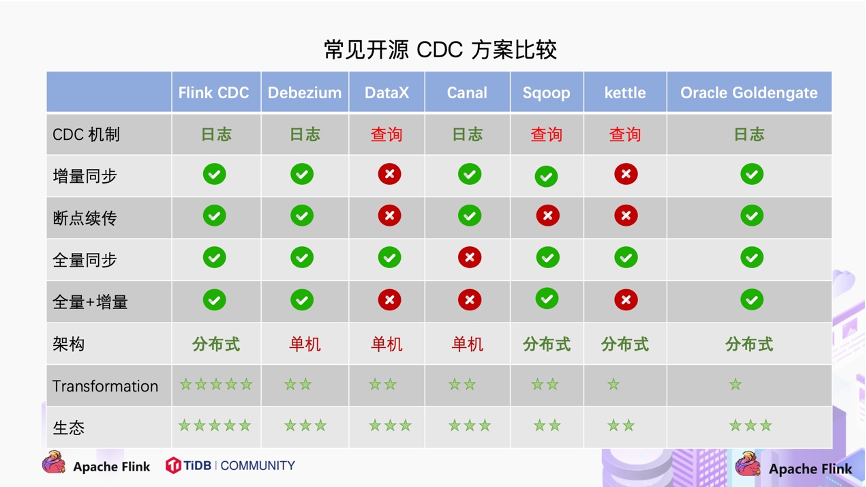
对比常见的开源 CDC 方案
封装 CDC 框架
关于为什么我要自己封装 CDC 框架
提到同步 MySQL 数据到 ES,肯定最先想到的就是 Canal,我也是使用了一段时间,他给我的感觉就是功能很全很强大,但是比较复杂也比较难用,他的主要配置文件有两个非常的长,Java 客户端也不是很易用,想要完全搞懂需要下一番功夫,而且现在也已经停止维护了。
我其实对 CDC 的要求很简单不需要特别复杂的功能,只要数据库数据发生了 增删改 你通知我就行了,具体要同步到 ES、Redis 、消息队列 由我决定。
偶然的机会我接触到了 Flink CDC ,项目地址:https://github.com/ververica/flink-cdc-connectors。官方提供了一个演示的例子,只通过一个方法竟然就可以完成 CDC,我表示很震惊,例子如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // set captured database
.tableList("yourDatabaseName.yourTableName") // set captured table
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}
}
通过后续的了解,我知道了 Flink CDC 有一整套的生态,性能很高,功能也非常丰富,在大数据、数据仓储等领域非常常见。
但是为了一个简单的 CDC 去学一整套 Flink CDC 生态,属实有点力不从心,但好在如果只是简单的监听 MySQL 数据的 增删改 事件还是比较简单的,通过上面的例子就可以做到,于是我想基于这个例子封装一个简单易用的 CDC 框架 – easy-flink-cdc。
easy-flink-cdc
就不讲怎么封装了吧,直接看看怎么用,项目地址:https://github.com/Maskvvv/easy-flink-cdc
概念说明
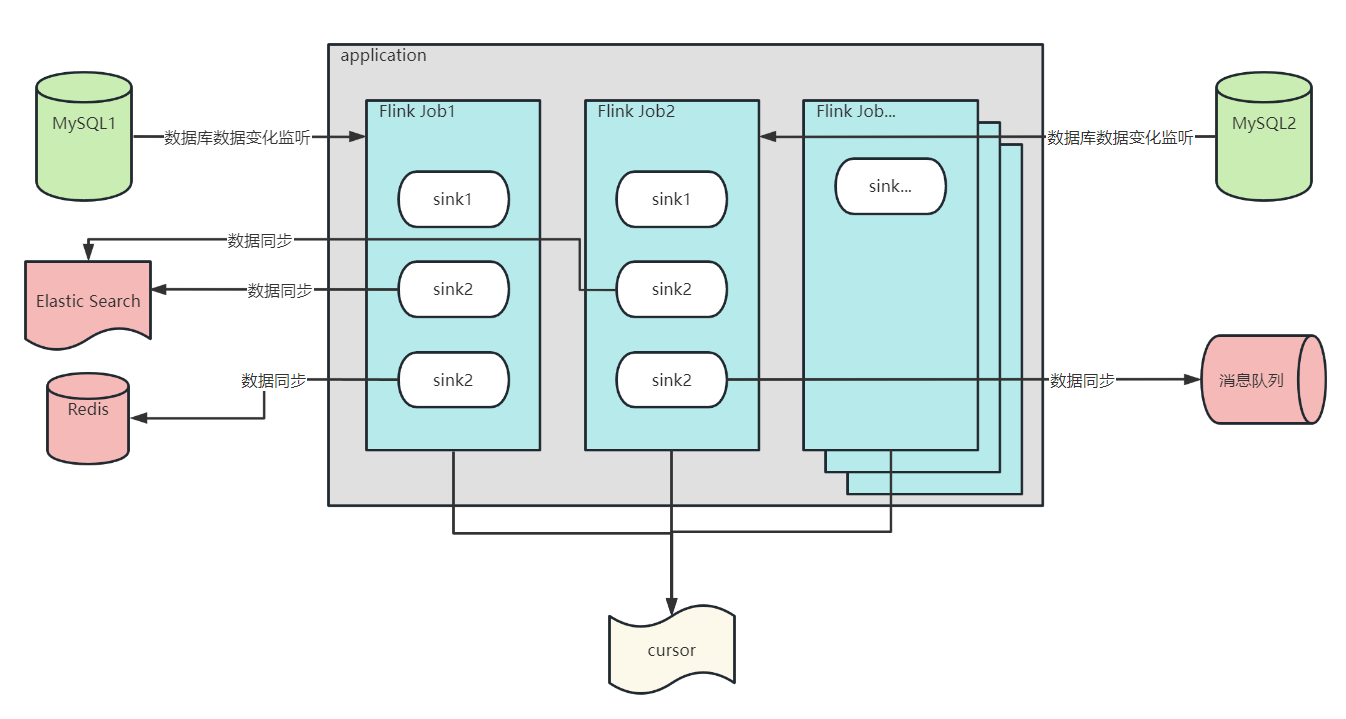
application
对应一个 Spring 项目
Flink Job
通过配置文件配置要监听的数据源,一个数据源对应一个 Flink Job,Flink Job 可以监听多个数据库和数据库表的数据变化
sink
Flink Job 收到数据变化的结果会调用其下面的 sink,在 sink 中你可以对 增删改 事件进行自由的业务代码处理,到底是同步到 ES 中,还是 Redis 中,还是 消息队列中等等,你可以自由决定。
cursor
每个 Flink Job 都有一个自己的 cursor,他记录着每个 Flink Job 当前同步 binlog 的位置,用来在 CDC 项目重新启动是接着上一次同步的位置,继续同步数据。
# cursor 数据结构
- application2
- 端口号
- meta.dat
- flink job cursor
- flink job cursor
- application2
- 端口号
- meta.dat
- flink job cursor
- flink job cursor
使用
通过下面这 4 步你就可以轻松实现对 MySQL 的 CDC。
引入依赖
<dependency>
<groupId>com.easy-flink-cdc</groupId>
<artifactId>easy-flink-cdc-boot-starter</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
编写配置文件
在 resources 路径下新建一个 easy-flink.conf 文件,语法为 typesafe.config。
ourea = {
name = "ourea"
hostname = "myserver.com"
port = "3308"
databaseList = "ourea"
tableList = "ourea.company,ourea.occupation"
username = "root"
password = "1234567788"
startupMode = "INITIAL"
}
athena = {
name = "athena"
hostname = "myserver.com"
port = "3308"
databaseList = "ourea"
tableList = "ourea.sort"
username = "root"
password = "1234567788"
startupMode = "INITIAL"
}
- name:于根名保持一致,一个根名对应着一个
Flink Job,不允许重名。 - hostname:需要监听的数据库域名
- port:需要监听的数据库端口号
- databaseList:需要监听的库名,多个用
,分开 - tableList:需要监听的表名,多个用
,分开 - username:数据库账号
- password:数据库密码
- startupMode:启动方式,如果有 cursor 存在,以 cursor 中优先。
- INITIAL: 初始化快照,即全量导入后增量导入(检测更新数据写入)
- LATEST: 只进行增量导入(不读取历史变化)
- TIMESTAMP: 指定时间戳进行数据导入(大于等于指定时间错读取数据)
启用 easy-flink-cdc
application.properties
easy-flink.enable=true
easy-flink.meta-model=file
启动类
@EasyFlinkScan("com.esflink.demo.sink")
@SpringBootApplication
public class EasyFlinkCdcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(EasyFlinkCdcDemoApplication.class, args);
}
}
@EasyFlinkScan 注解指定 sink 类的存放路径,可以指定多个。
编写 sink
@FlinkSink(value = "ourea", database = "ourea", table = "ourea.company")
public class DemoSink implements FlinkJobSink {
@Override
public void invoke(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void insert(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void update(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void delete(DataChangeInfo value, Context context) throws Exception {
