






Kimi团队
摘要
我们介绍了Kimi-Audio,这是一个开源的音频基础模型,在音频理解、生成和对话方面表现出色。我们详细描述了构建Kimi-Audio的实践,包括模型架构、数据整理、训练配方、推理部署和评估。具体而言,我们利用了一个12.5 Hz的音频分词器,设计了一种基于LLM的新架构,该架构以连续特征作为输入,离散标记作为输出,并开发了一种基于流匹配的块状流式解码器。我们整理了一个预训练数据集,其中包括超过1300万小时的音频数据,涵盖了广泛的模态,包括语音、声音和音乐,并构建了一条管道来构建高质量和多样化的后训练数据。Kimi-Audio从一个预训练的LLM初始化,然后在音频和文本数据上进行持续预训练,通过几个精心设计的任务,并进一步微调以支持各种音频相关任务。广泛的评估表明,Kimi-Audio在一系列音频基准测试中实现了最先进的性能,包括语音识别、音频理解、音频问答和语音对话。我们在https://github.com/MoonshotAI/Kimi-Audio上发布了代码、模型检查点以及评估工具包。
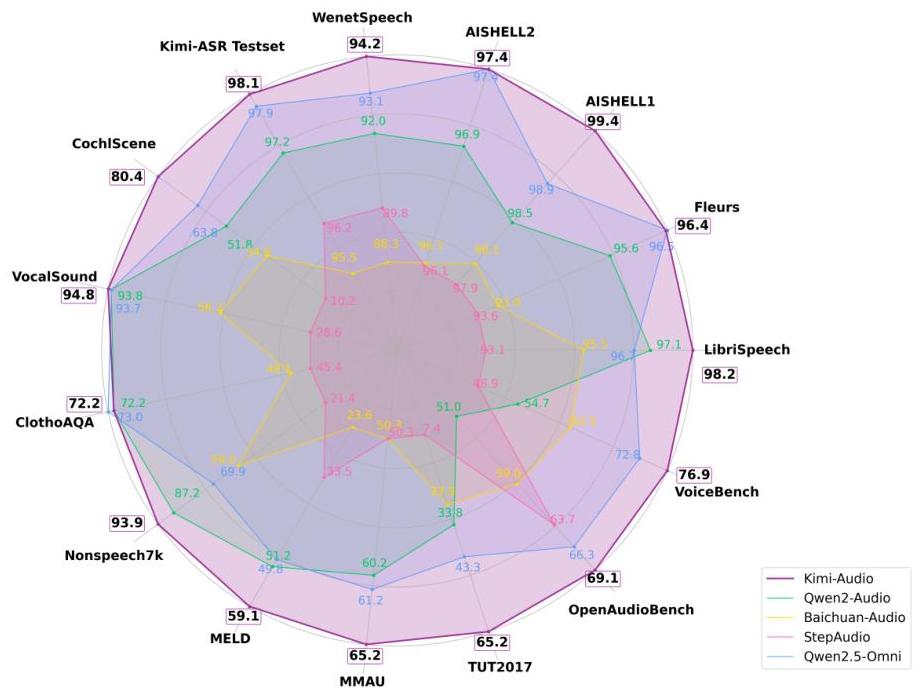
图1:Kimi-Audio与先前的音频语言模型Qwen2-Audio [11]、BaichuanAudio [41]、Step-Audio [28]和Qwen2.5-Omni [73]在各种基准测试上的性能比较。
1 引言
音频在人类日常生活中扮演着不可或缺的角色,如环境感知、语音对话、情感表达和音乐欣赏,是人工通用智能中的一个重要话题。传统的音频建模受制于人工智能的发展,分别处理每个音频处理任务(例如,语音识别、情感识别、声音事件检测和语音对话)。然而,音频本质上是顺序的,语音与文本有严格的对应关系,这使得它非常适合利用大型语言模型(LLMs)的进步来进行音频建模。正如自然语言处理所经历的那样,音频处理迅速从为不同任务单独建立模型演变为能够处理各种任务的通用模型。
例如,先驱工作将语言模型引入音频生成 [3, 77]、音频理解 [10, 63, 9]、语音识别 [58, 87]、语音合成 [70, 80] 和端到端语音对话 [29, 14] 中。然而,以前的工作在以下几个方面未能构建出适用于多种音频处理任务的通用音频基础模型:1) 不够通用,仅专注于特定类型的任务,如音频理解 [10, 11, 21, 63, 88, 35]、音频生成 [45, 77] 或语音对话 [14, 84]; 2) 对音频预训练的关注较少,仅在下游音频任务上微调 LLM [10, 63, 9]; 3) 无法访问源代码和检查点,对社区的价值有限 [29, 7]。
在本报告中,我们介绍了 Kimi-Audio,这是一种开源的音频基础模型,可以处理各种音频处理任务。我们从三个方面详细说明了构建最先进的(SOTA)音频基础模型的努力:架构、数据和训练。
- 架构。我们的模型由三个组件组成:音频分词器和反分词器作为音频输入/输出,以及音频LLM作为核心处理部分(见第2.1节)。我们将离散语义音频标记用作音频LLM输入和输出的基本表示。同时,我们在输入中连接语义音频标记与连续声学向量以增强感知能力,并在输出中连接与离散文本标记以增强生成能力。这样,我们可以同时实现良好的音频感知和生成能力,促进通用音频建模。我们将每秒音频中的标记数量减少,以弥合文本和音频序列之间的差距,并将语义和声学音频标记的压缩率均设置为12.5 Hz。第2.2节和第2.3节分别介绍了用于离散语义标记和连续声学向量的音频分词器的详细设计,以及离散语义标记和文本标记的生成。
-
- 数据。为了实现SOTA通用音频建模,我们需要在大量音频数据上预训练模型以涵盖多样化场景。为此,我们爬取并处理了一个大规模的音频预训练数据集。我们开发了一个包含语音增强、说话人日志化、转录、过滤等的数据处理流水线,以确保高数据质量(见第3.1节)。为了支持多样化的音频处理任务,我们整理了大量的任务专用数据以进行监督微调(SFT)。我们展示了一种经济的方式来使用纯开放且可访问的数据源和处理工具构建大部分SFT数据以实现SOTA性能,而无需依赖任何数据购买(见第3.2节)。
-
- 训练。为了在保持高知识容量和智能的同时获得良好的音频理解和生成能力,我们从预训练的LLM初始化音频LLM,并精心设计了一系列预训练任务以充分学习音频数据并弥合文本和音频之间的差距。具体来说,预训练任务可以分为三类:1) 纯文本和纯音频预训练,旨在分别从文本和音频领域学习知识;2) 音频到文本映射,鼓励音频和文本之间的转换;3) 音频-文本交错,进一步弥合文本和音频之间的差距(见第4.1节)。在监督微调阶段,我们开发了一种训练配方以提高微调效率和任务泛化能力(见第4.2节)。
此外,我们介绍了在Kimi APP中部署和提供音频基础模型推理的实践,如第5节所述。在各种下游任务中评估和基准测试音频基础模型(如语音识别、音频理解和语音对话)具有挑战性。我们在公平比较不同音频模型时遇到了棘手的问题,如非标准化的指标、评估协议和推理超参数。因此,我们开发了一种评估工具包,可以忠实地在综合基准上评估音频LLM(见第6.1节)。我们开源此工具包以促进社区内的公平比较。
- 训练。为了在保持高知识容量和智能的同时获得良好的音频理解和生成能力,我们从预训练的LLM初始化音频LLM,并精心设计了一系列预训练任务以充分学习音频数据并弥合文本和音频之间的差距。具体来说,预训练任务可以分为三类:1) 纯文本和纯音频预训练,旨在分别从文本和音频领域学习知识;2) 音频到文本映射,鼓励音频和文本之间的转换;3) 音频-文本交错,进一步弥合文本和音频之间的差距(见第4.1节)。在监督微调阶段,我们开发了一种训练配方以提高微调效率和任务泛化能力(见第4.2节)。
基于我们的评估工具包,我们对Kimi-Audio和其他音频LLM在各种音频基准上进行了全面评估(见第6.2节)。评估结果表明,Kimi-Audio在一系列音频任务中取得了SOTA性能,包括语音识别、音频理解、音频到文本聊天和语音对话。我们在https://github.com/MoonshotAI/Kimi-Audio上开源了Kimi-Audio的代码和检查点,以及评估工具包,以推动社区的发展。
2 架构
2.1 概述
Kimi-Audio是一种音频基础模型,旨在通过统一架构执行全面的音频理解、生成和对话任务。如图2所示,我们的系统包含三个主要组件:(1) 一个音频分词器,将输入音频转换为通过矢量量化以12.5 Hz帧速率派生的离散语义标记。音频分词器还提取连续声学向量以增强感知能力。(2) 一个音频LLM,生成语义标记和文本标记以改进生成能力,其特点是具有处理多模态输入的共享变压器层,然后分支到专门的并行头用于文本和音频生成;(3) 一个音频解码器,将音频LLM预测的离散语义标记转换回连贯的音频波形,使用流匹配方法。这种集成架构使Kimi-Audio能够在单一统一模型框架内无缝处理从语音识别和理解到语音对话的各种音频-语言任务。
2.2 音频分词器
我们的音频基础模型采用了一种混合音频分词策略,结合离散语义标记和互补的连续声学信息向量,有效地表示语音信号以供下游任务使用。这种分词允许模型利用离散标记的效率和语义重点,同时受益于连续表示捕获的丰富声学细节。
我们采用了GLM-4-Voice [84]提出的离散语义标记。该组件利用从自动语音识别(ASR)模型派生的监督语音分词器。
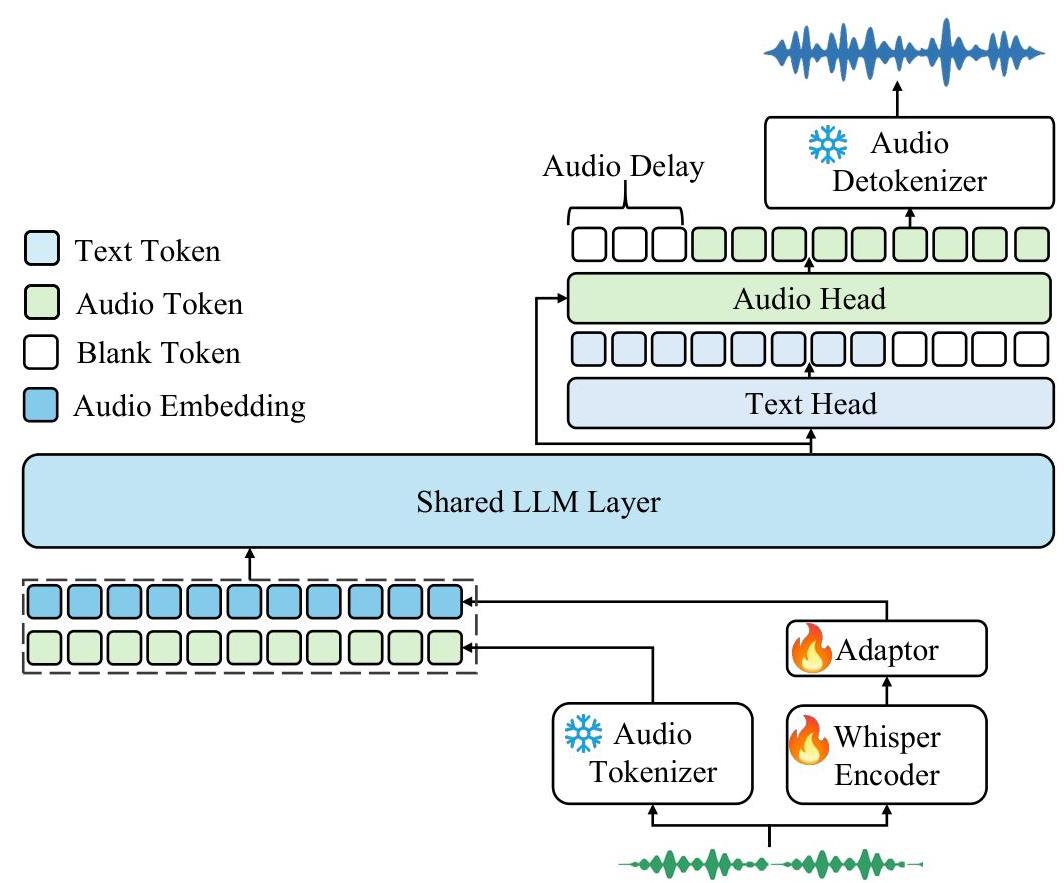
图2:Kimi-Audio模型架构概述:(1) 一个音频分词器,提取离散语义标记和Whisper编码器生成的连续声学特征;(2) 一个音频LLM,处理音频输入并生成文本和/或音频输出;(3) 一个音频解码器将音频标记转换为波形。
通过在whisper编码器架构[58]中引入矢量量化层,我们可以使用单个码本将连续语音表示转换为低帧率(即12.5 Hz)的离散标记序列。
补充离散语义标记,我们结合了来自预训练whisper模型[58]的连续特征表示以增强模型的感知能力。由于whisper特征的帧率为50 Hz ,我们另外引入了一个适配器,将特征从50 Hz 下采样到12.5 Hz 。下采样的特征添加到离散语义标记的嵌入中,作为音频LLM的输入。
通过结合离散语义标记与连续的whisper特征,我们的模型从高效、语义基础的表示和详细的声学建模中受益,为各种音频处理任务提供了全面的基础。
2.3 音频LLM
我们系统的核⼼是⼀个⾳频LLM,旨在处理第2.2节中描述的分词策略⽣成的⾳频表⽰,并产⽣包括⾳频的离散语义标记和相应的⽂本标记在内的多模态输出,以提⾼⽣成能⼒。
为了使模型能够⽣成⾳频语义标记和相应的⽂本响应,我们通过将标准LLM架构结构化为具有共享和专⽤功能的组件来适应。⼤部分原始变换器底层,即前⼏层,被用作共享层。这些层处理输⼊序列并学习跨模态表⽰,整合输⼊或上下⽂中存在的⽂本和⾳频模态的信息。基于这些共享层,架构分为两个包含变换器层的并⾏头。第⼀个头是负责⾃回归预测⽂本标记的⽂本头,形成模型的⽂本输出。第⼆个头是预测离散⾳频语义标记的⾳频头。这些预测的⾳频标记随后传递给⾳频解码器模块,以合成最终的输出⾳频波形。
为了利⽤预训练⽂本LLM[76, 24, 13]的强⼤语⾔能⼒,共享变换器层和⽂本头的参数直接从预训练⽂本LLM的权重初始化。⾳频头层则随机初始化。这种初始化策略确保模型保留稳健的⽂本理解和⽣成能⼒,同时学习有效处理和⽣成⾳频信息。
2.4 音频解码器
音频解码器旨在根据离散语义音频标记生成高质量和表现力强的语音。我们采用了MoonCast [32]中相同的解码器架构,该架构包含两部分:1)将12.5 Hz语义标记转换为50 Hz梅尔频谱图的流匹配模块;2)从梅尔频谱图生成波形的声码器。为了减少语音生成延迟,我们设计了一种块状流式解码器。直观上,我们可以将语义标记分割成块并分别解码它们,但在我们的初步实验中,块边界面临间断问题。因此,我们提出了一种带有前瞻机制的块状自回归流式框架。
块状自回归流式框架。我们将音频分成块(例如,每块1秒):
{
c
1
,
c
2
,
…
,
c
i
,
…
,
c
N
}
\left\{c_{1}, c_{2}, \ldots, c_{i}, \ldots, c_{N}\right\}
{c1,c2,…,ci,…,cN},其中
N
N
N是块的数量。首先,为了匹配语义标记
(
12.5
H
z
)
(12.5 \mathrm{~Hz})
(12.5 Hz)和梅尔频谱图
(
50
H
z
)
(50 \mathrm{~Hz})
(50 Hz)之间的序列长度,我们将语义标记上采样4倍。其次,在训练和推理过程中应用块状因果掩码,即对于块
c
i
c_{i}
ci,所有之前的块
c
j
c_{j}
cj (
j
<
i
j<i
j<i)都是提示。我们将块
c
i
c_{i}
ci的梅尔频谱图记为
m
i
m_{i}
mi,对应的离散语义音频标记记为
a
i
d
a_{i}^{d}
aid。流匹配模型的前向步骤将
m
i
m_{i}
mi与高斯噪声混合,后向步骤将在条件
a
i
d
a_{i}^{d}
aid和提示
c
j
c_{j}
cj (
j
<
i
j<i
j<i)的情况下去除噪声以获得干净的
m
i
m_{i}
mi,其中
c
j
c_{j}
cj包含
m
j
m_{j}
mj和
a
j
d
a_{j}^{d}
ajd。通过这种设计,在推理过程中,当LLM生成一个块时,我们使用流匹配模型将其解码以获得梅尔频谱图。最后,我们应用BigVGAN [38]声码器为每个块生成波形。
