







海量数据去重的应用场景有很多,例如在使用word文档的时候,如何判断某个单词是否拼写正确;网络爬虫程序,如何不去爬取相同的url页面;垃圾邮件过滤等。这就涉及到了海量数据去重。
我们将问题简化:
‘如何从海量数据中查询某字符串是否存在。’
常用查询数据结构
set and map
- C++ STL中的set和map都可以用来进行查询。他们都是采用红黑树来实现的,增删查改的事件复杂度为o(logn),这里不多展开介绍
- 优点:存储效率高,访问速度高
- 缺点:对于数据量大且查询字符串比较场且查询字符串相似时将会是噩梦
unordered_map
- STL中的unorderd_map<string, bool>采用的时hashtable实现的,其构成为数组+hash函数
- 常用hash函数:murmurhash1、murmurhhash2、murmurhash3、siphash、cityhash等。
- hash聚集现象解决方案参考——双重哈希(利用互质)

- 优点:访问速度快,无需字符串比较
- 缺点:存储效率不高,空间换事件,hash函数需要好好选择,避免冲突
小结
红黑树和hashtable都不能解决海量数据问题,因为他们需要存储。所以我们需要一个不需要存key且拥有hashtable的优点,这就用到了布隆过滤器
布隆过滤器
- 定义:布隆过滤器是一种概率型的数据结构,采用bit map的形势。其特点就是高效的插入和查询。能明确的告诉你查询的东西一定不存在或可能存在。
- 布隆过滤器不支持删除~
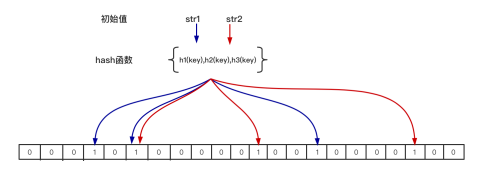
- 组成:bit map + n 个hash函数
- 原理:当一个元素加入位图的时候,通过k个hash将这个元素映射到位图的k个点,并将他们置1,当检索时,就通过这种方式计算k个点是否都为1,如果有不为1的点,则该元素一定不存在。如果都为1,则可能存在(会有误差)
-
在位图中每个槽位只有两种状态,0或1,但我们不知道其被置位了多少次,所以是不支持删除操作的。
-
在实际应用中,布隆过滤器如何使用,如何选择位图大小、hash函数个数、如何控制假阳率?

可以在下面的这个链接去选择合适的值
https://hur.st/bloomfilter
- 例如
n = 4000
p = 0.000000001
m = 172532
k = 30


‘在实际应用中,我们就确定n和p,通过计算得出m和k’。
那么如何选择k个hash?我们可以参考双重hash的打思路
//采用一个hash函数
uint64_t hash1 = MurmurHash2_x64(key, len, Seed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < k; i++){
Pos[i] = (hash1 + i*hash2)%m // n为位图大小,Pos为计算出来的位置数组
}
布隆过滤器的应用——缓存穿透
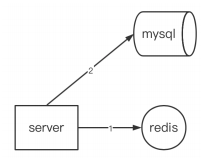
- 缓存场景:为了减轻落盘数据库的访问压力,在server和mysql之间加入已从缓存中间件(用于存在热点数据)
- 缓存穿透场景:如上图,server端疯狂向数据库请求数据,该数据在redis和mysql中都没有,数据请求的压力就全部涌向mysql
- 解决方案:
- 在redis中设置<key, null>键值对,以此避免访问mysql,缺点是这种键值对过多占内存。且如果频繁变换一个不存在的key,也会穿透。 所以这样的方案,还要给key设置一个超时时间,由redis自动清除这种无用的key
- 在server端设置一个布隆过滤器,将mysql包含的key放入布隆过滤器中;布隆过滤器可以过滤一定不存在的数据。















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









