






作者 | gongyouliu
编辑 | gongyouliu
我们在上一篇文章中介绍了规则策略召回算法,这类方法非常简单,只需要利用一些业务经验和基础的统计计算就可以实现了。本节我们来讲解一些基础的召回算法,这类算法要么是非常经典的方法,要么是需要利用一些机器学习知识的,相比上一章的方法要更复杂一点,不过也不难,只要懂一些基础的机器学习和数学知识就可以很好地理解算法原理。
具体来说,本章我们会讲解关联规则召回、聚类召回、朴素贝叶斯召回、协同过滤召回、矩阵分解召回等5类召回算法。我们会讲清楚具体的算法原理及工程实现的核心思想,读者可以结合自己公司的业务情况思考一下这些算法怎么用到具体的业务中。
8.1 关联规则召回算法
关联规则是数据挖掘中最出名的方法之一,相信大家都听过啤酒与尿布的故事(不知道的读者可以百度搜索了解一下),下面我们给出关联规则的定义。
假设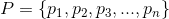 是所有物品的集合(对于家乐福超市来说,就是所有的商品集合)。关联规则一般表示为 的形式,其中是的子集,并且
是所有物品的集合(对于家乐福超市来说,就是所有的商品集合)。关联规则一般表示为 的形式,其中是的子集,并且 。关联规则表示如果在用户的购物篮(用户一次购买的物品的集合称为一个购物篮,通常用户购买的物品会放到一个篮子里,所以叫做购物篮)中,那么用户有很大概率同时购买了 。
。关联规则表示如果在用户的购物篮(用户一次购买的物品的集合称为一个购物篮,通常用户购买的物品会放到一个篮子里,所以叫做购物篮)中,那么用户有很大概率同时购买了 。
通过定义关联规则的度量指标,一些常用的关联规则算法(如Apriori)能够自动地发现所有关联规则。关联规则的度量指标主要有支持度(support)和置信度(confidence)两个,支持度是指所有的购物篮中包含的购物篮的比例(即同时出现在一次交易中的概率),而置信度是指包含的购物篮中同时也包含的比例(即在给定的情况下,出现的条件概率)。它们的计算公式如下:
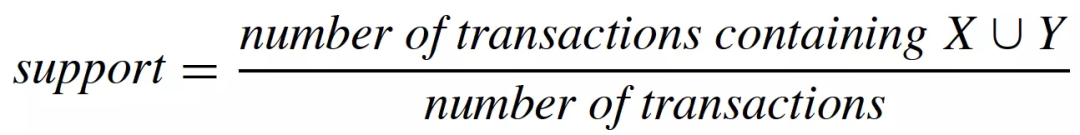
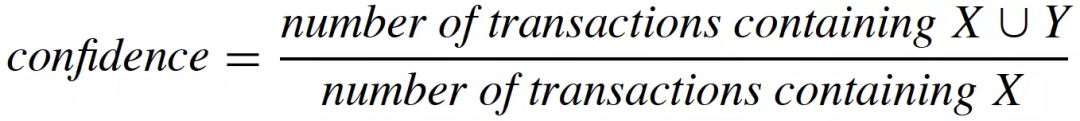
支持度越大,包含的交易样本越多,说明关联规则有更多的样本来支撑,“证据”更加充分。置信度越大,我们更有把握从包含的交易中推断出该交易也包含。关联规则挖掘中,我们需要挖掘出支持度和置信度大于某个阈值的关联规则,这样的关联规则才更可信,更有说服力,泛化能力也更强。
有了关联规则的定义,下面我们来讲解怎么将关联规则用于召回。对于推荐系统来说,一个购物篮即是用户操作过的所有物品的集合。关联规则表示的意思是:如果用户操作过中的所有物品,那么用户很可能喜欢中的物品。有了这些说明,那么利用关联规则为用户生成召回的算法流程如下(假设所有操作过的物品集合为):
挖掘出所有满足一定支持度和置信度(支持度和置信度大于某个常数)的关联规则;
从1中所有的关联规则中筛选出所有满足的关联规则;
为用户生成召回候选集,具体计算如下:
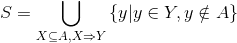
即将所有满足2的关联规则中的合并,并剔除掉用户已经操作过的物品,这些物品就是待召回给用户的。对于3中的候选推荐集,可以按照该物品所在关联规则的置信度的大小降序排列,对于多个关联规则生成同样的候选推荐物品的,可以用置信度最大的那个关联规则的置信度。除了可以采用置信度外,也可以用支持度和置信度的乘积作为排序依据。对于4中排序好的物品,可以取topN作为召回给用户的结果。
基于关联规则的召回算法思路非常简单朴素,算法也易于实现,Spark Mllib中有关联规则的两种分布式实现FP-Growth和PrefixSpan,大家在业务中可以直接使用。根据作者曾经的使用经验,要是物品数量太多、用户行为记录巨大,那么整个计算过程会非常慢,所以关联规则一般适合用户数和物品数不是特别大的场景。
8.2 聚类召回算法