前瞻机制。通过初步研究,我们发现块边界处生成的音频仍存在间断问题。尽管在扩散去噪过程中看到了长范围的历史上下文,但由于块状因果注意的性质,边界位置的未来上下文无法看到,导致质量下降。因此,我们提出了前瞻机制。具体来说,对于块
c
i
c_{i}
ci,我们从块
c
i
+
1
c_{i+1}
ci+1中选取未来的
n
n
n(例如4)个语义标记,并将它们连接到
c
i
c_{i}
ci的末尾以形成
c
^
i
\hat{c}_{i}
c^i。然后我们解码
c
^
i
\hat{c}_{i}
c^i以生成梅尔频谱图,但只保留与
c
i
c_{i}
ci对应的梅尔频谱图。这种机制无需训练,只会使第一个块的生成延迟
n
n
n个标记。
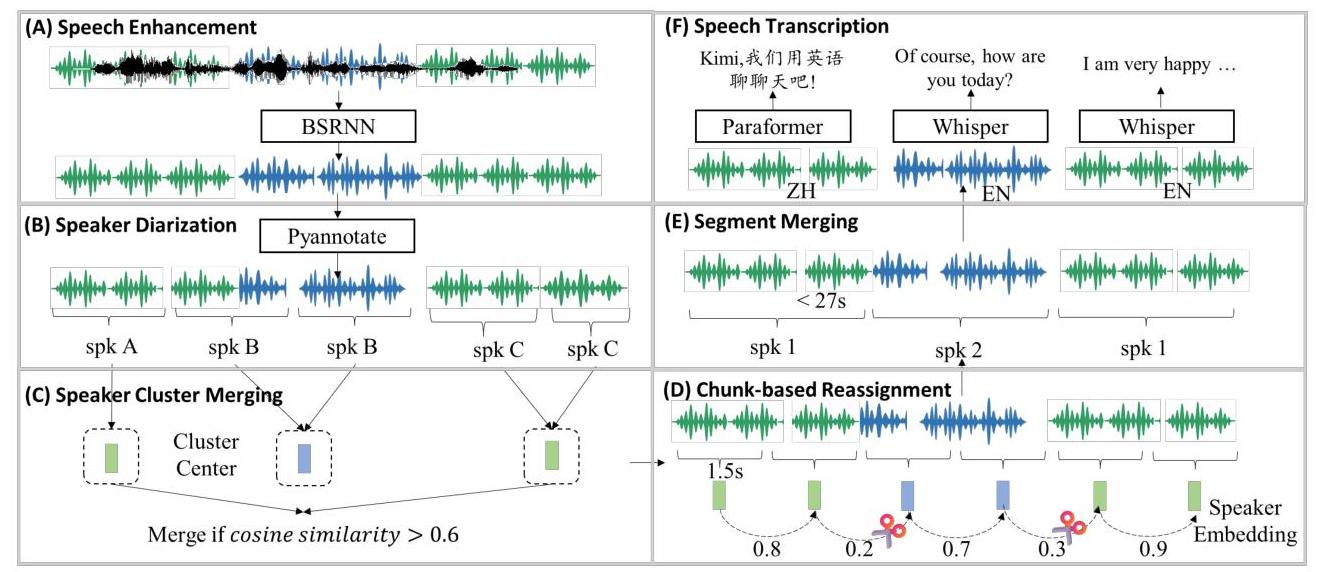
图3:音频预训练数据的处理流程。
3 数据
3.1 预训练数据
我们的预训练语料库包括单模态(纯文本、纯音频)和多模态(文本音频)数据。纯音频预训练数据覆盖了广泛的现实场景,包括有声读物、播客和访谈,包含大约1300万小时的原始音频,含有丰富的声学事件、音乐、环境声音、人类发声和多语言信息。纯文本预训练数据的详细信息可以在[65]中找到。
大多数音频语料库仅包含原始音频,没有对应的转录、语言类型、说话人注释和分段边界。此外,原始音频通常包含不希望出现的伪影,如背景噪音、混响和说话人重叠。
受到先前工作的启发[32, 81, 26],我们开发了一种高效的自动音频数据处理流水线,以生成高质量的注释,从而得到我们的多模态(音频-文本)数据。
与之前主要关注生成无上下文信息的高质量短音频片段的数据处理流水线相比,我们的流水线旨在提供具有一致长程上下文的长格式音频注释。该流水线按步骤包括以下关键组件,如图3所示并如下描述。
语音增强。为了抑制不需要的背景噪音和混响,我们基于Band-Split RNN (BSRNN)架构[49]开发了一个语音增强模型,如图3(A)所示。遵循与[82]相同的超参数配置,该模型应用于执行48 kHz语音增强。经验上,我们发现语音增强会去除环境声音和音乐,这对音频理解是有害的。因此,在预训练阶段,我们以1:1的比例随机选择原始或增强音频。
按话者分段。我们采用基于话者日志的方法来分割长格式音频。我们使用PyAnnote工具包
1
{ }^{1}
1进行话者日志化(图3(B)),它将音频分割并分配话者标签。然而,原始输出次优,因此我们开发了一个后处理流水线以解决之前分段结果中的问题:
- 话者聚类合并。我们观察到PyAnnote有时会为同一个实际话者分配多个话者标签,这会导致话者碎片化。我们计算每个初始聚类的代表性话者嵌入,并合并嵌入余弦相似度大于0.6的聚类对,如图3©所示。
-
- 块级重新分配。初始话者日志偶尔会产生包含多个话者的段。为了净化段落,1)我们首先将所有段落划分为1.5秒的块,然后2)对于每对相邻块,如果它们的余弦相似度低于0.5,我们将其视为属于不同的说话者,并将每个块重新分配给具有最高相似度的说话者集群,如图3(D)所示。
-
- 段落合并。初始话者日志可能导致高度变化且有时不切实际的段落长度(短于1秒或长于100秒)。因此,我们迭代地合并标记为相同说话者的相邻段落(在重新分配步骤之后)。如果累积段落长度超过27秒或两个段落之间的静音间隔大于2秒,则合并过程终止,如图3(E)所示。
经过细化的话者日志分割过程提供的说话者轮次比基线话者日志输出更准确且大小更一致。
- 段落合并。初始话者日志可能导致高度变化且有时不切实际的段落长度(短于1秒或长于100秒)。因此,我们迭代地合并标记为相同说话者的相邻段落(在重新分配步骤之后)。如果累积段落长度超过27秒或两个段落之间的静音间隔大于2秒,则合并过程终止,如图3(E)所示。
语音转录。为了获取每段语音的语言类型和文本转录,我们首先应用Whisper-large-v3模型[58]
2
{ }^{2}
2来检测所说语言的类型。在此工作中,我们仅保留英语和普通话段落以进行进一步转录。对于英语段落,我们直接使用Whisper-large-v3生成转录和标点符号注释。对于普通话段落,我们利用FunASR工具包
3
{ }^{3}
3中的Paraformer-Zh模型生成转录以及字符级别的时间戳。由于Paraformer-Zh不能输出标点符号注释,我们采用以下策略添加标点符号:如果两个连续字符之间的时间差大于0.5秒但小于1.0秒,我们插入“逗号”;如果时间差超过1.0秒,我们插入“句号”。
实施。数据处理流水线部署在由30个云实例组成的集群上。每个实例配备128个虚拟CPU(vCores)、1TB RAM和8个NVIDIA L20 GPU,由支持向量化加速指令(包括高级矩阵扩展(AMX))的Intel Xeon Platinum 8575C处理器驱动。总的来说,集群提供3,840个vCores、30TB内存和240个NVIDIA L20 GPU。经过广泛的优化,流水线每天处理约200,000小时的原始音频数据。
3.2 SFT 数据
在预训练阶段之后,我们进行监督微调(SFT)以增强Kimi-Audio在指令跟随和音频处理方面的性能。SFT数据主要可分为三部分:音频理解、语音对话和音频到文本聊天。
3.2.1 音频理解
2
{ }^{2}
2 https://huggingface.co/openai/whisper-large-v3
3
{ }^{3}
3 https://github.com/modelscope/FunASR
3
{ }^{3}
3 https://github.com/lighting#llove/zhvoice
表1:用于音频理解的训练数据集及其在SFT阶段的训练周期列表。
| 数据集 | 音频长度(小时数) | 任务类型 | SFT周期 |
|---|---|---|---|
| WenetSpeech [85] | 10,518 | ASR | 2.0 |
| WenetSpeech4TTS [50] | 12,085 | ASR | 2.0 |
| AISHELL-1 [4] | 155 | ASR | 2.0 |
| AISHELL-2 [17] | 1,036 | ASR | 2.0 |
| AISHELL-3 [62] | 65 | ASR | 2.0 |
| Emilla [25] | 98,305 | ASR | 2.0 |
| Fleurs [12] | 17 | ASR | 2.0 |
| CommonVoice [1] | 43 | ASR | 2.0 |
| KeSpeech [64] | 1,428 | ASR | 2.0 |
| Magicdata [79] | 747 | ASR | 2.0 |
| zhvoice | 901 | ASR | 2.0 |
| Libriheavy [33] | 51,448 | ASR | 2.0 |
| MLS [57] | 45,042 | ASR | 2.0 |
| Gigaspeech [5] | 10,288 | ASR | 2.0 |
| LibriSpeech [54] | 960 | ASR | 2.0 |
| CommonVoice [1] | 1,854 | ASR | 2.0 |
| Voxpopuli [69] | 529 | ASR | 2.0 |
| LibriTTS [83] | 568 | ASR | 2.0 |
| CompA-R [22] | 159 | AQA | 2.0 |
| ClothoAQA [43] | 7.4 | AQA | 4.0 |
| AudioCaps [34] | 137 | AAC | 2.0 |
| Clotho-v2 [16] | 24.0 | AAC | 2.0 |
| MACS [51] | 10.9 | AAC | 2.0 |
| FSD50k [19] | 80.8 | SEC | 2.0 |
| CochlScene [31] | 169.0 | ASC | 2.0 |
| Nonspeech7k [59] | 6.2 | SEC | 4.0 |
| MusicAVQA | 77.1 | AQA | 2.0 |
| WavCaps [52] | 3 , 793.3 3,793.3 3,793.3 | AAC | 2.0 |
| AVQA | 112 | AQA | 2.0 |
| IEMOCAP [68] | 10 | SER | 2.0 |
| MELD [56] | 9 | SER | 2.0 |
| RAVDESS [47] | 3 | SER | 2.0 |
| SAVEE [30] | 0.1 | SER | 2.0 |
| ESD [89] | 29 | SER | 2.0 |
| TUT2016 [53] | 10 | ASC | 2.0 |
| TUT2017 [53] | 13 | ASC | 4.0 |
| TAU2022 [27] | 67 | ASC | 2.0 |
| ESC50 [55] | 1 | SEC | 2.0 |
| VocalSound [23] | 19 | SEC | 4.0 |
| VGGSound [6] | 513 | SEC | 2.0 |
| UrbanSound8K [61] | 9 | SEC | 2.0 |
| FSD50K [19] | 74 | SEC | 2.0 |
| Kimi 内部 ASR 数据 | 55,000 | ASR | 2.0 |
| Kimi 内部音频数据 | 5,200 | AAC/AQA | 2.0 |
我们主要利用开源数据集进行音频理解。收集的数据集包括6项任务:自动语音识别(ASR)、音频问答(AQA)、自动化音频字幕(AAC)、语音情感识别(SER)、声音事件分类(SEC)和音频场景分类(ASC)。数据集及其在SFT阶段的相应训练周期详情如表1所示。除了开源数据集外,我们还利用了55,000小时的内部ASR数据和5,200小时的内部音频数据,涵盖AAC/AQA任务。
3.2.2 语音对话
为了激活Kimi-Audio模型在不同对话场景中生成风格多样且表达力高的语音的能力,我们构建了大量语音对话数据,这些数据由一系列用户查询和助手响应组成的多轮对话构成。对于用户查询,我们指示LLMs编写用户查询的文本,然后使用我们的Kimi-TTS系统将其转换为语音,其中提示语音从包含超过125,000种音色的大音色集中随机选择。对于助手响应,我们首先选择一位配音演员作为我们的Kimi-Audio发言人,并使用这一单一音色合成具有适当风格和情感的助手响应。接下来,我们介绍Kimi-Audio发言人的数据录制过程,以及用于合成具有多样风格和表达力的助手响应的Kimi-TTS和Kimi-VC系统。
Kimi-Audio发言人的数据录制。为了在生成的语音中实现多样且高度表达力的风格和情感,我们选择了一位配音演员作为Kimi-Audio发言人,并在专业录音室中精心录制了这位发言人的数据集。我们预先定义了超过20种风格和情感,每种情感进一步分为5个级别以代表不同的情感强度。对于每种风格和情感级别,我们都录制了一段音频作为参考,以保持不同文本句子之间的一致性。整个录制过程由专业录音导演指导。
Kimi-TTS。我们开发了一种零样本文本到语音合成(TTS)系统,称为Kimi-TTS,只需3秒钟的提示即可生成语音,同时保留提示语音的音色、情感和风格。借助Kimi-TTS,我们可以为1)不同说话人/音色中的查询文本;2)由Kimi选定的配音演员记录的Kimi-Audio发言人的响应文本,合成具有多样风格和情感的语音。类似于MoonCast [32]的架构,Kimi-TTS使用LLM根据提示语音和输入文本生成语音标记。然后使用基于流匹配的语音解码器生成高质量的语音波形。我们在由自动数据管道(第3.1节)生成的约1百万小时数据上训练Kimi-TTS,并应用强化学习以进一步增强生成语音的鲁棒性和质量。