}
@Override
public void handleError(DataChangeInfo value, Context context, Throwable throwable) {
}
}
FlinkJobSink 接口
这里你需要实现 FlinkJobSink 接口并按照你的需求重写对应事件的方法。
insert()、update()、delete()方法:分别对应着 增、改、删 事件invoke()方法:增、改、删 事件都会调用改方法handleError(): 用来处理方法调用时出现的异常
@FlinkSink
当然你还要通过 @FlinkSink 注解标识这是一个 sink,该注解有以下属性
value:用来指定该 sink 是属于哪个 Flink Job,必须database:用来指定接收 Flink Job 中的哪些 数据库 的数据变化,默认为 Flink Job 中指定的,选填database:用来指定接收 Flink Job 的哪些 表 的数据变化,不填则为 Flink Job 中指定的,选填
存在问题
总体上来讲封装一个简单易用的 CDC 框架这个目的已经基本达到了,但是由于自己是第一次封装框架,该框架还存在着许多问题,比如:
- 框架不够模块化
- 框架类分包混乱(主要我不知道咋分)
- 框架可拓展性不高,比如自定义拓展序列化方式、自定义配置文件加载方式等
- cursor 的记录不支持现在现在主流分布式的特性,现在是通过先写内存,再定时刷盘的方式记录 cursor 的,后续规划支持通过 zookeeper 记录 cursor
- 配置文件的加载不支持分布式特性,现在只能加载本地配置文件,后续规划支持通过 nacos-config
- 项目启动时会如果有指定 cursor,会短暂阻塞数据库,所以建议指定从库进行监听
- 自已对 Flink CDC 的了解还不够深刻,可能有些情况还没考虑到
- 不保证 crash safe,需要做好代码的幂等性
- 同步性能方面,自己没有做过海量数据同步的测试,我是大概8000条数据同步到 ES 大约几分钟吧
- 当前框架还没有上传到 Maven 的中心仓库(等我在完善完善,再说吧)
自己写框架才知道,一个(好的)框架是多么难写,对于现阶段的我来说也算尽力了,我这个 CDC 框架就当抛砖引玉吧
ElasticSearch 索引设计
数据来源的问题解决了,现在就是设计一个可以支持中文搜索提示的 ES 索引了。
我们要想实现功能齐全的搜索提示,就需要自定义分词器了。
自定义分词器的设计与测试
中文前缀分词器
索引
GET /_analyze
{
"tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"text": [
"北京字节跳动"
]
}
搜索
GET /_analyze
{
"tokenizer": "keyword",
"text": [
"北京字节跳动"
]
}
结果
# 索引
{
"tokens" : [
{
"token" : "北",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "北京",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "北京字",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "北京字节",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 3
},
{
"token" : "北京字节跳",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "北京字节跳动",
"start_offset" : 0,
"end_offset" : 6,
"type" : "word",
"position" : 5
}
]
}
# 搜索
{
"tokens" : [
{
"token" : "北京字节跳动",
"start_offset" : 0,
"end_offset" : 12,
"type" : "word",
"position" : 0
}
]
}
中文中缀分词器
索引
GET /_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": [
"北京字节跳动"
]
}
搜索
同索引
结果
{
"tokens" : [
{
"token" : "北",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "京",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "字",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "节",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "跳",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "动",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
}
]
}
拼音全拼前缀分词器
索引
GET /_analyze
{
"tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"filter": [
{
"type": "pinyin",
"keep_original": false,
"keep_first_letter": false,
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_none_chinese_together": true,
"keep_none_chinese_in_joined_full_pinyin": true,
"none_chinese_pinyin_tokeniz": false,
"keep_none_chinese": false,
"ignore_pinyin_offset": false
}
],
"text": [
"北京字节跳动"
]
}
搜索
GET /_analyze
{
"tokenizer": "keyword",
"filter": [
{
"type": "pinyin",
"keep_original": false,
"keep_first_letter": false,
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_none_chinese_together": true,
"keep_none_chinese_in_joined_full_pinyin": true,
"none_chinese_pinyin_tokeniz": false,
"keep_none_chinese": false,
"ignore_pinyin_offset": false
}
],
"text": [
"北京"
]
}
结果
# 索引
{
