






深度学习
- 二元分类 (Binary Classification)
- Logistic 回归 (Logistic Regression)
- Logistic 回归损失函数 (Logistic Regression Cost Function)
- 梯度下降法 (Gradient Descent)
- m 个样本的梯度下降 (Gradient Descent on m mm example)
- 向量化 (Vectorization)
- 随机初始化
- 编程作业(识别猫咪图片:)
- 超参数:
- 隐藏层和层的定义:
- 训练/开发/测试集
- 正则化
- Dropout 正则化
- 归一化输入
- 梯度消失与梯度爆炸
- 神经网络的权重初始化
- 梯度的数值逼近
- 梯度检验
- Mini-batch 梯度下降
- 指数加权平均
- 偏差修正
- 动量梯度下降法
- RMSprop的算法
- 归一化网络的激活函数
- BatchNorm(BN)
- Softmax 回归
- TensorFlow
- 为什么需要ML策略 (Why ML strategy?)
- 正交化 (Orthogonalization)
- 单一数字评估指标 (Single Number Evaluation Metric)
- 满足和优化指标 (Satisficing and Optimizing Metrics)
- 训练/开发/测试集划分 (Train/Dev/Test Distribution)
- 什么时候改变开发和测试集评估指标 (When to change dev/test sets and metrics)
- 贝叶斯最优错误率(Bayes optimal error)
- 可避免误差 (Avoidable Error)
- 改善你的模型表现
二元分类 (Binary Classification)
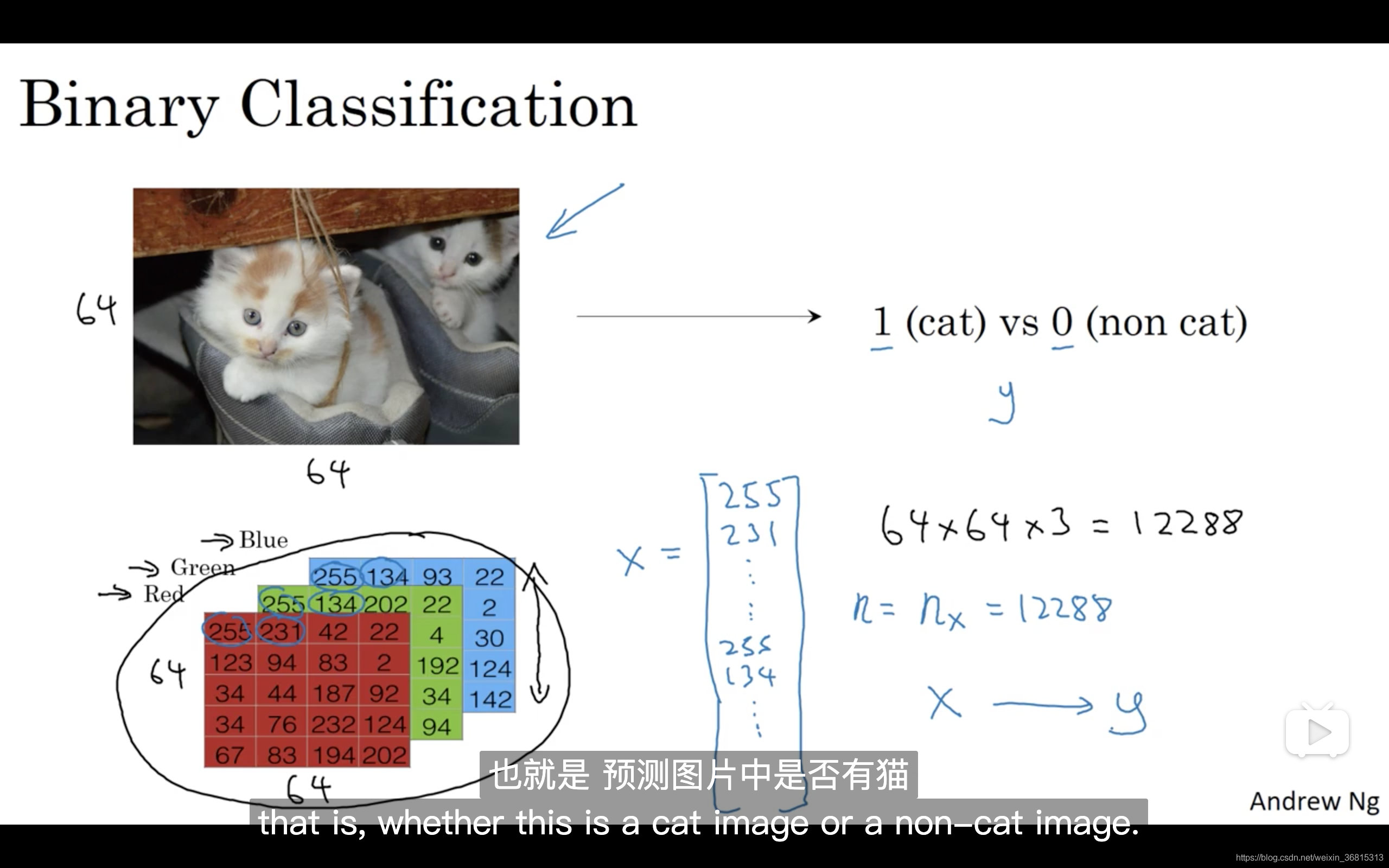
向量x的总维度,将是64乘以64乘以3,这是三个像素矩阵中像素的总量。
在这个例子中结果为
n
x
n_{x}
nx=12288。
然后预测输出y结果为1还是0,也就是预测图片中是否有猫。


X是一个规模为
n
x
n_{x}
nx乘以m的矩阵,当你用Python实现的时候,你会看到X.shape,这是一条Python命令,用于显示矩阵的规模,即X.shape等于 (
n
x
n_{x}
nx,m) 。
Y.shape等于,表示这是一个规模为1乘以m的矩阵。
Logistic 回归 (Logistic Regression)
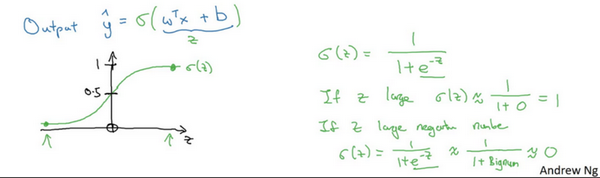
目的是输出是否为猫的概率应该在0-1之间,而公式
y
^
=
w
T
x
+
b
\hat{y}=w^{T} x+b
y^=wTx+b超出范围,要转化为sigmoid函数
把整个当作z代入
σ
(
z
)
=
1
1
+
e
−
z
\sigma(z)=\frac{1}{1+e^{-z}}
σ(z)=1+e−z1
Logistic 回归损失函数 (Logistic Regression Cost Function)
代价函数:

逻辑回归中用到的损失函数是:
L
(
y
^
,
y
)
=
−
y
log
(
y
^
)
−
(
1
−
y
)
log
(
1
−
y
^
)
L(\hat{y}, y)=-y \log (\hat{y})-(1-y) \log (1-\hat{y})
L(y^,y)=−ylog(y^)−(1−y)log(1−y^)

为了衡量算法在全部训练样本上的表现如何,我们需要定义一个算法的代价函数,算法的代价函数是对m个样本的损失函数求和然后除以m
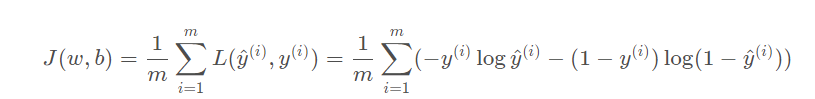
损失函数只适用于像这样的单个训练样本,而代价函数是参数的总代价,所以在训练逻辑回归模型时候,我们需要找到合适的w和b,来让代价函数J的总代价降到最低。
梯度下降法 (Gradient Descent)

m 个样本的梯度下降 (Gradient Descent on m mm example)

