






File类基本操作
基本使用
程序执行磁盘文件处理操作流程图:

现在我们来看一段Java程序创建File实例的代码:
public class base01 {
public static void main(String[] args) {
File file = new File("F:\\test");
System.out.println(file.getName());
}
}
我们看到文件的路径是F:\\test,这是windows的文件路径模式,但是Java是跨平台编程的,所以他有的时候还需要在其他的系统上编写,那么这就涉及到文件路径的问题。
文件路径问题
Frist windows系统,文件路径分隔符是
Second Unix Linux MacOS AIX 的路径分隔符是 /
要是每次都要使用 // 或者是 \ 进行字符转义,会比较麻烦,所以File类使用File.separator进行提取系统分隔符的操作,一样可以执行。
File file = new File("F:" + File.separator + "test");
文件目录操作
接下来看一下下面这段代码:
public class base01 {
public static void main(String[] args) {
File file = new File("F:" + File.separator + "test" + File.separator + "test" + File.separator+ "demo.txt");
InputStream input = null;
try {
input = new FileInputStream(file);
System.out.println(file.getName());
} catch (IOException e) {
e.printStackTrace();
}
}
}
执行出现异常:
java.io.FileNotFoundException:
F:\Mytest\test\demo.txt (系统找不到指定的路径。)
这里的路径是自己瞎写的, 当然,我的系统当中不存在这个目录的,所以在执行的过程当中出现错误。
那么如何在文件不存在的时候创建目录呢??
目录操作
| 返回值 | 方法名称 | 实现功能 |
|---|---|---|
| boolean | mkdir | 创建单级目录 |
| boolean | mkdirs | 创建多级目录(包含子目录) |
| String | getParent | 得到父目录名称 |
| File | getParentFile | 得到父目录File对象 |
目录不存在问题
那么我们使用如下代码实现:
public class base01 {
public static void main(String[] args) throws IOException {
File file = new File("F:" + File.separator + "test" + File.separator + "test" + File.separator+ "demo.txt");
if(!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
if(!file.exists()) {
System.out.println("不存在,创建文件: " + file.createNewFile());
} else {
System.out.println("存在,删除文件: " + file.delete());
}
}
}
多线程效率问题
但是我们想,现在我们的代码都是每访问一次都判断一下是不是存在父目录,但是假如有很多的线程去访问这一功能,那么每次都检验一下父目录是否存在,这会影响程序的效率,最好的想法就是检验一次就可以了,一次检查,下一次访问就不进行检验了。那么可以使用静态代码块去实现。
public class base01 {
private static File file = new File("F:" + File.separator + "test" +
File.separator + "test" + File.separator+ "demo.txt");
static {
if(!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
}
public static void main(String[] args) throws IOException {
if(!file.exists()) {
System.out.println("不存在,创建文件: " + file.createNewFile());
} else {
System.out.println("存在,删除文件: " + file.delete());
}
}
}
这样的话,多个线程访问的时候也都是创建一次文件夹,这样就节省了一些时间,性能调优就是这样一点一点的慢慢的弄的。
获取文件信息
获取文件信息的方法……们
| 返回值 | 方法 | 实现功能 |
|---|---|---|
| boolean | canExecute | 文件是否可执行 |
| boolean | canRead | 文件是否可读 |
| boolean | canWrite | 文件是否可写 |
| File | getAbsoluteFile | 得到文件的绝对路径实例 |
| String | getName | 得到文件的名称 |
| boolean | isDirectory | 打开的文件是不是目录 |
| boolean | isFile | 是否是文件 |
| long | lastModified | 文件是否可读 |
| File[] | listFiles | 得到当前目录下的所有文件的实例 |
这些东西都是比较简单的,就试试怎么用就可以了。
现在举一个例子,当文件当中存在文件,那么如何实现全部读取,我么采用递归的方式来实现这个功能。
递归实现文件读取(解释都放在代码里面了)
public static void main(String[] args) throws IOException {
getDir(new File("F:" + File.separator + "test"));
}
public static void getDir(File file) {
if(file.isDirectory()) { //当打开的文件是目录,获取当前目录下的所有文件,之后递归判断
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
getDir(files[i]); //当打开的是文件,输出文件目录
}
} else {
System.out.println(file);
}
}
output:
F:\test\test\testfirst.txt
F:\test\test\testsecond.txt
F:\test\test\testthird.txt
F:\test\test01.txt
F:\test\test02.txt
F:\test\test03.txt
F:\test\test04.txt
F:\test\test05.txt
F:\test\test06.txt
F:\test\test07.txt
既然我可以写,那么我肯定也可以删除
public static void getDir(File file) {
if(file.isDirectory()) {
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
getDir(files[i]);
}
}
file.delete(); //删除目录下的其他文件之后,删除当前文件
}
文件更名
不多说,直接上代码:
public static void main(String[] args) throws IOException {
renameTest();
}
public static void renameTest() {
File oldFile = new File("F:" + File.separator + "test" + File.separator + "test01.txt");
File newFile = new File("F:" + File.separator + "test" + File.separator + "TEST01.txt");
oldFile.renameTo(newFile);
}
使用renameTo方法就行
Important Program一个批量更改的程序
业务背景:
假设我们之前在存文件的时候,存的格式是这样的:

但是这样的文件的格式都是不统一的,那么我们现在就要把他变成统一的, 来写一段代码:
public class FileFormat {
private int maxSequenceLen = 0; //得到等待改变位置的序列长度
private int maxFileLen = 0; //存储最大的文件名称长度
private String maxFileName; //储存最大文件的名称
public FileFormat(File file) {
init(file);
this.maxSequenceLen = this.maxFileName.substring(
this.maxFileName.lastIndexOf("-") + 1, this.maxFileName.lastIndexOf(".txt")
).length(); //获取最大的序列长度
rename(file);
}
//通过递归,对这个类进行初始化 获得最大长度的 满足固定格式的文件
private void init(File file) {
if(file.isDirectory()) {
System.out.println(file);
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
init(files[i]); //递归查找
}
} else {
if(file.isFile()) {
//使用正则表达式匹配需要修改的文件
if (file.getName().matches("\\d{17}\\-\\d+\\.txt")) {
System.out.println(file.getName());
getMaxFile(file.getName()); //获得最大的序列
}
}
}
}
//执行重命名的操作
public void rename(File file) {
if(file.isDirectory()) {
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
rename(files[i]);
}
} else {
if(file.isFile()) {
if(file.getName().matches("\\d{17}\\-\\d+\\.txt")) { //使用正则表达式匹配正确的文件名称
//字符串匹配,进行改名的操作
String oldName = file.getName().substring(file.getName().lastIndexOf("-") + 1, file.getName().lastIndexOf(".txt"));
String newName = file.getName().substring(0, file.getName().lastIndexOf("-") + 1) + getNewFileName(oldName) + ".txt";
File newFile = new File(file.getParentFile(), newName);
file.renameTo(newFile);
}
}
}
}
//得到最大的文件的名称
public void getMaxFile(String fileName) {
if(fileName.length() > this.maxFileLen) {
this.maxFileLen = fileName.length();
this.maxFileName = fileName;
}
}
//得到新的字符串
private String getNewFileName(String oldName) {
StringBuffer buffer = new StringBuffer(oldName);
while (buffer.length() < this.maxSequenceLen) {
buffer.insert(0, 0);
}
return buffer.toString();
}
}
### main 主函数 ####
public static void main(String[] args) throws IOException {
File file = new File("F:" + File.separator + "test" + File.separator + "files" + File.separator + "test1");
FileFormat format = new FileFormat(file);
}
这样执行之后,所有的文件都变成了下面这个样子:

字节流和字符流
流操作简介
流指的是数据的处理方式和目标内容的处理机制,所有的流都分为字符流和字节流。
基本上分为两种:
InputStream(字节输入流)、OutputStream(字节输出流)
Reader(字符输入流)、Writer(字符输出流)
无论是字节流和字符流,基本的操作流程都是一样的:
流操作步骤
1、通过File类寻找要操作的文件路径
2、使用字符流或者字节流的子类为父类对象进行实例化处理
3、记性读写流操作
4、流是很重要的资源,所以需要在使用完毕后关闭流
CPU和磁盘之间的数据交互
运行在CPU当中的程序需要数据的时候去请求内存,内存又从磁盘当中读取,当内存从磁盘中当中读取数据的时候,为了防止写入的数据过多,导致数据丢失(因为谁都不能保证在运行的过程当中,电脑不断电,断电的话, 内存数据会丢失),所以在中间加了一个缓冲区,数据经过缓冲区写入磁盘。并且内存从缓冲区当中可以更快速的读取数据。

字节输出流: OutPutStream
定义(详细代码就省略了,只写方法)
public abstract class OutputStream implements Closeable, Flushable {
//进行写入一个int的操作
public abstract void write(int b) throws IOException;
//写入一个byte数组
public void write(byte b[]) throws IOException {}
//写入byte数组,指定起始和结束的位置
public void write(byte b[], int off, int len) throws IOException {}
public void flush() throws IOException {}
public void close() throws IOException {}
}
OutputStream在JDK1.0就存在了,在JDK1,5去实现了Closeable, Flushable接口,那么继续看下去
Closeable接口定义
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}
Flushable接口定义
public interface Flushable {
void flush() throws IOException;
}
看OutputStream的定义结构,就可以知道,字节输出流全都是针对字节数据进行操作的,但是这是一个抽象类,所以需要依靠子类对它进行实例化,然后我们是对文件进行操作的,所以需要使用子类——文件输出流FileOutputStream对其进行实例化。
FileOutputStream的定义
继承流程图

