







文章目录
写在前面
难

友友们,别问我为何这次这么晚,俺是真的没时间写,哭唧唧。
一、部署KALDI
1. 下载并解压KALDI工具箱
这个大家自己去搜一搜安装包,github上也有。
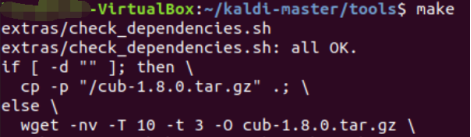
2. tools中执行extras/check_dependencies.sh脚本,根据其输出安装依赖库直到输出ALL OK



3.make

4. src中执行./configure –shared

5. src中执行make depend和make



二、运行yesno项目实例,简要解析发音词典内容,画出初步的WFST图
1. 下载并划分数据集
从网络上下载数据集文件waves_yesno.tar.gz到s5/路径下并解压。
原始的数据是60个wav文件。文件名是八个用下划线分隔的01组合。需要将音频数据转化成kaldi能够处理的格式。
运行指令local/prepare_data.sh waves_yesno准备数据(生成训练和测试集)

Kaldi使用以下几个文件来表示数据:
(1)Text
音频的文本记录。每一个音频文件一行。格式为<utt_id> 。<utt_id>为音频的id,一般用不带扩展名的文件名表示。utt_id在wav.scp文件中与具体的文件映射。是音频对应的文字。

(2)wav.scp
将文件映射到唯一的utt_id。格式为<utt_id>
第二个参数既可以是对应utt_id的音频文件路径,也可以是能够获得音频文件的指令。

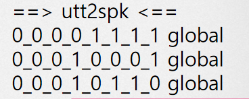
(3)utt2spk
对于每一个音频文件,标记是哪一个人发音的。因为yesno数据集中只有一个发音者,用global来表示所有的utt_id。文件内每一行的格式为<utt_id> <speaker_id>。
(4)spk2utt
和utt2spk反过来。文件内每一行对应一个发音者,第一个是speaker的id,后面用空格分隔开60个utt_id。格式为<speaker_id> <utt_id1> <utt_id2>。

2. 建立词典
对于当前项目,我们只有两个词 yes和no。
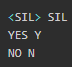
在真实的语言中,词的数量更多,并且还有停顿和环境噪声。
kaldi将这些非语言的声音称作slience(SIL)。加上SIL一共需要三个词来表示当前这个yesno语言模型。执行指令local/prepare_dict.sh,将会在s5/data/local/dict中看到新生成的5个文件。其中发音词典lexicon.txt给出了YES、NO和三个单词的音素序列
3. 构造语言模型
接下来要做语言模型。
项目提供了一个一元的语言模型。然而我们需要将这个模型转换成一个WFST(一种有穷自动机)。执行指令: local/prepare_lm.sh ,这条命令将这个模型转换成一个WFST(有限加权状态转换机)
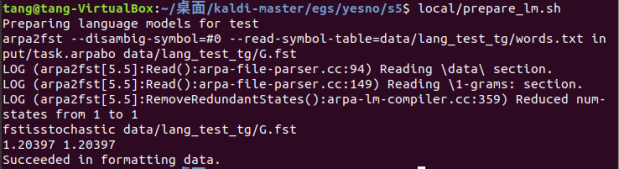
执行后在data/lang_test_tg文件夹下生成WFST,文件格式为fst,我们执行以下指令将其转化为jpg图片。

查看图片文件:

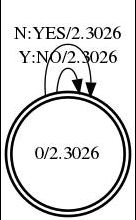
4. MFCC特征提取和GMM-HMM建模
提取梅尔倒谱系数。这里我采用的参数是 output_dir=mfcc。那么结果将会保存在mfcc文件夹下。
建立提取mfcc特征脚本文件mfcc.sh,并运行:
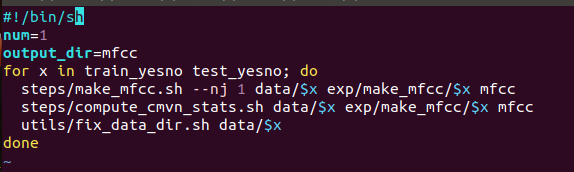
建立模型训练脚本文件model.sh,并运行:

到现在我们已经完成了模型的训练。
接下来用测试集来验证一下模型的准确与否。
第一步是创建一个全连接的FST网络。

然后steps/decode.sh [options] 用来寻找每一个测试音频的最佳路径,写一个脚本文件find.sh并运行:

5. 查看结果
在decode.sh内部最后会调用score.sh,这个脚本则生成预测的结果并且计算测试集Word error rate(WER)。
调用下列命令可以看到最好的效果:
for x in exp//decode; do [ -d $x ] && grep WER $x/wer_* | utils/best_wer.sh;
done
结果如下:
WER后跟着的0.00是说字的错误率为0,即准确率为100%。
测试集一共29条音频,每条音频有8个字(单音素的字)。一共232个字。

三、调整并运行TIMIT项目,将命令行输出的过程与run.sh各部分进行对应,叙述顶层脚本run.sh的各部分功能
1. TIMIT实例介绍
TIMIT全称The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus, 是由德州仪器(TI)、麻省理工学院(MIT)和坦福研究院(SRI)合作构建的声学-音素连续语音语料库。TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子,由来自美国八个主要方言地区的630个人每人说出给定的10个句子,所有的句子都在音素级别(phone level)上进行了手动分割,标记。
TIMIT语料库多年来已经成为语音识别社区的一个标准数据库,在今天仍被广为使用。其原因主要有两个方面:数据集中的每一个句子都在音素级别上进行了手动标记,同时提供了说话人的编号,性别,方言种类等多种信息;数据集相对来说比较小,可以在较短的时间内完成整个实验;同时又足以展现系统的性能。
2. 安装irstlm
irstlm是语言模型工具包,Timit要用到,安装的脚本在kaldi/tools/extras/install_irstlm.sh。
cd kaldi/tools/extras
./install_irstlm.sh

3. 准备数据
在/egs/timit/s5/data目录下创建TIMIT文件夹,Timit语音库分为train和test两个文件夹,将这两个文件夹放在TIMIT下面。

4. 准备训练模型
进入/egs/timit/s5文件夹,s5文件夹下中包含三个关键的脚本:cmd.sh,path.sh,run.sh。
cmd.sh用来定义每个步骤使用的脚本。修改cmd.sh:

path.sh用来定义各种工具包的路径。修改path.sh如下:

run.sh是所有阶段的脚本,包括了读取数据,建立发音字典,特征提取,声学模型训练(单音节、双音节、三音节、SGMM2、DNN等等),解码。最后显示各种模型的正确率。
在运行之前,需要修改run.sh脚本中的Timit数据路径(必须提供自己的Timit绝对路径):

run.sh中SGMM2 Training & Decoding部分 exit 0 要注释掉

5. 运行
cd kaldi/egs/timit/s5
./run.sh

6. 分析runsh.sh脚本每个模块的作用
Acoustic model parameters下的参数是声学模型的参数;
#nj是指需要运行jobs的数量,一般不超过cpu的数量;

这部分代码功能是生成词典文件,并将模型转换成一个WFST;


这部分代码功能是提取MFCC特征;


这里是单音素的训练和解码部分,语音识别最基础的部分;


这里是三音素的训练和解码部分;


这里在三音素模型的基础上做了 LDA + MLLT 变换;


这里是三音素模型的基础上做了 LDA + MLLT + SAT 变换;


这里是三音素模型的基础上做了 sgmm2;


这里是三音素模型的基础上做了 MMI + SGMM2;


这里是povey版本的dnn模型:


这里是得到上述模型的最后识别结果;

















 8859
8859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