先初始化为0,然后循环对1-m个样本循环求导求平均值
向量化 (Vectorization)

用向量替代for循环可以更快

为了方便计算,用reshape重塑为矩阵
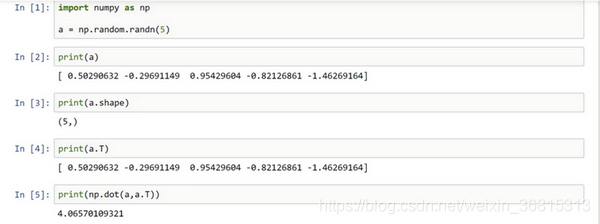
不建议a=np.random.randn(5)这样写,它既不是一个行向量也不是一个列向量,而是a 为 ( 5 , 1 )
随机初始化


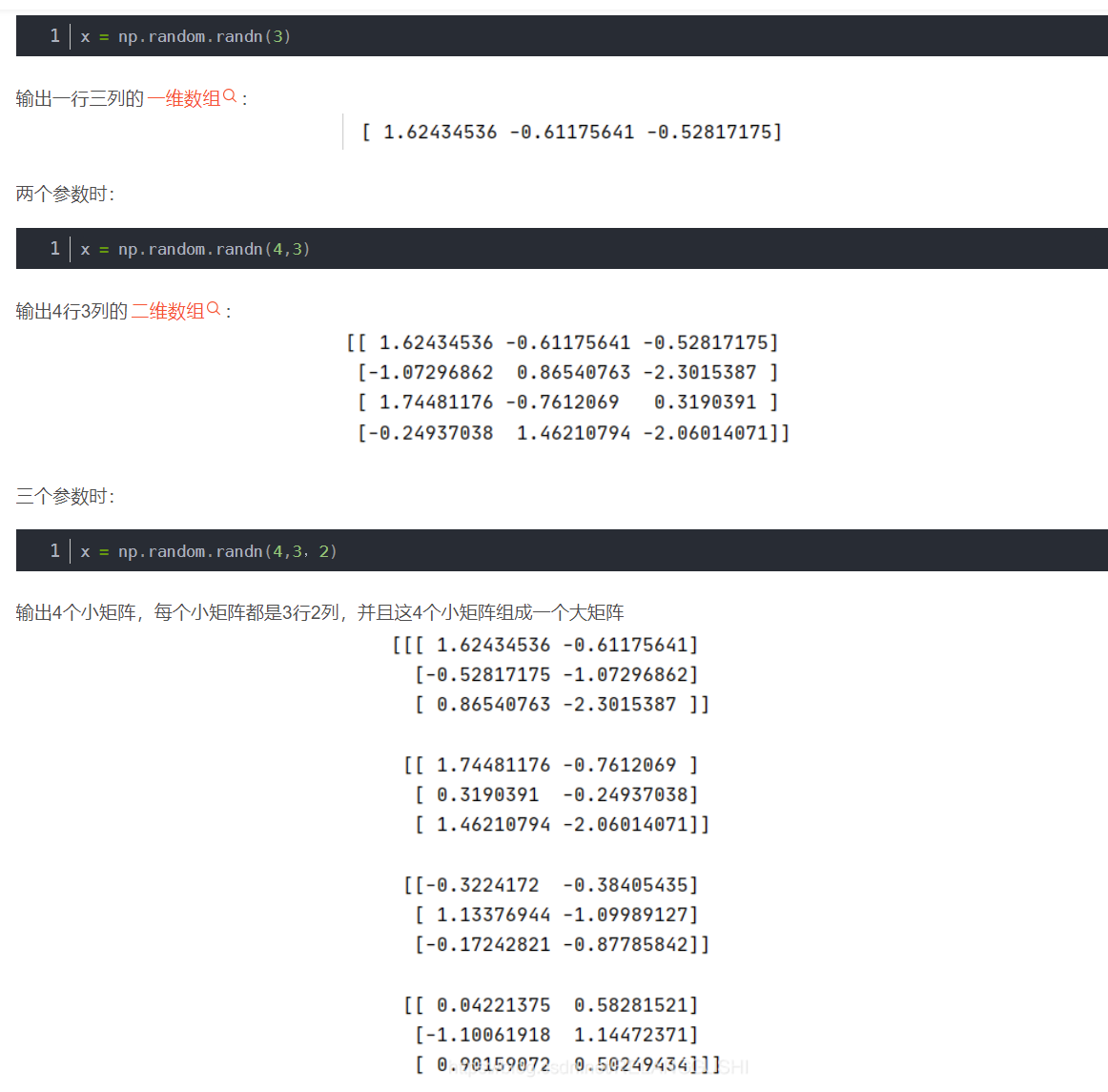
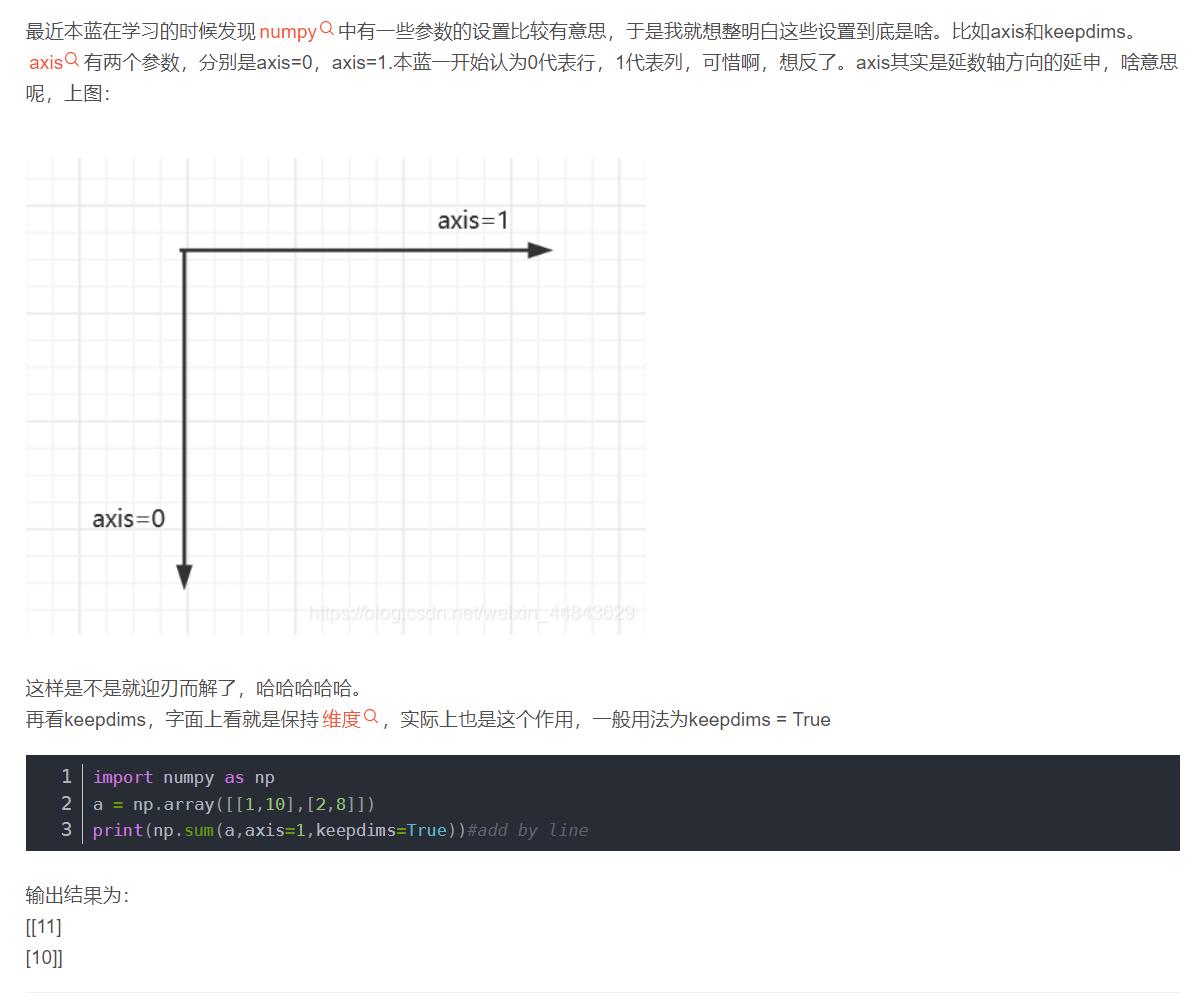

