









前端校招笔试面试基础知识点总结
- 1 HTTP/浏览器
- 1.1 HTTP
- 1.2 OSI七层模型
- 1.3 TCP/IP与UDP
- 1.4 浏览器
- 1.4.1 从输入URL到页面加载的整个过程
- 1.4.2 浏览器渲染流程
- 1.4.3 浏览器缓存机制
- 1.4.4 浏览器持久化
- 1.4.5 cookie sessionStorage localStorage
- 1.4.6 实现浏览器内多个标签之间的通信
- 1.4.7 从浏览器的URL中获取查询字符串参数
- 1.4.8 同源策略与跨域问题
- 1.4.8.1 同源策略
- 1.4.8.2 跨域
- 1.4.8.2.1 通过JSONP跨域
- 1.4.8.2.2 当主域相同时,通过document.domain+iframe来跨子域
- 1.4.8.2.3 使用window.name+iframe来进行跨域
- 1.4.8.2.4 使用window.postMessage方法来跨域(不常用)
- 1.4.8.2.5 使用跨域资源共享(CORS)来跨域
- 1.4.8.2.6 使用location.hash+iframe来跨域(不常用)
- 1.4.8.2.7 使用WebSocket来跨域
- 1.4.8.2.8 使用flash URLLoader来跨域
- 1.4.8.2.9 nginx反向代理跨域
- 1.2.8.2.10 nodejs中间件代理跨域
- 1.4.8.3 利用多个域名来存储网站资源更有效的原因
- 1.4.9 csrf和xss的网络攻击与防御
- 1.4.10 常用浏览器的内核
- 1.5 前端性能优化
- 2 HTML/HTML5
- 3 CSS
- 4 JS
- 5 JQuery
方便个人学习复习使用。引用博客均有标注链接。
1 HTTP/浏览器
1.1 HTTP
1.1.1 HTTP请求报文与响应报文
1.1.1.1 HTTP请求报文
HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成。
- 请求行:(get/post方法,url中的path路径,http版本)
- 请求头部(header):关键字/值对组成,每行一对,关键字和值用英文冒号
- 空行
- 请求数据body
1.1.1.2 HTTP响应报文
HTTP响应报文由状态行,响应头部,空行,响应数据4个部分组成。
- 状态码(Status Code):描述了响应的状态。可用来检查是否成功的完成了请求。请求失败的情况下,状态码可用来找出失败的原因。如果Servlet没有返回状态码,默认会返回成功的状态码HTTPServletResponse.SC_OK。
- HTTP头部(HTTP Header):包含了更多关于响应的信息。比如:头部可以指定认为响应过期的过期日期,或者是指定用来给用户安全的传输实体内容的编码格式。如何在Servlet中检索HTTP的头部看这里。
- 空行
- 主体(Body):它包含了响应的内容。可以包含HTML代码、图片等。主体是由传输在HTTP消息中紧跟在头部后面的数据字节组成的。
1.1.2 get与post
- GET - 从指定的资源请求数据
- POST - 向指定的资源提交要被处理的数据
- GET和POST方法各有特点,在外在的表现上似乎是有着诸多的不同但是本质相同,并无区别,GET和POST实际均是TCP链接。但是由于 HTTP 的规定以及浏览器/服务器的限制,导致它们在应用过程中可能会有所不同。
1.1.3 HTTP头部
1.1.3.1 常见的HTTP头部
- 可以将http首部分为通用首部,请求首部,响应首部,实体首部。
- 通用首部表示一些通用信息,比如date表示报文创建时间。
- 请求首部就是请求报文中独有的,如cookie,和缓存相关的如if-Modified-Since。
- 响应首部就是响应报文中独有的,如set-cookie,和重定向相关的location。
- 实体首部用来描述实体部分,如allow用来描述可执行的请求方法,content-type描述主题类型,content-Encoding描述主体的编码方式。
1.1.3.2 HTTP请求头
| 协议头 | 说明 |
|---|---|
| Accept | 可接受的响应内容类型(Content-Types)。 |
| Accept-Charset | 可接受的字符集 |
| Accept-Encoding | 可接受的响应内容的编码方式。 |
| Accept-Language | 可接受的响应内容语言列表。 |
| Accept-Datetime | 可接受的按照时间来表示的响应内容版本 |
| Authorization | 用于表示HTTP协议中需要认证资源的认证信息 |
| Cache-Control | 用来指定当前的请求/回复中的,是否使用缓存机制。 |
| Connection | 客户端(浏览器)想要优先使用的连接类型 |
| Cookie | 由之前服务器通过Set-Cookie(见下文)设置的一个HTTP协议Cookie |
| Content-Length | 以8进制表示的请求体的长度 |
| Content-MD5 | 请求体的内容的二进制 MD5 散列值(数字签名),以 Base64 编码的结果 |
| Content-Type | 请求体的MIME类型 (用于POST和PUT请求中) |
| Date | 发送该消息的日期和时间(以RFC 7231中定义的"HTTP日期"格式来发送) |
| Expect | 表示客户端要求服务器做出特定的行为 |
| From | 发起此请求的用户的邮件地址 |
| Host | 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。 |
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要用于像 PUT 这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源。 |
| If-Modified-Since | 允许在对应的资源未被修改的情况下返回304未修改 |
| If-None-Match | 允许在对应的内容未被修改的情况下返回304未修改( 304 Not Modified ),参考 超文本传输协议 的实体标记 |
| If-Range | 如果该实体未被修改过,则向返回所缺少的那一个或多个部分。否则,返回整个新的实体 |
| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 |
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 |
| Origin | 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)。 |
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生。 |
| Proxy-Authorization | 用于向代理进行认证的认证信息。 |
| Range | 表示请求某个实体的一部分,字节偏移以0开始。 |
| Referer | 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面。Referer其实是Referrer这个单词,但RFC制作标准时给拼错了,后来也就将错就错使用Referer了。 |
| TE | 浏览器预期接受的传输时的编码方式:可使用回应协议头Transfer-Encoding中的值(还可以使用"trailers"表示数据传输时的分块方式)用来表示浏览器希望在最后一个大小为0的块之后还接收到一些额外的字段。 |
| User-Agent | 浏览器的身份标识字符串 |
| Upgrade | 要求服务器升级到一个高版本协议。 |
| Via | 告诉服务器,这个请求是由哪些代理发出的。 |
| Warning | 一个一般性的警告,表示在实体内容体中可能存在错误。 |
1.1.4 HTTP状态码
1.1.4.1 常见的HTTP状态码
200 OK 请求成功。一般用于GET与POST请求
201 Created 已创建。成功请求并创建了新的资源
202 Accepted 已接受。已经接受请求,但未处理完成
203 Non-Authoritative Information 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本
204 No Content 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档
205 Reset Content 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域
206 Partial Content 部分内容。服务器成功处理了部分GET请求
300 Multiple Choices 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择
301 Moved Permanently 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
302 Found 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI
303 See Other 查看其它地址。与301类似。使用GET和POST请求查看
304 Not Modified 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
305 Use Proxy 使用代理。所请求的资源必须通过代理访问
306 Unused 已经被废弃的HTTP状态码
307 Temporary Redirect 临时重定向。与302类似。使用GET请求重定向
400 Bad Request 客户端请求的语法错误,服务器无法理解
401 Unauthorized 请求要求用户的身份认证
402 Payment Required 保留,将来使用
403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面
500 Internal Server Error 服务器内部错误,无法完成请求
501 Not Implemented 服务器不支持请求的功能,无法完成请求
502 Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
503 Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
504 Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求
505 HTTP Version not supported 服务器不支持请求的HTTP协议的版本,无法完成处理
1.1.4.2 状态码301和302的区别
- 301 Moved Permanently 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
- 302 Found 请求的资源现在临时从不同的URI响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。
- 区别
- 301是永久重定向,而302是临时重定向。
- 301比较常用的场景是使用域名跳转。
- 302用来做临时跳转,比如未登陆的用户访问用户中心重定向到登录页面。
1.1.4.3 状态码200和304
- 状态码200:请求已成功,请求所希望的响应头或数据体将随此响应返回。即返回的数据为全量的数据,如果文件不通过GZIP压缩的话,文件是多大,则要有多大传输量。一般用于GET与POST请求。
- 状态码304:如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码。即客户端和服务器端只需要传输很少的数据量来做文件的校验,如果文件没有修改过,则不需要返回全量的数据。
1.1.4.4 状态码400、401和403
(1)400状态码:请求无效
产生原因:
- 前端提交数据的字段名称和字段类型与后台的实体没有保持一致
- 前端提交到后台的数据应该是json字符串类型,但是前端没有将对象JSON.stringify转化成字符串。
解决方法:
- 对照字段的名称,保持一致性
- 将obj对象通过JSON.stringify实现序列化
(2)401状态码:当前请求需要用户验证
(3)403状态码:服务器已经得到请求,但是拒绝执行
1.1.5 HTTP支持的方法
- HEAD
- OPTIONS
- PUT
- DELETE
- TRACE
- CONNECT
1.1.6 HTTP与HTTPS
https的SSL加密是在传输层实现的。
1.1.6.1 http和https的基本概念
- http: 超文本传输协议,是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
- https: 是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
https协议的主要作用是:建立一个信息安全通道,来确保数组的传输,确保网站的真实性。