"tokens" : [
{
"token" : "bei",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "beijing",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "beijingzi",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "beijingzijie",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 3
},
{
"token" : "beijingzijietiao",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "beijingzijietiaodong",
"start_offset" : 0,
"end_offset" : 6,
"type" : "word",
"position" : 5
}
]
}
# 搜索
{
"tokens" : [
{
"token" : "beijing",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
}
]
}
拼音全拼中缀分词器
索引
GET /_analyze
{
"tokenizer": {
"type": "pinyin",
"keep_original": false,
"keep_first_letter": false,
"keep_full_pinyin": true,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
},
"text": [
"北京字节跳动"
]
}
搜索
GET /_analyze
{
"tokenizer": "keyword",
"filter": [
{
"type": "pinyin",
"keep_original": false,
"keep_first_letter": false,
"keep_full_pinyin": true,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
}
],
"text": [
"北京"
]
}
结果
# 索引
{
"tokens" : [
{
"token" : "bei",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "jing",
"start_offset" : 1,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "zi",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "jie",
"start_offset" : 3,
"end_offset" : 4,
"type" : "word",
"position" : 3
},
{
"token" : "tiao",
"start_offset" : 4,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "dong",
"start_offset" : 5,
"end_offset" : 6,
"type" : "word",
"position" : 5
}
]
}
# 搜索
{
"tokens" : [
{
"token" : "bei",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "jing",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
}
]
}
拼音首字母前缀分词器
索引
GET /_analyze
{
"tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"filter": [
{
"type": "pinyin",
"keep_original": false,
"keep_full_pinyin": false,
"limit_first_letter_length": 50,
"none_chinese_pinyin_tokeniz": false,
"keep_none_chinese": false,
"ignore_pinyin_offset": false
}
],
"text": [
"北京字节跳动"
]
}
搜索
GET /_analyze
{
"tokenizer": "keyword",
"filter": [
{
"type": "pinyin",
"keep_original": false,
"keep_full_pinyin": false,
"limit_first_letter_length": 50,
"none_chinese_pinyin_tokeniz": false,
"keep_none_chinese": false,
"ignore_pinyin_offset": false
}
],
"text": [
"北京"
]
}
结果
# 索引
{
"tokens" : [
{
"token" : "b",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "bj",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "bjz",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "bjzj",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 3
},
{
"token" : "bjzjt",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "bjzjtd",
"start_offset" : 0,
"end_offset" : 6,
"type" : "word",
"position" : 5
}
]
}
# 搜索
{
"tokens" : [
{
"token" : "bj",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
}
]
}
拼音首字母中缀分词器
索引
GET /_analyze
{
"tokenizer": {
"type": "pinyin",
"keep_original": false,
"keep_separate_first_letter": true,
"keep_first_letter": false,
"keep_full_pinyin": false,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
},
"text": [
"北京字节跳动"
]
}
搜索
GET /_analyze
{
"tokenizer": "keyword",