所以这道题是按行相加,变成4行1列

由上面的结果可以得到下面规律:

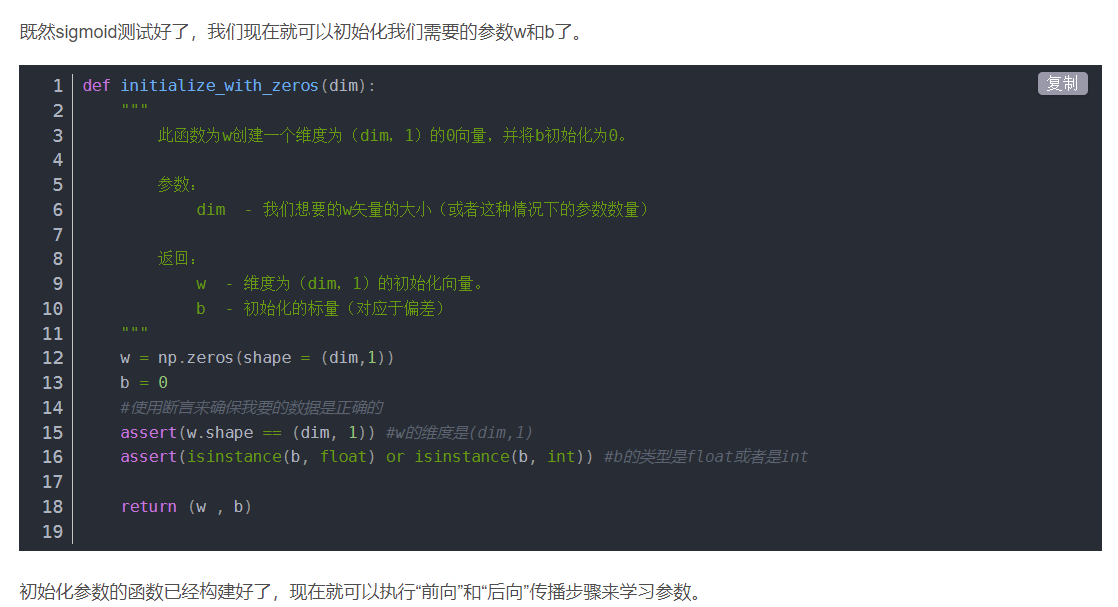
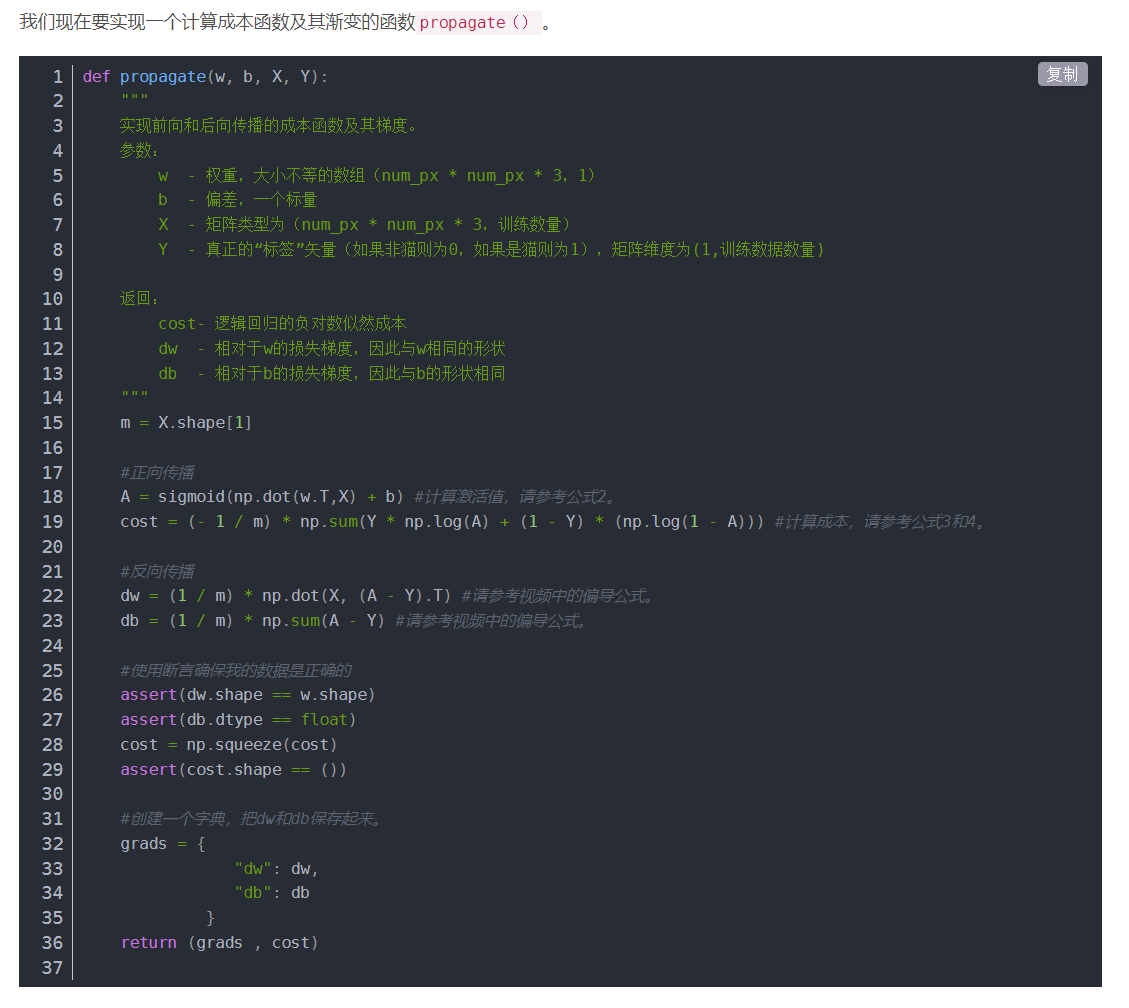
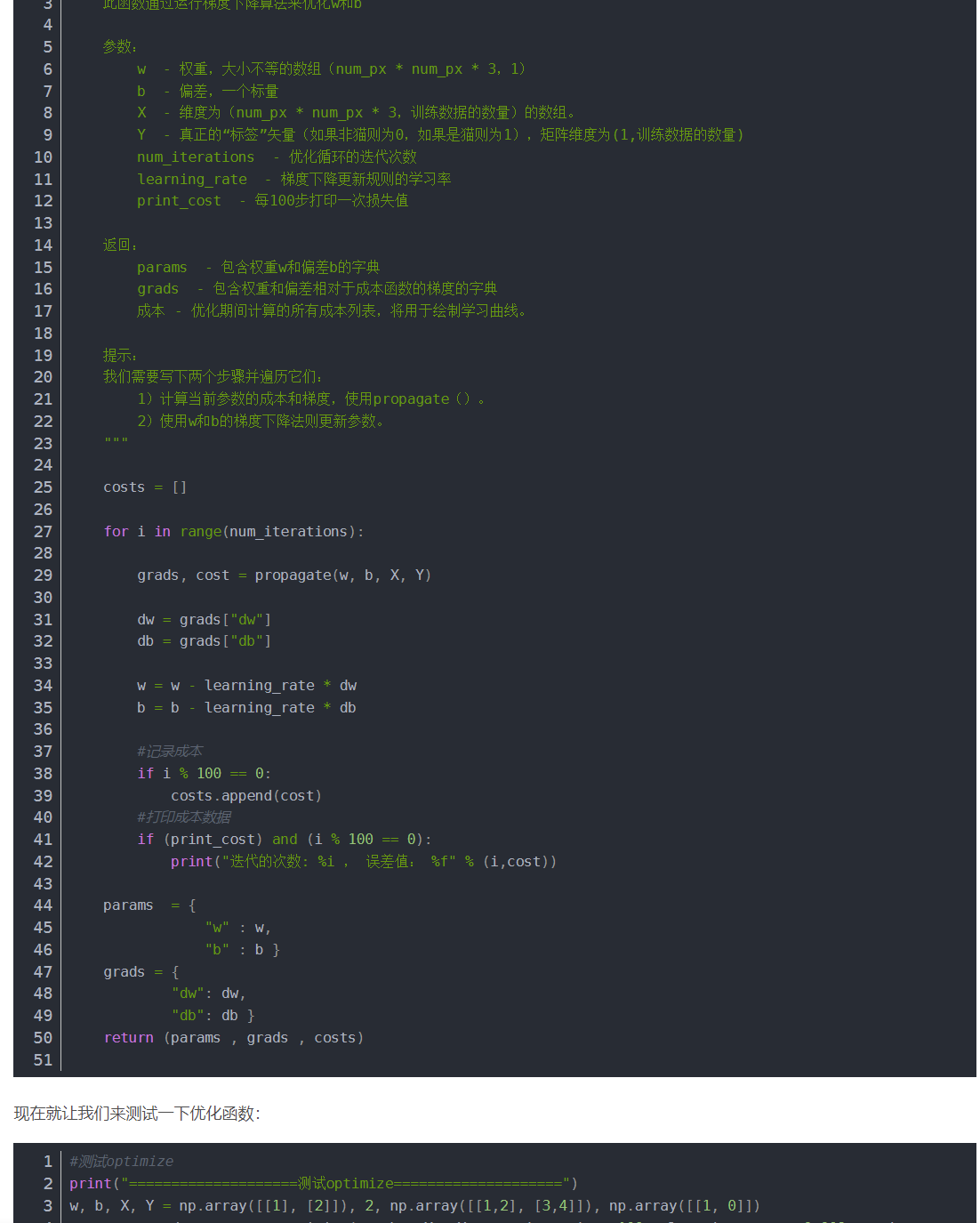