1.1.6.2 http和https的区别
- http传输的数据都是未加密的,也就是明文的,网景公司设置了SSL协议来对http协议传输的数据进行加密处理,简单来说https协议是由http和ssl协议构建的可进行加密传输和身份认证的网络协议,比http协议的安全性更高。
- 主要的区别如下:
(1)Https协议需要ca证书,费用较高。
(2)http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
(3)使用不同的链接方式,端口也不同,一般而言,http协议的端口为80,https的端口为443
(4)http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
1.1.6.3 https协议的工作原理
客户端在使用HTTPS方式与Web服务器通信时的步骤:
(1)客户使用https url访问服务器,则要求web 服务器建立ssl链接。
(2)web服务器接收到客户端的请求之后,会将网站的证书(证书中包含了公钥),返回或者说传输给客户端。
(3)客户端和web服务器端开始协商SSL链接的安全等级,也就是加密等级。
(4)客户端浏览器通过双方协商一致的安全等级,建立会话密钥,然后通过网站的公钥来加密会话密钥,并传送给网站。
(5)web服务器通过自己的私钥解密出会话密钥。
(6)web服务器通过会话密钥加密与客户端之间的通信。
1.1.6.4 https协议的优点与缺点
优点
(1)使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
(2)HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
(3)HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
缺点
(1)https握手阶段比较费时,会使页面加载时间延长50%,增加10%~20%的耗电。
(2)https缓存不如http高效,会增加数据开销。
(3)SSL证书也需要钱,功能越强大的证书费用越高。
(4)SSL证书需要绑定IP,不能再同一个ip上绑定多个域名,ipv4资源支持不了这种消耗。
1.1.7 HTTP 2.0
http2.0是基于1999年发布的http1.0之后的首次更新。
(1)提升访问速度(可以对于,请求资源所需时间更少,访问速度更快,相比http1.0)
(2)允许多路复用:多路复用允许同时通过单一的HTTP/2连接发送多重请求-响应信息。改善了:在http1.1中,浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制(连接数量),超过限制会被阻塞。
(3)二进制分帧:HTTP2.0会将所有的传输信息分割为更小的信息或者帧,并对他们进行二进制编码
(4)首部压缩
(5)服务器端推送
1.1.8 谈谈对HTTP控制访问CORS的理解
跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain) 上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。
出于安全原因,浏览器限制从脚本内发起的跨源HTTP请求。 例如,XMLHttpRequest和Fetch API遵循同源策略。 这意味着使用这些API的Web应用程序只能从加载应用程序的同一个域请求HTTP资源,除非响应报文包含了正确CORS响应头。
跨域资源共享标准( cross-origin sharing standard )允许在下列场景中使用跨域 HTTP 请求:
(1)前文提到的由 XMLHttpRequest 或 Fetch 发起的跨域 HTTP 请求。
(2)Web 字体 (CSS 中通过 @font-face 使用跨域字体资源), 因此,网站就可以发布 TrueType 字体资源,并只允许已授权网站进行跨站调用。
(3)WebGL 贴图
(4)使用 drawImage 将 Images/video 画面绘制到 canvas
1.2 OSI七层模型
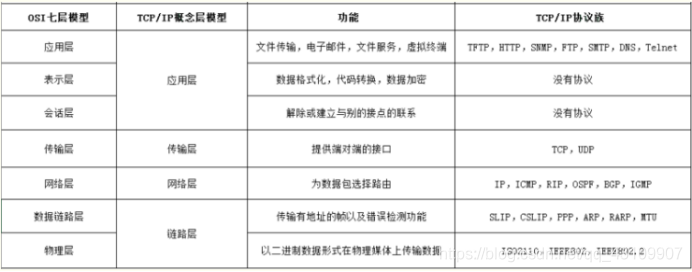
1.3 TCP/IP与UDP
1.3.1 TCP三次握手
1.3.1.1 TCP三次握手的过程

(1)首先客户端发出请求连接即SYN=1 ACK=0到服务器,并进入SYN_SENT状态,等待服务器确认。
(2)服务器收到SYN包后进行回复确认,同时发送SYN=1,ACK=1,seq=y,ack=x+1,此时服务器进入SYN_RCVD状态。
(3)客户端收到服务端发过来的SYN+ACK包,向服务器发送确认ACK=1,seq=x+1,ack=y+1,然后客户端和服务器进入ESTABLISHED状态,TCP连接建立成功。
1.3.1.2 为什么TCP连接是三次握手不是两次握手

1.3.1.3 为什么连接的时候是三次握手,关闭的时候却是四次握手
因为服务器端收到客户端的SYN连接请求报文后,可以直接发送SYN+ACK报文,其中ACK报文用来应答,SYN报文用来同步。但关闭连接时,当服务器端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉客户端已收到它发送的FIN报文。只有等服务器端所有报文都发完了,服务器端才能发送FIN报文,不能一起发送。
1.3.2 TCP四次挥手
1.3.2.1 TCP四次挥手的过程
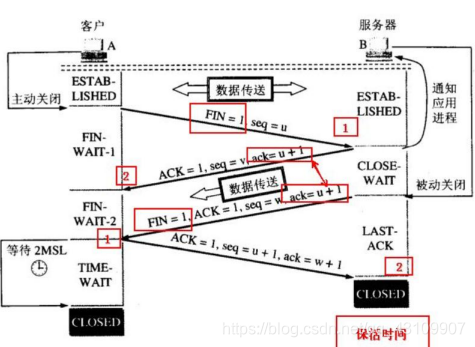
1.3.2.2 为什么是四次挥手
因为TCP有个半关闭状态,假设客户端和服务器端要释放连接,那么客户端发送一个释放连接报文给服务器端,服务器端收到后发送确认,此时客户端补发数据,但是服务器端如果发数据,客户端还是要接受,然后服务器端发确认,所以是4次。
1.3.3 TCP拥塞
- 在某段时间,如果对网络中的某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要发生变化,这种情况叫阻塞。
- 拥塞产生的原因:①接收方容量不够;②网络内部有瓶颈;
1.3.3.1 TCP/IP协议的拥塞控制的4种算法
①慢开始
②拥塞避免
③快速重传
④快速恢复
1.3.3.2 TCP拥塞控制和流量控制的区别
1.3.4 TCP与UDP的区别
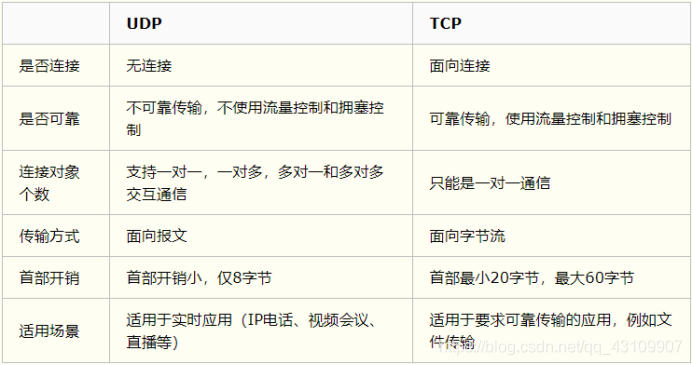
总结
- TCP向上层提供面向连接的可靠服务 ,UDP向上层提供无连接不可靠服务。
- 虽然 UDP 并没有 TCP 传输来的准确,但是也能在很多实时性要求高的地方有所作为
- 对数据准确性要求高,速度可以相对较慢的,可以选用TCP
1.4 浏览器
1.4.1 从输入URL到页面加载的整个过程
毅江:从输入URL到页面加载的全过程
小火柴的蓝色理想:从输入URL到页面加载的全过程
1.4.2 浏览器渲染流程
(1)解析HTML文件,创建DOM树。
(2)自上而下,遇到任何样式(link、style)与脚本(script)都会阻塞(外部样式不阻塞后续外部脚本的加载)。
(3)解析CSS。
优先级:浏览器默认设置<用户设置<外部样式<内联样式<HTML中的style样式
(4)将CSS和DOM合并,构建render树。
(5)布局和绘制render树,重绘(repaint)和重排(reflow)。
简书oWSQo:浏览器渲染原理与过程
1.4.3 浏览器缓存机制
- 缓存分为两种:强缓存和协商缓存,根据响应的header内容来决定。
- 强缓存相关字段有expires,cache-control。如果cache-control与expires同时存在的话,cache-control的优先级高于expires。
- 协商缓存相关字段有Last-Modified/If-Modified-Since,Etag/If-None-Match
1.4.4 浏览器持久化
- 现代浏览器主要有8种缓存机制: HTTP文件缓存、LocalStorage、SessionStorage、indexDB、Web SQL、Cookie、CacheStorage、Application Cache
happylittlefish:浏览器数据持久化缓存技术 ——《现代前端技术解析》笔记
1.4.5 cookie sessionStorage localStorage
1.4.5.1 cookie sessionStorage localStorage的区别
(1)存储大小限制不同
- cookie数据不能超过4k,同时因为每次http请求都会携带cookie,所以cookie只适合保存很小的数据,如会话标识。很多浏览器都限制一个站点最多保存20个cookie。
- sessionStorage和localStorage的存储大小限制比cookie大得多,大约5M或者更大。
(2)数据的有效期不同
- cookie:一般由服务器生成,可设置失效时间,关闭窗口或浏览器后超过失效时间失效,在失效时间之前能一直保存。
- sessionStorage:浏览器窗口开启时生成,仅在当前浏览器窗口关闭前有效,自然也就不可能持久保持;
- localStorage:始终有效,窗口或浏览器关闭也一直保存,只要不手动删除就一直存在,因此用作持久数据;
(3)与服务器的交互
- cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递。如果使用cookie保存数据过多会带来性能问题。
- sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。
(4)作用域不同
- cookie和localStorage在所有同源窗口中共享。
- sessionStorage不在不同的浏览器窗口中共享,即使是同一个页面。
1.4.5.2 cookie
1.4.5.2.1 cookie的可设置字段
| 字段 | 说明 |
|---|---|
| name | cookie的名称 |
| value | cookie的值 |
| domain | 可以访问此cookie的域名 |
| path | 可以访问此cookie的页面路径 |
| expires/Max-Age | cookie的超时时间。若设置其值为一个时间,那么当到达此时间后,此cookie失效。不设置的话默认值是Session,意思是cookie会和session一起失效。当浏览器关闭(不是浏览器标签页,而是整个浏览器) 后,此cookie失效。 |
| Size | cookie的大小 |
| http | cookie的httponly属性。若此属性为true,则只有在http请求头中会带有此cookie的信息,而不能通过document.cookie来访问此cookie。 |
| secure | 设置是否只能通过https来传递此条cookie |
1.4.5.2.2 cookie的编码方式
encodeURI()
1.4.5.2.3 cookie弊端
(1)cookie限制
- IE6或更低版本最多20个cookie
- IE7和之后的版本最后可以有50个cookie。
- Firefox最多50个cookie
- chrome和Safari没有做硬性限制
- Opera会清理近期最少使用的Firefox会随机清理4096字节,为了兼容性,一般不能超过IE提供了一种存储可以持久化用户数据,叫做IE5.0就开始支持。每个数据最多128K,每个域名下最多1M。这个持久化数据放在缓存中,如果缓存没有清理,那么会一直存在。
- (2)cookie安全性问题
- cookie欺骗
- cookie截获
- cookie泄漏网络隐私
深入分析cookie的安全性问题
1.4.5.2.4 cookie隔离
- 通过使用多个非主要域名来请求静态文件,如果静态文件都放在主域名下,那静态文件请求的时候带有的cookie的数据提交给server是非常浪费的,还不如隔离开。
- 因为cookie有域的限制,因此不能跨域提交请求,故使用非主要域名的时候,请求头中就不会带有cookie数据,这样可以降低请求头的大小,降低请求时间,从而达到降低整体请求延时的目的。
- 同时这种方式不会将cookie传入server,也减少了server对cookie的处理分析环节,提高了server的http请求的解析速度。
1.4.6 实现浏览器内多个标签之间的通信
(1)通过WebSocket或者SharedWorker把客户端和服务器端建立socket连接,从而实现通信
(2)localStorage、cookies等本地存储方法。
1.4.7 从浏览器的URL中获取查询字符串参数
Location对象包含当前页面与url相关的信息。
Location对象的8个属性:
href:声明了当前显示文档的完整的URL。
protocol:声明URL的协议部分,包括后缀的冒号,例如http。
host:声明当前URL的主机名和端口号(是hostname和port的合集),例如www.baidu.com:80。
hostname:声明当前URL的主机名,例如www.baidu.com
port:声明当前URL的端口部分,例如80。
pathname:声明当前URL的路径部分,例如news/index.aspx
search:声明当前URL的查询部分,例如?id=1&name=localhost。
hash:声明当前URL的锚的部分,例如#top,指定在文档中的锚记的名称。