"filter": [
{
"type": "pinyin",
"keep_original": false,
"keep_separate_first_letter": true,
"keep_first_letter": false,
"keep_full_pinyin": false,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
}
],
"text": [
"北京"
]
}
结果
# 索引
{
"tokens" : [
{
"token" : "b",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "j",
"start_offset" : 1,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "z",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "j",
"start_offset" : 3,
"end_offset" : 4,
"type" : "word",
"position" : 3
},
{
"token" : "t",
"start_offset" : 4,
"end_offset" : 5,
"type" : "word",
"position" : 4
},
{
"token" : "d",
"start_offset" : 5,
"end_offset" : 6,
"type" : "word",
"position" : 5
}
]
}
# 搜索
{
"tokens" : [
{
"token" : "b",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "j",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
}
]
}
索引构建
PUT /ourea-home-suggestion-v15
{
"settings": {
"analysis": {
"analyzer": {
"lowercase_standard": {
"tokenizer": "standard",
"filter": "lowercase"
},
"prefix_index_analyzer": {
"tokenizer": "edge_ngram_tokenizer"
},
"full_pinyin_index_analyzer": {
"tokenizer": "full_pinyin_tokenizer"
},
"full_pinyin_prefix_index_analyzer": {
"tokenizer": "edge_ngram_tokenizer",
"filter": [
"full_pinyin_prefix_filter"
]
},
"first_letter_prefix_index_analyzer": {
"tokenizer": "edge_ngram_tokenizer",
"filter": [
"first_letter_prefix_filter"
]
},
"first_letter_index_analyzer": {
"tokenizer": "first_letter_tokenizer"
},
"full_pinyin_search_analyzer": {
"tokenizer": "keyword",
"filter": [
"full_pinyin_filter"
]
},
"full_pinyin_prefix_search_analyzer": {
"tokenizer": "keyword",
"filter": [
"full_pinyin_prefix_filter"
]
},
"first_letter_prefix_search_analyzer": {
"tokenizer": "keyword",
"filter": [
"first_letter_prefix_filter"
]
},
"first_letter_search_analyzer": {
"tokenizer": "keyword",
"filter": [
"first_letter_filter"
]
}
},
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"full_pinyin_tokenizer": {
"type": "pinyin",
"keep_original": false,
"keep_first_letter": false,
"keep_full_pinyin": true,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
},
"first_letter_tokenizer": {
"type": "pinyin",
"keep_original": false,
"keep_separate_first_letter": true,
"keep_first_letter": false,
"keep_full_pinyin": false,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
}
},
"filter": {
"full_pinyin_filter": {
"type": "pinyin",
"keep_original": false,
"keep_first_letter": false,
"keep_full_pinyin": true,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
},
"full_pinyin_prefix_filter": {
"type": "pinyin",
"keep_original": false,
"keep_first_letter": false,
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_none_chinese_together": true,
"keep_none_chinese_in_joined_full_pinyin": true,
"none_chinese_pinyin_tokeniz": false,
"keep_none_chinese": false,
"ignore_pinyin_offset": false
},
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"first_letter_filter": {
"type": "pinyin",
"keep_original": false,
"keep_separate_first_letter": true,
"keep_first_letter": false,
"keep_full_pinyin": false,
"none_chinese_pinyin_tokeniz": false,
