







前言
之前有段工作经历涉及到了chat相关,而消息的发送 -> 存储 -> 消费是由不同的团队负责的,因此消息如何再多个团队之间流通、以及通过什么介质传递都是需要考虑的问题。
之前我负责过一些消息消费的相关工作,消息发送团队将消息推送到kafka之后,由我们去订阅topic并消费对应的分区,拿到消息之后做对应的消息类型解析、消息发送双方可见性分析、接收方未读数、推送等业务处理。本文旨在记录之前工作中遇到的相关问题以及从consumer端如何优化处理。
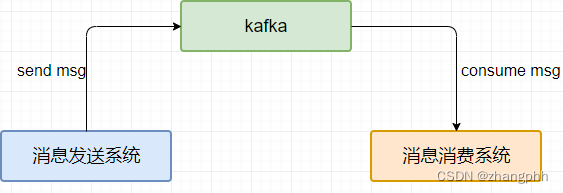
可以看到,消息系统中引入了kafka,因此如果kafka出现问题,那整个系统都会出现问题。
顺序问题
1、为什么要保证消息的顺序
我们之所以能够回复对方发过来的消息的依据就是对方消息内容,因此对于chat系统来说,消息的顺序性是必须要求保证的硬核标准,如果消息乱序,那这个chat系统可以说是完全报废。因此对于chat系统来说必须要保证消息的顺序性 。
2、如何保证消息的顺序性
众所周知,kafka有topic的概念,每个topic可以拥有多个分区(partition),而每个分区的内部都是有序的
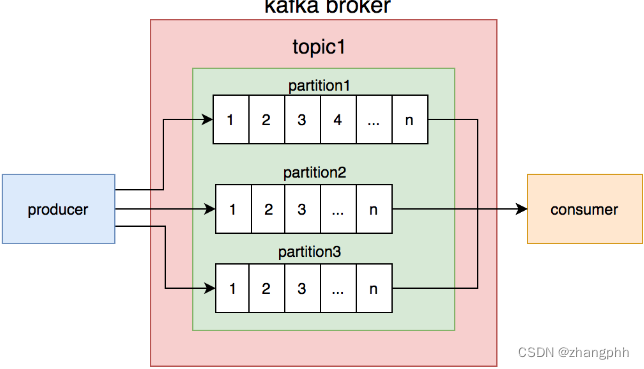
如此一来,如何保证消息的顺序性思路就比较清晰了,完全可以利用partition的特性去做处理,按照一定的规则将消息写到不同的partition中去,然后消费者消费partition中的消息。
思考这样一个问题:写到partition中的消息要按照什么规则去做呢?试想一下,我们要保证消息的顺序性,有序性是在同一会话的前提下,也就是说不同会话之前不需要保证消息的顺序性,因此我们可以把conversationId去做如取余或哈希操作,将同一个partition会话的消息全都放入一个partition中。

消息积压
上述一期方案上线后在项目初期运行一段时间基本没问题,但随着产品推广用户量激增,上述消费架构就出现了问题:消息接收方受消息不够实时,延迟比较高,这对用户来说十分不友好,本来10秒钟几句话的事,到现在可能延迟有1分钟,这谁能忍得了啊。
虽然可以通过水平扩展增加机器数量来缓解压力,但这不是最优的方案,而且最主要是费钱。
优化思路
1、消息体
思考下kafka消息发送到消息消费共经历了几次IO?
- 从producer到broker经历一次网络IO
- broker落盘经历一次磁盘IO
- consumer从broker取数据时经历一次网络IO
- broker从磁盘拿数据经历一次磁盘IO
一共经历四次IO,引用一张如图说明

因此这里有个优化思路就是减少消费者取数据时broker从磁盘取数据时经历的IO耗时,那该如何减少呢?
试想一下,假设消费者每次取500条数据,如果每条消息的消息体过大,那取500条数据经历IO耗时势必会增加,进而影响生产和消费速度。而且当消息体过大时,还有可能会导致磁盘空间不足的问题。
2、路由规则
排除消息体过大的原因之后,我们需要看下kafka是否存在lag,如果存在lag我们要从消费者端解决问题。
根据监控查看出现lag的具体的分区,如果是同一个topic的特定某几个分区出现lag,那就需要考虑下是不是路由规则不合理的问题。
一个例子就是对于点餐系统,如果路由规则是根据商家ID来做的,而某些商家订单量一直很大,恰巧这些商家的相关消息都路由到了同一个partition,就导致只有这个partition出现了lag,进而消息处理较慢。
针对这种路由不合理的问题,解决方案就是选择合理的路由规则或key,如上述点餐系统,可以考虑路由规则根据订单号来做,因为所有订单号都是基于同一套方案生成的,所以基本不会出现个别partition lag太高的情况。
而chat系统之前也说过路由规则是基于conversationId去做的,而conversationId也是基于相同的方案生成的,所以如果出现lag发生,那理论上会涉及到大多数partition都出现lag。
3、表过大
假设现在有1亿conversation存于一张表中,即使有索引,根据conversationId去查询对应会话信息的时候耗时也会很高,一条消息的消费原来可能只有500ms,但是现在可能需要5s甚至更久,因此,当数据量比较大时就要考虑分表了。
这里提供一种分表思路,基于conversatioId%100去做,或者是对1000取余。
4、数据库主从延迟
如果在生产环境数据库采用主从架构,主节点负责写,从节点负责读,在从broker拿到消息并完成解析拿到conversationId,这时候去会话团队拿数据,发现数据返回空,对应我们这边后续消费逻辑直接报错而返回,而会话团队根据conversationId去查是有这个会话的,这种情况第一次遇到时就显得很诡异。
后来进过分析发现,我们这边调接口时走的是会话团队数据库的从库,而主从同步还没将最新数据写到从库中。
发现问题后有两个解决方案:
- 直接读master节点,这种方案不太可取,这样slave节点只作为备份?而且master节点压力会变大,甚至垮掉,也就失去了主从架构原有的作用。
- 加入重试机制,读取到conversation为空时,将此消息加入到
重试表,在做后续处理。
5、并发消费
上述消费架构是一个分区有一个消费者,既然一个消费者消费速度太慢,那何不增加消费者的数量呢?因此优化思路就有了:
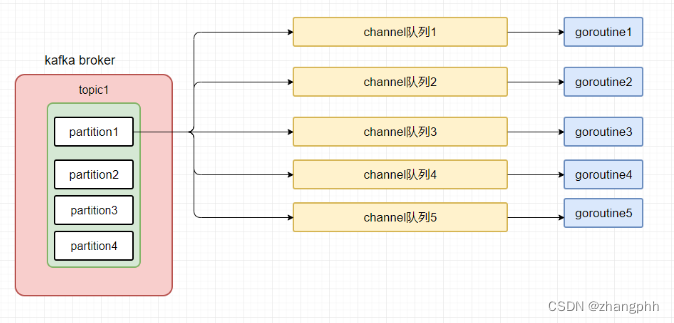
可以把每个partition中的消息按照conversationId%5然后放入到channel中,然后每个channel在配备一个goroutine去消费,这样既能保证同一会话消息的顺序性,又能提升消费速度尽量避免lag。

















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