如果改变了文档的location.href,那么浏览器会载入新的页面。
如果改变了location.hash,那么页面会跳转到新的锚点,但此时页面不会重载。
location对象的两个方法:
reload():可以重载当前文档。
replace():可以装载一个新文档而无须为其创建一个新的历史记录。即在浏览器的历史列表中,新文档将替换当前文档。
∴通过将url字符串信息赋值给窗口的location属性来装载新文档可以实现返回浏览。
1.4.8 同源策略与跨域问题
1.4.8.1 同源策略
- 同源的条件:协议相同、域名相同、端口相同
- 同源的目的:为了保证用户信息的安全,防止恶意的网站窃取数据。
- 非同源的限制范围:
随着互联网的发展,同源政策越来越严格。目前,如果非同源,共有三种行为受到限制。
(1)无法读取非同源网页的 Cookie、LocalStorage 和 IndexedDB。
(2)无法接触非同源网页的 DOM。
(3)无法向非同源地址发送 AJAX 请求(可以发送,但浏览器会拒绝接受响应)。
1.4.8.2 跨域
- 跨域是指浏览器不能执行其他网站的脚本。它是由浏览器同源策略造成的,是浏览器施加的安全限制。
萌主_iii:JS中的八种常用的跨域方式及其具体示例的总结 - 跨域的方法
1.4.8.2.1 通过JSONP跨域
(服务器与客户端跨源通信的常用方法)
-
JSONP的基本思想:网页通过添加一个
<script>元素,向服务器请求 JSON 数据,这种做法不受同源政策限制;服务器收到请求后,将数据放在一个指定名字的回调函数里传回来。
首先,网页动态插入<script>元素,由它向跨源网址发出请求。
接着,服务器收到这个请求以后,会将数据放在回调函数的参数位置返回。 -
最大特点就是简单适用,老式浏览器全部支持,服务端改造非常小。
-
JSONP包括回调函数和数据两个部分。
回调函数:当响应到来时要放在当前页面被调用的函数。
数据:传入回调函数中的JSON数据,即回调函数的参数。 -
JSONP的缺点:
①安全问题(请求代码中可能存在安全隐患)
②要确定JSONP请求是否失败并不容易
1.4.8.2.2 当主域相同时,通过document.domain+iframe来跨子域
1.4.8.2.3 使用window.name+iframe来进行跨域
- window的name属性特征:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB),即在一个窗口(window)的生命周期内,窗口载入的所有的页面都是共享一个window.name的,每个页面window.name都有读写的权限。
1.4.8.2.4 使用window.postMessage方法来跨域(不常用)
- window.postMessage(message,targetOrigin) 方法是html5新引进的特性,可以使用它来向其它的window对象发送消息,无论这个window对象是属于同源或不同源(可实现跨域),目前IE8+、FireFox、Chrome、Opera等浏览器都已经支持window.postMessage方法。
message:为要发送的消息,类型只能为字符串;
targetOrigin:用来限定接收消息的那个window对象所在的域,如果不想限定域,可以使用通配符 “*”。
1.4.8.2.5 使用跨域资源共享(CORS)来跨域
- CORS:一种跨域访问的机制,属于跨院AJAX请求的根本解决办法;
- 相比 JSONP 只能发GET请求,CORS 允许任何类型的请求。
- CORS允许一个域上的网络应用向另一个域提交跨域AJAX请求。
- 服务器设置Access-Control-Allow-Origin HTTP响应头之后,浏览器将会允许跨域请求。
- 使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
1.4.8.2.6 使用location.hash+iframe来跨域(不常用)
- 假设域名test.com下的文件a.html要和csdnblogs.com域名下的b.html传递信息。
①创建test.com下的a.html页面, 同时在a.html上加一个定时器,隔一段时间来判断location.hash的值有没有变化,一旦有变化则获取获取hash值
②b.html响应请求后再将通过修改a.html的hash值来传递数据
③test.com域下的c.html代码
1.4.8.2.7 使用WebSocket来跨域
- WebSocket: 是一种通信协议,使用ws://(非加密)和wss://(加密)作为协议前缀。该协议不实行同源政策,只要服务器支持,就可以通过它进行跨源通信。它的目标是在一个单独的持久连接上提供全双工、双向通信。
- 因为有了Origin这个字段,所以 WebSocket 才没有实行同源政策。因为服务器可以根据这个字段,判断是否许可本次通信。
- WebSocket原理:在JS创建了WebSocket之后,会有一个HTTP请求发送到浏览器以发起连接。取得服务器响应后,建立的连接会使用HTTP升级从HTTP协议交换为WebSocket协议。
1.4.8.2.8 使用flash URLLoader来跨域
- flash有自己的一套安全策略,服务器可以通过crossdomain.xml文件来声明能被哪些域的SWF文件访问,SWF也可以通过API来确定自身能被哪些域的SWF加载。
- 例如:当跨域访问资源时,例如从域baidu.com请求域google.com上的数据,我们可以借助flash来发送HTTP请求。
flash URLLoader跨域实现方式:- 首先,修改域google.com上的crossdomain.xml(一般存放在根目录,如果没有需要手动创建) ,把baidu.com加入到白名单。
- 其次,通过Flash URLLoader发送HTTP请求
- 最后,通过Flash API把响应结果传递给JavaScript。
1.4.8.2.9 nginx反向代理跨域
腾讯云社区木二:Nginx跨域配置
在Server域中配置Nginx:
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Credentials true;
add_header Access-Control-Allow-Headers Origin,X-Requested-With,Content-Type,Accept,x-language;
add_header Access-Control-Allow-Methods POST,GET,OPTIONSZ,PUT,DELETE;
1.2.8.2.10 nodejs中间件代理跨域
app.all('*', function(req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers","Content-Type,Content-Length, Authorization, Accept,X-Requested-With");
res.header("Access-Control-Allow-Methods","PUT,POST,GET,DELETE,OPTIONS");
res.header("X-Powered-By",' 3.2.1')
if(req.method=="OPTIONS") res.send(200);
else next();
});
1.4.8.3 利用多个域名来存储网站资源更有效的原因
(1)CDN缓存更方便
(2)突破浏览器并发限制
(3)节约cookie带宽
(4)节约主域名的连接数,优化页面响应速度
(5)防止不必要的安全问题
1.4.9 csrf和xss的网络攻击与防御
- 什么是CSRF(跨站请求伪造)
- 当用户访问A(信任网站)网站并登录成功时,在用户处产生A的Cookie。这时候用户访问了B(危险网站)网站,当B要求访问第三方站点(A)时,浏览器会带着用户最开始登录A的时候产生的Cookie访问A,而A网站并不能分辨请求是由用户发出的还是由B发出的,这时候B网站就能模拟用户操作。例如转账等操作。
- 如何防范CSRF攻击
- (1)使用token
可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。 - (2)检查http头部的refer
根据 HTTP 协议,在 HTTP 头中有一个字段叫 refer,它记录了该 HTTP 请求的来源地址。例如我们要在网上银行执行转账,那么我们发出去的请求的http中的refer通常是通常是以 bank.example 域名开头的地址,既该银行的页面上的url,而黑客执行CSRF攻击的时候http中的refer是黑客自己网站的url。如果 Referer 是其他网站的话,则有可能是黑客的 CSRF 攻击,拒绝该请求。 - (3)在 HTTP 头中自定义属性并验证
这种方法也是使用 token 并进行验证,和上一种方法不同的是,这里并不是把 token 以参数的形式置于 HTTP 请求之中,而是把它放到 HTTP 头中自定义的属性里 - (4)使用验证码
在表单中增加一个随机的数字或字母验证码,通过强制用户和应用进行交互,来有效地遏制CSRF攻击。
- (1)使用token
- 什么是XSS
- XSS全称是Cross Site Scripting即跨站脚本,当目标网站目标用户浏览器渲染HTML文档的过程中,出现了不被预期的脚本指令并执行时,XSS就发生了。
- 如何防御XSS
- (1)对用户的输入进行检查
不信任任何用户的输入,对每个用户的输入都做严格检查,过滤,在输出的时候,对某些特殊字符进行转义,替换等。 - (2)Cookie设置为httpOnly属性
httponly–这个属性可以防止XSS,它会禁止javascript脚本来访问cookie。
- (1)对用户的输入进行检查
1.4.10 常用浏览器的内核
- 通常所谓的浏览器内核也就是浏览器所采用的渲染引擎,排版引擎(Rendering Engine,也有称渲染引擎),渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。不同的浏览器内核对网页编写语法的解释也有不同,因此同一网页在不同的内核的浏览器里的渲染(显示)效果也可能不同,这也是网页编写者需要在不同内核的浏览器中测试网页显示效果的原因。
| 浏览器 | 内核 | 备注 |
|---|---|---|
| IE | Trident | Window10 发布后,IE 将其内置浏览器命名为 Edge,Edge 最显著的特点就是新内核 EdgeHTML。 |
| Mozilla FireFox | Gecko | Gecko 的特点是代码完全公开,因此,其可开发程度很高,但是这几年没落了,缺点:打开速度慢、升级频繁。 |
| chrome | Chromium/Blink | 在 Chromium 项目中研发 Blink 渲染引擎(即浏览器核心),内置于 Chrome 浏览器之中。Blink 其实是 WebKit 的分支。大部分国产浏览器最新版都采用Blink内核,进行二次开发。 |
| Safari | Webkit | |
| Opera | Blink | 最新的Opera已经跟随chrome用blink内核。 |
| 注意: | ||
| (1)360和搜狗这些分极速模式和兼容模式的浏览器,极速模式用的是Webkit内核,兼容模式用的Trident内核. | ||
| (2) iPhone 和 iPad 等苹果 iOS 平台主要是 WebKit,Android 4.4 之前的 Android 系统浏览器内核是 WebKit,Android4.4 系统浏览器切换到了Chromium,内核是 Webkit 的分支 Blink,Windows Phone 8 系统浏览器内核是 Trident。 |
1.5 前端性能优化
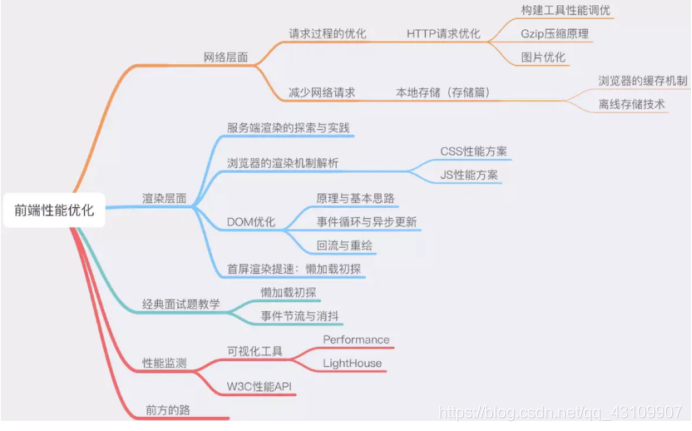
(1)减少HTTP请求,特别是vue在请求http时,要将请求放在父组件中,不然每个子组件都去请求一遍就很浪费性能。
(2)使用内容发布网络(CDN)
(3)添加本地缓存
(4)使用缓存,在vue中可以使用keep-alive,这样重复访问一个页面时就不会重新去请求,而是从缓存中取出来直接使用。
(5)压缩资源文件
(6)将CSS样式表放在顶部,把javascript放在底部(浏览器的运行机制决定)或异步
(7)避免使用CSS表达式
(8)减少DNS查询
(9)使用外部javascript和CSS
(10)避免重定向
(11)图片lazyLoad
优化工具:
(1)真实用户浏览页面分析:OneAPM Browser Insight(统计分析网站流量,定位网站性能瓶颈)
(2)页面结构分析工具: PageSpeed(google官方的页面载入速度检测工具)
2 HTML/HTML5
2.1 DOCTYPE标签
2.1.1 DOCTYPE标签的标准模式与兼容模式的区别
- 标准模式的排版 和 JS运作模式都是以该浏览器支持的最高标准运行。在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为以防止站点无法工作。
- 具体区别
-
(1)盒模型
- 在严格模式中 :width是内容宽度 ,元素真正的宽度 = width;
- 在兼容模式中 :width则是=width+padding+border
-