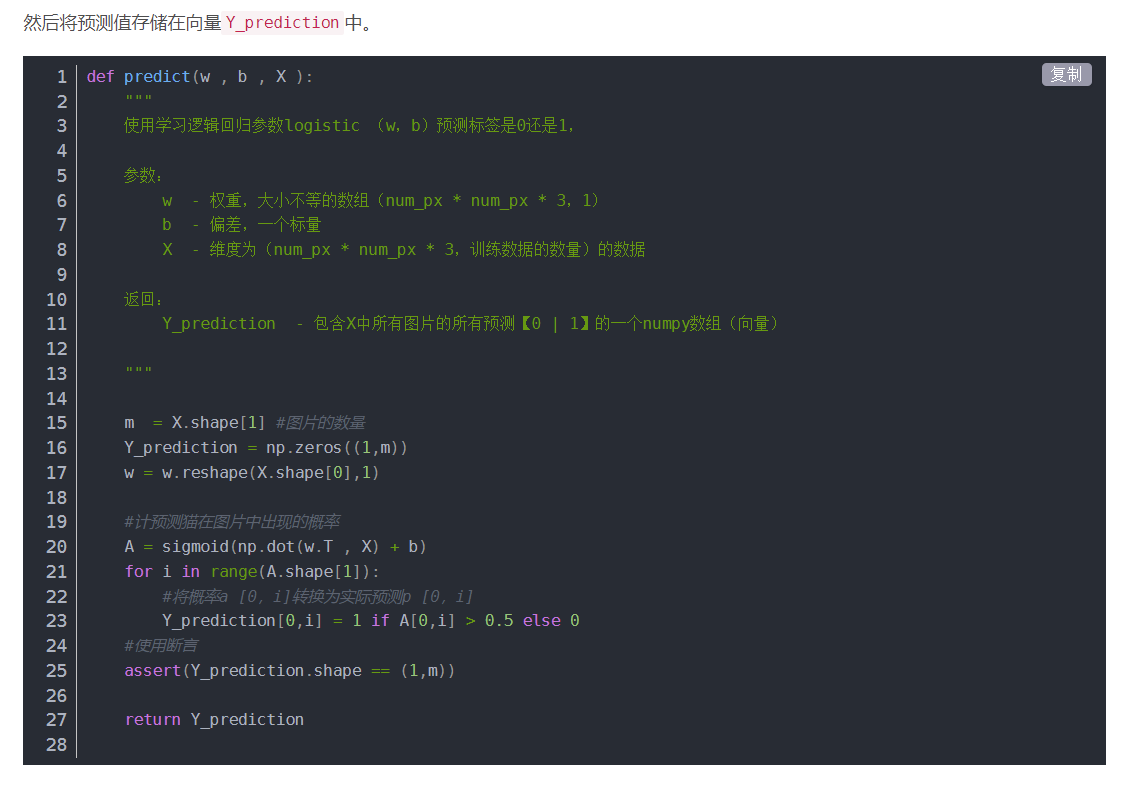
编程作业(识别猫咪图片:)
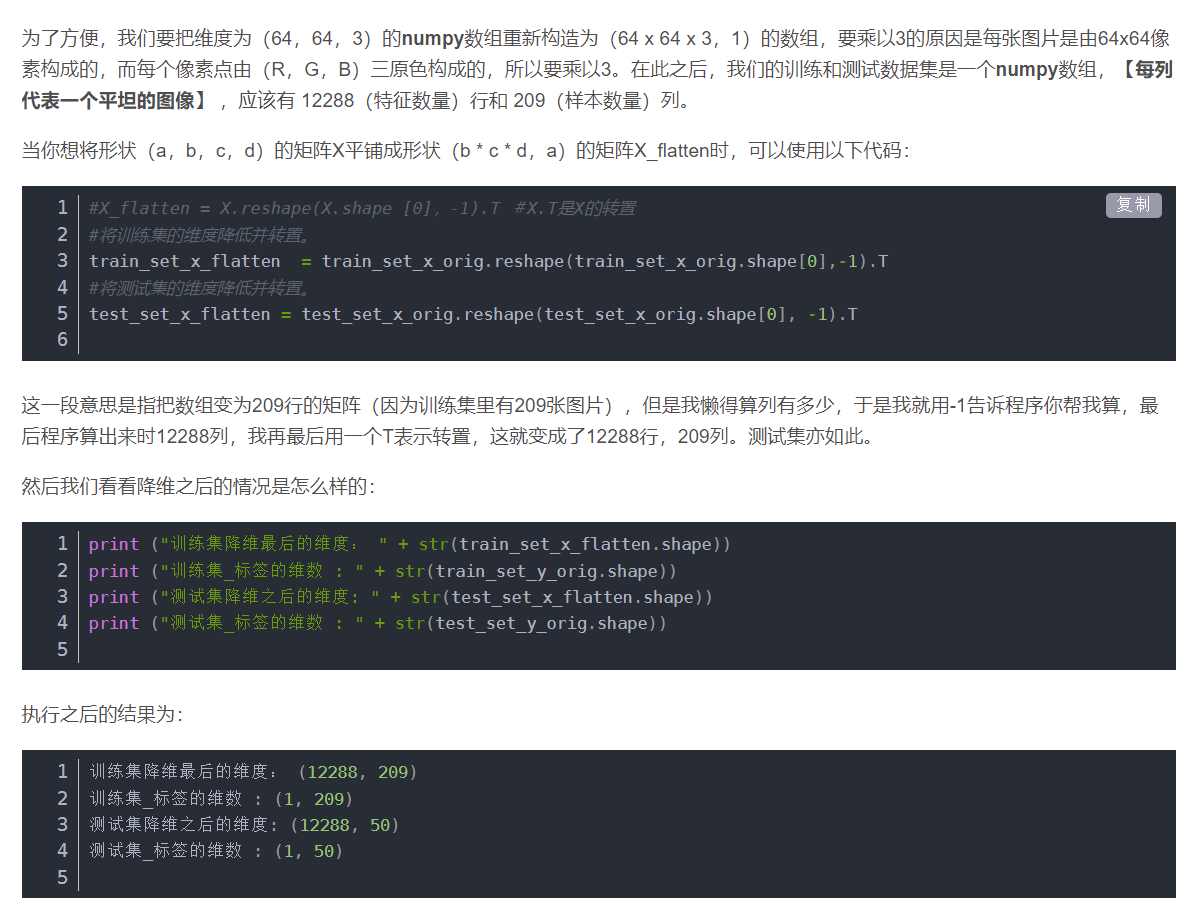
先对数据处理,转换维度
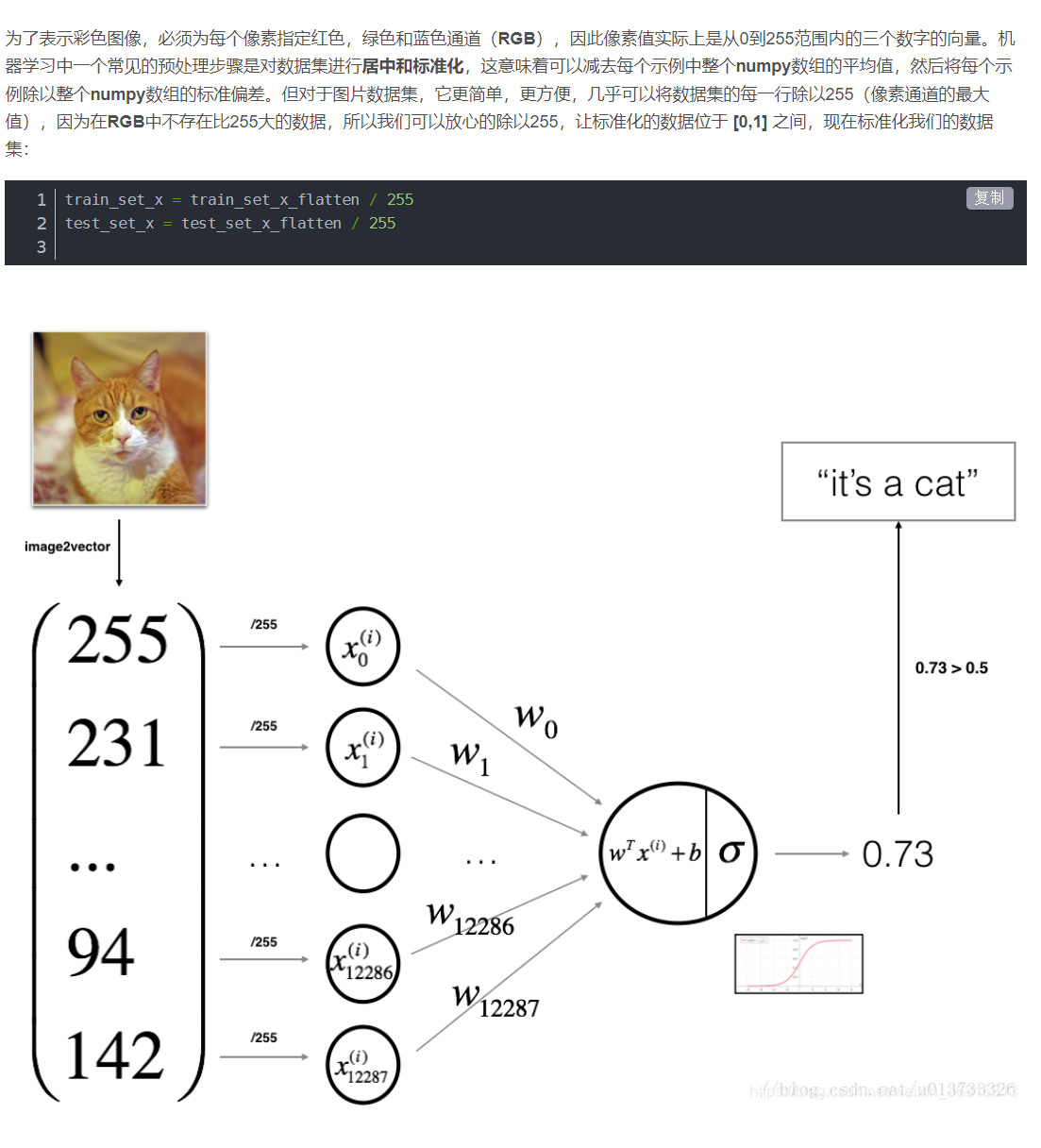
让数据位于0到1之间

