







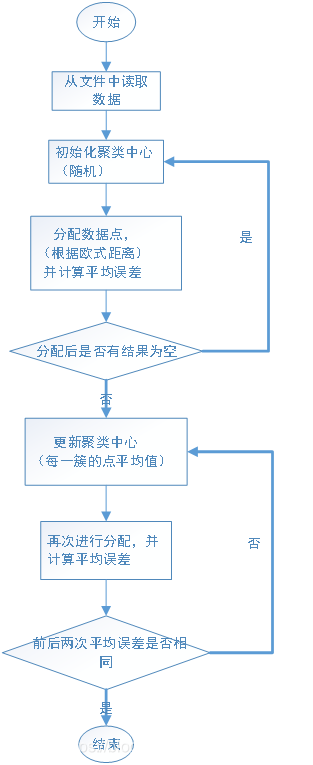
k-means算法思想:
第一步,从文件中读取数据,点用元组表示,点集用列表表示。
第二步,初始化聚类中心。首先获取数据的长度,然后在range(0,length)这个区间上随机产生k个不同的值,以此为下标提取出数据点,将它们作为聚类初始中心,产生列表center。
第三步,分配数据点。将数据点分配到距离(欧式距离)最短的聚类中心中,产生列表assigment,并计算平均误差。
第四步,如果首次分配后有结果为空,则重新初始化聚类中心。
第五步,更新聚类中心,(计算每一簇中所有点的平均值),然后再次进行分配,并计算平均误差。
第六步,比较前后两次的平均误差是否相等,若不相等则进行循环,否则终止循环,进入下一步
最少进行两次聚类,对比误差,输出较小误差时的结果,避免平均误差过大。流程图:
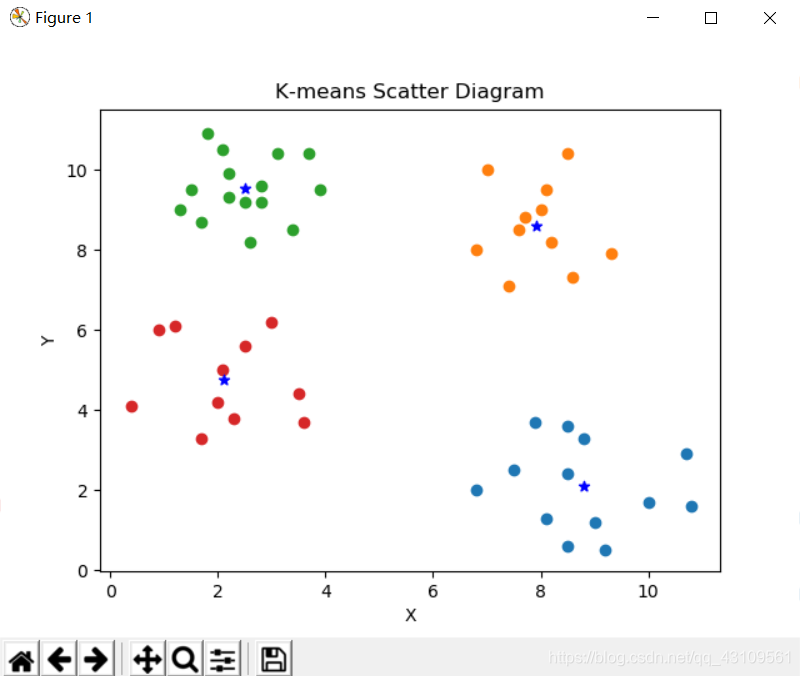
结果输出:

散点图:
python代码:
import random
from math import *
import matplotlib.pyplot as plt
#从文件种读取数据
def read_data():
data_points = []
with open('data.txt','r') as fp:
for line 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