(2)
- 兼容模式下可设置百分比的高度和行内元素的高宽
- 在Standards模式下,给span等行内元素设置wdith和height都不会生效,而在兼容模式下,则会生效。
- 在standards模式下,一个元素的高度是由其包含的内容来决定的,如果父元素没有设置高度,子元素设置一个百分比的高度是无效的。
-
(3)
- 用margin:0 auto设置水平居中在IE下会失效
- 使用margin:0 auto在standards模式下可以使元素水平居中,但在兼容模式下却会失效(用text-align属性解决)
body{ text-align:center }; #content{ text-align:left } -
(4)兼容模式下Table中的字体属性不能继承上层的设置,white-space:pre会失效,设置图片的padding会失效。
-
2.1.2 DOCTYPE标签在HTML 4.01 与 HTML5之间的差异
- HTML 4.01 规定了三种不同的<!DOCTYPE> 声明,分别是:Strict、Transitional 和 Frameset。 HTML5 中仅规定了一种。
2.2 meta标签
-
meta标签提供了 HTML 文档的元数据。元数据不会显示在客户端,但是会被浏览器解析。元数据通常以 名称/值 对出现。
-
META元素通常用于指定网页的描述,关键词,文件的最后修改时间,作者及其他元数据。
-
元数据可以被使用浏览器(如何显示内容或重新加载页面),搜索引擎(关键词),或其他 Web 服务调用。
-
注意:
①meta 标签中的元数据无法使用其他的元相关标签表示,例如:base标签、link标签,script标签、style标签或title标签。
②如果没有提供 name 属性,那么名称/值对中的名称会采用 http-equiv 属性的值。
③HTML5 不支持 scheme 属性,但新的charset属性定义文档的字符编码。 -
meta的作用:
①meta数据是供机器解读的,告诉机器如何解析这个页面;
②可添加服务器发送到浏览器的http头部内容; -
常用的meta标签
(1)charset 声明文档使用的字符编码,解决乱码问题。
<meta charset="UTF-8">
或者
<meta http-equiv="content-type" content="text/html;charset=utf-8">
(2)百度禁止转码
<meta http-equiv="Cache-Control" content="no-siteapp" />
(3)SEO优化
IT刘磊:SEO优化篇–meta用法
<title>your title</title>
<!-- 搜索引擎搜索关键字 -->
<meta name="keywords" content="your keywords">
<!-- 搜索引擎网站内容描述 -->
<meta name="description" content="your description">
<!-- 网页作者 -->
<meta name="author" content="author,email address">
<!--
搜索引擎爬虫的索引方式
content的参数有:
all 此页面与继续通过此网页的链接索引 等价于index或follow,content的默认值。
follow 继续通过此网页的链接索引其他网页
index 索引此网页
none 忽略此网页 等价于noindex或nofollow
noindex 不索引此网页
nofollow 不继续通过此网页链接索引其他页面
-->
<meta name="robots" content="index,follow">
(4)viewport 主要影响移动端布局
<meta name="viewport" content="width=device-width,initial-scale=1.0" />
<!--
content的参数有:
width:控制viewport的大小
height:和width相对应,指定高度
initial-scale:初始缩放比例,即当页面第一次load时缩放比例
maxinum-scale:允许用户缩放最大比例
mininum-scale:允许用户缩放到最小比例
user-scalable:用户是否可手动缩放
-->
2.3 link和@import的区别
相同点:都是外部引用CSS的方式
区别:
(1)link是xhtml标签,除了加载CSS外,还可以定义RSS等其他事务;@import属于CSS范畴,只能加载CSS;
(2)link引用CSS时,页面载入时同时加载,@import需要在页面完全加载以后加载,而且@import被引用的CSS会等到引用它的CSS文件被加载完才加载;
(3)link是xhtml标签,无兼容问题;@import是在CSS2.1提出的,低版本的浏览器不支持;
(4)link支持使用JS控制去改变样式(JS插入操作DOM),而@import不支持;
(5)link方式的样式的权重高于@import的权重;
(6)import在html使用时需<style type="text/css">标签;
2.4 script标签的defer和async
2.5 行内元素/块级元素 非替换元素/替换元素 空元素
(1)行内元素
特点:
①行内元素一般无法设置width和height属性(替换元素除外)。
②行内元素设置margin和padding属性时,只有margin-left、margin-right、padding-left和padding-right有效。
③行内元素前后不会换行,多个行内元素会排成一行,直到排满一行。
常见的行内元素有:a、br、em、i、img、input、span等。
(2)块级元素
特点:
①默认独占一行,左右两边都没有元素。
②可以设置宽高,在不设置宽度的情况下,默认为父元素的宽度一致。
常见的块级元素有:div、dl、h1-h6、hr、ol、p、table、ul等。
(3)替换元素
定义:替换元素是浏览器根据元素的标签和属性来决定元素的具体显示内容。
特点:
①替换元素本身没有内容,是“空元素”。
②替换元素有内在尺寸,有width和height属性。
③替换元素的margin和padding属性有效。
常见的替换元素有:img、input、textarea等。
(4)非替换元素
定义:将内容直接告诉浏览器,将其显示出来。
常见的非替换元素为p标签。
可继承与不可继承的样式属性:
不可继承的:display、margin、border、padding、background、height、min-height、max- height、width、min-width、max-width、overflow、position、left、right、top、 bottom、z-index、float、clear、table-layout、vertical-align、page-break-after、 page-bread-before和unicode-bidi。
所有元素可继承:visibility和cursor。
内联元素可继承:letter-spacing、word-spacing、white-space、line-height、color、font、 font-family、font-size、font-style、font-variant、font-weight、text- decoration、text-transform、direction。
块状元素可继承:text-indent和text-align。
列表元素可继承:list-style、list-style-type、list-style-position、list-style-image。
表格元素可继承:border-collapse。
(5)空元素
2.6 src与href的区别
- src用于替换当前元素,href用于在当前文档和引用资源之间确立联系。
- src是source的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置。
- href是Hypertext Reference的缩写,指向网络资源所在的位置,建立和当前元素(锚点)或当前文档(链接)之间的链接。
2.7 img的title与alt的区别
- title是全局属性,是图片的标题主题,只要img标签存在,不管图片是否显示,当鼠标停滞在图片区域时都会显示定义的提示。
- alt是局部属性,实在图片载入或者加载失败时通过文字来代替图片内容。替换文字的语言由lang属性指定。(在IE浏览器下会在没有title时把alt当成tooltip显示。)
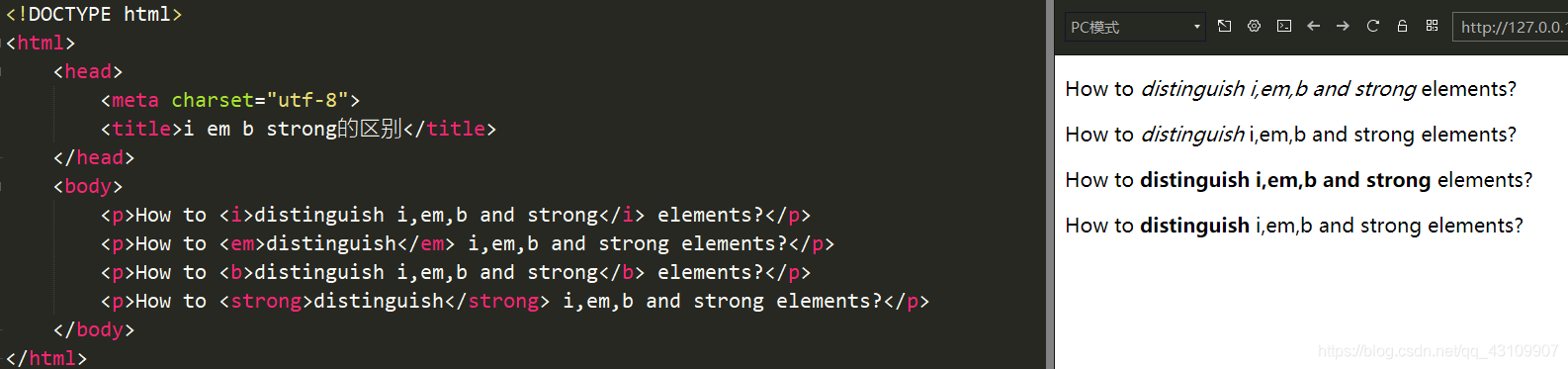
2.8 i、em、b与strong的区别
在只用标签时单从显示效果来看,i和em标签包围的文字都是以斜体显示的,b和strong标签包围的文字都是会加粗显示。具体效果见下图。
<b>:规定粗体文本。
<i>:显示斜体的文本效果。
<em>:把文本定义为强调的内容。
<strong>:把文本定义为语气更强烈的强调的内容。
弄清两个概念–物理元素和逻辑元素
物理元素:告诉浏览器应该以什么样的格式显示文字,
逻辑元素:告诉浏览器这些文本有什么样的重要性。
<b>和<strong>的区别:
<b>属于物理标签,只是让文本达成显示文本为粗体的效果。<strong>属于逻辑标签,强调的是该标签在文档中的文档逻辑而不是通过一个命令来告诉浏览器如何显示文本,并且<strong>的显示样式可以改变,可通过其他方式来进行强调显示(加粗只是<strong>的默认样式)。
<i>和<em>的区别:
<i>属于物理标签,斜体<em>属于逻辑标签,强调
<em>和<strong>的区别:
<em>表示对文本定义为强调的内容<strong>表示更为重要的强调,语气上更强烈,强调程度strong大于em。
对于搜索引擎来说<strong>和<em>比<b>和<i>重要,所以这两者通常都被<strong>和<em>所代替了。
2.9 readyonly与disabled的区别
readyonlyhe disabled的作用是使用户不能更改表单域中的内容,但是二者还是有着一些区别的:
(1)readyonly只针对<input type="text/password">和<textarea>有效,而disabled对于所有的表单元素有效,包括select,radio,checkbox,button等。
(2)在表单元素使用了disabled后,我们将表单以POST或者GET的方式提交的话,这个元素的值不会被传递出去,而readonly会将该值传递出去。
2.10 input有哪些type
<input type="text"> //文本框
<input type="password"> //密码框
<input type="submit"> //提交按钮
<input type="checkbox"> //复选框
<input type="radio"> //单选框
<input type="reset"> //重置按钮
<input type="image"> //图片按钮
<input type="hidden"> //隐藏域
<input type="button"> //按钮
<input type="file"> //浏览文件
<!--
公共属性:
Name="";
Value="";
Size="";
-->
2.11 table iframe
2.11.1 table的缺点
(1)太深的嵌套,比如table>tr>td>h3, 会导致搜索引擎读取困难,而且,最直接的损失就是大大增加了冗余代码量
(2)灵活性差,比如要将tr设置border等属性是不行的,得通过td
(3)代码臃肿,当在table中套用table的时候,阅读代码会显得异常混乱
(4)混乱的colspan与rowspan用来布局时,频繁使用他们会造成整个文档顺序混乱
(5)不够语义
2.11.2 div+css布局与table布局相比的优点
(1)改版时更方便
(2)只要改CSS文件
(3)页面加载速度更快、结构化清晰、页面显示简洁
(4)表现与结构相分离
(5)易于优化(seo)搜索引擎更友好,排名更容易靠前
2.11.3 iframe的优缺点
优点:
(1)解决加载缓慢的第三方内容如图标和广告等的加载问题
(2)iframe无刷新文件上传
(3)iframe跨域通信
缺点:
(1)iframe会阻塞主页面的onload事件
(2)无法被一些搜索引擎索引到
(3)页面会增加服务器的http请求
(4)会产生很多页面,不容易管理
2.11.4 很多网站不常用table、iframe这两个元素的原因
因为浏览器页面渲染的时候是从上至下的,而table和iframe这两种元素会改变这样渲染机制,他们是要等待自己元素内的内容加载才整体渲染。用户体验会很不友好。
2.12 Web安全色
Web安全色:
红 绿 蓝 明暗程度
2位 2位 2位 2位
2^8=256种颜色,其中保留色:40种,Web安全色:6红6绿6蓝=216种。用十六进制表示颜色就只能从00,33,66,99,CC,FF这6组值来进行组合。0,3,6,9,C,F这些数值才能组成Web安全色。
2.13 语义化
2.13.1 语义化的理解
- 语义化是你写的HTML结构,是用相对应的有一定语义的英文字母(标签)表示的,标记的,因为HTML本身就是标记语言。
- 易读易写,方便开发
为什么要语义化?