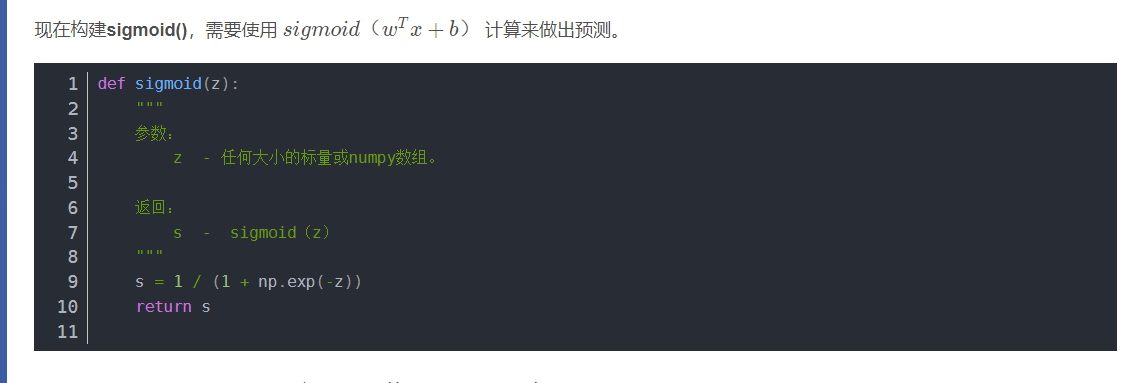
然后按照上图开始建立网络
超参数:

隐藏层和层的定义:

训练/开发/测试集

正则化


让隐藏单元的w影响变小
Dropout 正则化
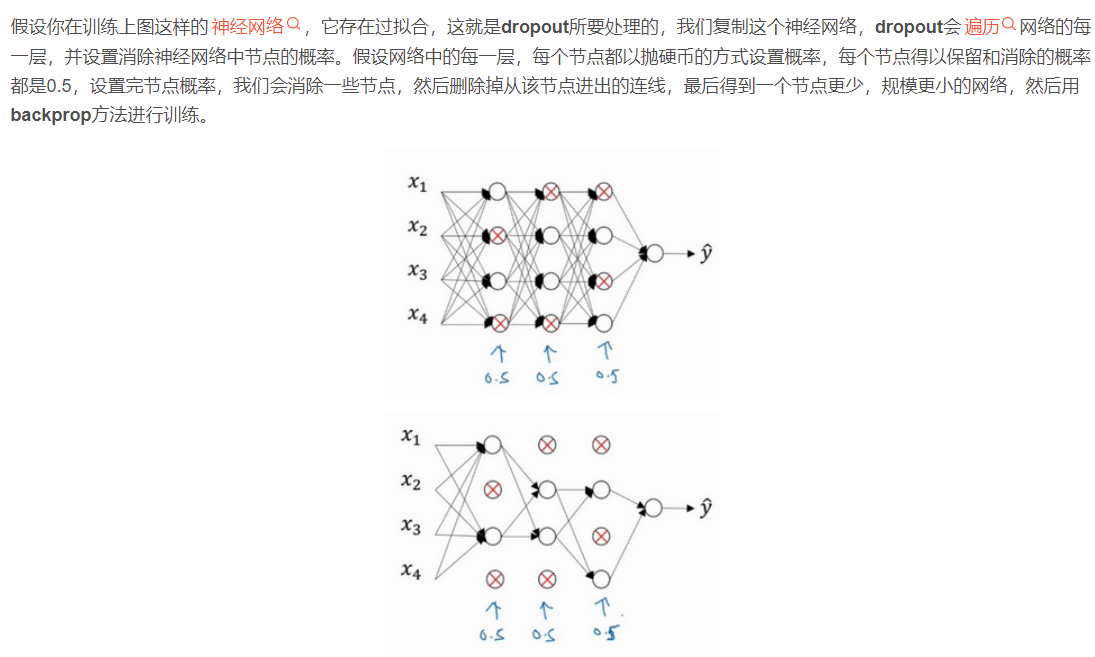

为解决过拟合而设置消除概率,目的是预防权重过大。这个方法只在训练的时候用,不能在测试的时候用
归一化输入

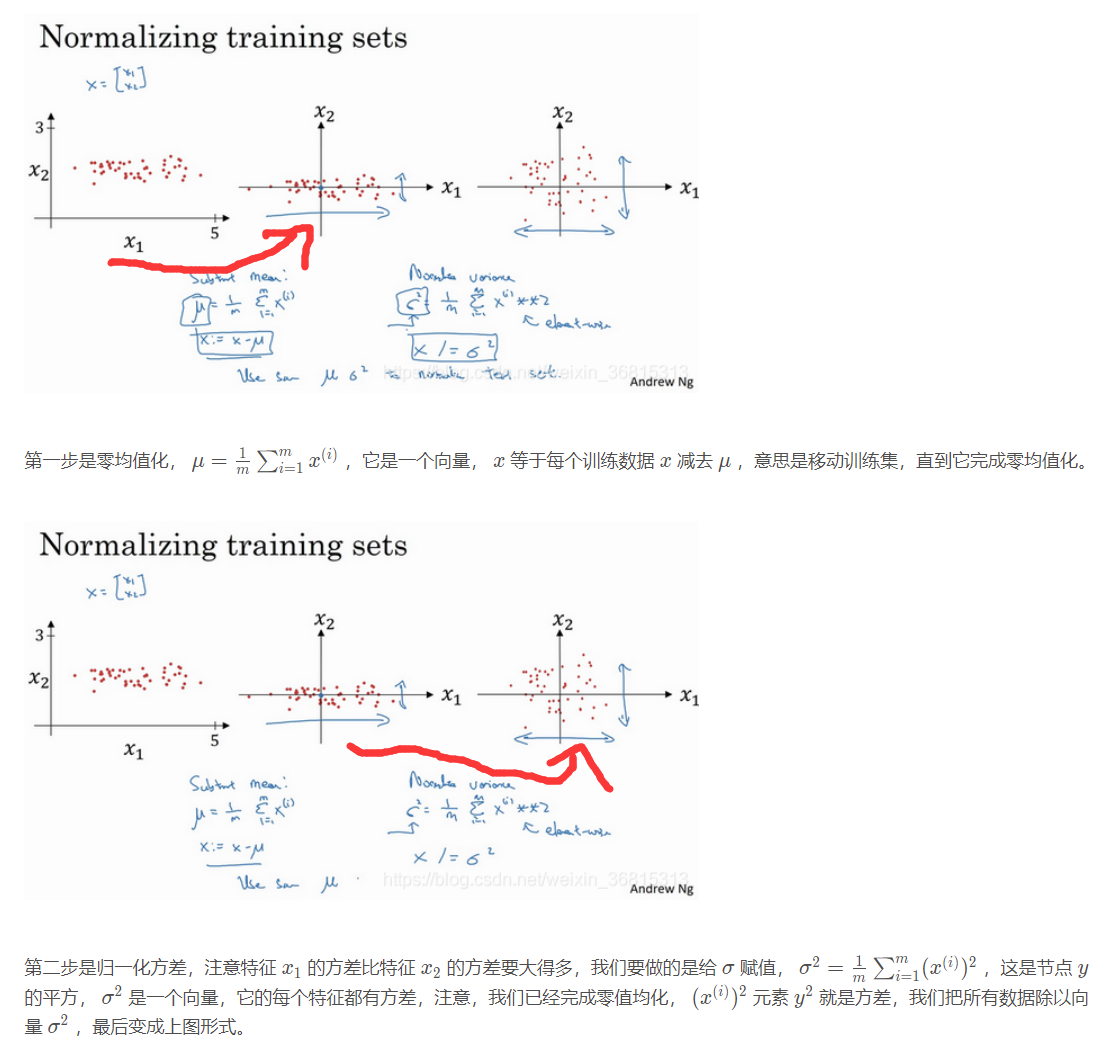
为了保证特征的都在相似范围内,所以用归一化
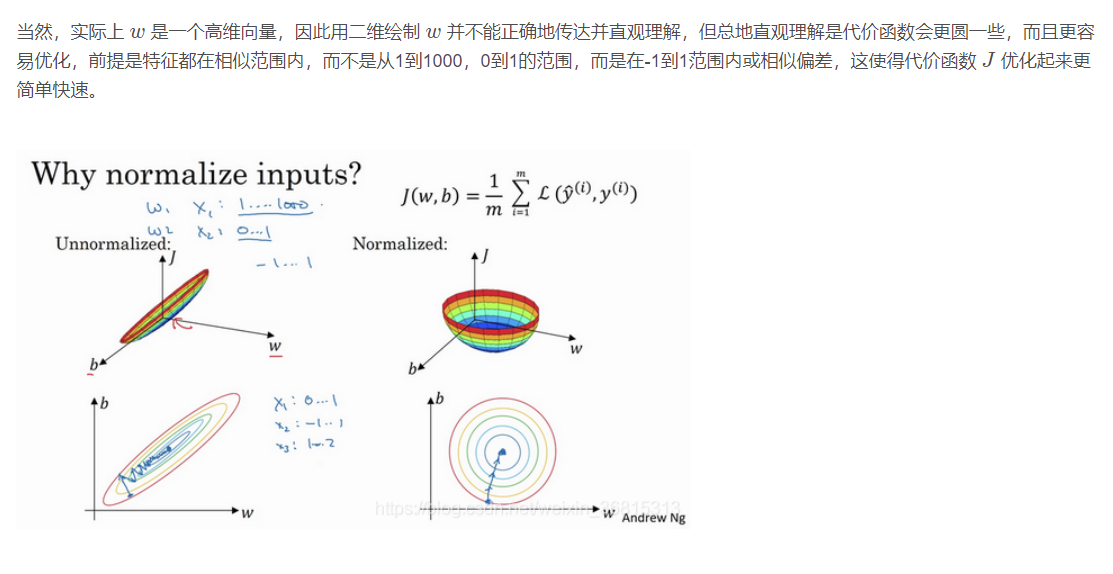
梯度消失与梯度爆炸


