






前言:先确定Mysql服务开启正常,确认时间是否匹配
一:导入数据
1. RDBMS(关系型数据库,如mysql)到HDFS
需求一(全部导入):将mysql数据库test1的表stu1的数据全部导入到hadoop的/user/student下
sqoop import \ //导入命令 ,其中 \表示跨行写,为了直观
--connect jdbc:mysql://192.168.223.110:3306/test1 \ //数据库驱动
--username root \ //用户名
--password 123456 \ //密码
--table stu1 \ //数据来源表
--target-dir /user/student \ //目标路径
--delete-target-dir \ //目标存在则删除
--num-mappers 1 \ //可简写为 --m 1
--fields-terminated-by "\t" //hdfs导入的数据以”\t”分隔符分隔
查看导入是否成功:
hadoop fs -cat /user/student/*
需求二(查询导入):将mysql表中stu1的数据按条件查询处理的结果导入到hadoop 的/user/student1下
sqoop import \
--connect jdbc:mysql://192.168.223.110:3306/test1 \
--username root \
--password 123456 \
--target-dir /user/student1 \
--delete-target-dir \
--m 1 \
--fields-terminated-by "\t" \
--query 'select id,name,age,address from stu1 where age>18 and $CONDITIONS;'
//注意:sql语句末尾必须加上$CONDITIONS
查看结果:
hadoop fs -cat /user/student1/*;
需求三(导入指定列):将mysql表中stu1的id,name导入到hadoop的/user/student2下
sqoop import \
--connect jdbc:mysql://192.168.223.110:3306/test1 \
--username root \
--password 123456 \
--target-dir /user/student2 \
--delete-target-dir \
--m 1 \
--fields-terminated-by "\t" \
--columns id,name \
--table stu1
查看结果:
hadoop fs -cat /user/student2/*;
需求四(使用sqoop关键字筛选查询导入数据):将表中id=2的用户导入…/student3下
sqoop import \
--connect jdbc:mysql://192.168.223.110:3306/test1 \
--username root \
--password 123456 \
--target-dir /user/student3 \
--delete-target-dir \
--m 1 \
--fields-terminated-by "\t" \
--where "id=2" \
--table stu1
查看结果:
hadoop fs -cat /user/student3/*;
2. RDBMS(关系型数据库,如mysql)到Hive
方式一(不推荐):将mysql的test1数据库下表stu1的数据导入到hive中db_order数据库的stu01表中
sqoop import \
--connect jdbc:mysql://192.168.223.110:3306/test1 \
--username root \
--password 123456 \
--table stu1 \
--m 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-database db_order \
--hive-table stu01 \
--delete-target-dir
在hive的db_order数据下查看结果:
select * from stu01;
方式二(建议使用):使用1.1的方式先将mysql导入到hdfs,然后再hive里使用下面代码即可导入
load data inpath '/user/student1' into table hive 'stu01';
二:导出数据
1. HDFS到RDBMS(关系型数据库,如mysql)
需求:将hadoop里的/user/students1.txt的数据导出到mysql的表stu1
sqoop export \
--connect "jdbc:mysql://192.168.223.110:3306/test1?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--export-dir /user/students1.txt \
--table stu1 \
--m 1 \