- 代码结构:使页面没有css的情况下,也能够呈现出很好的内容结构。
- 提升用户体验:例如title、alt可以用于解释名称或者解释图片信息,以及label标签的灵活运用。
- 便于团队开发和维护:语义化使代码更具可读性,让其他开发人员更加理解你的html结构,减少差异化。
- 方便其他设备解析:如屏幕阅读器、盲人阅读器、移动设备等,以有意义的方式来渲染网页。
- 有利于SEO:爬虫依赖标签来确定关键字的权重,因此可以和搜索引擎建立良好的沟通,帮助爬虫抓取更多的有效信息
2.13.2 用html知识解决seo优化问题
- html语义化标签要简洁,合理,这样可以在CSS和JS加载不全时,使html文档尽量清晰的展示出来,而不会特别乱。
2.14 HTML5
重点:H5新特性
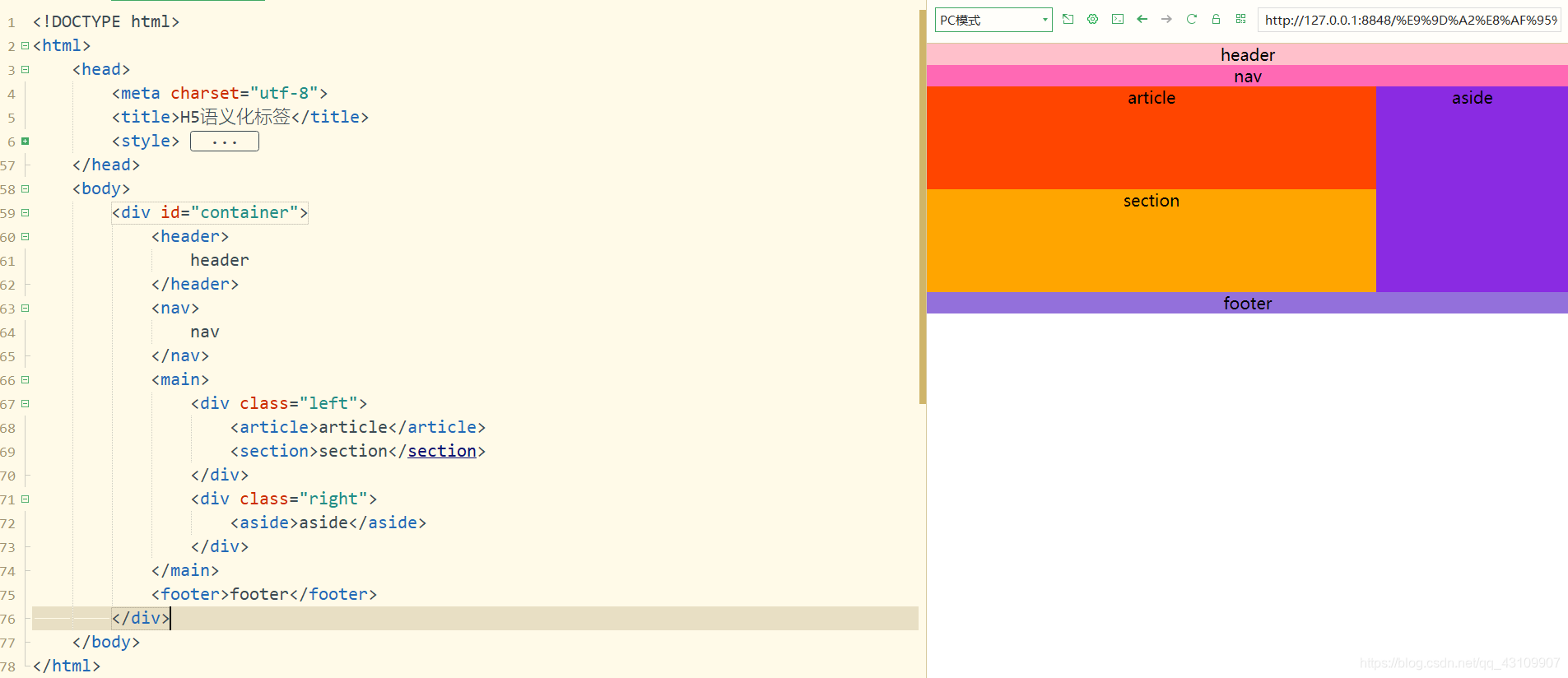
2.14.1 语义化标签
header:
通常被放置在页面或者页面中某个区块元素的顶部,包含整个页面或者区块的标题、简介等信息,起到引导与导航的作用。
nav:
表示页面的导航,可以通过导航连接到网站的其他页面,或者当前页面的其它部分。
aside:
所包含的内容不是页面的主要内容、具有独立性,是对页面的补充。(侧边栏)
footer:
一般被放置在页面或者页面中某个区块的底部,包含版权信息、联系方式等信息。
article:
表示包含于一个文档、页面、应用程序或网站中的一段独立的内容,可以被独立的发布或者重新使用文章标记标签。
section:
是一个主题性的内容分组,通常用于对页面进行分块或者对文章等进行分段。
定义日期或时间,或者两者。
details: 用于描述文档或文档某个部分的细节。
summary:标签包含details元素的标题。
dialog:定义对话框,比如提示框。
2.14.2 增强型表单
| input的type | 描述 |
|---|---|
| color | 选取颜色 |
| date | 从日期选择器选择一个日期 |
| datetime | 选择一个日期(UTC)时间 |
| 包含email地址的输入域 | |
| month | 选择一个月份 |
| number | 数值的输入域 |
| range | 一定范围内数字值的输入域 |
| search | 用于搜索域 |
| tel | 定义输入电话号码字段 |
| time | 选择一个时间 |
| url | URL地址的输入域 |
| week | 选择周和年 |
2.14.3 新增表单元素
| 表单元素 | 描述 |
|---|---|
| datalist | 元素规定输入域的选项列表,使用 input 元素的 list 属性与 datalist 元素的 id 绑定 |
| keygen | 提供一种验证用户的可靠方法,标签规定用于表单的密钥对生成器字段 |
| output | 用于不同类型的输出,比如计算或脚本输出 |
keygen 元素的作用是提供一种验证用户的可靠方法。
keygen 元素是密钥对生成器(key-pair generator)。当提交表单时,会生成两个键,一个是私钥,一个公钥。
私钥(private key)存储于客户端,公钥(public key)则被发送到服务器。公钥可用于之后验证用户的客户端证书(client certificate)。
目前,浏览器对此元素的糟糕的支持度不足以使其成为一种有用的安全标准。
2.14.4 新增表单属性
Required:自动check内容
autofocus:自动获取焦点(页眉一打开就获取到焦点,而不是将光标移动到上面才获取到)
placeholder:默认显示内容
2.14.5 音频audio、视频video
2.14.6 canvas与SVG
2.14.6.1 canvas
通过JavaScript来绘制,使用id来寻找canvas元素(document.getElementById(“”)),再创建context对象(getContext(“2d”)),绘制图形,fillStyle 方法将其染色,fillRect 方法规定了形状、位置和尺寸。
2.14.6.2 SVG
SVG 指可伸缩矢量图形 。
SVG 用于定义用于网络的基于矢量的图形。
SVG 使用 XML 格式定义图形。
SVG 图像在放大或改变尺寸的情况下其图形质量不会有损失。
SVG 是万维网联盟的标准。
与其他图像格式相比(比如 JPEG 和 GIF),使用 SVG 的优势在于:
①SVG 图像可通过文本编辑器来创建和修改
②SVG 图像可被搜索、索引、脚本化或压缩
③SVG 是可伸缩的
④SVG 图像可在任何的分辨率下被高质量地打印
⑤SVG 可在图像质量不下降的情况下被放大
2.14.6.3 Canvas与SVG的比较
| Canvas | SVG | |
|---|---|---|
| 是否依赖分辨率 | 是 | 否 |
| 是否支持事件处理器 | 否 | 是 |
| 渲染 | 弱的文本渲染能力 | 最适合带有大型渲染区域的应用程序(比如谷歌地图),复杂度高会减慢渲染速度(任何过度使用 DOM 的应用都不快) |
| 保存图像 | 能够以 .png 或 .jpg 格式保存结果图像 | |
| 是否适合游戏应用 | 最适合图像密集型的游戏,其中的许多对象会被频繁重绘 | 否 |
2.14.7 地理定位
getCurrentPosition():获得用户的位置
getCurrentPosition() 方法的第二个参数用于处理错误。
①Permission denied - 用户不允许地理定位
②Position unavailable - 无法获取当前位置
③Timeout - 操作超时
showPosition() :获得并显示经度和纬度
Geolocation 对象
watchPosition() - 返回用户的当前位置,并继续返回用户移动时的更新位置(就像汽车上的 GPS)。
clearWatch() - 停止 watchPosition() 方法。
2.14.8 拖拽drag api
(1)元素可拖放,draggable设置为true;
(2)元素拖动
ondragstart 属性调用了一个函数,drag(event),它规定了被拖动的数据。dataTransfer.setData() 方法设置被拖数据的数据类型和值。
function drag(ev)
{
ev.dataTransfer.setData("Text",ev.target.id);
}
(3)拖放位置:ondragover()
默认地,无法将数据/元素放置到其他元素中。如果需要设置允许放置,我们必须阻止对元素的默认处理方式,调用ondragover 事件的event.preventDefault() 方法。
调用 preventDefault() 来避免浏览器对数据的默认处理(drop 事件的默认行为是以链接形式打开)。