"ignore_pinyin_offset": false
},
"first_letter_prefix_filter": {
"type": "pinyin",
"keep_original": false,
"keep_full_pinyin": false,
"limit_first_letter_length": 50,
"none_chinese_pinyin_tokeniz": false,
"keep_none_chinese": false,
"ignore_pinyin_offset": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "keyword",
"fields": {
"standard": {
"type": "text",
"analyzer": "lowercase_standard"
},
"prefix": {
"type": "text",
"analyzer": "prefix_index_analyzer"
},
"full_pinyin": {
"type": "text",
"analyzer": "full_pinyin_index_analyzer",
"search_analyzer": "full_pinyin_search_analyzer",
"fields": {
"prefix": {
"type": "text",
"analyzer": "full_pinyin_prefix_index_analyzer",
"search_analyzer": "full_pinyin_prefix_search_analyzer"
}
}
},
"first_letter": {
"type": "text",
"analyzer": "first_letter_index_analyzer",
"search_analyzer": "first_letter_search_analyzer",
"fields": {
"prefix": {
"type": "text",
"analyzer": "first_letter_prefix_index_analyzer",
"search_analyzer": "first_letter_prefix_search_analyzer"
}
}
}
}
},
"status": {
"type": "short"
},
"type": {
"type": "short"
},
"top": {
"type": "short"
},
"onlined": {
"type": "short"
},
"sequence": {
"type": "double"
}
}
}
}
中文搜索提示主要是对名称的搜索提示,所以这里给 name 属性增加了许多子字段用来支撑多种情况的搜索。
ElasticSearch DSL 编写
索引建好了 搜索的 DSL 编写也是十分重要的。
这里需要注意的是,不管是 拼音全拼前缀分词器 还是 拼音全拼分词器,都没有独自办法实现 shangh => 上海的前缀搜索提示的同时还高亮显示,所以这里需要将这俩个分词器结合使用。
GET /ourea-home-suggestion/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"onlined": {
"value": 1,
"boost": 1
}
}
}
],
"should": [
{
"term": {
"name.prefix": {
"value": "上海",
"boost": 10
}
}
},
{
"match_phrase": {
"name.standard": {
"query": "上海",
"slop": 0,
"zero_terms_query": "NONE",
"boost": 5
}
}
},
{
"bool": {
"filter": [
{
"match_phrase_prefix": {
"name.full_pinyin.prefix": {
"query": "上海",
"analyzer": "full_pinyin_prefix_search_analyzer",
"slop": 0,
"max_expansions": 100,
"zero_terms_query": "NONE",
"boost": 1
}
}
}
],
"should": [
{
"match_phrase_prefix": {
"name.full_pinyin": {
"query": "上海",
"analyzer": "full_pinyin_search_analyzer",
"slop": 0,
"max_expansions": 50,
"zero_terms_query": "NONE",
"boost": 1
}
}
}
],
"adjust_pure_negative": true,
"minimum_should_match": "1",
"boost": 3
}
},
{
"match_phrase_prefix": {
"name.full_pinyin": {
"query": "上海",
"analyzer": "full_pinyin_search_analyzer",
"slop": 0,
"max_expansions": 50,
"zero_terms_query": "NONE",
"boost": 1.5
}
}
},
{
"match": {
"name.first_letter.prefix": {
"query": "上海",
"operator": "OR",
"analyzer": "first_letter_prefix_search_analyzer",
"prefix_length": 0,
"max_expansions": 100,
"fuzzy_transpositions": true,
"lenient": false,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"boost": 1
}
}
},
{
"match_phrase": {
"name.first_letter": {
"query": "上海",
"analyzer": "first_letter_search_analyzer",
"slop": 0,
"zero_terms_query": "NONE",
"boost": 0.8
}
}
}
],
"adjust_pure_negative": true,
"minimum_should_match": "1",
"boost": 1
}
},
"highlight": {
"type": "plain",
"fields": {
"name.prefix": {},
"name.standard": {},
"name.full_pinyin": {},
"name.first_letter.prefix": {},
"name.first_letter": {}
}
}
}
这里解释一下为什么没有使用 Completion suggester 方式
