






获取datasets中的数据
2将数据集划分为训练集和测试集
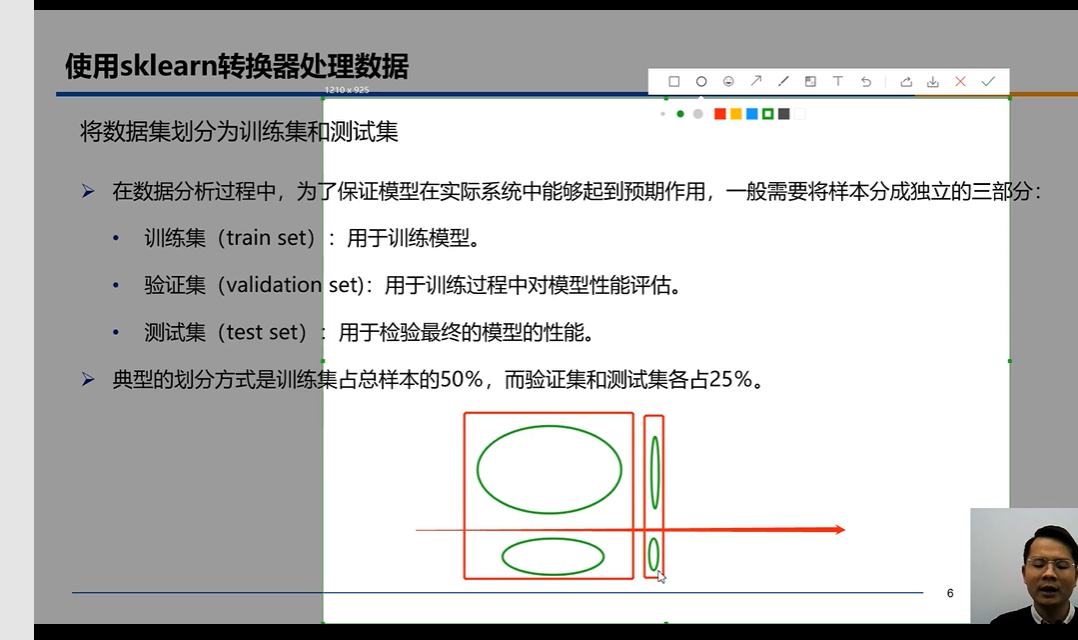
分为训练集和测试集以及二者标签

3使用sklearn转换器转换处理数据
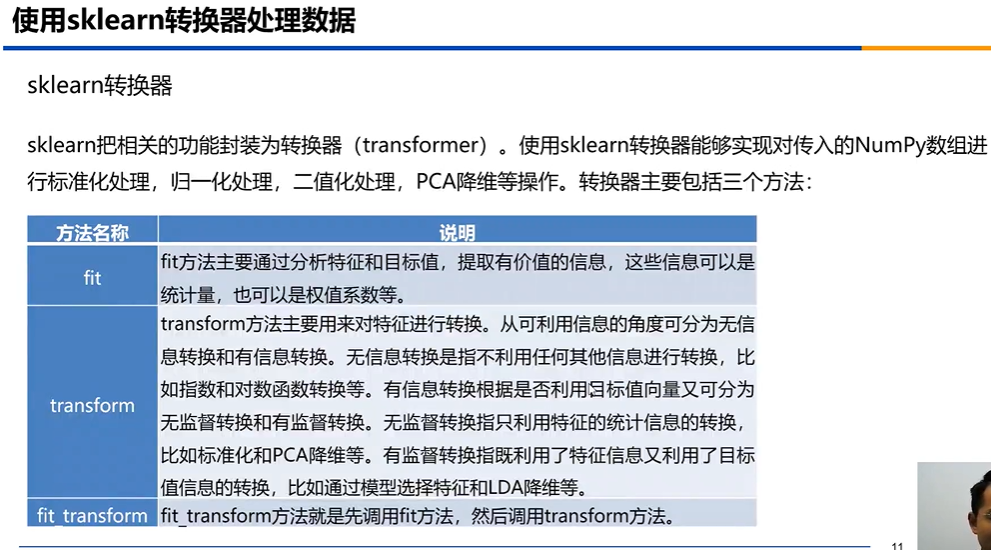
用pandas得定义函数,但是sklearn这里直接提供