通过 dataTransfer.getData(“Text”) 方法获得被拖的数据。该方法将返回在 setData() 方法中设置为相同类型的任何数据。
function drop(ev)
{
ev.preventDefault();
var data=ev.dataTransfer.getData("Text");
ev.target.appendChild(document.getElementById(data));
}
2.14.9 本地存储localStorage和sessionStorage
参见本文1.4.5.1 cookie sessionStorage localStorage部分。
2.14.10 WebSocket
weixin_39863747:
HTML5 WebSocket 简介和实战演练
3 CSS
3.1 W3C盒模型和怪异盒模型
CSS盒模型本质是一个盒子,封装周围的HTML元素,包括边距、边框、填充和实际内容。
标准盒模型:
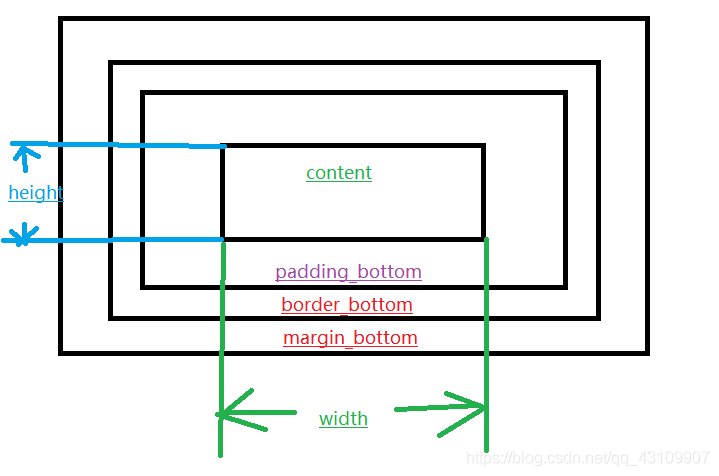
box-sizing: content-box;
width=content
盒子宽度= margin(左右)+ padding(左右)+ border(左右)+ width
IE盒模型(怪异盒模型):
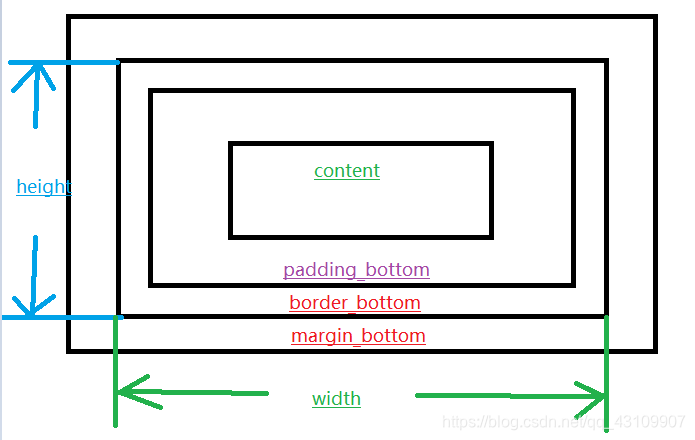
box-sizing: border-box
width = border(左右) + padding(左右) + border(左右)
盒子宽度= margin(左右) + width
3.2 BFC
简书寿木:BFC相关介绍链接
BFC是块格式化上下文。
浮动元素和绝对定位元素,非块级盒子的块级容器(例如 inline-blocks, table-cells, 和 table-captions),以及overflow值不为“visiable”的块级盒子,都会为他们的内容创建新的BFC(块级格式上下文)。

BFC的特性与作用:
①内部的box会在垂直方向一个接一个放置
②box垂直方向的距离由margin决定,同一个BFC相邻两个margin会重叠
③每个box的margin-left会触碰到容器的border-left,即使浮动也如此
④不会发生margin穿透
⑤形成BFC的区域不会与float重叠(可阻止浮动元素造成的环绕现象)
⑥计算BFC高度时浮动元素也参与计算(BFC确切包含浮动的子元素)
⑦原来浮动元素脱离文档流,但与BFC会计算其高度
BFC应用:
①实现自适应两栏布局
②解决父元素高度塌陷
③解决垂直方向兄弟元素的margin重叠
3.3 清除浮动的方法
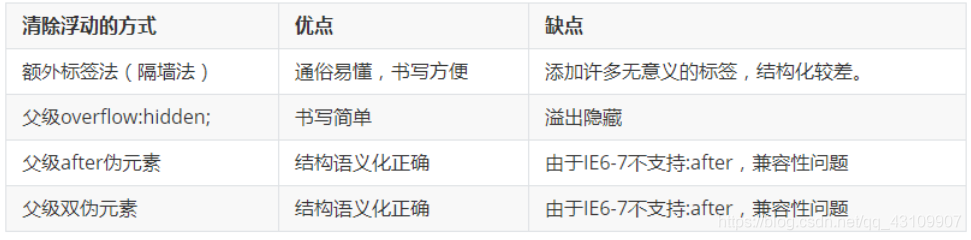
(1)额外标签法:在要清除的浮动元素的末尾添加一个空标签。
.clear{
clear:both;
}
<div class="block1"></div>
<div class="clear"></div>
/*
如<div class="clear"></div>,并在CSS中赋予.clear{clear:both;}属性即可清理浮动。亦可使用<br class="clear" />或<hr class="clear" />来进行清理。*/
(2)父级添加overflow属性方法:可以通过触发BFC的方式,实现清楚浮动效果。给父级加overflow为hidden或者auto或者scroll都可。另外在 IE6 中还需要触发 hasLayout ,例如为父元素设置容器宽高或设置 zoom:1。
在添加overflow属性后,浮动元素又回到了容器层,把容器高度撑起,达到了清理浮动的效果。
(3)使用after伪元素清除浮动:
结合:after 伪元素(注意这不是伪类,而是伪元素,代表一个元素之后最近的元素)和 IEhack ,可以完美兼容当前主流的各大浏览器,这里的 IEhack 指的是触发 hasLayout。
给浮动元素的容器添加一个clearfix的class,然后给这个class添加一个:after伪元素实现元素末尾添加一个看不见的块元素(Block element)清理浮动。
.clearfix:after {
content: "";
visibility: hidden;
display: block;
clear: both;
height: 0;
}
.clearfix {
*zoom: 1; /* IE6、7 专有 */
}
(4)使用before和after双伪元素清除浮动:
.clearfix:before,
.clearfix:after {
content: "";
display: table;
}
.clearfix:after {
clear: both;
}
.clearfix {
*zoom: 1; /* 由于IE6-7不支持:after,使用zoom: 1触发hasLayout */
}
(5)使用邻接元素处理:
什么都不做,给浮动元素后面的元素添加clear属性。
(6)给浮动的元素的容器添加浮动
给浮动元素的容器也添加上浮动属性即可清除内部浮动,但是这样会使其整体浮动,影响布局,不推荐使用。
3.4 position的属性
| 值 | 描述 |
|---|---|
| absolute(绝对定位) | 绝对定位的元素的位置相对于最近的已定位父元素,如果元素没有已定位的父元素,那么它的位置相对于<html>。 absolute 定位使元素的位置与文档流无关,因此不占据空间。 absolute 定位的元素和其他元素重叠。 |
| fixed(固定定位) | 元素的位置相对于浏览器窗口是固定位置,即使窗口是滚动的它也不会移动。Fixed定位使元素的位置与文档流无关,因此不占据空间。 Fixed定位的元素和其他元素重叠。 |
| relative(相对定位) | 如果对一个元素进行相对定位,它将出现在它所在的位置上。然后,可以通过设置垂直或水平位置,让这个元素“相对于”它的起点进行移动。 在使用相对定位时,无论是否进行移动,元素仍然占据原来的空间。因此,移动元素会导致它覆盖其它框。 |
| static(默认定位) | 默认值。没有定位,元素出现在正常的流中(忽略top, bottom, left, right 或者 z-index 声明)。 |
| sticky(粘性定位) | 元素先按照普通文档流定位,然后相对于该元素在流中的flow root(BFC)和 containing block(最近的块级祖先元素)定位。而后,元素定位表现为在跨越特定阈值前为相对定位,之后为固定定位。 |
| inherit | 规定应该从父元素继承position 属性的值。 |