--input-fields-terminated-by ","
提示:Mysql中如果表不存在,不会自动创建
如果mysql的表中存在数据,那么该数据会追加在后面
2. Hive到RDBMS(关系型数据库,如mysql)
需求:将hive里的数据/user/hive/warehouse/db_order.db/stu1/students1.txt导入到mysql的表stu1中
sqoop export \
--connect jdbc:mysql://192.168.223.110:3306/test1 \
--username root \
--password 123456 \
--export-dir /user/hive/warehouse/db_order.db/stu1/students1.txt \
--table stu1 \
--m 1 \
--input-fields-terminated-by ","
乱码解决:
上面的情况用于不包含中文时,如果包含中文,很可能出现中文乱码,
这时需要在mysql处查看编码格式:
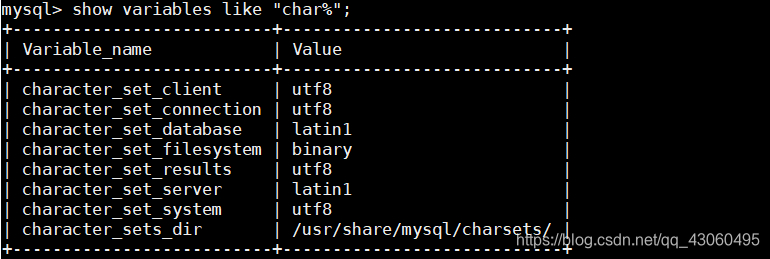
可用看到database与server都采用了latin1编码,不支持中文,我们需要将它修改为utf-8
set character_set_database=utf8;
set character_set_server=utf8;
还需查看
show variables like 'collation_%';
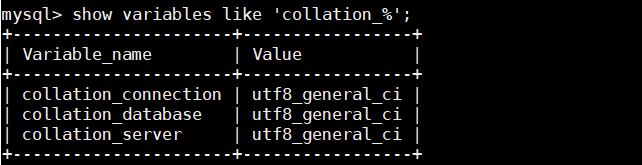
这时将mysql的编码改过来了,但是之前创建的表格式还是没变,我们需修改修改表的编码格式
alter table stu1 convert to character set utf8 collate utf8_general_ci;
这时再执行有中文的导出操作时,mysql的结果就不会乱码了
sqoop export \
--connect "jdbc:mysql://192.168.223.110:3306/test1?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--export-dir /user/hive/warehouse/db_order.db/stu1/students1.txt \
--table stu1 \
--m 1 \
--input-fields-terminated-by ","
注意:该修改编码只是临时的,当你再次登录mysql时,就又恢复系统默认的编码格式了,我们可用修改/etc/my.cnf文件,使其永久生效
vi /etc/my.cnf
--------添加如下内容------------------------------
[mysql]
default-character-set=utf8
[client]
default-character-set=utf8
[mysqld]
character-set-server=utf8
character-set-database=utf8
init_connect='SET NAMES utf8'
这时,再重启mysql服务,再登录mysql,查看编码格式
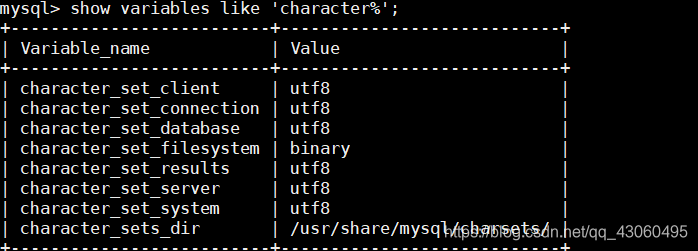
如果是这样,说明修改成功了。
三:脚本打包
- 创建一个.opt文件
mkdir opt
- 编写导出sqoop脚本
vi opt/export.opt
内容如下:将hadoop的内容导出到mysql的表stu1下
export
--connect
jdbc:mysql://192.168.223.110:3306/test1?useUnicode=true&characterEncoding=utf-8
--username
root
--password
123456
--m
1
--export-dir
/user/students1.txt
--table
stu1
--input-fields-terminated-by
","
- 在sqoop的解压路径下(bin的上一级路径下)执行该脚本
bin/sqoop --options-file /root/opt/export.opt
- 编写导入sqoop脚本
vi opt/import.opt
内容如下:(需求)将表stu1的数据导入到hadoop的user/student下
import
--connect
jdbc:mysql://192.168.223.110:3306/test1
--username
root
--password
123456
--table
stu1
--num-mappers
1
--delete-target-dir
--target-dir
/user/student
--input-fields-terminated-by
","
- 在sqoop的解压路径下(bin的上一级路径下)执行该脚本
bin/sqoop --options-file /root/opt/import.opt














 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