机器学习中的聚类算法种类非常多,大家用得最多的还是k-means聚类,本节我们也只采用k-means聚类来说明怎么召回,在讲解之前我们简单介绍一下k-means聚类的算法原理,具体步骤如下:
k-means算法的步骤:
input:N个样本点,每个样本点是一个n维向量,每一维代表一个特征。最大迭代次数M。
(1)从N个样本点中随机选择k个点作为中心点,尽量保证这k个距离相对远一点
(2)针对每个非中心点,计算他们离k个中心点的距离(欧氏距离)并将该点归类到距离最近的中心点
(3)针对每个中心点,基于归类到该中心点的所有点,计算它们新的中心(可以用各个点的坐标轴的平均值来估计),进而获得k个新的中心点
(4)重复上述步骤(2)、(3),直到迭代次数达到M或者前后两次中心点变化不大(可以计算前后两次中心点变化的平均绝对误差,比如绝对误差小于某个很小的阈值就认为变化不大)
从上面的算法原理我们可以看到,k-means是一个迭代算法,原理非常简单,可操作性也很强,scikit-learn和Spark中都有k-means算法的实现,大家可以直接调用。
讲完了k-means聚类的算法原理,我们就可以基于用户或物品进行k-means召回了,这两类召回分别用在个性化召回和物品关联物品召回中,下面我们来分别说明这两种情况怎么用k-means进行召回。
8.2.1 基于用户聚类的召回
如果我们将所有用户聚类了,就可以将该用户所在类别的其他用户操作过的物品(但是该用户没有操作行为)作为该用户的召回。具体计算公式如下,其中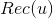 是给用户u的召回,是用户所在的聚类,
是给用户u的召回,是用户所在的聚类,![]() 、分别是用户、的操作历史集合。
、分别是用户、的操作历史集合。
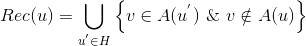
那么,对用户怎么聚类呢?其实方法有很多,下面简单举例说明一些常见的方法,读者也可以思考一下有不有其它的更好的方法。
(1)如果是社交网络产品,可以通过是否是好友关系进行用户聚类。
(2)如果有用户操作行为,那么可以获得操作行为矩阵(下面8.4节会介绍),矩阵的行就可以作为用户向量,再进行聚类;
(3)下面8.5节介绍的矩阵分解算法也可以获得用户向量表示;
(4)如果获得了物品的向量表示,那么用户的向量表示可以是他操作过的物品向量表示的加权平均;
上面只是列举了一些简单的方法,还有一些嵌入方法也可以使用(比如构建用户关系图,然后利用图嵌入),这里不进行说明,读者可以参考相关文献。
8.2.2 基于物品聚类的召回
如果有了物品的聚类,我们可以做物品关联物品的召回,具体做法是将物品A所在类别中的其他物品作为关联召回结果。另外,我们还可以利用物品聚类给用户进行个性化召回。具体做法是从用户历史行为中的物品所在的类别挑选用户没有操作行为的物品作为该用户的召回,这种召回方式是非常直观自然的。具体计算公式如下,其中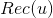 是给用户的推荐,是用户的历史操作行为集合,
是给用户的推荐,是用户的历史操作行为集合,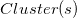 是物品所在的聚类。
是物品所在的聚类。
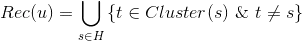
那么怎么对物品聚类呢?可行的方法有利用物品的metadata信息,采用TF-IDF、LDA、Word2vec等方式获得物品的向量表示,再利用Kmeans聚类。另外,也可以基于用户的历史操作行为,获得物品的嵌入表示(矩阵分解、item2vec等算法),用户行为矩阵的列向量也是物品的一种向量表示。
8.3 朴素贝叶斯召回算法
利用概率方法来构建算法模型为用户做召回也是可行的,用户召回问题可以看成是一个预测用户对物品的评分问题,也可以将预测评分问题看成一个分类问题,将可能的评分离散化为有限个离散值(比如1、2、3、4、5一共5个可行的分值),那么预测用户对某个物品的评分,就转化为用户在该物品上的分类了(比如分为1、2、3、4、5个类别,这里不考虑不同类之间的有序关系)。在本节我们就利用最简单的贝叶斯分类器来进行个性化召回。