3.5 水平垂直居中的方法
3.6 flex布局
听风是风:Flex布局
Flex布局是弹性布局,设为Flex布局后,子元素的float、clear、vertical-align属性失效。采用Flex布局的元素为Flex容器。
Flex容器的属性:
①flex-direction:决定主轴的方向(即项目的排序方向)。
flex-direction: row | row-reverse | column | column-reverse
②flex-wrap:默认情况下,项目都排在一条线(又称"轴线")上。flex-wrap属性定义,如果一条轴线排不下,如何换行。
flex-wrap: nowrap | wrap | wrap-reverse
③flex-flow:flex-flow属性是flex-direction属性和flex-wrap属性的简写形式。
flex-flow: <flex-direction> || <flex-wrap>
④justify-content:定义了项目在主轴上的对齐方式。
justify-content: flex-start | flex-end | center | space-between | space-around
⑤align-items:定义项目在交叉轴上如何对齐。
align-items: flex-start | flex-end | center | baseline | stretch
⑥align-content:定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
align-content: flex-start | flex-end | center | space-between | space-around | stretch
Flex项目的属性:
①order:定义项目的排列顺序。数值越小,排列越靠前,默认为0。
②flex-grow:
- 定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。
- 如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)。
- 如果一个项目的flex-grow属性为2,其他项目都为1,则前者占据的剩余空间将比其他项多一倍。
③flex-shrink:
- 定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
- 如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小。
- 如果一个项目的flex-shrink属性为0,其他项目都为1,则空间不足时,前者不缩小。
④flex-basis:定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。它的默认值为auto,即项目的本来大小。
⑤flex:是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto。后两个属性可选。
⑥align-self:允许单个项目有与其他项目不一样的对齐方式,可覆盖align-items属性。默认值为auto,表示继承父元素的align-items属性,如果没有父元素,则等同于stretch。
3.7 双栏布局、三栏布局
3.8 等高布局
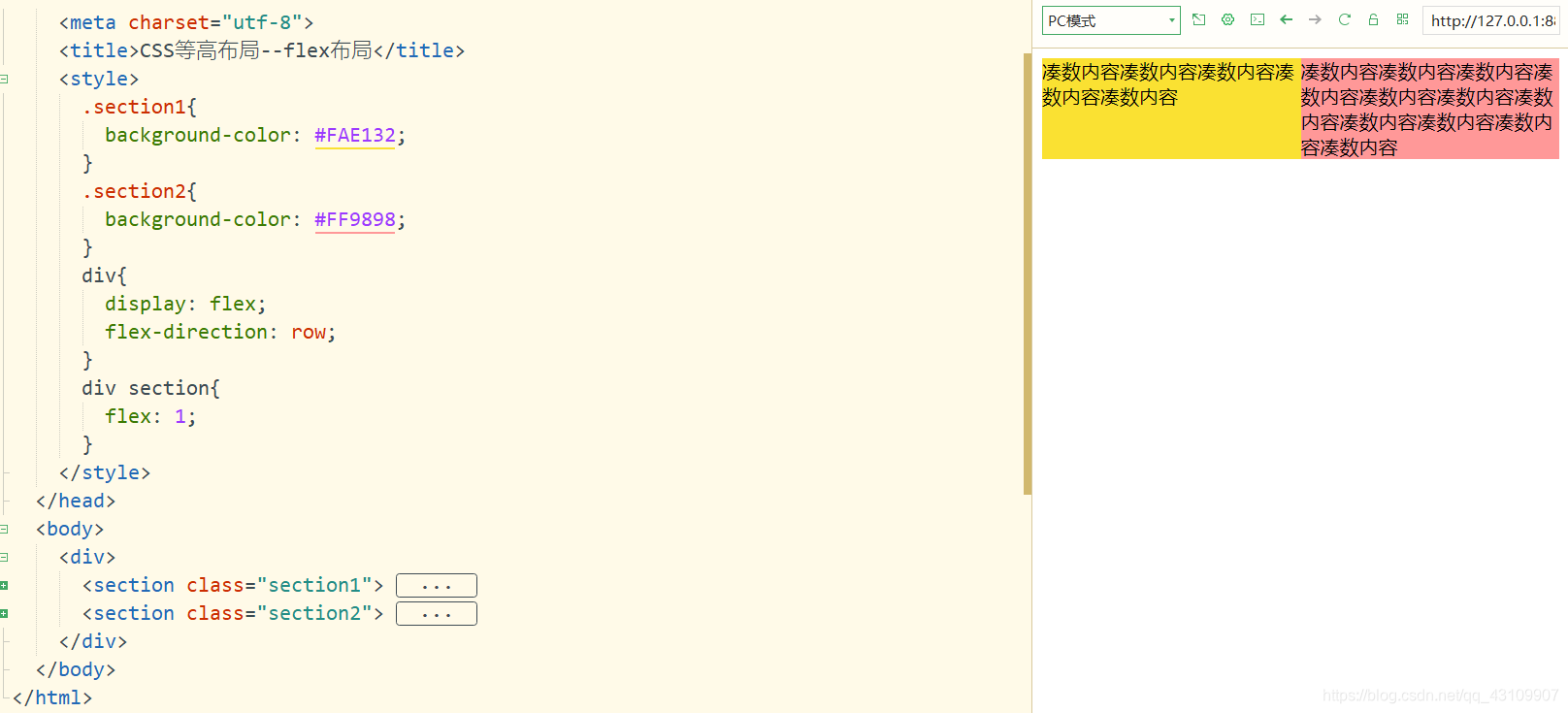
3.8.1 flex布局
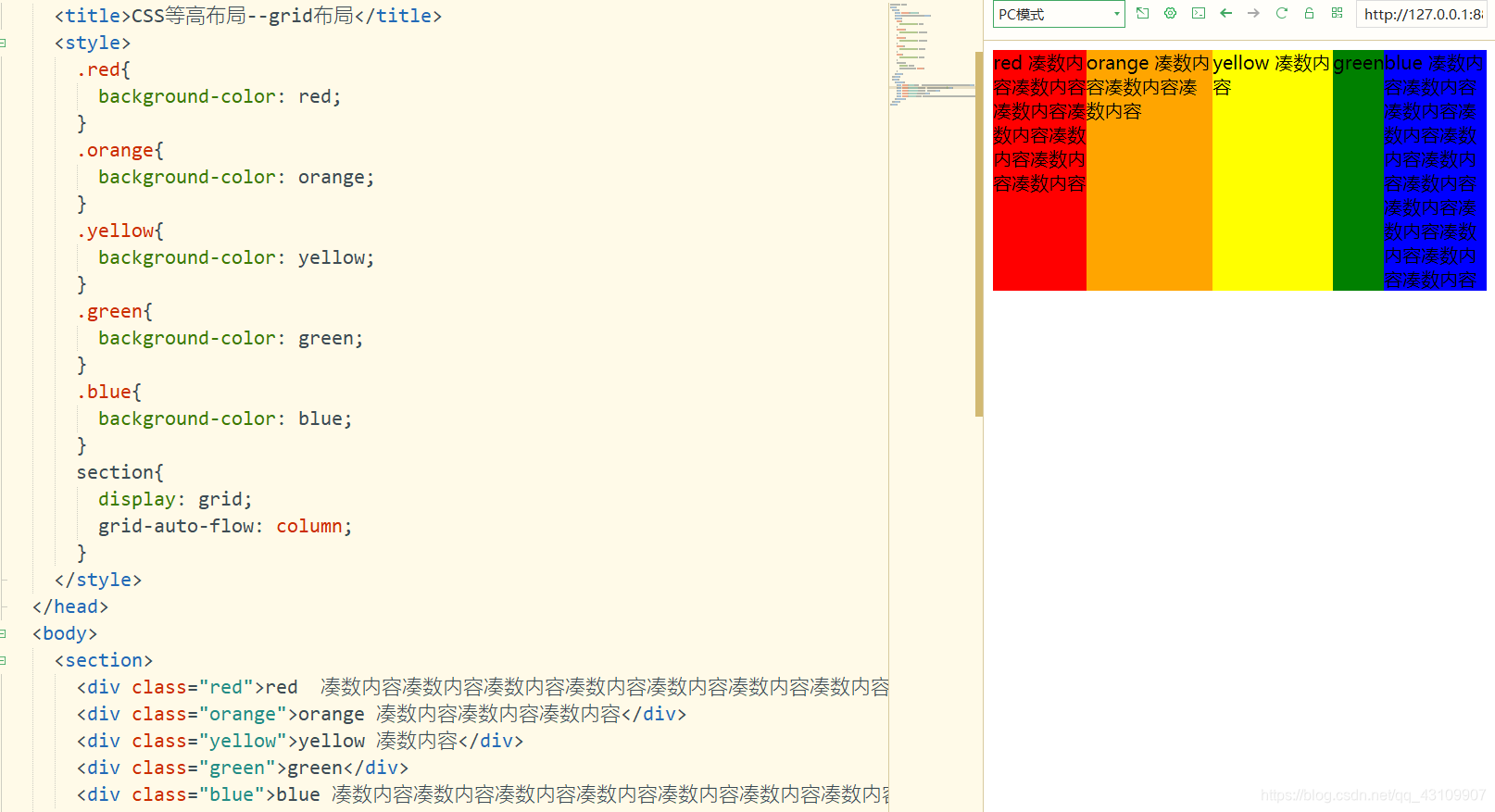
3.8.2 grid布局
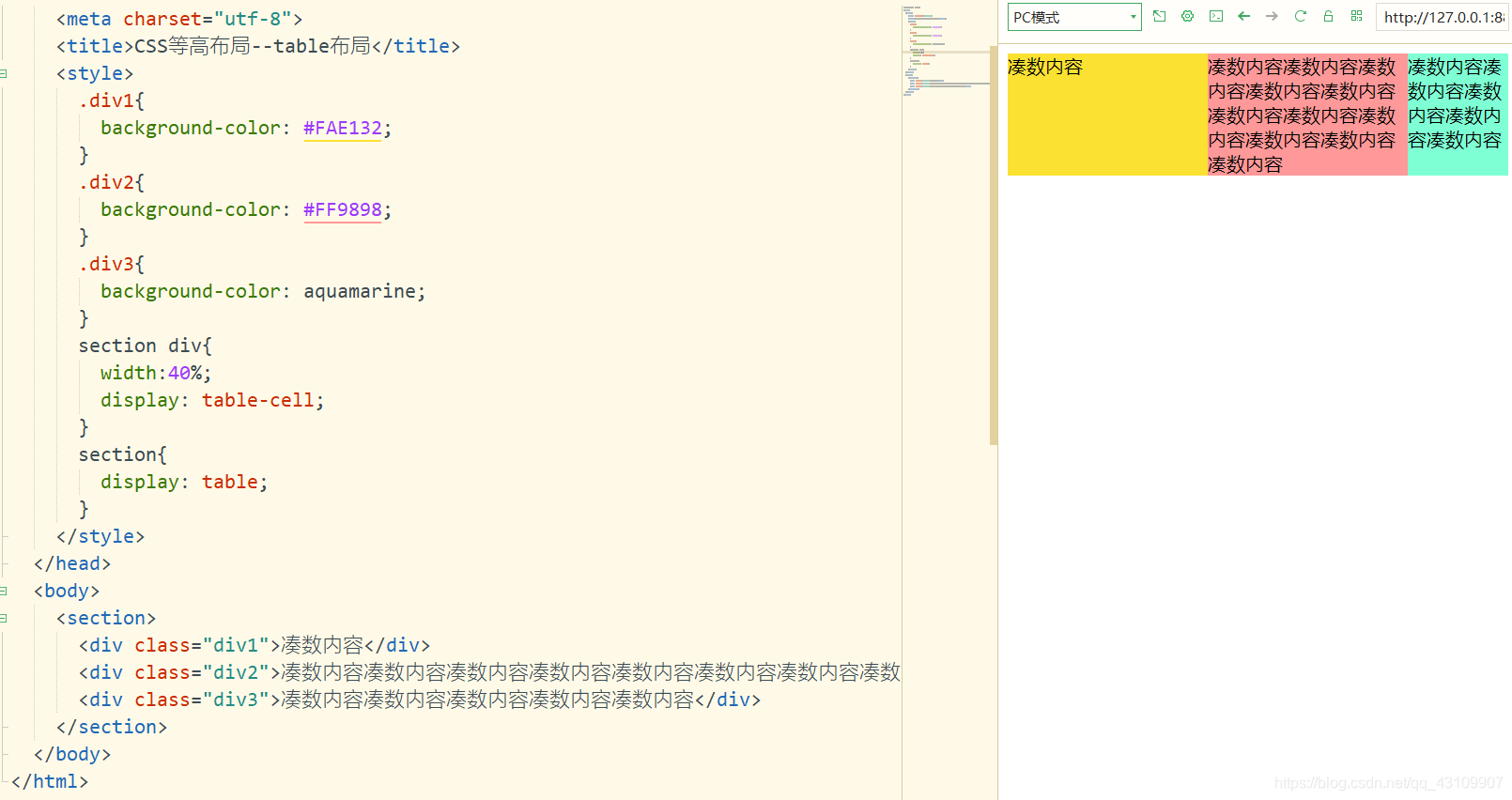
3.8.3 table布局
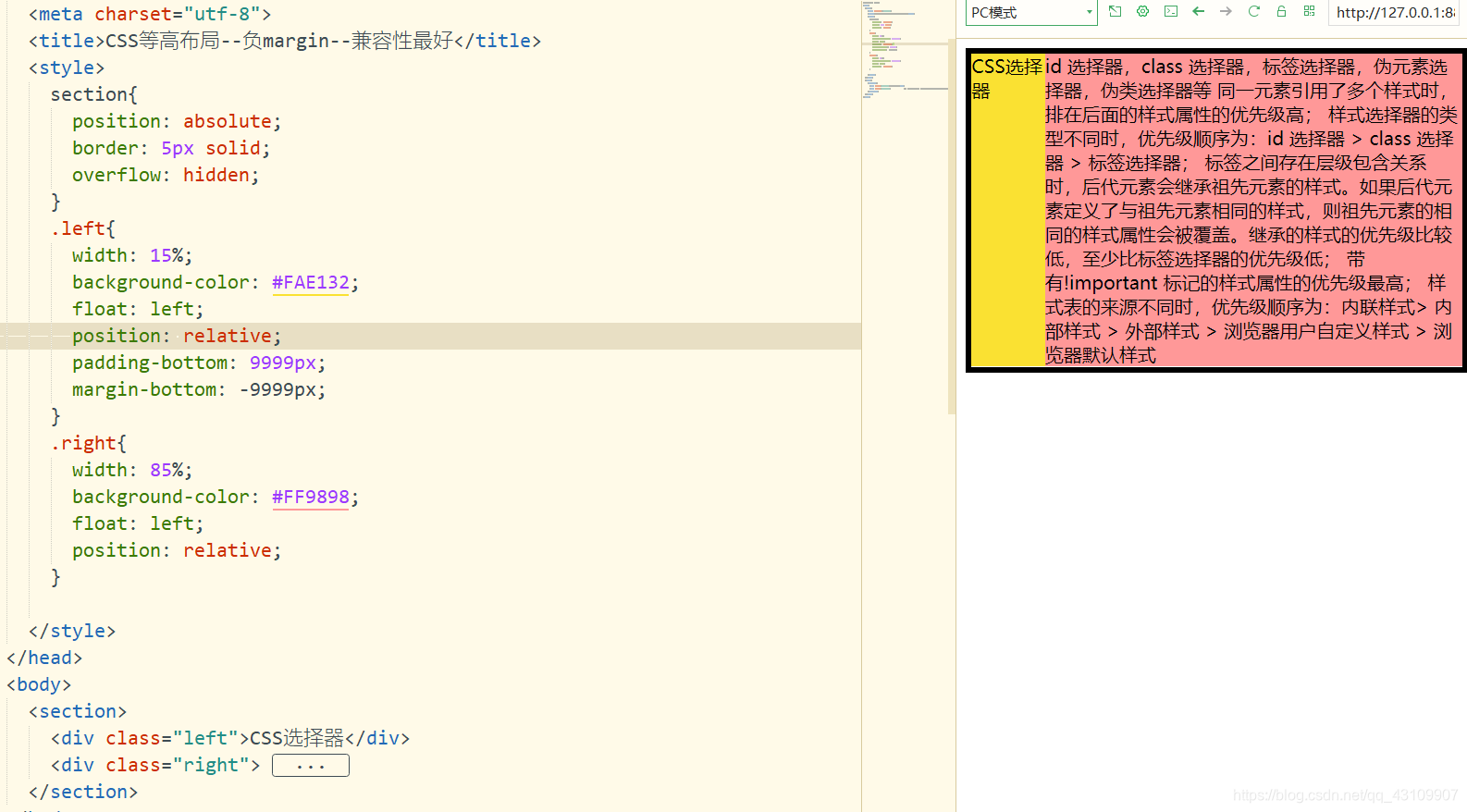
3.8.4 负margin(兼容性最好)
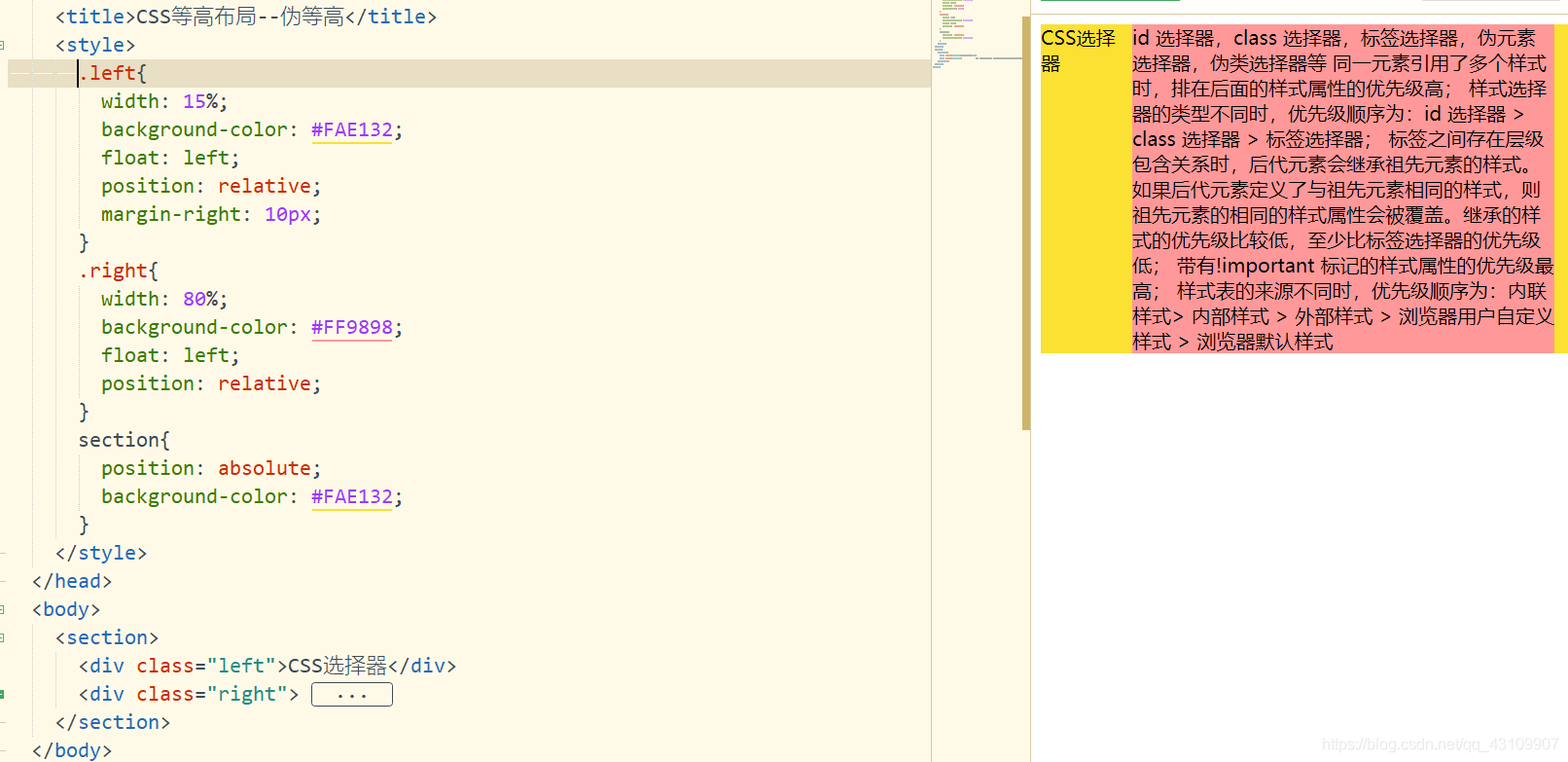
3.8.5 伪等高布局
3.9 重排和重绘
重排/回流(reflow):当渲染树中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。每个页面至少需要一次回流,就是在页面第一次加载的时候。
重绘(repaint)是指一个元素外观的改变所触发的浏览器行为,浏览器会根据元素的新属性重新绘制,使元素呈现新的外观。
重绘和重排的关系:在回流的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成回流后,浏览器会重新绘制受影响的部分到屏幕中,该过程称为重绘。
重排必定会引发重绘,但重绘不一定会引发重排。
imooc网小白师兄:前端性能优化:细说浏览器渲染的重排与重绘
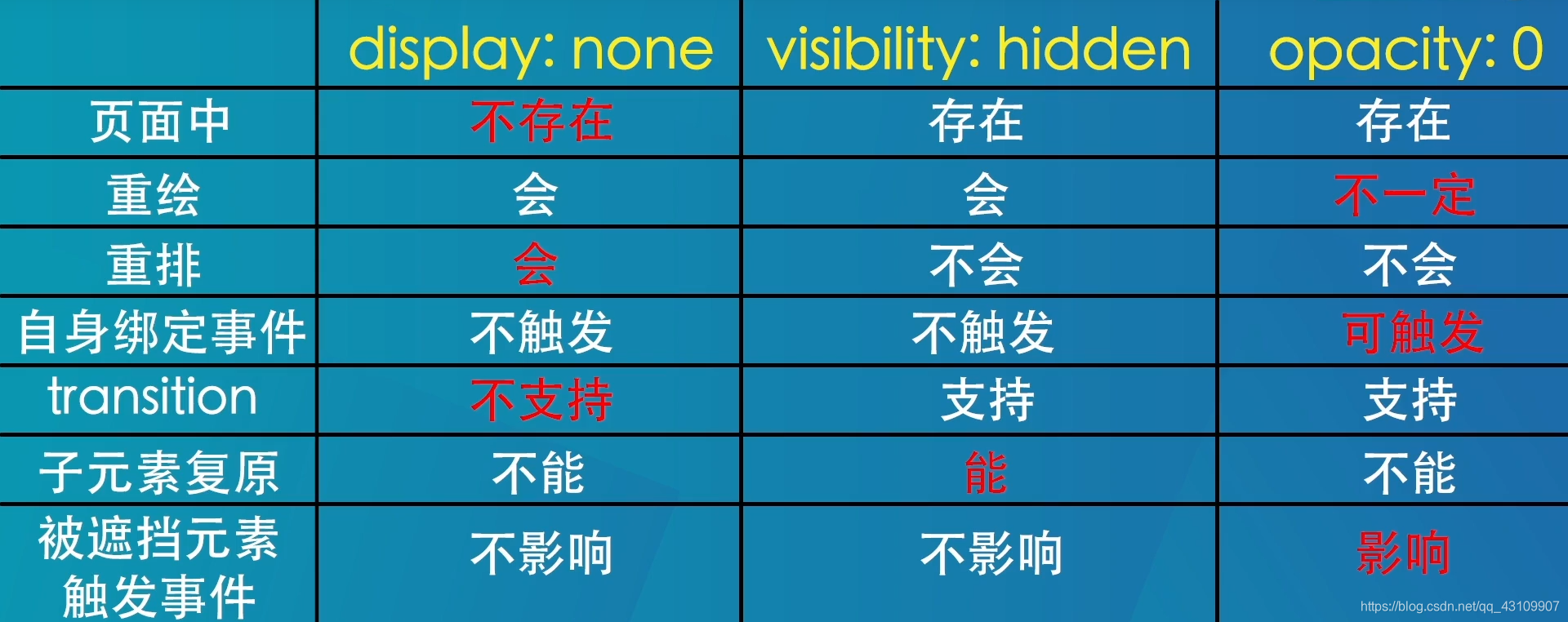
3.10 CSS隐藏元素的方式
3.11 CSS选择器
-
id 选择器,class 选择器,标签选择器,伪元素选择器,伪类选择器等
-
同一元素引用了多个样式时,排在后面的样式属性的优先级高;
-
样式选择器的类型不同时,优先级顺序为:id 选择器 > class 选择器 > 标签选择器;
-
标签之间存在层级包含关系时,后代元素会继承祖先元素的样式。如果后代元素定义了与祖先元素相同的样式,则祖先元素的相同的样式属性会被覆盖。继承的样式的优先级比较低,至少比标签选择器的优先级低;
-
带有!important 标记的样式属性的优先级最高;
-
样式表的来源不同时,优先级顺序为:内联样式> 内部样式 > 外部样式 > 浏览器用户自定义样式 > 浏览器默认样式
3.12 伪类/伪元素
伪类:与类一样能够定义样式,但却不是真正意义的类。
HTML中如何实现样式:浏览器会在后台向这些伪类增加和删除元素。


3.13 CSS动画
3.13.1 CSS动画
- 创建动画序列,需要使用animation属性或其子属性,该属性允许配置动画时间、时长以及其他动画细节,但该属性不能配置动画的实际表现,动画的实际表现是由 @keyframes规则实现,具体情况参见使用keyframes定义动画序列小节部分。
| animation属性 | 描述 |
|---|---|
| animation-name | 动画名称。和@keyframes名称一致。 |
| animation-duration | 动画持续时间。 |
| animation-delay | 动画延迟时间。 |
| animation-timing-function | 动画运动轨迹。 |
| animation-iteration-count | 动画运动次数,infinite无限循环。 |