Completion suggester 是 ES 专门为前缀匹配设计的数据类型,他会将 completion 类型的数据加载到内存中,性能非常高,但是他也存在如下几个问题,无法满足我们的需求:
- 只支持前缀匹配,没办法实现中缀匹配
- 没办法在搜索时指定分词器
- 不能过滤结果
- 不支持高亮
代码实现
有了前面的铺垫代码实现显得格外的简单。
数据同步到 ES
这里我们需要同步职位表和公司表的数据到 ES,写两个 sink 就可以了。
CompanySink
@FlinkSink(value = "ourea", database = "ourea", table = "ourea.company")
public class CompanySink implements FlinkJobSink {
@Autowired(required = false)
private OureaHomeSuggestionDocMapper homeSuggestionDocMapper;
@Override
public void update(DataChangeInfo value, Context context) throws Exception {
String afterData = value.getAfterData();
OureaHomeSuggestionDoc homeSuggestionDoc = JSON.parseObject(afterData, OureaHomeSuggestionDoc.class);
homeSuggestionDoc.setType(1);
homeSuggestionDoc.setOnlined(1);
homeSuggestionDocMapper.insert(homeSuggestionDoc);
}
@Override
public void insert(DataChangeInfo value, Context context) throws Exception {
String afterData = value.getAfterData();
OureaHomeSuggestionDoc homeSuggestionDoc = JSON.parseObject(afterData, OureaHomeSuggestionDoc.class);
homeSuggestionDoc.setType(1);
homeSuggestionDoc.setOnlined(1);
homeSuggestionDocMapper.insert(homeSuggestionDoc);
}
@Override
public void delete(DataChangeInfo value, Context context) throws Exception {
OureaHomeSuggestionDoc homeSuggestionDoc = JSON.parseObject(value.getBeforeData(), OureaHomeSuggestionDoc.class);
homeSuggestionDocMapper.deleteById(homeSuggestionDoc.getId());
}
}
OccupationSink
@FlinkSink(value = "ourea", database = "ourea", table = "ourea.occupation")
public class OccupationSink implements FlinkJobSink {
@Autowired(required = false)
private OureaHomeSuggestionDocMapper homeSuggestionDocMapper;
@Override
public void update(DataChangeInfo value, Context context) throws Exception {
String afterData = value.getAfterData();
OureaHomeSuggestionDoc homeSuggestionDoc = JSON.parseObject(afterData, OureaHomeSuggestionDoc.class);
homeSuggestionDoc.setType(2);
homeSuggestionDocMapper.insert(homeSuggestionDoc);
}
@Override
public void insert(DataChangeInfo value, Context context) throws Exception {
String afterData = value.getAfterData();
OureaHomeSuggestionDoc homeSuggestionDoc = JSON.parseObject(afterData, OureaHomeSuggestionDoc.class);
homeSuggestionDoc.setType(2);
homeSuggestionDocMapper.insert(homeSuggestionDoc);
}
@Override
public void delete(DataChangeInfo value, Context context) throws Exception {
OureaHomeSuggestionDoc homeSuggestionDoc = JSON.parseObject(value.getBeforeData(), OureaHomeSuggestionDoc.class);
homeSuggestionDocMapper.deleteById(homeSuggestionDoc.getId());
}
}
这里我们为了简便用了一个开源的 ES ORM 框架 Easy-Es ,类似于 MyBatis-Plus,简单的增删改用它就不用使用
RestHighLevelClient写一大堆代码了。详细请看官网官网:https://www.easy-es.cn/
搜索 - 服务端
这里由于搜索比较复杂,还是使用了原生的RestHighLevelClient 编写,没有用 Easy-Es。
Controller
这里为了方便业务逻辑就直接写在 Controller 里了
@RestController
@RequestMapping("ourea_home_v2")
public class OureaHomeSuggestiongV2Controller {
@Autowired(required = false)
private CompanyDocumentMapper companyDocumentMapper;
@GetMapping("suggest")
private List<OureaHomeSuggestionModel> getCompanies(String key) throws IOException {
SearchRequest searchRequest = new SearchRequest("ourea-home-suggestion");
