







MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
一、MapReduce核心思想
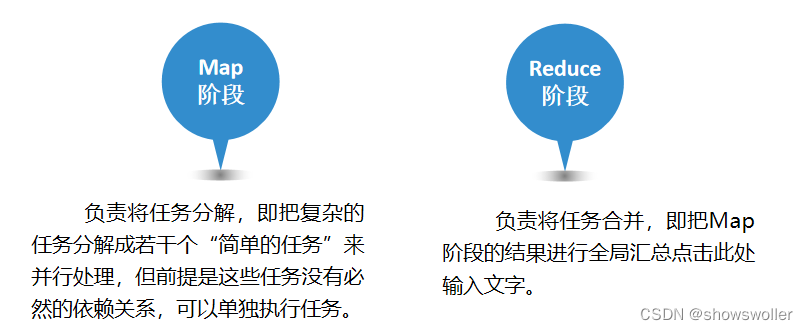
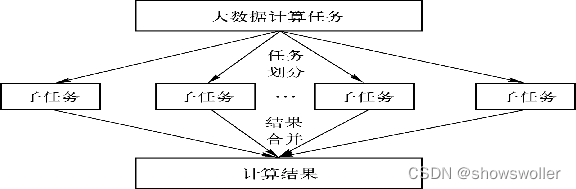
MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果,这种思想来源于日常生活与工作时的经验,同样也完全适合技术领域。任务分解的前提是这些任务没有必然的依赖关系,可以单独执行任务,将结果合并,即把任务划分中的各个子任务的结果进行全局汇总
MapReduce作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段。
构架方面:以统一构架位开发人员隐藏系统层细节,程序员只需要集中于应用问题和算法本身,而不需要关注其他系统层的处理细节,大大减轻了开发人员开发程序的负担
该框架可负责自动完成以下系统底层相关的处理
1:计算任务的自动划分和调度
2:数据的自动化分布存储和划分
3:处理数据与计算任务的同步
4:结果数据的收集整理
5:系统通信 负载平衡 计算性能优化处理
6:处理系统节点出错检测和失效恢复
MapReduce就是“任务的分解与结果的汇总”。即使用户不懂分布式计算框架的内部运行机制,但是只要能用Map和Reduce思想描述清楚要处理的问题,就能轻松地在Hadoop集群上实现分布式计算功能。
二、MapReduce编程模型
MapReduce是一种编程模型,用于处理大规模数据集的并行运算。使用MapReduce执行计算任务的时候,每个任务的执行过程都会被分为两个阶段,分别是Map和Reduce,其中Map阶段用于对原始数据进行处理,Reduce阶段用于对Map阶段的结果进行汇总,得到最终结果。

三、MapReduce工作过程
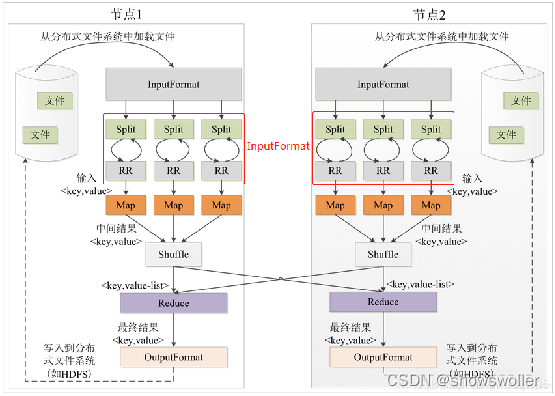
包括输入和拆分-执行map-执行Shuffle过程-执行Reduce-写入文件 五个步骤
四、MapReduce编程组件
MapReduce编程组件主要有以下六种
InputFormat组件:主要用于描述输入数据的格式,它提供两个功能,分别是数据切分和为Mapper提供输入数据。
Mapper组件:Hadoop提供的Mapper类是实现Map任务的一个抽象基类,该基类提供了一个map()方法。
OutputFormat组件:OutputFormat是一个用于描述MapReduce程序输出格式和规范的抽象类。
Reducer组件:Map过程输出的键值对,将由Reducer组件进行合并处理,最终的某种形式的结果输出。
Combiner组件:Combiner组件的作用就是对Map阶段的输出的重复数据先做一次合并计算,然后把新的(key,value)作为Reduce阶段的输入。
Partitioner组件:Partitioner组件可以让Map对Key进行分区,从而可以根据不同的key分发到不同的Reduce中去处理,其目的就是将key均匀分布在ReduceTask上
五、MapReduce工作原理
MapReduce作业的执行设计四个独立的实体
1:Jobclient:编写MapReduce客户端程序,配置作业和提交作业,是开发人员需要完成的工作
2:JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行
3:TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务,TaskTracker与JobTracker的不同是在执行任务时TaskTracker可以有多个,JobTracker只会有一个
4:HDFS:保存作业的数据,配置信息等等,最后的结果也保存在HDFS上面
创作不易 觉得有帮助请点赞关注收藏~~~
















 2527
2527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











