









之前收集到一个关于纽约市全年出租车的数据集,于是想到,我们是不是可以用这个数据集来研究一下纽约市中各个社区之间的关联度?为了研究这个问题,就需要使用python来建立一些图论模型。
igraph是python/R等语言中常用的建立图模型的模块。接下来首先对igraph模块做一个简要介绍,然后对纽约市的出租车数据进行建模。
一、igraph
首先我们导入所需的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from igraph import *
import datetime
创建图:
g = Graph()
print一下:
print(g)
#输出结果如下
#IGRAPH U--- 0 0 --
添加顶点:
g.add_vertices(3)
print(g)
#输出结果如下
#IGRAPH U--- 3 0 --
添加边:
g.add_edges([(0,1), (1,2)])
IGRAPH U--- 3 2 --
+ edges:
0--1 1--2
如果我们想要删去某两个节点间的边:
g.get_eid(2,1)#获取边的序号
#1
g.delete_edges(1)#删除边
print(g)
"""
IGRAPH U--- 3 1 --
+ edges:
0--1
"""
我们还可以给边定义一些属性
如:
g.vs["name"] = ["Alice"]
g.vs["age"] = [25]
g.vs["gender"] = ["f"]
g.es["is_formal"] = [False]
此时的图如下:
"""
IGRAPH UN-- 3 1 --
+ attr: age (v), gender (v), name (v), is_formal (e)
+ edges (vertex names):
Alice--Alice
"""
二、Community Detection(社区发现)
1.什么是community(社区)
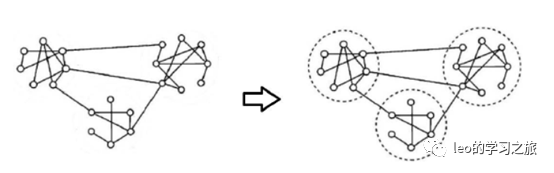
community是一个图中的一个子图,它包含比图的其余部分或更紧密地彼此紧密链接的节点,如果子图内部的边数大于这些子图之间的边数,则图具有community结构。
例如:
以及:
2.什么是modularity(模块度)
Newman 在2003年的论文 “Finding and evaluating community structure in networks” 中首次提出了modularity的定义,它被用来度量自己的社团检测算法的好坏。
Consider a particular division of a network into k communities. Let us
define a k×k symmetric matrix e whose element is the fraction of all
edges in the network that link vertices in community i to vertices in
community j [49].
假设社团划分把一个网络划分为v个社团,定义一个 k*k的矩阵 e , eij 表示连接社团 i 和社团 j 的边的数目占总边数的比例。
特别的, eii表示的是社团i 和社团 i 之间的边占总边数的比例,也就是社团 [公式] 内部的边占总边数的比例。
以下便是模块度的计算公式:
![[公式]](https://img-blog.csdnimg.cn/20191213172037308.png)
如果用 ei 表示社团 i 内部的边数,就可以得到计算modularity最常用的公式
![[公式]](https://img-blog.csdnimg.cn/20191213172139525.png)
3.multilevel community detection algorithm
为了快速进行社区发现,我们需要一些求解该问题的算法。这其中,时间复杂度最低的便是Blondel发明的multilevel算法。
该算法有两个主要步骤:
步骤一:
不断地遍历网络图中的节点,通过比较节点给每个邻居社区带来的模块度的变化,将单个节点加入到能够使modulaity模块度有最大增量的社区中。
步骤二:
对第一阶段进行处理,将属于同一社区的顶点合并为一个大的超点重新构造网络图,即一个社区作为图的一个新的节点。此时两个超点之间边的权重是两个超点内所有原始顶点之间相连的边权重之和,即两个社区之间的边权重之和。
重复以上步骤,直至不能改变网络图为止。
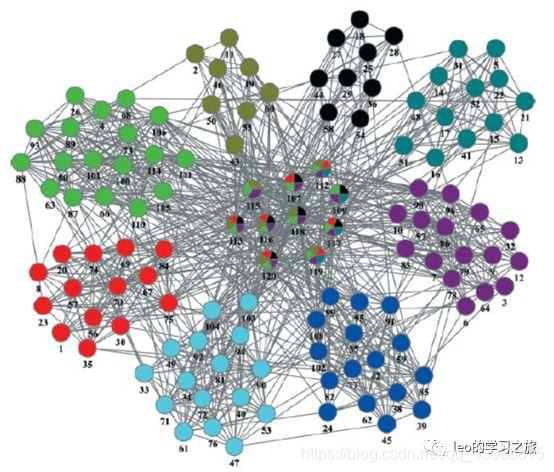
三、实例
通过纽约的出租车数据进行纽约市的社区发现。
首先读取数据
intersections=pd.read_csv("intersections.csv",header=None)
intersection_to_zone=pd.read_csv("intersection_to_zone.csv")
taxi_id=pd.read_csv("taxi_id.csv",header=None)
观察数据
taxi_id.tail(5)
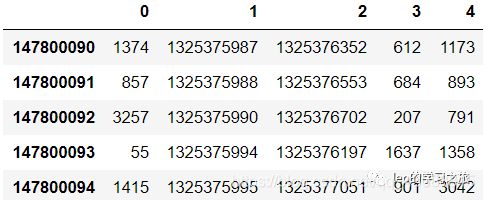
每一趟出租车的数据
intersection_to_zone.tail(5)
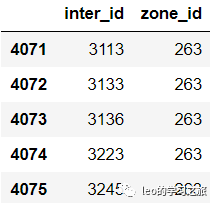
每个intersection属于的community
intersections.head(5)
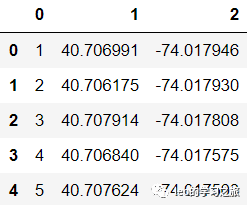
intersection的经纬信息
建立图模型,并遍历taxi数据,探究早晨7-9点的纽约哪些社区的关系较为紧密
g1=Graph()
g1.add_vertices(63)
for index, row in taxi_id.iterrows():
beginTime = datetime.datetime.fromtimestamp(row["1"])
endTime = datetime.datetime.fromtimestamp(row["2"])
start_place=row["3"]
end_place=row["4"]
print(beginTime)
try:
start_zone=dic[start_place]
end_zone=dic[end_place]
except KeyError:
continue
if (beginTime.hour==7 or beginTime.hour==8) and (endTime.hour==7 or endTime.hour==8):
#print(start_zone,end_zone)
g1.add_edges([(to_vid[start_zone],to_vid[end_zone])])
使用Blondel的算法进行社区发现
result1=g1.community_multilevel()
观察结果
print(result1)
Clustering with 63 elements and 3 clusters
[0] 0, 1, 2, 7, 13, 14, 15, 18, 19, 20, 23, 26, 31, 32, 35, 41, 42, 43, 44,
45, 48, 49, 50, 51, 59, 60
[1] 8, 9, 10, 16, 17, 36, 37, 38, 39, 47, 58
[2] 3, 4, 5, 6, 11, 12, 21, 22, 24, 25, 27, 28, 29, 30, 33, 34, 40, 46, 52,
53, 54, 55, 56, 57, 61, 62
可以看到,该算法将纽约划分为了三个主要部分。
同时,结合纽约的地理信息
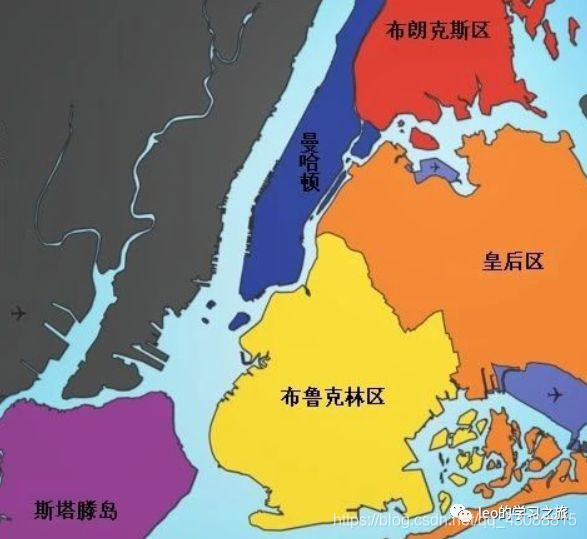
可见纽约的五个区分布在三块分离的岛屿上,而出租车数据的分析结果也与这一点吻合的很好。
看完文章别忘了送上点赞~
欢迎关注我的个人公众号-leo的学习之旅
公众号内会分享个人整理/学习的数据科学/深度学习知识~














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