Kimi-VC。由于配音演员难以用任何风格、情感和口音录制语音,我们开发了一种语音转换(VC)系统,称为Kimi-VC,将不同说话人/音色中的多样化和野外语音转换为Kimi-Audio发言人的音色,同时保留风格、情感和口音。基于Seed-VC框架[46],Kimi-VC在训练期间通过音色转换模型引入源音色扰动,减轻信息泄露并确保训练和推理阶段的一致性。为了确保高质量的语音转换,我们使用由Kimi选定的配音演员录制的语音数据微调Kimi-VC模型。
3.2.3 音频到文本聊天
为了帮助Kimi-Audio具备基本的聊天能力,我们从文本领域收集开源监督微调数据,如表2所示,并将用户查询转换为各种音色的语音,从而生成音频到文本聊天数据,其中用户查询为语音,助手响应为文本。考虑到一些文本不易转换为语音,我们对文本进行了一些预处理步骤,包括1)过滤掉包含复杂数学、代码、表格、复杂的多语言内容或过长内容的文本,2)进行口语改写,3)将
表2:在音频到文本聊天中使用的文本数据集列表及其在SFT阶段的训练周期。
| 数据集 | 样本数 | SFT周期 |
|---|---|---|
| Magpie-Pro [75] | 300 K | 2.0 |
| Magpie-MT [75] | 300 K | 2.0 |
| Evol-Instruct [15] | 143 K | 2.0 |
| Evol-Instruct-Code [15] | 80 K | 2.0 |
| Infinity-Instruct [2] | 7 M | 2.0 |
| Synthia [67] | 119 K | 2.0 |
| NuminaMath [40] | 860 K | 2.0 |
| Tulu3 [36] | 900 K | 2.0 |
| OpenHermes-2.5 [66] | 1 M | 2.0 |
| OpenOrca [42] | 2 M | 2.0 |
单轮问答数据转换为多轮数据,指令简单明了。
4 训练
4.1 预训练
Kimi-Audio的预训练阶段旨在从真实世界的音频和文本领域学习知识,并在模型的潜在空间中对齐它们,从而促进诸如音频理解、音频到文本聊天和语音对话等复杂任务。为此,我们设计了几种预训练任务,包括以下方面:1)单模态(即音频和文本)预训练,分别从每个领域单独学习知识(见第4.1.1节);2)学习音频-文本映射(见第4.1.2节);3)三种音频-文本交错任务,进一步弥合两种模态之间的差距(见第4.1.3节)。
正式地,给定一个原始音频 A A A,数据预处理流水线(在第3.1节中描述)将其分割成一系列段落 { S 1 , S 2 , … , S N } \left\{S_{1}, S_{2}, \ldots, S_{N}\right\} {S1,S2,…,SN},每个段落 S i , i ∈ [ 1 , N ] S_{i}, i \in[1, N] Si,i∈[1,N]由一个音频 a i a_{i} ai和相应的转录 t i t_{i} ti组成。此外,如第2.2节所述,对于一个音频段 a i a_{i} ai,我们提取连续声学向量 a i c a_{i}^{c} aic和离散语义标记 a i d a_{i}^{d} aid。为了符合第2节中描述的模型架构设计,该架构以离散语义音频标记作为输入和输出的主要表示形式,同时在输入中添加连续声学音频标记并在输出中添加离散文本标记,我们将训练序列表示为 { a 1 c / a 1 d / t 1 , a 2 c / a 2 d / t 2 , … , a N c / a N d / t N } \left\{a_{1}^{c} / a_{1}^{d} / t_{1}, a_{2}^{c} / a_{2}^{d} / t_{2}, \ldots, a_{N}^{c} / a_{N}^{d} / t_{N}\right\} {a1c/a1d/t1,a2c/a2d/t2,…,aNc/aNd/tN},其中 a i c / a i d / t i a_{i}^{c} / a_{i}^{d} / t_{i} aic/aid/ti表示段 i i i的语义音频、声学音频和文本序列。我们通过向较短的序列添加空白标记来确保音频和文本序列具有相同的长度。实际的预训练段可以是 a i c / a i d / t i a_{i}^{c} / a_{i}^{d} / t_{i} aic/aid/ti中的一个或两个,例如 a i d , t i , a i c / a i d a_{i}^{d}, t_{i}, a_{i}^{c} / a_{i}^{d} aid,ti,aic/aid,或 a i d / t i a_{i}^{d} / t_{i} aid/ti。对于 a i c / a i d a_{i}^{c} / a_{i}^{d} aic/aid,我们添加连续向量 a i c a_{i}^{c} aic和语义标记 a i d a_{i}^{d} aid(语义标记将通过查找表转换为嵌入)以获得最终的音频特征 a i a_{i} ai。因此,我们用 a i a_{i} ai简短地表示 a i c / a i d a_{i}^{c} / a_{i}^{d} aic/aid。对于 a i d / t i a_{i}^{d} / t_{i} aid/ti,我们将语义标记和文本标记的查找嵌入作为输入,并生成每个标记与其各自的头部,如第2节所述。
通过这种表示法,我们在表3中制定了以下预训练任务并进行介绍。
表3:预训练任务列表。我们设计了三类预训练任务,包括:1)音频/文本单模态预训练;2)音频-文本映射预训练;3)音频-文本交错预训练。符号:
a
i
d
a_{i}^{d}
aid和
a
i
c
a_{i}^{c}
aic分别表示音频段
i
i
i的离散语义标记和连续声学向量,
a
i
a_{i}
ai表示音频段
i
i
i的
a
i
d
a_{i}^{d}
aid和
a
i
c
a_{i}^{c}
aic组合,下划线表示在训练期间会收到损失。
| 类别 | 预训练任务 | 任务公式 | 任务权重 |
|---|---|---|---|
| 音频/文本单模态 | 仅文本 | t 1 ‾ , t 2 ‾ , … , t N ‾ \underline{t_{1}}, \underline{t_{2}}, \ldots, \underline{t_{N}} t1,t2,…,tN | 7 |
| 仅音频 | a 1 d ‾ , a 2 d ‾ , … , a N d ‾ \underline{a_{1}^{d}}, \underline{a_{2}^{d}}, \ldots, \underline{a_{N}^{d}} a1d,a2d,…,aNd | 1 | |
| 音频-文本映射 | 音频到文本 | a 1 , t 1 ‾ , a 2 , t 2 ‾ , … , a N , t N ‾ a_{1}, \underline{t_{1}}, a_{2}, \underline{t_{2}}, \ldots, a_{N}, \underline{t_{N}} a1,t1,a2,t2,…,aN,tN | 1 |
| 文本到音频 | t 1 , a 1 d ‾ , t 2 , a 2 d ‾ , … , t N , a N d ‾ t_{1}, \underline{a_{1}^{d}}, t_{2}, \underline{a_{2}^{d}}, \ldots, t_{N}, \underline{a_{N}^{d}} t1,a1d,t2,a2d,…,tN,aNd | 1 | |
| 音频-文本交错 | 音频到语义 | a 1 , a 2 d ‾ , a 3 , a 3 d ‾ , … , a N − 1 , a N d ‾ a_{1}, \underline{a_{2}^{d}}, a_{3}, \underline{a_{3}^{d}}, \ldots, a_{N-1}, \underline{a_{N}^{d}} a1,a2d,a3,a3d,…,aN−1,aNd | 1 |
| 音频到文本 | a 1 , t 2 ‾ , a 3 , t 4 ‾ , … , a N − 1 , t N ‾ a_{1}, \underline{t_{2}}, a_{3}, \underline{t_{4}}, \ldots, a_{N-1}, \underline{t_{N}} a1,t2,a3,t4,…,aN−1,tN | 1 | |
| 音频到语义和文本 | a 1 , a 2 d ‾ / t 2 ‾ , a 3 , a 3 d ‾ / t 4 ‾ , … , a N − 1 , a N d ‾ / t N ‾ a_{1}, \underline{a_{2}^{d}} / \underline{t_{2}}, a_{3}, \underline{a_{3}^{d}} / \underline{t_{4}}, \ldots, a_{N-1}, \underline{a_{N}^{d}} / \underline{t_{N}} a1,a2d/t2,a3,a3d/t4,…,aN−1,aNd/tN | 2 |
4.1.1 音频/文本单模态预训练
我们首先分别学习文本和音频的知识。对于文本预训练,我们直接利用MoonLight [44]中的文本数据,这对于训练大型语言模型来说是高质量且全面的。我们仅对文本标记应用下一个标记预测。对于音频预训练,对于每个段 S i S_{i} Si,我们对其离散语义标记序列 a i d a_{i}^{d} aid应用下一个标记预测。
4.1.2 音频-文本映射预训练
直观上,为了在统一空间中对齐音频和文本,学习两种模态之间的映射是有帮助的。因此,我们设计了自动语音识别(ASR)和文本到语音合成(TTS)预训练任务。对于ASR,我们将训练序列公式化为 { a 1 , t 1 , a 2 , t 2 , … , a N , t N } \left\{a_{1}, t_{1}, a_{2}, t_{2}, \ldots, a_{N}, t_{N}\right\} {a1,t1,a2,t2,…,aN,tN}。对于TTS,我们将训练序列公式化为 { t 1 , a 1 d , t 2 , a 2 d , … , t N , a N d } \left\{t_{1}, a_{1}^{d}, t_{2}, a_{2}^{d}, \ldots, t_{N}, a_{N}^{d}\right\} {t1,a1d,t2,a2d,…,tN,aNd}。我们仅在ASR上计算文本标记的损失,在TTS上计算音频语义标记的损失。
4.1.3 音频-文本交错预训练
为了进一步弥合音频和文本模态之间的差距,我们设计了三种音频-文本交错预训练任务。
- 音频到语义标记交错。我们将训练序列公式化为 { a 1 , a 2 d , a 3 , a 4 d , … , a N − 1 , a N d } 4 \left\{a_{1}, a_{2}^{d}, a_{3}, a_{4}^{d}, \ldots, a_{N-1}, a_{N}^{d}\right\}^{4} {a1,a2d,a3,a4d,…,aN−1,aNd}4。然后我们仅计算语义音频标记 a i d a_{i}^{d} aid的损失,而不是 a i − 1 a_{i-1} ai−1。