生成得规则(取属性得最值等)是对训练集得取值,在转换测试集时可能出现异常值,因为二者得数据有差异
4构建并评价聚类模型
4.1构建

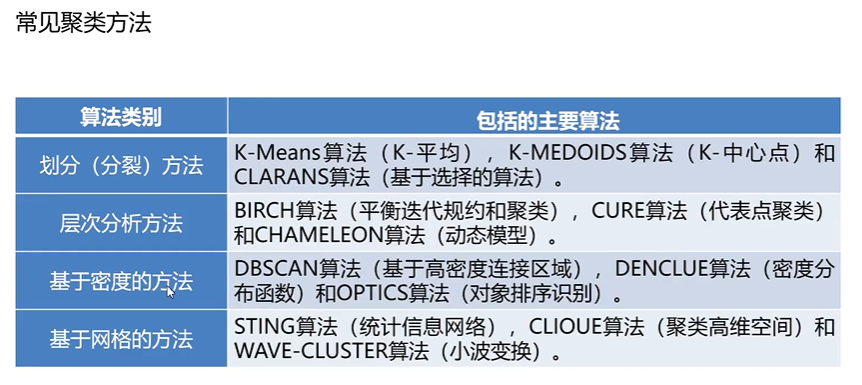
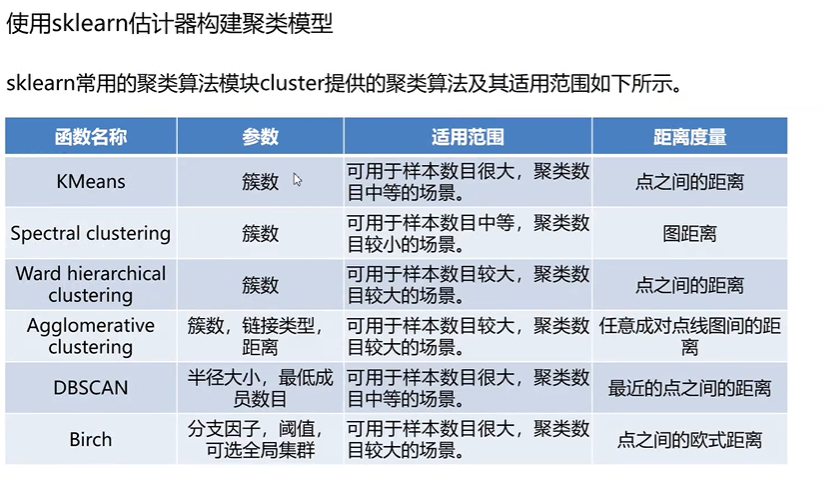
4.2评估
需要指的是样本得实际标签
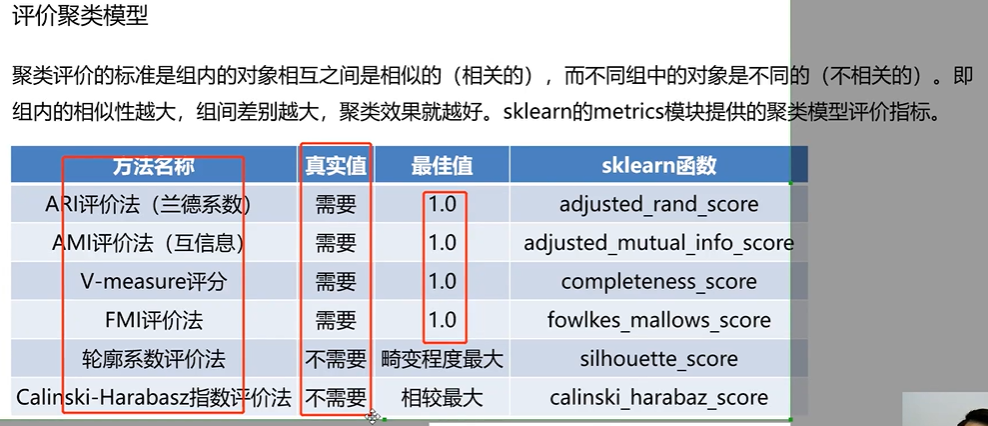
对轮廓系数而言
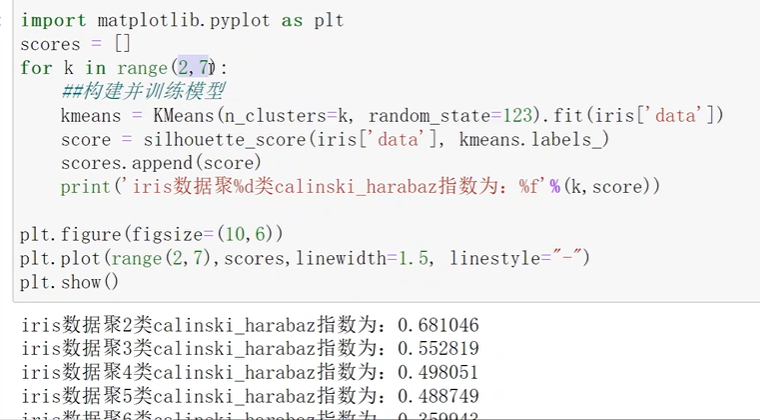
key进行变动,作图找畸变最严重得就是最合适得
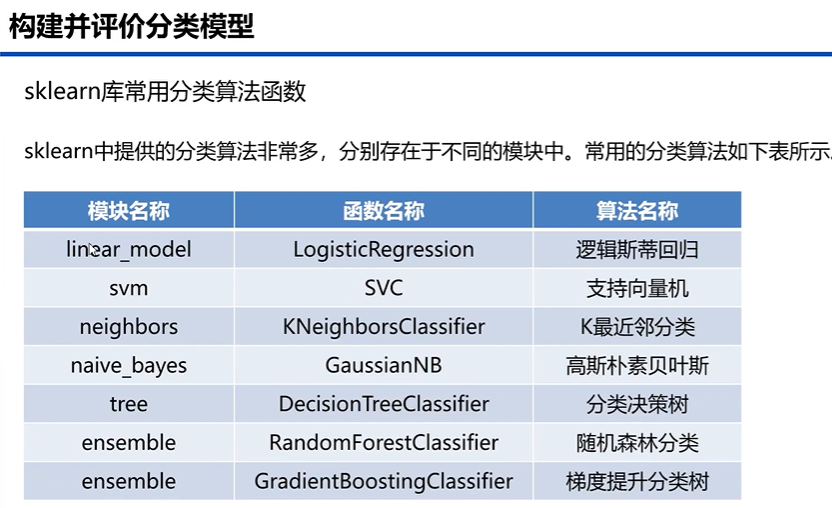
5构建并评价分类模型
Python复制代码
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
#数据得准备
iris=load_iris(return_X_y=True) #自变量和标签,返回得是元组,而不是字典了
X=iris[0]
y=iris[1]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,stratify=y) #=y分层抽样
clf=DecisionTreeClassifier() #实例化决策树分类器
clf.fit(X_train,y_train) #调用fit方法进行模型训练
print(clf)
print(clf.classes_)
print(clf.feature_importances_)