神经网络的权重初始化


梯度的数值逼近
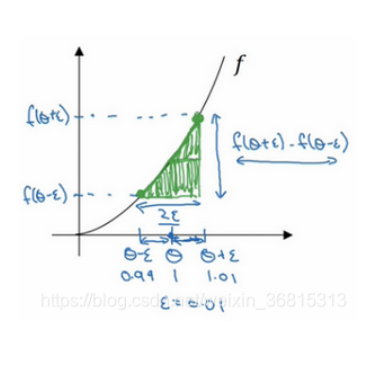

梯度检验




注意:
1.不要在训练中使用梯度检验,它只用于调试。
2.如果算法的梯度检验失败,要检查所有项,检查每一项,并试着找出bug
3.在实施梯度检验时,如果使用正则化,请注意正则项。
4.梯度检验不能与dropout同时使用,因为每次迭代过程中,dropout会随机消除隐藏层单元的不同子集,难以计算dropout在梯度下降上的代价函数 J 。
Mini-batch 梯度下降
所以如果你在处理完整个500万个样本的训练集之前,先让梯度下降法处理一部分,你的算法速度会更快,准确地说,这是你可以做的一些事情。
使用batch梯度下降法,一次遍历训练集只能让你做一个梯度下降,使用mini-batch梯度下降法,一次遍历训练集,能让你做5000个梯度下降。

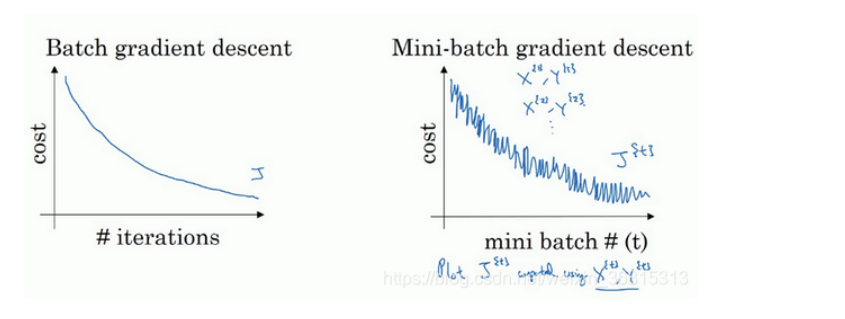
如果mini-batch的大小等于 m ,其实就是batch梯度下降法;
假设mini-batch大小为1,就有了新的算法,叫做随机梯度下降法,每个样本都是独立的mini-batch

选择原则:

指数加权平均
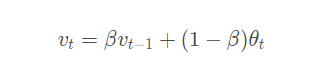

通过调节β的大小来对前面的数据加权平均,β越大越平稳

偏差修正

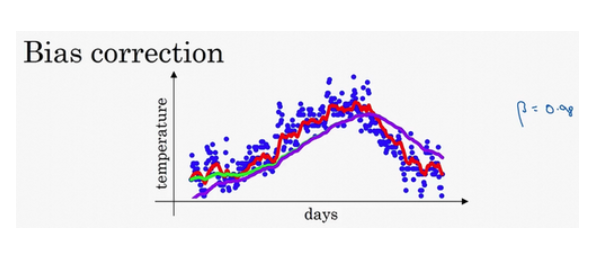
让初始值更接近真实值。
动量梯度下降法

给w和b都加了指数加权平均,让它在纵轴摆动幅度更小,在横轴更快

完整公式:

β取0.9是很好的值
RMSprop的算法

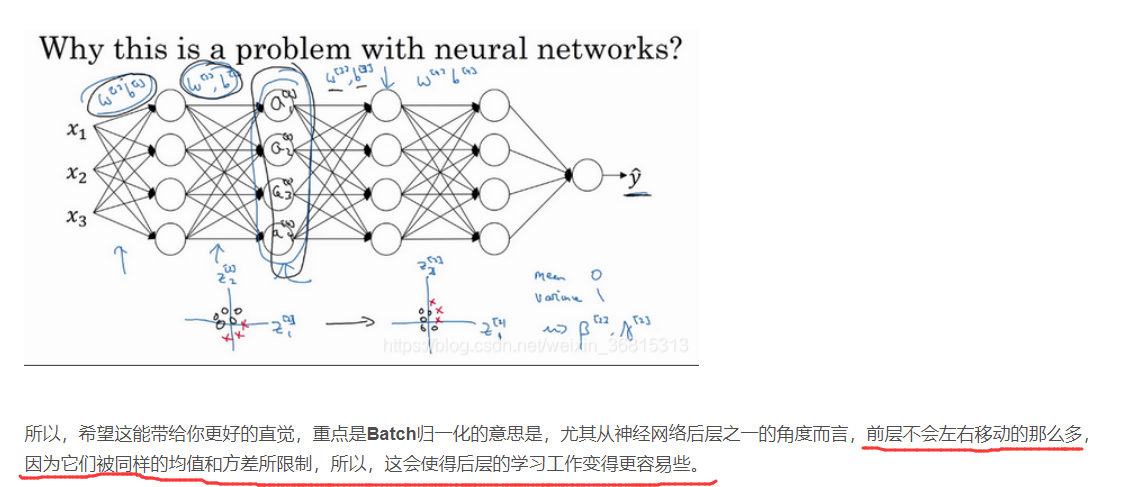
归一化网络的激活函数

logistic回归时是归一化输入特征
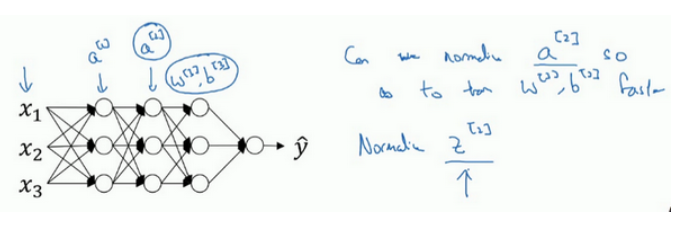
Batch归一化是归一化激活函数a

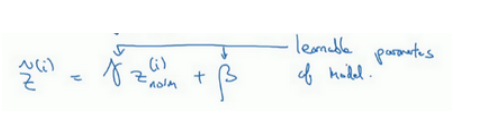
通过赋予 γ和 β 其它值,可以使你构造含其它平均值和方差的隐藏单元值,这里γ和 β也是可以学习的参数。
BatchNorm(BN)
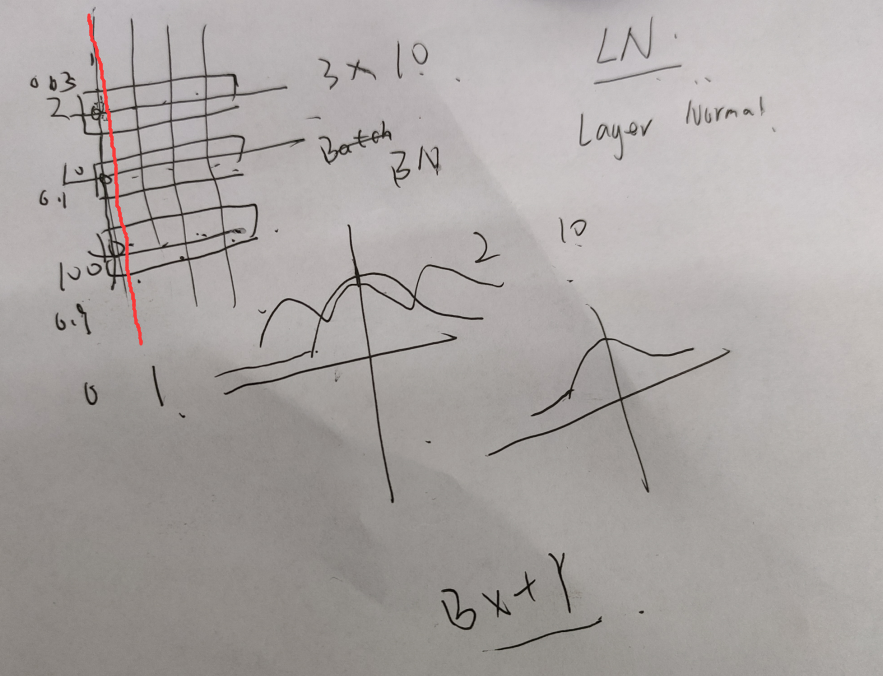
上图假设是3x10的向量,而列方向相当于是特征,BN的作用就是对一列一列进行归一化,使其差距没那么大,比如2和100都缩小到0-1的范围。
而β和y是让曲线拟合原来的,因为归一以后正态分布和原来不像了。