-
- 音频到文本交错。我们将训练序列公式化为 { a 1 , t 2 , a 3 , t 4 , … , a N − 1 , t N } \left\{a_{1}, t_{2}, a_{3}, t_{4}, \ldots, a_{N-1}, t_{N}\right\} {a1,t2,a3,t4,…,aN−1,tN}。我们仅计算文本标记 t i t_{i} ti的损失。
-
- 音频到语义标记 + 文本交错。我们将训练序列公式化为 { a 1 , a 2 d / t 2 , a 3 , a 3 d / t 4 , … , a N − 1 , a N d / t N } \left\{a_{1}, a_{2}^{d} / t_{2}, a_{3}, a_{3}^{d} / t_{4}, \ldots, a_{N-1}, a_{N}^{d} / t_{N}\right\} {a1,a2d/t2,a3,a3d/t4,…,aN−1,aNd/tN}。对于 a i d / t i a_{i}^{d} / t_{i} aid/ti,由于语义音频标记序列通常比文本标记序列长,预测语义标记类似于4.1.2节中的流式文本到语音任务。经验上,我们发现预测前几个语义标记很困难,因为模型需要同时预测下一个文本标记及其语义音频标记。我们通过在语义音频标记前附加6个特殊的空白标记(根据初步实验,6是生成质量和延迟之间的权衡结果)来解决这个问题,从而延迟预测第一个几个语义音频标记。
4 { }^{4} 4 第一段也可能是 a 1 d a_{1}^{d} a1d,最后一段也可能是 a N a_{N} aN。
4.1.4 预训练配方
我们从预训练的Qwen2.5 7B模型[76]初始化Kimi-Audio的音频LLM,并扩展其词汇表以包含语义音频标记和特殊标记。我们在上述预训练任务上进行预训练,对应的任务权重为
1
:
7
:
1
:
1
:
1
:
1
:
2
1: 7: 1: 1: 1: 1: 2
1:7:1:1:1:1:2,如表3所示。我们使用585B音频标记和585B文本标记进行1轮预训练。我们使用AdamW [48]优化器,学习率从
2
e
−
5
2 e^{-5}
2e−5到
2
e
−
6
2 e^{-6}
2e−6进行余弦衰减。我们使用
1
%
1 \%
1%标记进行学习率预热。
音频分词器中的连续声学特征提取模块从Whisper large-v3 [58]初始化,可以捕捉输入音频信号中固有的细粒度声学特性。在模型预训练的初始阶段(大约占预训练中的
20
%
20 \%
20%标记),此基于whisper的特征提取器参数保持冻结状态。随后,特征提取器解冻,使其参数与模型的其余部分一起微调,允许它更具体地适应训练数据的细微差别和目标任务的要求。
4.2 监督微调
4.2.1 公式化
在使用大量真实世界的音频和文本数据对Kimi-Audio进行预训练后,我们执行监督微调以赋予其指令跟随能力。我们有以下设计选择:1)考虑到下游任务多样化,我们不设置特殊的任务切换操作,而是使用自然语言作为每个任务的指令;2)对于指令,我们构建了音频和文本版本(即,音频由给定文本的Kimi-TTS零样本生成),并在训练期间随机选择一个;3)为了增强指令跟随能力的鲁棒性,我们通过LLM构建了200条ASR任务指令和30条其他任务指令,并为每个训练样本随机选择一条。如第3.2节所述,我们构建了约300,000小时的数据用于监督微调。
4.2.2 微调配方
如表1和表2所示,基于全面的消融实验,我们在每个数据源上对Kimi-Audio进行2-4轮微调。我们使用AdamW [48]优化器,学习率从 1 e − 5 1 e^{-5} 1e−5到 1 e − 6 1 e^{-6} 1e−6进行余弦衰减。我们使用 10 % 10 \% 10%标记进行学习率预热。
4.3 音频解码器的训练
我们分三个阶段训练音频解码器。首先,我们使用第3.1节中描述的预训练数据中的约1百万小时音频,预训练流匹配模型和声码器,以学习具有多样音色、韵律和质量的音频。其次,我们在相同的预训练数据上采用块状微调策略,动态块大小从0.5秒到3秒 [32]。最后,我们在Kimi-Audio发言人的高质量单人录音数据上进行微调。
5 推理和部署
Kimi-Audio旨在处理各种与音频相关的任务,例如语音识别、音频理解、音频到文本聊天和语音到语音对话。我们以实时语音-
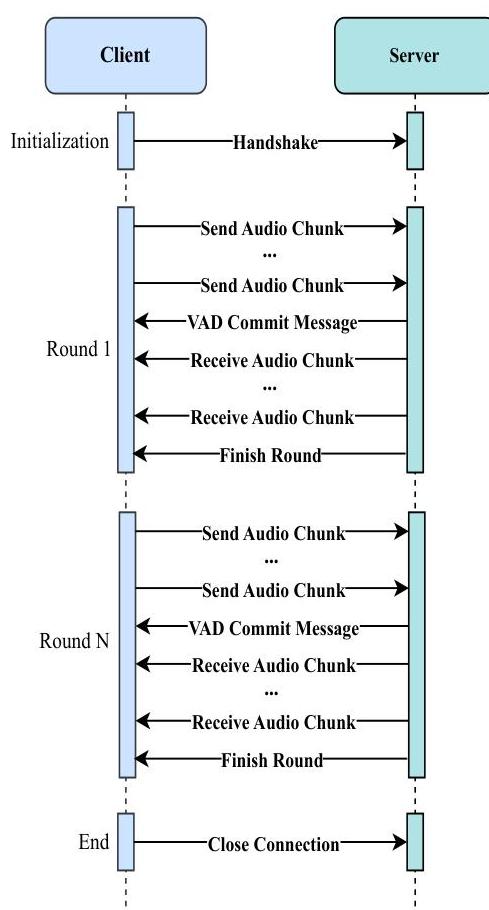
图4:Kimi-Audio中实时语音到语音对话的客户端-服务器通信。
到语音对话为例,说明Kimi-Audio部署中的实践,因为这项任务在基础设施和工程努力方面比其他音频任务更为复杂。我们首先介绍用户客户端(例如,Kimi APP或网页浏览器)与服务器(Kimi-Audio服务)之间实时语音对话的工作流程,然后描述产品部署的实践。
5.1 实时语音对话工作流程
用户客户端(例如,Kimi APP)上的用户讲话,音频数据被收集并流式传输到服务器。
在服务器端,语音活动检测(VAD)模块确定用户是否已停止讲话。
一旦用户停止讲话,服务器发送确认信号并启动Kimi-Audio模型的推理过程。
在推理过程中,客户端实时接收生成的音频块并开始为用户播放它们。
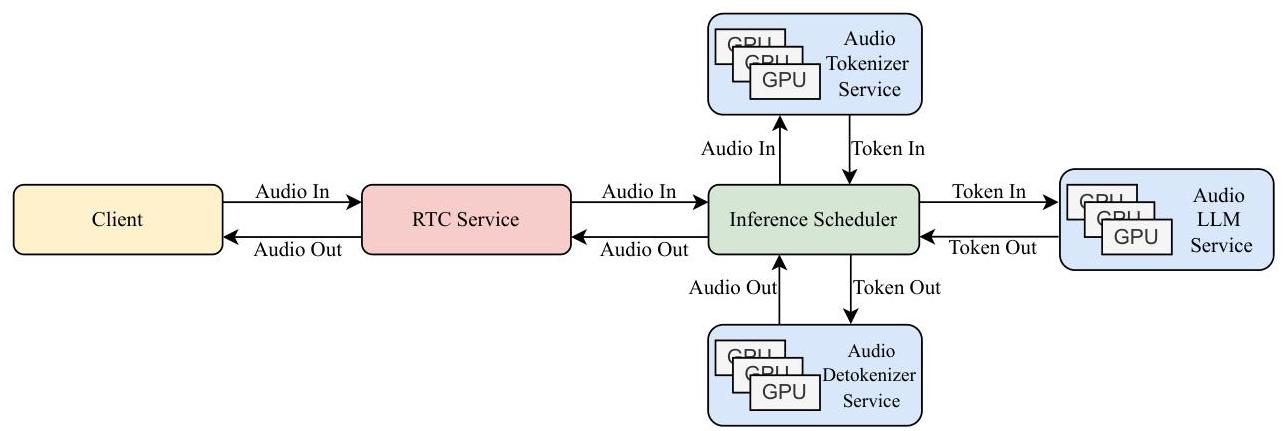
图5:Kimi-Audio中实时语音到语音对话的生产部署工作流程。
客户端(移动电话或网页浏览器)向用户播放接收到的音频块。
服务器端Kimi-Audio每轮推理的过程如下。首先,使用音频分词器将输入音频转换为离散语义标记和连续声学向量。接下来,通过连接系统提示标记、音频标记和对话历史标记来组装音频LLM的输入。然后将标记序列传递给音频LLM,生成输出标记。最后,使用解码器将输出标记转换回音频波形。
5.2 生产部署
如图5所示,在生产环境中,所有核心组件:音频分词器、音频LLM和音频解码器,都是计算密集型的,需要可扩展且高效的基础设施。为此,我们设计了生产部署架构如下。
Kimi-Audio RTC服务。该服务与客户端接口,接收用户的音频,将其转发到推理调度器,并将生成的音频块返回给客户端。我们使用WebRTC协议确保稳定且低延迟的连接。
推理调度器。推理调度器通过在存储后端中维护对话历史作为标记来管理对话流程。对于每次交互回合,它执行以下步骤:
- 调用分词器服务将用户的音频转换为标记。
-
- 通过组合新标记与对话历史来构造模型输入。
-
- 将输入发送到LLM服务以生成响应标记。
-
- 调用解码器服务将响应标记转换为音频输出。
此外,它将所有输出标记存储为正在进行的对话历史的一部分,以确保对话的连续性。
- 调用解码器服务将响应标记转换为音频输出。
分词器/解码器/LLM服务:这些服务处理模型推理,并配备了负载均衡器和多个推理实例以并行处理请求,确保可扩展性。
这种模块化架构确保Kimi-Audio能够有效地扩展以满足实时语音交互的性能需求,同时在生产中保持低延迟和高可用性。
6 评估
评估音频基础模型并与以前的最先进系统进行比较是一项具有挑战性的任务,因为音频社区存在一些固有问题。因此,我们首先在第6.1节中开发了一个公平、可重复和全面的音频基础模型评估工具包,然后在第6.2节中评估Kimi-Audio在包括语音识别、通用音频理解、音频到文本聊天和语音对话在内的各种音频处理任务上的表现,并与以前的系统进行比较以展示其优势。
6.1 评估工具包
即使一个音频基础模型完全开源,仍然很难重现其论文或技术报告中报告的相同结果,更不用说那些闭源模型了。我们分析了在各种音频处理任务中评估和比较音频基础模型所面临的挑战如下:
-
指标限制。当前的做法受到不一致的指标实现(例如,由于不同的文本规范化导致的词错误率计算变化)和不足的评估方法(例如,仅依赖于精确字符串匹配来评估像音频问答这样的任务无法捕捉复杂的LLM响应的语义正确性)的影响。
-
- 多样化的配置。模型性能对推理参数(如解码温度、系统提示和任务提示)的高度敏感性严重阻碍了可重复性。
-
- 缺乏生成评估。尽管在理解任务方面取得了进展,但评估生成音频响应的质量和连贯性仍缺乏基准。
为了解决这些关键限制,我们开发了一个开源的音频基础模型评估工具包,用于音频理解、生成和对话任务。它目前集成了并支持Kimi-Audio和一系列最近的音频LLM [11, 74, 84, 41, 28],并且可以用来评估任何其他音频基础模型。该工具包提供了以下特性和好处:
- 缺乏生成评估。尽管在理解任务方面取得了进展,但评估生成音频响应的质量和连贯性仍缺乏基准。
-
我们实现了标准化的WER计算(基于Qwen-2-Audio [11])并集成了GPT-4o-mini作为智能裁判(遵循[8]),用于像音频问答这样的任务。这种方法克服了指标不一致和简单字符串匹配的局限性,实现了公平比较。
-
- 我们的工具包提供了一个单一统一平台,支持多种模型和版本,简化了并列比较。它提供了一个定义和共享标准化推理参数和提示策略(“食谱”)的关键结构,直接解决了评估设置中的不一致性问题,并促进了不同研究工作的更大可重复性。
-
表4:Kimi-Audio和基线模型在ASR任务上的性能。最佳结果加粗显示。
| 数据集 | 模型 | 性能 (WER ↓ \downarrow ↓ ) |
| :–: | :–: | :–: |
| LibriSpeech [54] test-clean I test-other | Qwen2-Audio-base | 1.74 ∣ 4.04 1.74 \mid 4.04 1.74∣4.04 |
| | Baichuan-Audio-base | 3.02 ∣ 6.04 3.02 \mid 6.04 3.02∣6.04 |
| | Step-Audio-chat | 3.19 ∣ 10.67 3.19 \mid 10.67 3.19∣10.67 |
| | Qwen2.5-Omni | 2.37 ∣ 4.21 2.37 \mid 4.21 2.37∣4.21 |
| | Kimi-Audio | 1.28 | 2.42 |
| Fleurs [12] zh I en | Qwen2-Audio-base | 3.63 ∣ 5.20 3.63 \mid 5.20 3.63∣5.20 |
| | Baichuan-Audio-base | 4.15 ∣ 8.07 4.15 \mid 8.07 4.15∣8.07 |
| | Step-Audio-chat | 4.26 ∣ 8.56 4.26 \mid 8.56 4.26∣8.56 |
| | Qwen2.5-Omni | 2.92 ∣ 4.17 2.92 \mid \mathbf{4 . 1 7} 2.92∣4.17 |
| | Kimi-Audio | 2.69 | 4.44 |
| AISHELL-1 [4] | Qwen2-Audio-base | 1.52 |
| | Baichuan-Audio-base | 1.93 |
| | Step-Audio-chat | 2.14 |
| | Qwen2.5-Omni | 1.13 |
| | Kimi-Audio | 0.60 |
| AISHELL-2 [17] ios | Qwen2-Audio-base | 3.08 |
| | Baichuan-Audio-base | 3.87 |
| | Step-Audio-chat | 3.89 |
| | Qwen2.5-Omni | 2.56 |
| | Kimi-Audio | 2.56 |