List<OureaHomeSuggestionModel> result = new ArrayList<>();
String[] highlightFieldName = {"name.prefix", "name.standard", "name.full_pinyin", "name.first_letter.prefix", "name.first_letter"};
query(key, searchRequest);
highlight(searchRequest, highlightFieldName);
SearchResponse search = companyDocumentMapper.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
OureaHomeSuggestionModel homeSuggestionModel = JSON.parseObject(sourceAsString, OureaHomeSuggestionModel.class);
result.add(homeSuggestionModel);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
for (String hfName : highlightFieldName) {
HighlightField hf = highlightFields.get(hfName);
if (hf == null) continue;
Text[] fragments = hf.getFragments();
homeSuggestionModel.setHighlight(fragments[0].toString());
break;
}
}
return result;
}
private void highlight(SearchRequest searchRequest, String[] highlightField) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
for (String field : highlightField) {
highlightBuilder.field(field).highlighterType("plain");
}
searchRequest.source().highlighter(highlightBuilder);
}
private void query(String key, SearchRequest searchRequest) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().minimumShouldMatch(1);
boolQueryBuilder.filter(QueryBuilders.termQuery("onlined", 1));
List<QueryBuilder> should = boolQueryBuilder.should();
// 中文前缀
should.add(QueryBuilders
.termQuery("name.prefix", key)
.boost(10));
// 中文中缀
should.add(QueryBuilders
.matchPhraseQuery("name.standard", key)
.boost(5f));
// 拼音全拼前缀
BoolQueryBuilder fullPinyinPrefixBoolQueryBuilder = new BoolQueryBuilder();
should.add(fullPinyinPrefixBoolQueryBuilder);
fullPinyinPrefixBoolQueryBuilder.minimumShouldMatch(1);
fullPinyinPrefixBoolQueryBuilder.boost(3);
fullPinyinPrefixBoolQueryBuilder.filter(
QueryBuilders.matchPhrasePrefixQuery("name.full_pinyin.prefix", key)
.analyzer("full_pinyin_prefix_search_analyzer")
.maxExpansions(100));
fullPinyinPrefixBoolQueryBuilder.should().add(
QueryBuilders.matchPhrasePrefixQuery("name.full_pinyin", key)
.analyzer("full_pinyin_search_analyzer"));
// 拼音全拼中缀
should.add(QueryBuilders
.matchPhrasePrefixQuery("name.full_pinyin", key)
.analyzer("full_pinyin_search_analyzer")
.boost(1.5f));
// 拼音首字母前缀
should.add(QueryBuilders
.matchQuery("name.first_letter.prefix", key)
.analyzer("first_letter_prefix_search_analyzer")
.maxExpansions(100)
.boost(1));
// 拼音首字母中缀
should.add(QueryBuilders
.matchPhraseQuery("name.first_letter", key)
.analyzer("first_letter_search_analyzer")
.boost(0.8f));
searchRequest.source().query(boolQueryBuilder);
}
}
Model
public class OureaHomeSuggestionModel {
/**
* id
*/
private String id;
/**
* 职位/公司名称
*/
private String name;
/**
* 职位:状态 0未提交 1未审核 2已通过 3已驳回
* 公司:状态 0未认证 1待审核 2已认证 3未通过
*/
private Integer status;
/**
* 1 企业 2 职位
*/
private Integer type;
/**
* 是否置顶
*/
private Integer top;
/**
* 职位是否上线 1上线 0下线
*/
private Integer onlined;
/**
* 排序
*/
private Double sequence;
private String highlight;
// 省略 get set 方法
}
搜索 - 前端
由于本人前端能力有限所以网上找了个搜索的例子改了改,见笑了 : )
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Test Baidu</title>