在研究FileOutputStream类的时候,需要关注两个点
(1)抽象方法的实现
(2)子类构造实例化对象进行向上转型
FileOutputStream定义(只写几个我们感兴趣的方法)
public
class FileOutputStream extends OutputStream{
//构造函数参数File,根据文件得到输出流
public FileOutputStream(File file) throws FileNotFoundException {}
//append是true的时候,表示在文件后面增加信息
public FileOutputStream(File file, boolean append) throws FileNotFoundException { }
//写一个数字
public void write(int b) throws IOException { }
//写一个字符数组
public void write(byte b[]) throws IOException {}
//不解释了,OutputStream当中写了
public void write(byte b[], int off, int len) throws IOException {}
}
在这里FileOutputStream的一个构造方法当中有append参数,指定为true的时候表明你的write操作是在文件末尾增加的操作,来看一下效果是怎么样的。
public class base02_outputStream {
public static void main(String[] args) throws IOException {
File file = new File("F:" + File.separator + "test" + File.separator + "test02");
OutputStream outputStream = new FileOutputStream(file, true);
byte [] bytes = "Hello, this is FileOutputStream test".getBytes();
outputStream.write(bytes, 0, bytes.length);
outputStream.close();
}
}
文件当中的内容:
This is test02
Hello, this is FileOutputStream test
字节输入流: InputStream
这个类是针对字节数据输入的类,定义如下:
InputStream的定义(还是省略方法的具体实现细节)
public abstract class InputStream implements Closeable {
//读取操作方法
public abstract int read() throws IOException;
//读取数据到byte数组当中,返回读出的byte的长度,没有数据读出来返回-1
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
//读取到字符数组当中,指定读取的位置 没读出来返回-1
public int read(byte b[], int off, int len) throws IOException {}
//关闭的方法
public void close() throws IOException {}
}
和OutputStream的不同点是没有实现Flushable接口,是因为读取的时候不需要使用缓存区,缓存区存在的目的是防止过多的写入,导致数据丢失,写到缓存区当中,之后flush缓存区,写入到磁盘当中。但是读的过程当中不会出现这个问题,所以不需要实现Flusable接口。
在JDK8当中的方法都是比较正常的,但是在JDK11里面有个变态的方法:
| 返回类型 | 方法 | 实现功能 |
|---|---|---|
| byte[] | readAllBytes() | 返回文件当中的所有字符,没读取到返回-1(所谓的变态方法) |
| int | read(byte b[]) | 把数据读取到byte字符数组当中, 没读取到返回-1 |
| int | read(byte b[], int off, int len) | 读取到byte字符数组当中,指定读取的位置, 没读取到返回-1 |
为什么说readAllBytes()方法的坏话呢??想一种情况,读取一个1.5个G的文件,这光读取就需要相当的一段时间,这就是这个方法的坏处,读取大的文件根本没办法读取。即使可以,也是效率相当低的。
InputStream类也是一个抽象类,实现它的类是FileInputStream,需要使用这个类进行父类的实例化。
FileInputStream的主要方法
public class FileInputStream extends InputStream {
//使用文件名称或者是使用文件对象进行构造
public FileInputStream(String name) throws FileNotFoundException {}
public FileInputStream(File file) throws FileNotFoundException {}
//读取的三个方法
private native int readBytes(byte b[], int off, int len) throws IOException;
public int read(byte b[]) throws IOException {}
public int read(byte b[], int off, int len) throws IOException {}
}
字符输出流:Writer
OutputStream输出流可以进行数据的写操作,但是在一般的情况下,都不是使用字符数组进行写的,最方便的还是写字符串,所以为了简化操作,JDK1.1开始支持字符流。
Writer定义
public abstract class Writer implements
Appendable, Closeable, Flushable {
//写单个数字进去
public void write(int c) throws IOException {}
//写文件、按照字符数组写进去
public void write(char cbuf[]) throws IOException {}
//写入字符数组,指定写入的位置 起点和终点
abstract public void write(char cbuf[], int off, int len);
//写进去一个字符串
public void write(String str) throws IOException {
write(str, 0, str.length());
}
//写入字符串,指定开始和结束的位置
public void write(String str, int off, int len) { }
}
看看他去实现的那些接口:
Appendable接口的定义
public interface Appendable {
Appendable append(CharSequence csq) throws IOException;
Appendable append(CharSequence csq, int start, int end)
Appendable append(char c) throws IOException;
}
Writer类继承结构图:

Writer类的最大特点是可直接进行字符串数据的书写,Writer的接口当中有一个方法是Writer append(CharSequence csq)说明他是可以直接在文件当中直接追加实现CharSequence接口的实例。也就是说可以传递String、StringBuilder和StringBuffer类型的数据,把这些数据加到文件当中去。
演示样例:
public static void main(String[] args) throws IOException {
File file = new File("F:" + File.separator + "test" + File.separator + "test02.txt");
Writer out = new FileWriter(file);
out.write("this is Writer Test!!!");
out.append("i am writing blog...");
out.close();
}
操作结果:

Writer虽然达到的效果和OuputStream是一样的,但是最大的特点还是可以直接写入字符串。
字符输入流:Reader
Reader类的继承实现结构图:

Reader的定义
还是写几个我们经常用的方法:
public abstract class Reader implements Readable, Closeable {
//charbuffer这个是new io当中引入的类,本文不多解释
public int read(java.nio.CharBuffer target) throws IOException {}
//从文件当中读取单个字符
public int read() throws IOException {}
//读取文件内容到字符数组当中
public int read(char cbuf[]) throws IOException { }
//抽象方法,从文件读取字符到字符数组当中
abstract public int read(char cbuf[], int off, int len);
Reader没有InputStream的那个getAllBytes方法了,因为Reader考虑到有可能出现溢出的问题。所以读出字符的操作还是沿袭InputStream的操作方式:
public static void main(String[] args) throws IOException {
File file = new File("F:" + File.separator + "test" + File.separator + "test02.txt");
Reader reader = new FileReader(file);
char [] datas = new char[1024];
int read = reader.read(datas);
reader.close();
System.out.println(datas);
}
读写流小结
写到这里为止,我们发现无论是字符流还是字节流都实现一个Closeable的接口,而这个接口还实现了一个接口就是AutoCloseable,不看源码也知道,这个类是自动关闭的接口,所以这些流是否有一种简单的关闭操作。看过一些书的人可能看到过使用try catch快来关闭流的操作,就是这个原因:
public static void main(String[] args) throws IOException {
File file = new File("F:" + File.separator + "test" + File.separator + "test02.txt");
//使用try块进行流的关闭
try(Reader reader = new FileReader(file)) {
char [] datas = new char[1024];
int read = reader.read(datas);
System.out.println(datas);
}
}
字节流和字符流
现在看到的这两种流到底什么时候才使用呢???
字节操作属于基础的二进制数据操作流,在网络文件、图片、视频等二进制文件的传输上有较大的优势。但是不方便处理中文数据 ,所以对中文字符串的处理需要靠字节流来完成。
字节流和字符流的不同处理过程:

字符数据最后也是转换成字符数据存放到磁盘当中的,当中的这个过程需要用到缓冲区执行转换处理,所以说写入磁盘的只有字节,字符只不过是对字节的一种包装。
验证缓冲区的存在
既然有这个缓冲区,那么如何证明他的存在,其实很简单,只需要把close操作去掉就行,因为字符流传输的过程当中,把数据先保存到缓冲区当中,之后需要flush操作才能写到文件当中,来看一下如何操作。
public static void main(String[] args) throws IOException {
File file = new File("F:" + File.separator + "test" + File.separator + "test02.txt");
Writer writer = new FileWriter(file);
writer.write("there have nothing!!!");
// writer.close();
}
反正就是啥都没有

加上之后就可以写进去文件了。
Writer和Reader也和InputStream、OutputStream一样都是抽象类需要使用子类进行实例化。继承图如下:

文件拷贝
每个系统都有copy操作,基本的形式都是:copy 旧的文件路径 新的文件路径
如果使用java.io实现拷贝功能,需要考虑到几个点:
1、考虑到通用性,可能拷贝的文件是二进制文件
2、拷贝的文件可能是很大的文件,所以应该读一点儿写一点儿
3、目标目录可能不存在,索引如果不存在就新建目录
代码实现:
public class CopyUtil {
private static File srcFile;
private static File desFile;
/**
* @param args : 输入原来的文件名称,和目标文件名称
*/
public CopyUtil(String [] args) {
if(args.length != 2) {
System.out.println("输入文件的个数不正确");
return;
}
this.srcFile = new File(args[0]);
this.desFile = new File(args[1]);
}
/**
*
* @return 返回执行的时间
* @throws IOException : 文件操作错误的时候爆出异常
*/
public long copy() throws IOException {
InputStream input = null;
OutputStream output = null;
long start = System.currentTimeMillis();
try {
if(desFile.exists()) {
throw new FileNotFoundException("目标文件不存在!");
}
input = new FileInputStream(this.srcFile);
output = new FileOutputStream(this.desFile);
byte [] bytes = new byte[1024];
int len = 0;
//使用while循环来读取文件内容
while ((len = input.read(bytes)) != -1) {
output.write(bytes, 0, len);
}
} catch (IOException e) {
throw e;
} finally {
//input或者output是空的时候不执行关闭
if(input != null) {
try {
input.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(output != null) {
try {
output.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
long end = System.currentTimeMillis();
return end - start;
}
}
实现代码:
public class CopyDemo {
public static void main(String[] args) throws IOException {
String src = "F:" + File.separator + "test" + File.separator + "1.png";
String des = "F:" + File.separator + "test" + File.separator + "2.png";
CopyUtil util = new CopyUtil(new String[] {
src, des
});
util.copy();
}
}
这样就可以实现文件的拷贝。
但是我在学习的过程当中发现了一些东西,有个方法是这个样子滴:transferTo(OutputStream out),也就是说以后只要输入流转为输出流就可以了??
换成11试了一下:
input = new FileInputStream(this.srcFile);
output = new FileOutputStream(this.desFile);
input.transferTo(output);
看着还挺简单的,但是这个也只是在平常自己的开发当中,要是在面试当中用这个,估计会被打……
内存操作流
java.io包里面对内存流提供两种操作方式:
1、字节内存流:ByteArrayInputStream、ByteArrayOutputStream
2、字符内存流:CharArrayReader、CharArrayWriter
就说一下字节内存流的操作方法:
字节内存流的继承结构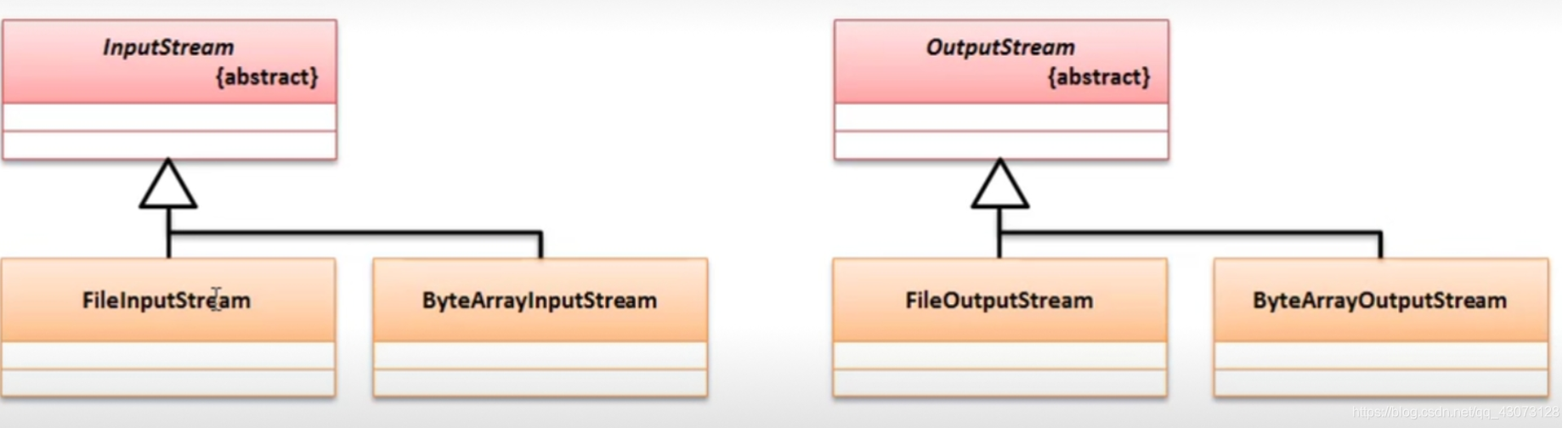
常规的输入输出流,都是从文件读到内存当中,对于这样的类来说,内存是内,文件是外。
但是内存流就不一样,他是从内存里读资源到程序当中,程序是内,内存是外,就像反过来一样。
演示样例:使用内存流实现字符串大小写的转换
public static void main(String[] args) throws IOException {
InputStream input = new ByteArrayInputStream("this is ByteArray test".getBytes());
OutputStream output = new ByteArrayOutputStream();
int data = 0;
while ((data = input.read()) != -1) {
output.write(Character.toUpperCase(data));
}
System.out.println(output.toString());
input.close();
output.close();
}
输出结果:
THIS IS BYTEARRAY TEST
首先通过ByteArrayInputStream把数据从内存读到程序当中,之后通过ByteArrayOutputStream把数据写到缓冲区当中,最后写到标准输出当中去。
在这里,只是在内存当中开辟了一段空间进行IO操作,根本就没有文件产生,所以在临时的操作文件完全可以使用内存流进行传输。
这篇文章就写到这里了,谢谢你的耐心观看。















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