| WenetSpeech [85] test-meeting I test-net | Qwen2-Audio-base | 8.40 ∣ 7.64 8.40 \mid 7.64 8.40∣7.64 |
| | Baichuan-Audio-base | 13.28 ∣ 10.13 13.28 \mid 10.13 13.28∣10.13 |
| | Step-Audio-chat | 10.83 ∣ 9.47 10.83 \mid 9.47 10.83∣9.47 |
| | Qwen2.5-Omni | 7.71 ∣ 6.04 7.71 \mid 6.04 7.71∣6.04 |
| | Kimi-Audio | 6.28 | 5.37 |
| Kimi-ASR内部测试集子集1 I 子集2 | Qwen2-Audio-base | 2.31 ∣ 3.24 2.31 \mid 3.24 2.31∣3.24 |
| | Baichuan-Audio-base | 3.41 ∣ 5.60 3.41 \mid 5.60 3.41∣5.60 |
| | Step-Audio-chat | 2.82 ∣ 4.74 2.82 \mid 4.74 2.82∣4.74 |
| | Qwen2.5-Omni | 1.53 ∣ 2.68 1.53 \mid 2.68 1.53∣2.68 |
| | Kimi-Audio | 1.42 | 2.44 | -
我们记录并发布了一个评估基准,用于从以下角度测试音频LLM在语音对话中的能力:1)语音对情感、速度和口音的控制;2)共情对话;3)多样风格,如讲故事和绕口令。
我们将此工具包开源给社区 https://github.com/MoonshotAI/Kimi-Audio-Evalkit。我们相信这个工具包可以作为一个有价值的资产,通过促进更可靠和可比较的基准测试来推动领域的发展。我们积极鼓励研究人员和开发人员利用它,通过添加新模型和数据集来贡献,并帮助完善标准化评估协议和推理配方。这样,我们可以为音频社区建立一个更好的生态系统。
6.2 评估结果
在本节中,基于我们的评估工具包,我们详细介绍了Kimi-Audio在一系列音频处理任务中的评估,包括自动语音识别(ASR)、
表5:Kimi-Audio和基线模型在音频理解任务上的性能。最佳结果加粗显示。
| 数据集 | 模型 | 性能 ↑ \uparrow ↑ |
|---|---|---|
| MMAU [60] 音乐 I 声音 I 语音 | Qwen2-Audio-base | 58.98 ∣ 69.07 ∣ 52.55 58.98 \mid 69.07 \mid 52.55 58.98∣69.07∣52.55 |
| Baichuan-chat | 49.10 | |
| GLM-4-Voice | 38.92 | |
| Step-Audio-chat | 49.40 | |
| Qwen2.5-Omni | 62.16 | |
| Kimi-Audio | 61.68 | |
| ClothoAQA [43] 测试 I 开发 | Qwen2-Audio-base | 71.73 |
| Baichuan-chat | 48.02 | |
| Step-Audio-chat | 45.84 | |
| Qwen2.5-Omni | 72.86 | |
| Kimi-Audio | 71.24 | |
| VocalSound [23] | Qwen2-Audio-base | 93.82 |
| Baichuan-Audio-base | 58.17 | |
| Step-Audio-chat | 28.58 | |
| Qwen2.5-Omni | 93.73 | |
| Kimi-Audio | 94.85 | |
| Nonspeech7k [59] | Qwen2-Audio-base | 87.17 |
| Baichuan-chat | 59.03 | |
| Step-Audio-chat | 21.38 | |
| Qwen2.5-Omni | 69.89 | |
| Kimi-Audio | 93.93 | |
| MELD [56] | Qwen2-Audio-base | 51.23 |
| Baichuan-chat | 23.59 | |
| Step-Audio-chat | 33.54 | |
| Qwen2.5-Omni | 49.83 | |
| Kimi-Audio | 59.13 | |
| TUT2017 [53] | Qwen2-Audio-base | 33.83 |
| Baichuan-Audio-base | 27.9 | |
| Step-Audio-chat | 7.41 | |
| Qwen2.5-Omni | 43.27 | |
| Kimi-Audio | 65.25 | |
| CochlScene [31] 测试 I 开发 | Qwen2-Audio-base | 52.69 |
| Baichuan-Audio-base | 34.93 | |
| Step-Audio-chat | 10.06 | |
| Qwen2.5-Omni | 63.82 | |
| Kimi-Audio | 79.84 |
- 我们记录并发布了评估基准,用于从以下角度测试音频LLM在语音对话中的能力:1)语音对情感、速度和口音的控制;2)共情对话;3)多样化风格,如讲故事和绕口令。
我们将此工具包开源给社区 https://github.com/MoonshotAI/Kimi-Audio-Evalkit。我们相信这个工具包可以作为一个有价值的资产,通过促进更可靠和可比较的基准测试来推动领域的发展。我们积极鼓励研究人员和开发人员利用它,通过添加新模型和数据集来贡献,并帮助完善标准化评估协议和推理配方。这样,我们可以为音频社区建立一个更好的生态系统。
6.2 评估结果
在本节中,基于我们的评估工具包,我们详细介绍了Kimi-Audio在一系列音频处理任务中的评估,包括自动语音识别(ASR),
表5:Kimi-Audio和基线模型在音频理解任务上的性能。最佳结果加粗显示。
| 数据集 | 模型 | 性能 ↑ \uparrow ↑ |
|---|---|---|
| MMAU [60] 音乐 I 声音 I 语音 | Qwen2-Audio-base | 58.98 ∣ 69.07 ∣ 52.55 58.98 \mid 69.07 \mid 52.55 58.98∣69.07∣52.55 |
| Baichuan-chat | 49.10 | |
| GLM-4-Voice | 38.92 | |
| Step-Audio-chat | 49.40 | |
| Qwen2.5-Omni | 62.16 | |
| Kimi-Audio | 61.68 | |
| ClothoAQA [43] 测试 I 开发 | Qwen2-Audio-base | 71.73 |
| Baichuan-chat | 48.02 | |
| Step-Audio-chat | 45.84 | |
| Qwen2.5-Omni | 72.86 | |
| Kimi-Audio | 71.24 | |
| VocalSound [23] | Qwen2-Audio-base | 93.82 |
| Baichuan-Audio-base | 58.17 | |
| Step-Audio-chat | 28.58 | |
| Qwen2.5-Omni | 93.73 | |
| Kimi-Audio | 94.85 | |
| Nonspeech7k [59] | Qwen2-Audio-base | 87.17 |
| Baichuan-chat | 59.03 | |
| Step-Audio-chat | 21.38 | |
| Qwen2.5-Omni | 69.89 | |
| Kimi-Audio | 93.93 | |
| MELD [56] | Qwen2-Audio-base | 51.23 |
| Baichuan-chat | 23.59 | |
| Step-Audio-chat | 33.54 | |
| Qwen2.5-Omni | 49.83 | |
| Kimi-Audio | 59.13 | |
| TUT2017 [53] | Qwen2-Audio-base | 33.83 |
| Baichuan-Audio-base | 27.9 | |
| Step-Audio-chat | 7.41 | |
| Qwen2.5-Omni | 43.27 | |
| Kimi-Audio | 65.25 | |
| CochlScene [31] 测试 I 开发 | Qwen2-Audio-base | 52.69 |
| Baichuan-Audio-base | 34.93 | |
| Step-Audio-chat | 10.06 | |
| Qwen2.5-Omni | 63.82 | |
| Kimi-Audio | 79.84 |
我们使用已建立的基准和内部测试集将Kimi-Audio与其他音频基础模型(Qwen2-Audio [11]、Baichuan-Audio [41]、Step-Audio [28]、GLM-4-Voice [84] 和 Qwen2.5-Omini [73])进行比较。
6.2.1 自动语音识别
Kimi-Audio 的 ASR 功能在涵盖多种语言和声学条件的不同数据集上进行了评估。如表 4 所示,Kimi-Audio 在先前模型中始终表现出卓越的性能。我们在这些数据集上报告词错率 (WER),其中较低的值表示更好的性能。
表 6:Kimi-Audio 和基线模型在音频到文本聊天任务上的性能。最佳结果加粗显示。
| 数据集 | 模型 | 性能 ↑ \uparrow ↑ |
|---|---|---|
| OpenAudioBench [41] AlpacaEval I Llama Questions I Reasoning QA I TriviaQA I Web Questions | Qwen2-Audio-chat | 57.19 ∣ 69.67 ∣ 42.77 ∣ 40.30 ∣ 45.20 57.19 \mid 69.67 \mid 42.77 \mid 40.30 \mid 45.20 57.19∣69.67∣42.77∣40.30∣45.20 |
| Baichuan-chat | 59.65 ∣ 74.33 ∣ 46.73 ∣ 55.40 ∣ 58.70 59.65 \mid 74.33 \mid 46.73 \mid 55.40 \mid 58.70 59.65∣74.33∣46.73∣55.40∣58.70 | |
| GLM-4-Voice | 57.89 ∣ 76.00 ∣ 47.43 ∣ 51.80 ∣ 55.40 57.89 \mid 76.00 \mid 47.43 \mid 51.80 \mid 55.40 57.89∣76.00∣47.43∣51.80∣55.40 | |
| Step-Audio-chat | 56.53 ∣ 72.33 ∣ 60.00 ∣ 56.80 ∣ 73.00 56.53 \mid 72.33 \mid 60.00 \mid 56.80 \mid \mathbf{7 3 . 0 0} 56.53∣72.33∣60.00∣56.80∣73.00 | |