<style>
* {
margin: 0;
padding: 0;
}
em {
color: red;
}
</style>
<script>
window.onload=function(){
//获取文本输入框
var textElment = document.getElementById("text");
//获取下提示框
var div = document.getElementById("tips");
textElment.onkeyup=function(){
//获取用户输入的值
var text = textElment.value;
//如果文本框中没有值,则下拉框被隐藏,不显示
if(text==""){
div.style.display="none";
return;
}
//获取XMLHttpRequest对象
var xhr = new XMLHttpRequest();
//编写回调函数
xhr.onreadystatechange=function(){
//判断回调的条件是否准备齐全
if(xhr.readyState===4){
if(xhr.status===200){
//取的服务器端传回的数据
var str = xhr.responseText;
var childs = "";
//判断传回的数据是否为空,若是则直接返回,不显示
if (str == "") {
div.innerHTML = "<div></div>";
div.style.display = "block";
return;
}
//我们将会在服务器端把数据用 , 隔开,当然这里也可以使用json
var result = str.split(",");
var resultJson = JSON.parse(xhr.responseText);
console.log(resultJson)
//遍历结果集,将结果集中的每一条数据用一个div显示,把所有的div放入到childs中
for (var i = 0; i < resultJson.length; i++) {
var suggest = resultJson[i];
childs += "<div style='border-bottom: 1px solid pink' οnclick='Write(this)' οnmοuseοut='recoverColorwhenMouseout(this)' οnmοuseοver='changeColorwhenMouseover(this)'>"
+ suggest.highlight + (suggest.type === 1 ? "(企业)" : "(职位)")
+ "</div>";
}
//把childs 这div集合放入到下拉提示框的父div中,上面我们以获取了
div.innerHTML = childs;
div.style.display = "block";
}
}
}
//创建与服务器的连接
xhr.open("GET", "ourea_home_v2/suggest?key=" + encodeURI(text).replace(/\+/g,'%2B'));
//发送
xhr.send();
}
}
//鼠标悬停时改变div的颜色
function changeColorwhenMouseover(div){
div.style.backgroundColor="blue";
}
//鼠标移出时回复div颜色
function recoverColorwhenMouseout(div){
div.style.backgroundColor="";
}
//当鼠标带点击div时,将div的值赋给输入文本框
function Write(div){
//将div中的值赋给文本框
document.getElementById("text").value=div.innerHTML;
//让下拉提示框消失
div.parentNode.style.display="none";
}
</script>
</head>
<body>
<!--
文本输入框
-->
<div id="serach" style="margin-left: 500px">
<input type="text" name="text" id="text" />
<input type="submit" value="搜索" />
</div>
<!--
提示下拉框
-->
<div id="tips" style="display: none;
width: 300px; border: 1px solid pink; margin-left: 500px"; >
</div>
</body>
</html>
测试
现在看看我们做的搜索提示是不是满足我们的要求
中文前缀

中文中缀

拼音全拼前缀
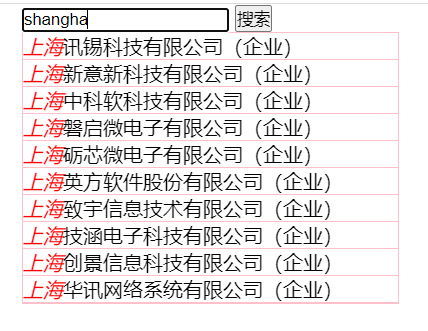
拼音全拼中缀

中文 + 拼音全拼 前缀


中文 + 拼音全拼 中缀


中文 + 拼音首字母 前缀

中文 + 拼音首字母 中缀


存在问题
由于拼音分词器会把符号过滤掉比如 + ,所以如果搜索 C++ 这种会出现问题,临时没找到比较好的解决方法。

总结
写到这里本文也接近尾声了,本次中文搜索提示的实战,算是对自己这段时间 Spring 框架 和 Elastic Search 学习的一个检验和总结,虽然还有许多问题,但搜索提示基本满足了我的要求。好就这样,祝大家生活愉快。
参考资料
- https://www.elastic.co/guide/en/elasticsearch/reference/8.8
- https://github.com/medcl/elasticsearch-analysis-pinyin
- https://juejin.cn/post/7206487695123513403
- https://time.geekbang.org/course/intro/100030501
- https://blog.csdn.net/UbuntuTouch/article/details/100697156
- https://elasticstack.blog.csdn.net/article/details/100526099
- https://github.com/ververica/flink-cdc-connectors
- https://developer.aliyun.com/article/984320
- https://juejin.cn/post/6844903605967781902
- https://blog.csdn.net/A_Story_Donkey/article/details/81244338
- https://www.easy-es.cn/
- https://blog.csdn.net/qq_22130209/article/details/110000579

















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