假设一共有k个不同的预测评分,我们记为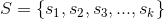 ,所有用户对物品的评分构成用户行为矩阵,该矩阵的-元素记为,即是用户对物品的评分,取值为评分集合中的某个元素。下面我们来讲解怎么利用贝叶斯公式来为用户召回。
,所有用户对物品的评分构成用户行为矩阵,该矩阵的-元素记为,即是用户对物品的评分,取值为评分集合中的某个元素。下面我们来讲解怎么利用贝叶斯公式来为用户召回。
假设用户有过评分的所有物品记为,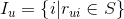 。现在我们需要预测用户对未评分的物品的评分(
。现在我们需要预测用户对未评分的物品的评分(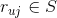 )。我们可以将这个过程理解为在用户已经有评分记录的条件下,用户对新物品的评分取集合中某个值的条件概率:
)。我们可以将这个过程理解为在用户已经有评分记录的条件下,用户对新物品的评分取集合中某个值的条件概率:
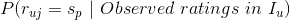
条件概率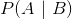 ,表示的是在事件发生的情况下事件发生的概率,由著名的贝叶斯定理,条件概率可以通过如下公式来计算:
,表示的是在事件发生的情况下事件发生的概率,由著名的贝叶斯定理,条件概率可以通过如下公式来计算:
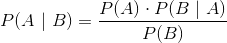
回到我们的召回问题,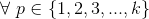 ,基于贝叶斯公式,我们有
,基于贝叶斯公式,我们有
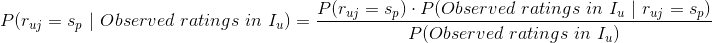
我们需要确定具体的值,让上式左边的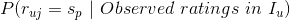 的值最大,这个最大的值就可以作为用户对未评分的物品的评分(=)。我们注意到上式中右边的分母的值与具体的无关,因此右边分子的值的大小才最终决定公式左边的值的相对大小,基于该观察,我们可以将上式记为:
的值最大,这个最大的值就可以作为用户对未评分的物品的评分(=)。我们注意到上式中右边的分母的值与具体的无关,因此右边分子的值的大小才最终决定公式左边的值的相对大小,基于该观察,我们可以将上式记为:
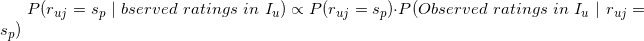
现在的问题就是怎么估计上式右边项的值,实际上基于用户评分矩阵,这些项的值是比较容易估计出来的,下面我们就来估计这些值。
估计
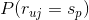
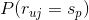 其实是的先验概率,我们可以用对物品评分为的用户的比例来估计该值,即
其实是的先验概率,我们可以用对物品评分为的用户的比例来估计该值,即
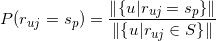
这里分母是所有对物品有过评分的用户,而分子是对物品评分为的用户。
估计

要估计 ,我们需要做一个朴素的假设,即条件无关性假设:用户所有的评分是独立无关的,也就是不同的评分之间是没有关联的,互不影响(该假设就是该算法叫做朴素贝叶斯的由来)。实际上,同一用户对不同物品评分可能是有一定关联的,在这里做这个假设是为了计算方便,在实际使用朴素贝叶斯做召回时效果还是很不错的,泛化能力也可以。
,我们需要做一个朴素的假设,即条件无关性假设:用户所有的评分是独立无关的,也就是不同的评分之间是没有关联的,互不影响(该假设就是该算法叫做朴素贝叶斯的由来)。实际上,同一用户对不同物品评分可能是有一定关联的,在这里做这个假设是为了计算方便,在实际使用朴素贝叶斯做召回时效果还是很不错的,泛化能力也可以。