Softmax 回归
要分四类,C等于4,因此这里的 y ^将是一个 4 ∗ 1维向量,因为它必须输出四个数字,给你这四种概率,因为它们加起来应该等于1,输出中的四个数字加起来应该等于1。
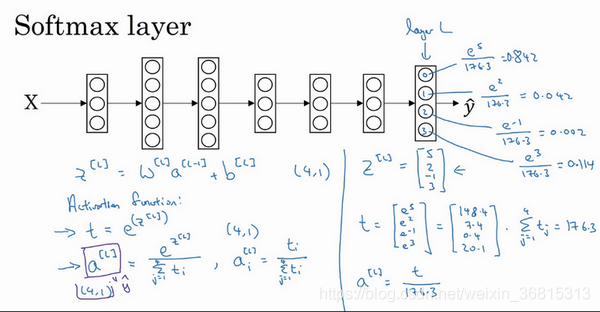
softmax可以做到分类



TensorFlow
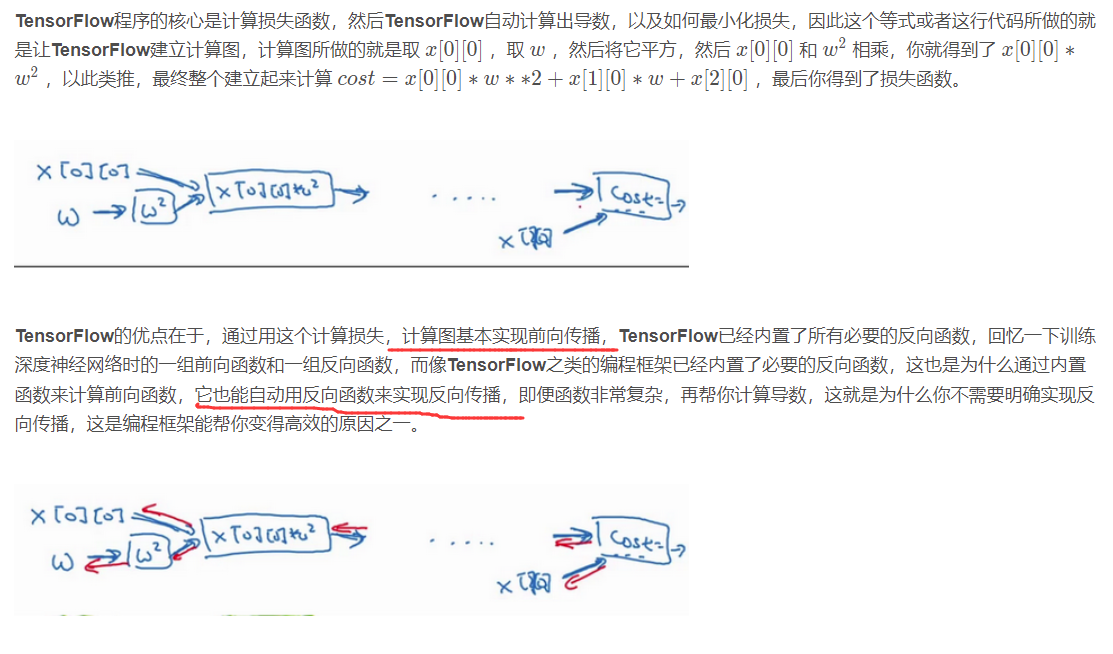
写好前向传播,自动会实行反向函数。
为什么需要ML策略 (Why ML strategy?)
能够学到如何更快速高效地优化你的机器学习系统,少走弯路
正交化 (Orthogonalization)
正交化指的是电视设计师设计这样的旋钮,使得每个旋钮都只调整一个性质,这样调整电视图像就容易得多,就可以把图像调到正中。
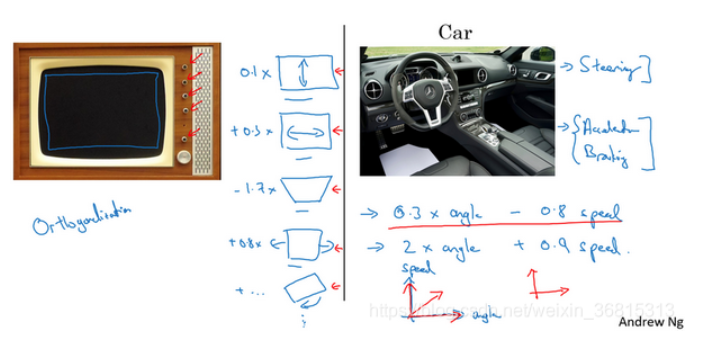 正交意味着互成90度
正交意味着互成90度
单一数字评估指标 (Single Number Evaluation Metric)
设置一个单实数评估指标,如果你有一个单实数评估指标,你的进展会快得多,它可以快速告诉你,新尝试的手段比之前的手段好还是差。作为一个从多个中选一个的指标。

如这里的f1,综合了前面两个,可以快速作出判断。
满足和优化指标 (Satisficing and Optimizing Metrics)
总结一下,如果你需要顾及多个指标,比如说,有一个优化指标,你想尽可能优化的,然后还有一个或多个满足指标,需要满足的,需要达到一定的门槛。现在你就有一个全自动的方法,在观察多个成本大小时,选出"最好的"那个。
训练/开发/测试集划分 (Train/Dev/Test Distribution)

让数据处于同一分布
什么时候改变开发和测试集评估指标 (When to change dev/test sets and metrics)
当评估指标指出某个更好,但是出现重大错误,如把色情图片当作猫图推个用户,这时候就要修改,得加大辨别色情图片的权重。
另一个问题:

但总体方针就是,如果你当前的指标和当前用来评估的数据和你真正关心必须做好的事情关系不大,那就应该更改你的指标或者你的开发测试集,让它们能更够好地反映你的算法需要处理好的数据。
贝叶斯最优错误率(Bayes optimal error)

但是过了一段时间,当这个算法表现比人类更好时,那么进展和精确度的提升就变得更慢了。也许它还会越来越好,但是在超越人类水平之后,它还可以变得更好,但性能增速,准确度上升的速度这个斜率,会变得越来越平缓,我们都希望能达到理论最佳性能水平。随着时间的推移,当您继续训练算法时,可能模型越来越大,数据越来越多,但是性能无法超过某个理论上限(绿色的线),完美的准确度可能不是100%。

可避免误差 (Avoidable Error)
贝叶斯错误率或者对贝叶斯错误率的估计和训练错误率之间的差值称为可避免偏差,而这个训练错误率和开发错误率之前的差值,就大概说明你的算法在方差问题上还有多少改善空间。


因为训练集和开发集的误差很小,所以B的减少误差不可靠了,应该是D。而减少正则化是让其尽量拟合。
假阳性:没有,识别为有;假阴性:有,识别为没有。
改善你的模型表现

















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









