







综述:
Mysql索引底层采用的是B树和B+树来实现。那为什么是B树和B+树而不是其他诸如数组、链表、平衡二叉树这些数据结构呢?下面来学习。
1、数据库文件存储方式
数据库文件都是以磁盘文件存储在系统中的,这也是数据库能够持久化存储数据的原因。
2、从数据库读取数据的原理
从数据库中读取数据,先不考虑从缓存中读取的情况,那就是直接从磁盘文件中读取数据,我们都知道,从磁盘文件中读取数据是十分耗时的,数据库select的时间取决于执行磁盘IO的次数,所以减少磁盘IO就可以显著提高读取数据的速度。
3、减少磁盘IO操作的影响因素
磁盘IO与预读:
磁盘读取分为分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,这个成本是访问内存的十万倍左右;正是由于磁盘IO是非常昂贵的操作,所以计算机操作系统对此做了优化:预读;每一次IO时,不仅仅把当前磁盘地址的数据加载到内存,同时也把相邻数据也加载到内存缓冲区中。 因为局部预读原理说明:当访问一个地址数据的时候,与其相邻的数据很快也会被访问到。每次磁盘IO读取的数据我们称之为一页(page)。一页的大小与操作系统有关,一般为4k或者8k。这也就意味着读取一页内数据的时候,实际上发生了一次磁盘IO。
正因为有了磁盘IO预读机制,所以才有了减少磁盘IO的可能,因为一次磁盘IO操作,可以查找到物理存储中相邻的一大片数据。
一次磁盘IO操作可以取出物理存储中相邻的一大片数据,如果查询的索引数据(就是B+树中从根节点一直到叶子节点整个过程中查询的节点数)都集中在该区域,那么只需要一次磁盘IO,否则就需要多次磁盘IO。
4、数据库中使用什么数据结构作为索引
①、链表,链表的查询速度是O(N),每次查询都得从链表头开始查询,如果有数据10000条,目标数据在第5000行,则每次都会从头开始遍历5000次才读取到。
②、数组,数组的查询速度是O(1),查询速度确实很快,但是对于数组来说Insert、Update、Delete等就显得很乏力了;而且另一个不使用数组的原因是索引是存储在磁盘中的,当索引非常大的时候无法一次加载到内存中。
③、平衡二叉树,二叉查找树查询的时间复杂度是O(logN),查找速度最快和比较次数最少,既然性能已经如此优秀,但为什么实现索引是使用B-Tree而不是二叉查找树,关键因素是磁盘IO的次数。
④、B树和B+树,数据库索引采用的数据结构。
B树和B+树阅读:BTree和B+Tree详解
5、为什么数据库选B-tree或B+tree而不是二叉树作为索引结构
阅读:为什么数据库选B-tree或B+tree而不是二叉树作为索引结构
推荐阅读:深入理解数据库索引采用B树和B+树的原因
6、聚簇索引与非聚簇索引
MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,分别实现了非聚簇索引和聚簇索引。
聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序;
非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。
在索引的分类中,我们可以按照索引的键是否为主键来分为“主索引”和“辅助索引”,使用主键键值建立的索引称为“主索引”,其它的称为“辅助索引”。因此主索引只能有一个,辅助索引可以有很多个。
MyISAM——非聚簇索引
- MyISAM存储引擎采用的是非聚簇索引,非聚簇索引的主索引和辅助索引几乎是一样的,只是主索引不允许重复,不允许空值,他们的叶子结点的key都存储指向键值对应的数据的物理地址。
- 非聚簇索引的数据表和索引表是分开存储的。
- 非聚簇索引中的数据是根据数据的插入顺序保存。因此非聚簇索引更适合单个数据的查询。插入顺序不受键值影响。
InnoDB——聚簇索引
- 聚簇索引的主索引的叶子结点存储的是键值对应的数据本身,辅助索引的叶子结点存储的是键值对应的数据的主键键值。因此主键的值长度越小越好,类型越简单越好。
- 聚簇索引的数据和主键索引存储在一起。
- 聚簇索引的数据是根据主键的顺序保存。因此适合按主键索引的区间查找,可以有更少的磁盘I/O,加快查询速度。但是也是因为这个原因,聚簇索引的插入顺序最好按照主键单调的顺序插入,否则会频繁的引起页分裂,严重影响性能。
- 在InnoDB中,如果只需要查找索引的列,就尽量不要加入其它的列,这样会提高查询效率。
使用主索引的时候,更适合使用聚簇索引,因为聚簇索引只需要查找一次,而非聚簇索引在查到数据的地址后,还要进行一次I/O查找数据。
因为聚簇辅助索引存储的是主键的键值,因此可以在数据行移动或者页分裂的时候降低成本,因为这时不用维护辅助索引。但是由于主索引存储的是数据本身,因此聚簇索引会占用更多的空间。
聚簇索引在插入新数据的时候比非聚簇索引慢很多,因为插入新数据时需要检测主键是否重复,这需要遍历主索引的所有叶节点,而非聚簇索引的叶节点保存的是数据地址,占用空间少,因此分布集中,查询的时候I/O更少,但聚簇索引的主索引中存储的是数据本身,数据占用空间大,分布范围更大,可能占用好多的扇区,因此需要更多次I/O才能遍历完毕。
下图可以形象的说明聚簇索引和非聚簇索引的区别
从上图中可以看到聚簇索引的辅助索引的叶子节点的data存储的是主键的值,主索引的叶子节点的data存储的是数据本身,也就是说数据和索引存储在一起,并且索引查询到的地方就是数据(data)本身,那么索引的顺序和数据本身的顺序就是相同的;
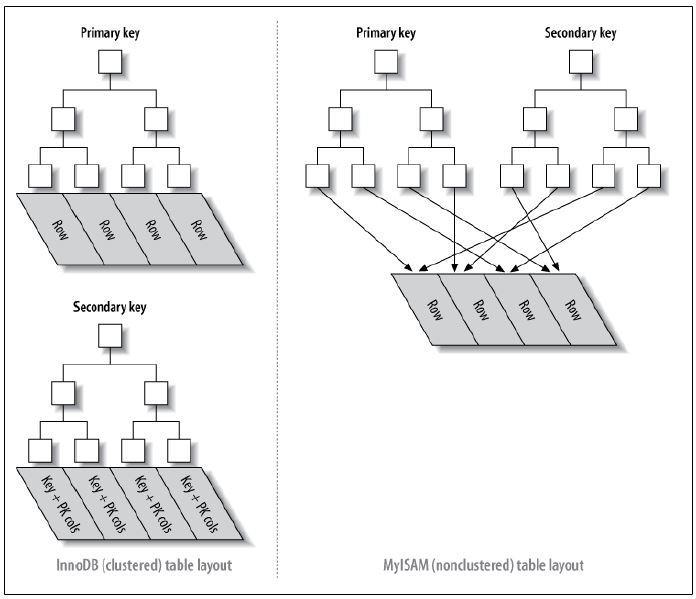
而非聚簇索引的主索引和辅助索引的叶子节点的data都是存储的数据的物理地址,也就是说索引和数据并不是存储在一起的,数据的顺序和索引的顺序并没有任何关系,也就是索引顺序与数据物理排列顺序无关。
参考文章:深入理解MySQL索引原理和实现——为什么索引可以加速查询?
关于索引的基础知识:mysql基础知识之索引















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