有了条件无关性假设,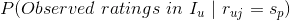 就可以用如下公式来估计了:
就可以用如下公式来估计了:

而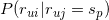 可用所有对物品评分为的用户中对物品评分为的比例来估计。即
可用所有对物品评分为的用户中对物品评分为的比例来估计。即
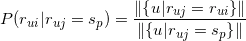
有了上面的两个估计,那么我们利用朴素贝叶斯计算用户对物品的评分概率问题最终可以表示为
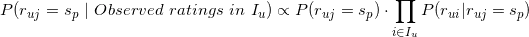
公式1:用户对物品评分的概率估计
有了上式,一般来说,我们可以采用极大似然方法来估计的值。该方法就是用 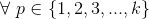 ,使得
,使得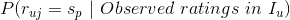 取值最大的p对应的作为的估计值,即
取值最大的p对应的作为的估计值,即
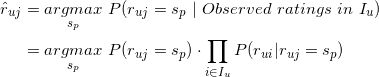
利用上面的计算公式,我们可以计算用户对每个没有操作行为的物品的评分,那么基于这些评分进行降序排列再取topN就可以获得该用户的召回结果了。
从上面的算法原理,我们可以看到朴素贝叶斯方法是一个非常简单直观的方法,工程实现也非常容易,也易于并行化。它对噪音有一定的“免疫力”,不太会受到个别评分不准的影响,并且也不易于过拟合(前面介绍的条件无关性假设是泛化能力强的主要原因),一般情况下召回效果还不错,并且当用户行为不多时,也可以使用,读者也可以通过参考文献1、2了解具体细节。朴素贝叶斯方法的代码实现也有现成的,大家可以参考scikit-learn和Spark MLlib中相关的算法实现。
8.4 协同过滤召回算法
协同过滤召回算法分为基于用户的协同过滤(user-based CF)和基于物品的协同过滤(item-based CF)两类,核心思想是很朴素的”物以类聚、人以群分“的思想。所谓物以类聚,就是计算出每个物品最相似的物品列表,我们就可以为用户推荐用户喜欢的物品相似的物品,这就是基于物品的协同过滤。所谓人以群分,就是我们可以将与该用户相似的用户喜欢过的物品推荐给该用户(而该用户未曾操作过),这就是基于用户的协同过滤。具体思想可以参考下面的图1。

图1:”物以类聚,人以群分“的朴素协同过滤召回算法
协同过滤的核心是怎么计算物品之间的相似度以及用户之间的相似度。我们可以采用非常朴素的思想来计算相似度。我们将用户对物品的评分(或者隐式反馈,如点击、收藏等)构建如下用户行为矩阵(见下面图2),矩阵的某个元素代表某个用户对某个物品的评分(如果是隐式反馈,值为1),如果某个用户对某个物品未产生行为,值为0。其中行向量代表某个用户对所有物品的评分向量,列向量代表所有用户对某个物品的评分向量。有了行向量和列向量,我们就可以计算用户与用户之间、物品与物品之间的相似度了。具体来说,行向量之间的相似度就是用户之间的相似度,列向量之间的相似度就是物品之间的相似度。
在真实业务场景中用户数和物品数一般都是很大的(用户数可能是百万、千万、亿级,物品可能是十万、百万、千万级),而每个用户只会操作过有限的物品,所以用户行为矩阵是稀疏矩阵。正因为矩阵是稀疏的,我们进行相似度计算及为用户做召回会更加简单。

图2:用户对物品的操作行为矩阵
相似度的计算可以采用cosine余弦相似度算法来计算两个向量(可以是上图的中行向量或者列向量)之间的相似度:
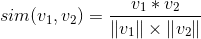
计算完了用户(行向量)或者物品(列向量)之间的相似度,那么下面说说怎么为用户做个性化召回。
8.4.1 基于用户的协同过滤
根据上面算法思想的介绍,我们可以将与该用户最相似的用户喜欢的物品作为该用户的召回。这就是基于用户的协同过滤的核心思想。