| Qwen2.5-Omni | 72.76 ∣ 75.33 ∣ 63.76 ∣ 57.06 ∣ 62.80 72.76 \mid 75.33 \mid \mathbf{6 3 . 7 6} \mid 57.06 \mid 62.80 72.76∣75.33∣63.76∣57.06∣62.80 | |
| Kimi-Audio | 75.73 ∣ 79.33 ∣ 58.02 ∣ 62.10 ∣ 70.20 \mathbf{7 5 . 7 3} \mid \mathbf{7 9 . 3 3} \mid 58.02 \mid \mathbf{6 2 . 1 0} \mid 70.20 75.73∣79.33∣58.02∣62.10∣70.20 | |
| VoiceBench [8] AlpacaEval I CommonEval I SD-QA I MMSU | Qwen2-Audio-chat | 3.69 ∣ 3.40 ∣ 35.35 ∣ 35.43 3.69 \mid 3.40 \mid 35.35 \mid 35.43 3.69∣3.40∣35.35∣35.43 |
| Baichuan-chat | 4.00 ∣ 3.39 ∣ 49.64 ∣ 48.80 4.00 \mid 3.39 \mid 49.64 \mid 48.80 4.00∣3.39∣49.64∣48.80 | |
| GLM-4-Voice | 4.06 ∣ 3.48 ∣ 43.31 ∣ 40.11 4.06 \mid 3.48 \mid 43.31 \mid 40.11 4.06∣3.48∣43.31∣40.11 | |
| Step-Audio-chat | 3.99 ∣ 2.99 ∣ 46.84 ∣ 28.72 3.99 \mid 2.99 \mid 46.84 \mid 28.72 3.99∣2.99∣46.84∣28.72 | |
| Qwen2.5-Omni | 4.33 ∣ 3.84 ∣ 57.41 ∣ 56.38 4.33 \mid 3.84 \mid 57.41 \mid 56.38 4.33∣3.84∣57.41∣56.38 | |
| Kimi-Audio | 4.46 ∣ 3.97 ∣ 63.12 ∣ 62.17 \mathbf{4 . 4 6} \mid \mathbf{3 . 9 7} \mid \mathbf{6 3 . 1 2} \mid \mathbf{6 2 . 1 7} 4.46∣3.97∣63.12∣62.17 | |
| VoiceBench [8] OpenBookQA I IFEval I AdvBench I Avg | Qwen2-Audio-chat | 49.01 ∣ 22.57 ∣ 98.85 ∣ 54.72 49.01 \mid 22.57 \mid 98.85 \mid 54.72 49.01∣22.57∣98.85∣54.72 |
| Baichuan-chat | 63.30 ∣ 41.32 ∣ 86.73 ∣ 62.51 63.30 \mid 41.32 \mid 86.73 \mid 62.51 63.30∣41.32∣86.73∣62.51 | |
| GLM-4-Voice | 52.97 ∣ 24.91 ∣ 88.08 ∣ 57.17 52.97 \mid 24.91 \mid 88.08 \mid 57.17 52.97∣24.91∣88.08∣57.17 | |
| Step-Audio-chat | 31.87 ∣ 29.19 ∣ 65.77 ∣ 48.86 31.87 \mid 29.19 \mid 65.77 \mid 48.86 31.87∣29.19∣65.77∣48.86 | |
| Qwen2.5-Omni | 79.12 ∣ 53.88 ∣ 99.62 ∣ 72.83 79.12 \mid 53.88 \mid 99.62 \mid 72.83 79.12∣53.88∣99.62∣72.83 | |
| Kimi-Audio | 83.52 ∣ 61.10 ∣ 100.00 ∣ 76.93 \mathbf{8 3 . 5 2} \mid \mathbf{6 1 . 1 0} \mid \mathbf{1 0 0 . 0 0} \mid \mathbf{7 6 . 9 3} 83.52∣61.10∣100.00∣76.93 |
值得注意的是,Kimi-Audio在广泛使用的LibriSpeech [54]基准测试中取得了最佳结果,test-clean上的错误率为1.28,test-other上的错误率为2.42,显著优于Qwen2-Audio-base和Qwen2.5-Omni等模型。对于普通话ASR基准测试,Kimi-Audio在AISHELL-1 [4] (0.60)和AISHELL-2 ios [17] (2.56)上达到了SOTA结果。此外,它在具有挑战性的WenetSpeech [85]数据集上表现出色,在test-meeting和test-net上均达到了最低错误率。最后,对我们内部的Kimi-ASR测试集的评估证实了模型的稳健性。这些结果展示了Kimi-Audio在各种领域和语言中的强大ASR能力。
6.2.2 音频理解
除了语音识别外,我们还评估了Kimi-Audio理解各种音频信号的能力,包括音乐、声音事件和语音。表5总结了在各种音频理解基准测试中的表现,一般而言,更高的分数表示更好的表现。
在MMAU基准测试 [60] 中,Kimi-Audio在声音类别(73.27)和语音类别(60.66)上表现出色。同样,它在MELD [56]语音情绪理解任务上得分最高,达到59.13。Kimi-Audio还在非语音声音分类(VocalSound [23] 和 Nonspeech7k [59])以及声学场景分类(TUT2017 [53] 和 CochlScene [31])任务中领先。这些结果突显了Kimi-Audio在解释复杂声学信息方面的高级能力,而不仅仅是简单的语音识别。
6.2.3 音频到文本聊天
我们使用OpenAudioBench [41]和VoiceBench基准测试评估Kimi-Audio基于音频输入进行文本对话的能力。这些基准测试评估了诸如指令跟随、问题回答和推理等方面。性能指标是
表7:Kimi-Audio和基线模型在语音对话上的性能。最佳结果加粗显示,次佳结果下划线显示。
| 模型 | 速度控制 | 口音控制 | 情感控制 | 共情 | 风格控制 | 平均 |
|---|---|---|---|---|---|---|
| GPT-4o | 4.21 ‾ \underline{4.21} 4.21 | 3.65 \mathbf{3 . 6 5} 3.65 | 4.05 | 3.87 \mathbf{3 . 8 7} 3.87 | 4.54 \mathbf{4 . 5 4} 4.54 | 4.06 \mathbf{4 . 0 6} 4.06 |
| Step-Audio-chat | 3.25 | 2.87 | 3.33 | 3.05 | 4.14 ‾ \underline{4.14} 4.14 | 3.33 |
| GLM-4-Voice | 3.83 | 3.51 | 3.77 | 3.07 | 4.04 | 3.65 |
| GPT-4o-mini | 3.15 | 2.71 | 4.24 ‾ \underline{4.24} 4.24 | 3.16 | 4.01 | 3.45 |
| Kimi-Audio | 4.30 \mathbf{4 . 3 0} 4.30 | 3.45 ‾ \underline{3.45} 3.45 | 4.27 \mathbf{4 . 2 7} 4.27 | 3.39 ‾ \underline{3.39} 3.39 | 4.09 | 3.90 ‾ \underline{3.90} 3.90 |
特定于基准,较高的分数表示更好的对话能力。结果如表6所示。
在OpenAudioBench上,Kimi-Audio在AlpacaEval、Llama Questions和TriviaQA等多个子任务上实现了最先进的性能,并在Reasoning QA和Web Questions上取得了高度竞争的性能。
VoiceBench评估进一步证实了Kimi-Audio的优势。它在AlpacaEval(4.46)、CommonEval(3.97)、SD-QA(63.12)、MMSU(62.17)、OpenBookQA(83.52)、Advbench(100.00)和IFEval(61.10)上持续超越所有对比模型。Kimi-Audio在这些综合基准上的整体表现展示了其在基于音频的对话和复杂推理任务中的卓越能力。
6.2.4 语音对话
最后,我们基于主观评价在多个维度上评估了Kimi-Audio的端到端语音对话能力。如表7所示,Kimi-Audio与GPT-4o和GLM-4-Voice等模型进行了比较,评分范围为1-5,分数越高越好。
排除GPT-4o,Kimi-Audio在情感控制、共情和速度控制方面取得了最高分。虽然GLM-4-Voice在口音控制方面表现略好,但Kimi-Audio的整体平均得分3.90分更高。这一得分高于Step-Audio-chat(3.33)、GPT-4o-mini(3.45)和GLM-4-Voice(3.65),与GPT-4o(4.06)相比差距较小。总体而言,评估结果显示Kimi-Audio在生成富有表现力和可控的语音方面表现出色。
7 相关工作
将大型语言模型(LLMs)应用于音频任务已经在广泛的领域内带来了显著的进步,包括自动语音识别(ASR)、音频理解、文本到语音合成(TTS)、通用音频生成和基于语音的人机交互。这些努力探讨了如何通过将音频视为可分词的序列来弥合原始声学信号和语言推理之间的差距,从而使LLMs能够以类似语言的方式处理或生成音频。
ASR和音频理解 许多基于LLM的系统已被开发出来以改进自动语音识别(ASR)和更广泛的音频理解任务。Whisper [58] 作为一个强大的音频编码器,当与大型语言模型(LLMs)结合时,显著增强了语音理解系统的性能。这种方法已在Qwen-Audio [10]、Qwen2-Audio [11]、SALMONN [63] 和 OSUM [21] 等模型中成功应用。
然而,这些系统大多局限于理解任务,不原生支持音频输出。
TTS和音频生成 对于语音合成和通用音频生成,例如 AudioLM [3]、VALL-E [70] 和 LLASA [80] 等模型通过对神经编解码器进行音频分词,并使用仅解码器的语言模型进行自回归生成。其他努力如 UniAudio [77] 和 VoiceBox [37] 则通过混合分词或流匹配来扩展这些方法,以提高质量和控制。尽管这些模型可以生成高保真音频,但它们通常只关注生成,缺乏理解和对话能力或指令跟随的语音交互。
语音对话和实时对话 最近的模型已经朝着实现实时、端到端的语音交互迈进。Moshi [14]、GLM-4-Voice [84] 和 Mini-Omni [72] 采用交错或并行解码以支持文本和音频标记的同时生成,促进低延迟对话系统。OmniFlatten [86] 引入了一种渐进式训练管道,以适应冻结的LLM进行全双工对话。LLaMA-Omni [18] 和 Freeze-Omni [71] 通过流式解码器或多任务对齐策略进一步细化双工语音交互。然而,这些系统往往过于依赖纯语音数据集,并因有限的预训练而妥协了语言建模的质量或通用性。
