






 文章介绍了Kitsak提出的k-壳分解法在确定网络中节点位置的重要性,以及如何通过MATLAB实现该算法。后续研究探讨了基于k核分解过程中迭代信息的改进方法。
文章介绍了Kitsak提出的k-壳分解法在确定网络中节点位置的重要性,以及如何通过MATLAB实现该算法。后续研究探讨了基于k核分解过程中迭代信息的改进方法。
Kitsak 等人提出用 k-壳分解法(k-shell decomposition)确定网络中节点的位置,将外围的节点层层剥去,处于内层的节点拥有较高的影响力.。这一方法可看成是一种基于节点度的粗粒化排序方法。 具体分解过程如下: 网络中如果存在度为 1 的节点,,从度中心性的角度看它们就是最不重要的节点。如果把这些度为1的节点及其所连接的边都去掉, 剩下的网络中会新出现一些度为1的节点,再将这些度为1的节点去掉,,循环操作,直到所剩的网络中没有度为 1 的节点为止. 此时, 所有被去掉的节点组成一个层, 称为 1-壳(记 为 ks=1). 对一个节点来说, 剥掉一层之后在剩下的 网络中节点的度就叫该节点的剩余度. 按上述方法 继续剥壳, 去掉网络中剩余度为 2 的节点, 重复这些 操作, 直到网络中没有节点为止。MATLAB代码如下:
nodedegree=sum(A,2); %算出网络中每个节点的度,A为网络的邻接矩阵
ksindex=zeros(1,length(A)); %ksindex用来记录每个节点的核数
i=0;
while sum(ksindex~=0)~=length(A) %当所有节点的核数都已算出,则退出while循环
i=i+1;
while sum(ismember(1:i,nodedegree))~=0 %当核数为i的节点都已找到,则退出while循环
temp=(ksindex==0); %找出还未算出核数的节点
ksindex(find(nodedegree<=i&temp'))=i; %对还未算出核数的节点中度小于等于i的节点的核数赋值为i
A(find(nodedegree<=i&temp'),:)=zeros();
A(:,find(nodedegree<=i&temp'))=zeros(); %将刚找到的节点与其他节点的链接切开
nodedegree=sum(A,2); %重新统计节点的度
end
end
后面有学者根据k 核分解过程中产生的迭代信息来改进传统的k核分解方法、
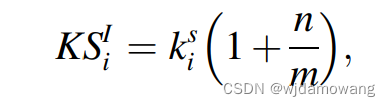
where n is the iteration of the removing process when removing vi, m is the total iteration number in the k-shell of vi.
matlab代码如下:
clc
clear
load('C:\Users\xs\Desktop\需要用的数据集\USAir.mat');
A=USAir;
nodedegree=sum(A,2);
ksindex=zeros(1,length(A)); %ksindex用来记录每个节点的核数
i=0;
M=zeros(1,100); %记录每轮都迭代了多少次,比如统计核数为1的节点迭代了一次
M1=zeros(1,length(A)); %记录每个节点属于哪轮
N=zeros(1,length(A)); %记录每个节点属于第几次迭代
while sum(ksindex~=0)~=length(A) %当所有节点的核数都已算出,则退出while循环
i=i+1;
j=0;
while sum(ismember(1:i,nodedegree))~=0 %当核数为i的节点都已找到,则退出while循环 这段代码逻辑有些问题
j=j+1;
temp=(ksindex==0); %找出还未算出核数的节点
ksindex(find(nodedegree<=i&temp'))=i; %对还未算出核数的节点中度小于等于i的节点的核数赋值为i
if j==1
temp1=find(nodedegree<=i&temp');
N(find(nodedegree<=i&temp'))=j;
M1(find(nodedegree<=i&temp'))=i;
M(i)=M(i)+1;
end
DDD=[];
for tt=1:length(temp1)
A(temp1(tt),:)=zeros();
A(:,temp1(tt))=zeros();
nodedegree=sum(A,2); %重新统计节点的度
temp=(ksindex==0); %找出还未算出核数的节点
ksindex(find(nodedegree<=i&temp'))=i; %对还未算出核数的节点中度小于等于i的节点的核数赋值为i
DDD=[DDD;find(nodedegree<=i&temp')];
end
N(DDD)=j+1;
M1(DDD)=i;
if ~isempty(DDD)
M(i)=M(i)+1;
end
temp1=find(ksindex~=0);
nodedegree=sum(A,2); %重新统计节点的度
end
end
for i=1:length(A)
iks(i)=ksindex(i)*(1+N(i)/M(M1(i)));
end
















 3822
3822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