用户u对物品s的喜好度sim(u,s)可以采用如下公式计算,其中U是与该用户最相似的用户集合(我们可以基于用户相似度找到与某用户最相似的K个用户,具体实现方案可以采用上一章中Spark分布式实现的思路),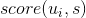 是用户对物品s的喜好度(对于隐式反馈为1,而对于非隐式反馈,该值为用户对物品的评分),
是用户对物品s的喜好度(对于隐式反馈为1,而对于非隐式反馈,该值为用户对物品的评分),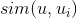 是用户与用户u的相似度。
是用户与用户u的相似度。

有了用户对每个物品的评分,基于评分降序排列,就可以取评分最大的topN的物品作为该用户的召回了。
8.4.2 基于物品的协同过滤
类似地,通过将用户操作过的物品最相似的物品作为该用户的召回,这就是基于物品的协同过滤的核心思想。
用户u对物品s的喜好度sim(u,s)可以采用如下公式计算,其中S是所有用户操作过的物品的列表,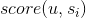 是用户u对物品的喜好度,
是用户u对物品的喜好度,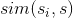 是物品与s的相似度。
是物品与s的相似度。
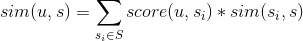
有了用户对每个物品的评分,基于评分降序排列,就可以取相似度最大的topN物品作为该用户的召回结果。
前面也说明了怎么计算物品之间的相似度,那么可以通过计算每个物品最相似的N个物品获得物品关联物品的召回结果,这里不细说。
从上面的介绍中我们可以看到,协同过滤算法思路非常直观易懂,计算公式也相对简单,也易于工程实现,同时该算法也不依赖于用户及物品的其它metadata信息。协同过滤算法在推荐系统发展的早些年被Netflix、Amazon等大的互联网公司证明效果非常好,能够为用户推荐新颖性的物品,所以一直以来都在工业界得到非常广泛的应用,即使是在现在,也常用作召回算法。
关于协同过滤算法的具体实现,作者之前开源过一个基于Netflix Prize竞赛数据集的完整实现方案,读者可以参考一下,具体地址为https://github.com/liuq4360/recommender_systems_abc。基于Spark来实现的原理也非常简单,作者在出版的专著《构建企业级推荐系统:算法、工程实现与案例分析》这本书的4.3、4.4节有详细的思路说明,读者可以参考一下。关于协同过滤的论文,读者可以阅读参考文献3、4、5。
8.5 矩阵分解召回算法
我们在8.4协同过滤算法这一节中讲过,用户操作行为可以转化为用户行为矩阵(参见图2)。其中是用户 i 对物品 j 的评分,如果是隐式反馈,值为0或者1(隐式反馈也可以通过一定的策略转化为得分),本文我们主要用显示反馈(用户的真实评分)来讲解矩阵分解召回算法。下面分别讲解矩阵分解算法的核心思想、原理和求解方法。
8.5.1 矩阵分解召回算法的核心思想
矩阵分解算法是将用户评分矩阵分解为两个矩阵、的乘积。
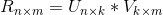
其中,代表的用户特征矩阵,代表物品特征矩阵。
某个用户对某个物品的评分,就可以采用矩阵对应的行(该用户的特征向量)与矩阵对应的列(该物品的特征向量)的乘积。有了用户对物品的评分列表就,很容易为用户做召回了。具体来说,可以采用如下计算方法为用户进行召回:
首先可以将用户特征向量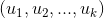 乘以物品特征矩阵,最终得到用户对每个物品的评分
乘以物品特征矩阵,最终得到用户对每个物品的评分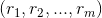 。
。
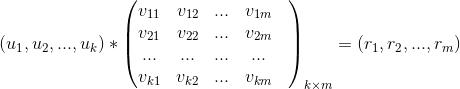
图3:为用户计算所有物品评分
得到用户对物品的评分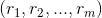 后,从该评分中过滤掉用户已经操作过的物品,针对剩下的物品得分做降序排列取topN作为该用户的召回结果。