朝向通用音频-语言基础模型 近期的一些工作旨在在一个单一的多模态模型中统一理解和生成。Baichuan-Audio [41] 使用多码本离散化来捕获语义和声学特征,实现实时交互和强大的问答能力。然而,其对语音领域的关注限制了其更广泛的适用性,特别是在音乐或环境声音等非语音音频任务上。另一方面,Step-Audio [28] 提供了一个强大的解决方案,用于实时语音交互,采用了一个拥有130B参数的统一语音-文本多模态模型。尽管Step-Audio表现出强劲的性能,但其对合成语音数据生成的依赖以及与其130B参数相关的高计算成本,对更广泛的用户群体来说构成了显著的可访问性和成本效益障碍。Qwen2.5-Omni [74] 引入了Thinker-Talker架构以实现文本和语音的同时解码,并在基准测试中取得了强劲的表现,但其设计主要强调流式推理,缺乏对原始音频的广泛预训练。
Kimi-Audio Kimi-Audio通过引入一个真正通用且开源的音频基础模型,推进了这一领域的进步,该模型在一个框架内支持语音识别、音频理解、音频生成和语音对话。它采用了结合Whisper派生的连续声学特征和离散语义标记(12.5 Hz)的混合输入表示,确保丰富的感知和高效建模。音频LLM从文本LLM初始化,具有双重生成头用于文本和音频,并配有一个基于块状流匹配解码器和BigVGAN [38] 来生成富有表现力和低延迟的语音。
最重要的是,Kimi-Audio在跨语音、音乐和环境声的1300万小时精心策划的音频数据上进行了广泛的多模态预训练,规模远超以往工作。预训练任务包括仅音频、仅文本、音频到文本和交错模态,使模型能够学习可泛化的音频推理并保持强大的语言能力。这之后通过跨多种任务的基于指令的微调,使Kimi-Audio在ASR、通用音频理解、音频-文本聊天和语音对话基准测试中实现了最先进的结果。与现有的模型相比,这些模型要么范围有限,要么缺乏预训练,要么未公开可用,Kimi-Audio是一个完全开源、预训练、指令跟随和实时能力的模型。其全面覆盖、可扩展架构和广泛的任务对齐使其成为通用音频智能的重要一步。
8 挑战与未来趋势
尽管Kimi-Audio在构建通用音频基础模型方面取得了显著进展,但在追求更强大和更智能的音频处理系统的过程中仍存在若干挑战。我们描述了这些挑战并指出了几个令人兴奋的未来方向如下。
- 从音频转录到音频描述。当前音频基础模型的预训练范式通常利用音频-文本预训练来弥合文本和音频之间的差距,其中文本是通过ASR转录从音频(语音)中获得的。然而,文本转录专注于所说词语的内容(说了什么),忽略了音频中的重要信息,如副语言信息(例如情感、风格、音色、语气)、声学场景和非语言声音。因此,引入描述性文本(即音频字幕)以描绘更丰富的上下文中的音频至关重要。结合音频的转录文本和描述性文本使模型能够更好地理解和生成不仅限于口语语言,还包括复杂声学环境的内容,从而为更细致、多模态的音频处理系统铺平道路,进而实现更通用和多功能的音频智能。
-
- 更好的音频表示。当前音频利用语义标记或声学标记作为其表示。语义标记通常通过基于ASR的辅助损失获得,专注于转录导向的信息,无法捕捉理解与生成所需的丰富声学细节。声学标记通常通过音频重建损失学习,专注于描述导向的声学细节,无法捕捉连接到文本智能至关重要的抽象语义信息。一个有价值的研究方向是开发整合转录导向的语义信息和描述导向的声学特征的表示,涵盖诸如说话人身份、情感和环境声音等细微差别,同时保持高层次的抽象信息,这对于更复杂的音频理解和生成至关重要。
-
- 在音频建模中抛弃ASR和TTS。当前的音频基础模型在预训练和微调阶段都严重依赖ASR和TTS来生成训练数据。训练数据的质量受到ASR的文本识别准确性和TTS合成语音的表现力/多样性/质量的限制。这种方式使得音频模型表现得像现有ASR和TTS系统的高级蒸馏版本。结果,它们很难超越ASR/TTS的天花板,并且无法实现真正的自主音频智能。一个重要的未来方向是训练音频模型时不依赖基于ASR/TTS的伪音频数据,而是依赖原生音频数据,这可以带来更高的性能上限。
参考文献
[1] Rosana Ardila 等人. “Common Voice: 一个大规模多语言语音语料库”. In: arXiv 预印本 arXiv:1912.06670 (2019).
[2] 北京人工智能研究院 (BAAI). “Infinity Instruct”. In: arXiv 预印本 arXiv:2406.XXXX (2024).
[3] Zalán Borsos 等人. “Audiolm: 一种用于音频生成的语言建模方法”. In: IEEE/ACM 音频、语音和语言处理事务 31 (2023), pp. 2523-2533.
[4] Hui Bu 等人. “Aishell-1: 一个开源普通话语音语料库及其语音识别基线”. In: 2017 第20届国际语音数据库与语音输入输出系统评估协调委员会东方分会会议 (O-COCOSDA). IEEE. 2017, pp. 1-5.
[5] Guoguo Chen 等人. “Gigaspeech: 一个包含10,000小时转录音频的多领域 ASR 语料库”. In: arXiv 预印本 arXiv:2106.06909 (2021).
[6] Honglie Chen 等人. “Vggsound: 一个大规模的视听数据集”. In: ICASSP 2020 - 2020 IEEE 国际声学、语音和信号处理会议 (ICASSP). IEEE. 2020, pp. 721-725.
[7] Qian Chen 等人. “Minmo: 一个无缝语音交互的多模态大语言模型”. In: arXiv 预印本 arXiv:2501.06282 (2025).
[8] Yiming Chen 等人. “VoiceBench: 基于LLM的语音助手基准测试”. In: arXiv 预印本 arXiv:2410.17196 (2024).
[9] Zesen Cheng 等人. “VideoLlama 2: 推进视频-LLMs 中的空间-时间建模和音频理解”. In: arXiv 预印本 arXiv:2406.07476 (2024).
[10] Yunfei Chu 等人. “Qwen-audio: 通过统一的大规模音频-语言模型推进通用音频理解”. In: arXiv 预印本 arXiv:2311.07919 (2023).
[11] Yunfei Chu 等人. “Qwen2-audio 技术报告”. In: arXiv 预印本 arXiv:2407.10759 (2024).
[12] Alexis Conneau 等人. “Fleurs: 少样本学习评估语音的通用表示”. In: 2022 IEEE 语音技术研讨会 (SLT). IEEE. 2023, pp. 798-805.
[13] DeepSeek-AI. DeepSeek-V3 技术报告. 2024. arXiv: 2412.19437 [cs. CL]. URL: https://arxiv. org/abs/2412.19437.
[14] Alexandre Défossez 等人. “Moshi: 一个用于实时对话的语音-文本基础模型”. In: arXiv 预印本 arXiv:2410.00037 (2024).
[15] Chandeepa Dissanayake 等人. OpenBezoar: 小型、成本效益高且开放的混合指令数据训练模型. 2024. arXiv: 2404.12195 [cs. CL].
[16] Konstantinos Drossos, Samuel Lipping 和 Tuomas Virtanen. “Clotho: 一个音频字幕数据集”. In: ICASSP 2020-2020 IEEE 国际声学、语音和信号处理会议 (ICASSP). IEEE. 2020, pp. 736-740.
[17] Jiayu Du 等人. “Aishell-2: 将普通话 ASR 研究转化为工业规模”. In: arXiv 预印本 arXiv:1808.10583 (2018).
[18] Qingkai Fang 等人. “Llama-omni: 大语言模型的无缝语音交互”. In: arXiv 预印本 arXiv:2409.06666 (2024).
[19] Eduardo Fonseca 等人. “FSD50K: 一个人类标注的声音事件开放数据集”. In: IEEE/ACM 音频、语音和语言处理事务 30 (2021), pp. 829-852.
[20] Zhifu Gao 等人. “Paraformer: 快速而准确的非自回归端到端语音识别并行变换器”. In: arXiv 预印本 arXiv:2206.08317 (2022).
[21] Xuelong Geng 等人. “OSUM: 学术界资源有限条件下推进开放语音理解模型”. In: arXiv 预印本 arXiv:2501.13306 (2025).
[22] Sreyan Ghosh 等人. “GAMA: 具有先进音频理解和复杂推理能力的大型音频-语言模型”. In: arXiv 预印本 arXiv:2406.11768 (2024).
[23] Yuan Gong, Jin Yu 和 James Glass. “VocalSound: 一个提高人类发声识别的数据集”. In: ICASSP 2022 - 2022 IEEE 国际声学、语音和信号处理会议 (ICASSP). 2022, pp. 151-155. DOI: 10.1109/ICASSP43922.2022.9746828.
[24] Aaron Grattafiori 等人. “The llama 3 herd of models”. In: arXiv 预印本 arXiv:2407.21783 (2024).
[25] Haorui He 等人. “Emilia: 一个大规模、广泛、多语言和多样化的语音生成数据集”. In: arXiv 预印本 arXiv:2501.15907 (2025).
[26] Haorui He 等人. “Emilia: 一个用于大规模语音生成的广泛、多语言和多样化语音数据集”. In: 2024 IEEE 语音技术研讨会 (SLT). IEEE. 2024, pp. 885-890.
[27] T. Heittola 等人. TAU Urban Acoustic Scenes 2022 Mobile, Development dataset. Zenodo. Mar. 2022. DoI: 10.5281/zenodo.6337421.
[28] Ailin Huang 等人. “Step-audio: 统一理解与生成在智能语音交互中”. In: arXiv 预印本 arXiv:2502.11946 (2025).
[29] Aaron Hurst 等人. “GPT-4o 系统卡”. In: arXiv 预印本 arXiv:2410.21276 (2024).
[30] Philip Jackson 和 Sana ul haq. Surrey Audio-Visual Expressed Emotion (SAVEE) 数据库. Apr. 2011.
[31] Il-Young Jeong 和 Jeongsoo Park. “Cochlscene: 使用众包获取声学场景数据”. In: 2022 亚太信号与信息处理协会年会和会议 (APSIPA ASC). IEEE. 2022, pp. 17-21.
[32] Zeqian Ju 等人. “MoonCast: 高质量零样本播客生成”. In: arXiv 预印本 arXiv:2503.14345 (2025).