#每个属性贡献的重要程度
# [0.01189024 0. 0.0453772 0.94273256]
print(clf.predict(X_test)) #测试样本得预测标签,调用模型对测试样本进行预测
# [0 0 2 2 2 2 2 1 0 1 2 0 2 2 1 1 1 2 0 2 1 0 0 1 0 1 0 0 2 1]
print(y_test) #[0 0 2 1 2 1 1 1 0 1 1 2 0 0 2 0 2 0 0 2 2 1 0 2 2 2 1 1 1 0]
#将预测结果与实际结果进行比对
print((clf.predict(X_test)==y_test).mean()) #0.9指标
from sklearn.metrics import classification_report
report=classification_report(y_test,clf.predict(X_test))
print(report)
#评估报告
# precision recall f1-score support
#
# 0 1.00 1.00 1.00 10
# 1 0.91 1.00 0.95 10
# 2 1.00 0.90 0.95 10
#
# avg / total 0.97 0.97 0.97 30
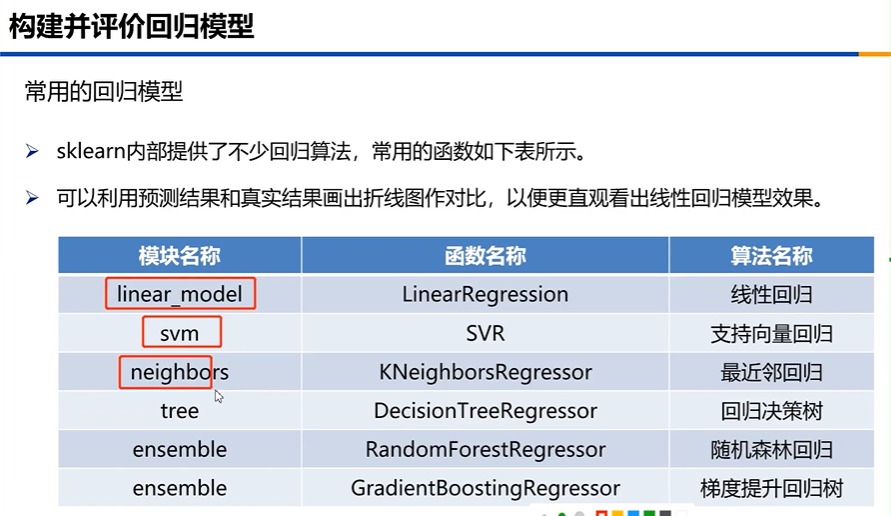
6回归模型的构建
















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