后,从该评分中过滤掉用户已经操作过的物品,针对剩下的物品得分做降序排列取topN作为该用户的召回结果。
有了矩阵分解,类似上面的用户召回,我们也可以做基于物品关联物品的召回,比如我们要对第i个物品召回最相似的物品,就可以用物品特征矩阵的第i列与该矩阵相乘,得到跟物品i相似的所有物品的相似向量(下面图4最右边的向量),然后剔除掉自身(即剔除掉第i个分量),对剩余的相似度进行降序排列就可以获得物品i最相似的topN个物品作为召回结果。
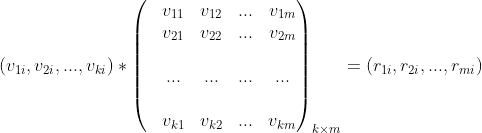
图4:为物品计算相似度
矩阵分解算法的核心思想是将用户行为矩阵分解为两个低秩矩阵的乘积,通过分解,我们分别将用户和物品嵌入到了同一个k维的向量空间(k一般很小,几十到上百),用户向量和物品向量的内积代表了用户对物品的偏好度。所以,矩阵分解算法本质上也是一种嵌入方法(我们在下一章中会介绍嵌入方法)。
上面提到的k维向量空间的每一个维度是隐因子(latent factor),之所以叫隐因子,是因为每个维度不具备与现实场景对应的具体的可解释的含义,所以矩阵分解算法也是一类隐因子算法。这k个维度代表的是某种行为特性,但是这个行为特性又是无法用具体的特征解释的,从这点也可以看出,矩阵分解算法的可解释性不强,我们比较难以解释矩阵分解算法为什么这么召回。
矩阵分解的目的是通过机器学习的手段将用户行为矩阵中缺失的数据(用户没有评分的元素)填补完整,最终达到可以为用户做推荐的目的,下面我们简单说明一下具体的算法原理。
8.5.2 矩阵分解召回算法的原理
前面只是很形式化地描述了矩阵分解算法的核心思想,下面我们来详细讲解怎么将矩阵分解问题转化为一个机器学习问题,从而方便我们训练机器学习模型、求解该模型,具备最终为用户做召回的能力。
假设所有用户有评分的对(代表用户,代表物品)组成的集合为,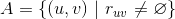 ,通过矩阵分解将用户和物品嵌入k维隐式特征空间的向量分别为:
,通过矩阵分解将用户和物品嵌入k维隐式特征空间的向量分别为:
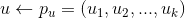
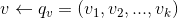
那么用户对物品的预测评分为 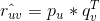 ,真实值与预测值之间的误差为
,真实值与预测值之间的误差为 。如果预测得越准,那么越小,针对所有用户评分过的对,如果我们可以保证这些误差之和尽量小,那么有理由认为我们的预测是精准的。
。如果预测得越准,那么越小,针对所有用户评分过的对,如果我们可以保证这些误差之和尽量小,那么有理由认为我们的预测是精准的。
有了上面的分析,我们就可以将矩阵分解转化为一个机器学习问题。具体地说,我们可以将矩阵分解转化为如下等价的求最小值的最优化问题。

公式2:矩阵分解等价的最优化问题
其中是超参数,可以通过交叉验证等方式来确定, 是正则项,避免模型过拟合。通过求解该最优化问题,我们就可以获得用户和物品的特征嵌入(用户的特征嵌入,就是上一节中用户特征矩阵的行向量,同理,物品的特征嵌入就是物品特征矩阵的列向量),有了特征嵌入,基于8.5.1节的思路,就可以为用户进行个性化召回了,也可以为物品进行物品关联物品的召回了。
是正则项,避免模型过拟合。通过求解该最优化问题,我们就可以获得用户和物品的特征嵌入(用户的特征嵌入,就是上一节中用户特征矩阵的行向量,同理,物品的特征嵌入就是物品特征矩阵的列向量),有了特征嵌入,基于8.5.1节的思路,就可以为用户进行个性化召回了,也可以为物品进行物品关联物品的召回了。
8.5.3 矩阵分解召回算法的求解方法
对于上一节讲到的最优化问题,在工程上一般有两种求解方法,SGD(Stochastic Gradient Descent)和ALS(Alternating Least Squares)。下面我们分别讲解这两种方法的实现原理。
假设用户对物品的评分为,嵌入k维隐因子空间的向量分别为,我们定义真实评分和预测评分的误差为,公式如下:
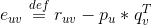
我们可将公式1写为如下函数
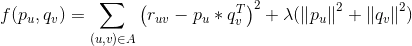
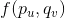 对求偏导数,具体计算如下:
对求偏导数,具体计算如下:
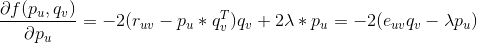
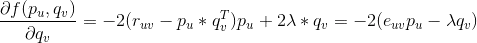
有了偏导数,我们沿着导数(梯度)相反的方向更新,最终我们可以采用如下公式来更新。

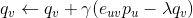
上式中为步长超参数,也称为学习率(导数前面的系数2可以吸收到参数中),取大于零的较小值。先可以随机取值,通过上述公式不断更新,直到收敛到最小值(一般是局部最小值),最终求得所有的。
SGD方法一般可以快速收敛,但是对于海量数据的情况,单机无法承载这么大的数据量,所以在单机上是无法或者在较短的时间内无法完成上述迭代计算的,这时我们可以采用ALS方法来求解,该方法可以非常容易地进行分布式拓展。
ALS(Alternating Least Squares)方法是一个高效的求解矩阵分解的算法,目前Spark MLlib中的协同过滤算法就是基于ALS求解的矩阵分解算法,它可以很好地拓展到分布式计算场景,轻松应对大规模训练数据的情况(参考文献6中有ALS分布式实现的详细说明)。下面对ALS算法原理做一个简单介绍。
ALS算法的原理基本就是它的名字表达的意思,通过交替优化求得极小值。一般过程是先固定,那么公式2就变成了一个关于的二次函数,可以作为最小二乘问题来解决,求出最优的后,固定,再解关于的最小二乘问题,交替进行直到收敛。
对工程实现感兴趣的读者可以参考Spark ALS算法的源码。开源的框架implicit(https://github.com/benfred/implicit)是一个关于隐式反馈矩阵分解的算法库,读者也可以使用,作者之前使用过,效果还是不错的。这里提一下,关于隐式反馈进行推荐的论文读者可以看看参考文献7,Spark ALS算法正是基于该论文的思路实现的。另外,开源的Python推荐库Surprise(https://github.com/NicolasHug/Surprise)中也有矩阵分解的实现,大家也可以参考。
总结
本章讲解了5类最基本的推荐召回算法的原理和具体工程实现思路。这5个算法实现原理都非常简单易懂,计算过程简单,也易于工程实现,它们在推荐系统发展史上有着举足轻重的地位,即使到现在,也会经常用于推荐系统召回业务中,所以读者需要掌握它们的基本原理,并能在实际项目中灵活运用。下一章我们会讲解基于嵌入方法和深度学习方法的召回算法。
参考文献
A Bayesian model for collaborative filtering
Collaborative filtering with the simple Bayesian classifier
Item-based collaborative filtering recommendation algorithms
item-based top-n recommendation algorithms
Collaborative filtering for implicit feedback datasets
Large-Scale Parallel Collaborative Filtering for the Netflix Prize
Collaborative Filtering for Implicit Feedback Datasets
大家如果想更全面学习推荐系统,可以购买作者之前出版的图书,购买链接如下:
















 2155
2155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