[33] Wei Kang 等人. “Libriheavy: 一个带有标点符号和上下文的50,000小时ASR语料库”. In: ICASSP 2024-2024 IEEE 国际声学、语音和信号处理会议 (ICASSP). IEEE. 2024, pp. 10991-10995.
[34] Chris Dongjoo Kim 等人. “AudioCaps: 为野外音频生成标题”. In: 2019 年北美计算语言学协会会议论文集:人类语言技术,第1卷(长篇和短篇论文). 2019, pp. 119-132.
[35] Zhifeng Kong 等人. “Audio Flamingo: 一个具有少样本学习和对话能力的新型音频语言模型”. In: arXiv 预印本 arXiv:2402.01831 (2024).
[36] Nathan Lambert 等人. “Tulu 3: 推动开放语言模型后训练的前沿”. In: arXiv 预印本 arXiv:2411.15124 (2024).
[37] Matthew Le 等人. “Voicebox: 规模化文本引导的多语言通用语音生成”. In: Advances in neural information processing systems 36 (2023), pp. 14005-14034.
[38] Sang-gil Lee 等人. “BigVGAN: 一个具有大规模训练的通用神经声码器”. In: arXiv 预印本 arXiv:2206.04658 (2022).
[39] Guangyao Li 等人. “Learning to answer questions in dynamic audio-visual scenarios”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, pp. 19108-19118.
[40] Jia Li 等人. “NuminaMath: AI4Maths 中最大的公共数据集,包含86万对竞赛数学问题和解决方案”. In: Hugging Face repository 13 (2024), p. 9.
[41] Tianpeng Li 等人. “Baichuan-audio: 一个统一的端到端语音交互框架”. In: arXiv 预印本 arXiv:2502.17239 (2025).
[42] Wing Lian 等人. OpenOrca: 一个开源的GPT增强FLAN推理轨迹数据集. https://https: //huggingface.co/datasets/Open-Orca/OpenOrca. 2023.
[43] Samuel Lipping 等人. “Clotho-AQA: 一个用于音频问答的众包数据集”. In: 2022 30th 欧洲信号处理会议 (EUSIPCO). IEEE. 2022, pp. 1140-1144.
[44] Jingyuan Liu 等人. Muon 对LLM训练具有可扩展性. 2025. arXiv: 2502.16982 [cs.LG]. URL: https: //arxiv.org/abs/2502.16982.
[45] Rui-Bo Liu 等人. “基于LLM和语音分词的可信音频生成”. In: 2024 IEEE 第14届国际中文语音处理研讨会 (ISCSLP). IEEE. 2024, pp. 591-595.
[46] Songting Liu. “Zero-shot Voice Conversion with Diffusion Transformers”. In: arXiv preprint arXiv:2411.09943 (2024).
[47] Steven R Livingstone 和 Frank A Russo. “The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): 一个动态、多模态的北美英语面部和语音表达集合”. In: PloS one 13.5 (2018), e0196391.
[48] Ilya Loshchilov 和 Frank Hutter. “Decoupled weight decay regularization”. In: arXiv preprint arXiv:1711.05101 (2017).
[49] Yi Luo 和 Jianwei Yu. “Music Source Separation With Band-Split RNN”. In: IEEE/ACM Transactions on Audio, Speech, and Language Processing 31 (2023), pp. 1893-1901. DOI: 10.1109/TASLP.2023.3271145.
[50] Linhan Ma 等人. “Wenetspeech4tts: 一个用于大规模语音生成模型基准的12,800小时普通话TTS语料库”. In: arXiv preprint arXiv:2406.05763 (2024).
[51] Irene Martín-Morató 和 Annamaria Mesaros. “What is the ground truth? reliability of multi-annotator data for audio tagging”. In: 2021 29th 欧洲信号处理会议 (EUSIPCO). IEEE. 2021, pp. 76-80.
[52] Xinhao Mei 等人. “Wavcaps: 一个由ChatGPT辅助的弱标签音频字幕数据集,用于音频-语言多模态研究”. In: IEEE/ACM Transactions on Audio, Speech, and Language Processing (2024).
[53] Annamaria Mesaros, Toni Heittola, 和 Tuomas Virtanen. “TUT Database for Acoustic Scene Classification and Sound Event Detection”. In: 第24届欧洲信号处理会议 2016 (EUSIPCO 2016). 布达佩斯,匈牙利,2016.
[54] Vassil Panayotov 等人. “Librispeech: 基于公共领域有声书的ASR语料库”. In: 2015 IEEE 国际声学、语音和信号处理会议 (ICASSP). IEEE. 2015, pp. 5206-5210.
[55] Karol J. Piczak. “ESC: Environmental Sound Classification 数据集”. In: 第23届年度 ACM 多媒体会议论文集. 布里斯班,澳大利亚: ACM Press, 2015年10月13日, pp. 1015-1018. ISBN: 978-1-4503-3459-4. DOI:
10.1145
/
2733373.2806390
10.1145 / 2733373.2806390
10.1145/2733373.2806390. URL: http://dl.acm.org/citation.cfm?doid= 2733373.2806390.
[56] Soujanya Poria 等人. “MELD: 一个多模态多方数据集,用于对话中的情感识别”. In: arXiv preprint arXiv:1810.02508 (2018).
[57] Vineel Pratap 等人. “MLS: 一个大规模多语言语音研究数据集”. In: ArXiv abs/2012.03411 (2020).
[58] Alec Radford 等人. “通过大规模弱监督实现鲁棒语音识别”. In: International conference on machine learning. PMLR. 2023, pp. 28492-28518.
[59] Muhammad Mamunur Rashid, Guiqing Li, 和 Chengrui Du. “Nonspeech7k 数据集: 分类和分析人类非语音声音”. In: IET Signal Processing 17.6 (2023), e12233.
[60] S Sakshi 等人. “MMAU: 一个大规模多任务音频理解和推理基准”. In: arXiv preprint arXiv:2410.19168 (2024).
[61] Justin Salamon, Christopher Jacoby, 和 Juan Pablo Bello. “一个用于城市声音研究的数据集和分类法”. In: Proceedings of the 22nd ACM international conference on Multimedia. 2014, pp. 1041-1044.
[62] Yao Shi 等人. “Aishell-3: 一个多说话人普通话TTS语料库及其基线”. In: arXiv preprint arXiv:2010.11567 (2020).
[63] Changli Tang 等人. “SALMONN: 朝向大型语言模型的通用听力能力”. In: arXiv preprint arXiv:2310.13289 (2023).
[64] Zhiyuan Tang 等人. “KeSpeech: 一个开源的普通话及其八个方言的语音数据集”. In: 第三十五届神经信息处理系统大会数据集和基准轨道(第二轮). 2021.
[65] Kimi Team 等人. Kimi k1.5: 使用LLM扩展强化学习. 2025. arXiv: 2501.12599 [cs.AI]. URL: https://arxiv.org/abs/2501.12599.
[66] Teknium. OpenHermes 2.5: 一个用于通用LLM助手的合成数据开源数据集. 2023. URL: https://huggingface.co/datasets/teknium/OpenHermes-2.5.
[67] Migel Tissera. Synthia-70b-v1.2: 合成智能体. Hugging Face. 2023. URL: https://huggingface. co/migtissera/Synthia-13B.
[68] Samarth Tripathi, Sarthak Tripathi, 和 Homayoon Beigi. “使用深度学习在iemocap数据集上的多模态情感识别”. In: arXiv preprint arXiv:1804.05788 (2018).
[69] Changhan Wang 等人. “VoxPopuli: 一个用于表征学习、半监督学习和解释的大规模多语言语音语料库”. In: arXiv preprint arXiv:2101.00390 (2021).
[70] Chengyi Wang 等人. “神经编解码语言模型是零样本文本到语音合成器”. In: arXiv preprint arXiv:2301.02111 (2023).
[71] Xiong Wang 等人. “Freeze-Omni: 一个智能且低延迟的冻结LLM语音到语音对话模型”. In: arXiv preprint arXiv:2411.00774 (2024).
[72] Zhifei Xie 和 Changqiao Wu. “Mini-Omni: 语言模型可以在流式处理中听到、说话和思考”. In: arXiv preprint arXiv:2408.16725 (2024).
[73] Jin Xu 等人. “Qwen2.5-Omni 技术报告”. In: arXiv preprint arXiv:2503.20215 (2025).
[74] Jin Xu 等人. Qwen2.5-Omni 技术报告. 2025. arXiv: 2503.20215 [cs.CL]. URL: https://arxiv. org/abs/2503.20215.
[75] Zhangchen Xu 等人. “Magpie: 从零开始通过提示对齐LLM合成对齐数据”. In: arXiv preprint arXiv:2406.08464 (2024).
[76] An Yang 等人. “Qwen2.5 技术报告”. In: arXiv preprint arXiv:2412.15115 (2024).
[77] Dongchao Yang 等人. “Uniaudio: 一个朝着通用音频生成的音频基础模型”. In: arXiv preprint arXiv:2310.00704 (2023).
[78] Pinci Yang 等人. “AVQA: 一个用于视频视听问题回答的数据集”. In: 第30届ACM国际多媒体会议论文集. 2022, pp. 3480-3491.
[79] Zehui Yang 等人. “开源 MagicData-RAMC: 一个丰富的注释普通话对话(RAMC)语音数据集”. In: arXiv preprint arXiv:2203.16844 (2022).
[80] Zhen Ye 等人. “LLASA: 扩展基于Llama的语音合成的训练时间和推理时间计算”. In: arXiv preprint arXiv:2502.04128 (2025).
[81] Jianwei Yu 等人. “Autoprep: 一个用于野生语音数据的自动预处理框架”. In: ICASSP 2024-2024 IEEE 国际声学、语音和信号处理会议 (ICASSP). IEEE. 2024, pp. 1136-1140.
[82] Jianwei Yu 等人. “High fidelity speech enhancement with band-split rnn”. In: arXiv preprint arXiv:2212.00406 (2022).
[83] Heiga Zen 等人. “LibriTTS: 一个从LibriSpeech派生的文本到语音语料库”. In: arXiv preprint arXiv:1904.02882 (2019).
[84] Aohan Zeng 等人. “GLM-4-Voice: 朝向智能和类人的端到端语音聊天机器人”. In: arXiv preprint arXiv:2412.02612 (2024).
[85] Binbin Zhang 等人. “WenetSpeech: 一个超过10,000小时的多领域普通话语音识别语料库”. In: ICASSP 2022-2022 IEEE 国际声学、语音和信号处理会议 (ICASSP). IEEE. 2022, pp. 6182-6186.
[86] Qinglin Zhang 等人. “OmniFlatten: 一个用于无缝语音对话的端到端GPT模型”. In: arXiv preprint arXiv:2410.17799 (2024).
[87] Yu Zhang 等人. “Google USM: 超过100种语言的自动语音识别扩展”. In: arXiv preprint arXiv:2303.01037 (2023).
[88] Hang Zhao 等人. “MINT: 通过多目标预训练和指令调整提升音频-语言模型”. In: Interspeech 2024. 2024, pp. 52-56. DOI: 10.21437/Interspeech.2024-1863.
[89] Kun Zhou 等人. “情感语音转换: 理论、数据库和ESD”. In: Speech Communication 137 (2022), pp. 1-18.
附录
A 贡献
核心贡献者
丁丁
居泽谦
LENG YiChong
刘松翔
刘通
商泽宇
沈凯
宋伟
谭旭
#
{ }^{\#}
#
唐海依
王正涛
韦楚
辛一飞
徐欣然
余建伟
张雨涛
周鑫宇
#
{ }^{\#}
#
贡献者
Y. Charles
陈军
陈彦如
杜昱伦
何维然
胡振星
赖国坤
李青城
刘洋洋
孙卫东
王建洲
王玉哲
吴悦峰
吴玉新
杨东超
杨浩
杨颖
杨志林
尹傲雄
袁瑞斌
张雨彤
周彩蝶
贡献者
® \stackrel{\text { ® }}{ } R◯ 项目负责人。
贡献者名单按照姓氏字母顺序排列。
参考论文:https://arxiv.org/pdf/2504.18425


















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