| animation-direction | 动画方向。alternate先正向再反向。 |
- transition也可实现动画。transition强调过渡,是元素的一个或多个属性发生变化时产生的过渡效果,同一个元素通过两个不同的途径获取样式,而第二个途径当某种改变发生(例如hover)时才能获取样式,这样就会产生过渡动画。
| transition属性 | 描述 |
|---|---|
| transition-property | 指定要过渡的CSS属性 |
| transition-duration | 指定完成过渡要花费的时间 |
| transition-delay | 指定过渡开始出现的延迟时间 |
| transition-timing-function | 指定过渡函数 |
| transition-timing-function有以下几种: | |
| 值 | 描述 |
| – | – |
| linear | 匀速 |
| ease | 相当于匀速,但是开始和结束慢速,中间快速 |
| ease-in | 减速 |
| ease-out | 加速 |
| ease-in-out | 开始和结束是慢速 |
| cubic-bezier(n,n,n,n) | 贝塞尔曲线 |
 |
3.13.2 js动画和css3动画的差异性
- 渲染线程分为main thread和compositor thread,如果css动画只改变transform和opacity,这时整个CSS动画得以在compositor thread完成(而js动画则会在main thread执行,然后出发compositor thread进行下一步操作),特别注意的是如果改变transform和opacity是不会layout或者paint的。
- 区别:
- 功能涵盖面,js比css大
- 实现/重构难度不一,CSS3比js更加简单,性能跳优方向固定
- 对帧速表现不好的低版本浏览器,css3可以做到自然降级
- css动画有天然事件支持
- css3有兼容性问题
3.13.3 CSS3兼容性问题
- 一般加私有前缀否则不做特殊处理
- 遵循两大原则
- 渐进增强
- 优雅降级
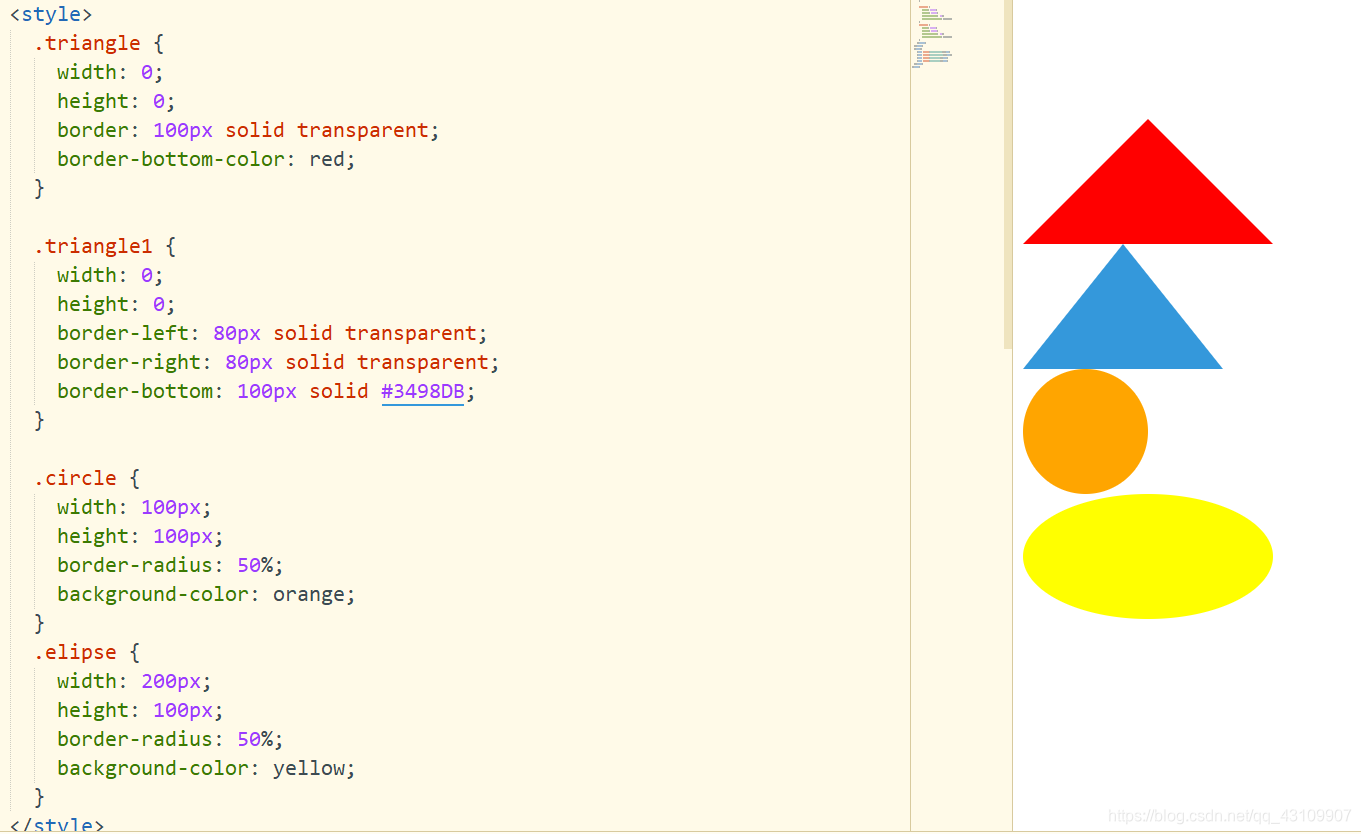
3.14 CSS画三角形、圆形、椭圆形
3.15 CSS3新增属性用法
- box-shadow(阴影效果)
- border-color(为边框设置多种颜色)
- border-image(图片边框)
- text-shadow(文本阴影)
- text-overflow(文本截断)
- word-wrap(自动换行)
- border-radius(圆角边框)
- opacity(透明度)
- box-sizing(控制盒模型的组成模式)
- resize(元素缩放)
- outline(外边框)
- background-size(指定背景图片尺寸)
- background-origin(指定背景图片从哪里开始显示)
- background-clip(指定背景图片从什么位置开始裁剪)
- background(为一个元素指定多个背景)
- hsl(通过色调、饱和度、亮度来指定颜色颜色值)
- hsla(在hsl的基础上增加透明度设置)
- rgba(基于rgb设置颜色,a设置透明度)
3.16 CSS Sprites
- 简介
CSS Sprites在国内很多人叫css精灵,是一种网页图片应用处理方式。它允许将一个页面涉及到的所有零星图片都包含到一张大图中, 利用CSS的“background-image”,“background- repeat”,“background-position”的组合进行背景定位, 访问页面时避免图片载入缓慢的现象。 - 优点
(1)CSS Sprites能很好地减少网页的http请求,从而大大的提高页面的性能,这是CSS Sprites最大的优点,也是其被广泛传播和应用的主要原因;
(2)CSS Sprites能减少图片的字节;
(3)CSS Sprites解决了网页设计师在图片命名上的困扰,只需对一张集合的图片命名,不需要对每一个小图片进行命名,从而提高了网页制作效率。
(4)CSS Sprites只需要修改一张或少张图片的颜色或样式来改变整个网页的风格。 - 缺点
(1)图片合并麻烦:图片合并时,需要把多张图片有序的合理的合并成一张图片,并留好足够的空间防止版块出现不必要的背景。
(2)图片适应性差:在高分辨的屏幕下自适应页面,若图片不够宽会出现背景断裂。
(3)图片定位繁琐:开发时需要通过工具测量计算每个背景单元的精确位置。
(4)可维护性差:页面背景需要少许改动,可能要修改部分或整张已合并的图片,进而要改动css。在避免改动图片的前提下,又只能(最好)往下追加图片,但这样增加了图片字节。
3.17 CSS hack
CSS hack是针对不同浏览器写不同的CSS code的过程。
#test {
width: 500px;
height: 500px;
background-color: red; /*firefox*/
background-color: orange\9; /*all IE*/
:root #test {
background-color: yellow\9; /*IE9*/
};
background-color: green; /*IE8*/
+backgorund-color: AquaMarine;/*IE7*/
_background-color: blue; /*IE6*/
@media all and (min-width: 0px)
}
{
#test {
background-color: purple;
}
} /*opera*/
@media screen and (-webkit-min-device-pixel-ratio:0)
{
#test {
background-color: black;
}
} /*chrome and safari*/
3.18 双边距重叠问题
多个相邻(兄弟或者父子关系)普通流的块元素垂直方向marigin会重叠
折叠的结果为:
①两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值。
②两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值。
③两个外边距一正一负时,折叠结果是两者的相加的和。
3.19 px rem em
- px是固定长度单位,不随其它元素的变化而变化。
- em是相对于父级元素的单位,会随父级元素的属性(font-size或其它属性)变化而变化。
- rem是相对于根目录(HTML元素)的,所有它会随HTML元素的属性(font-size)变化而变化。
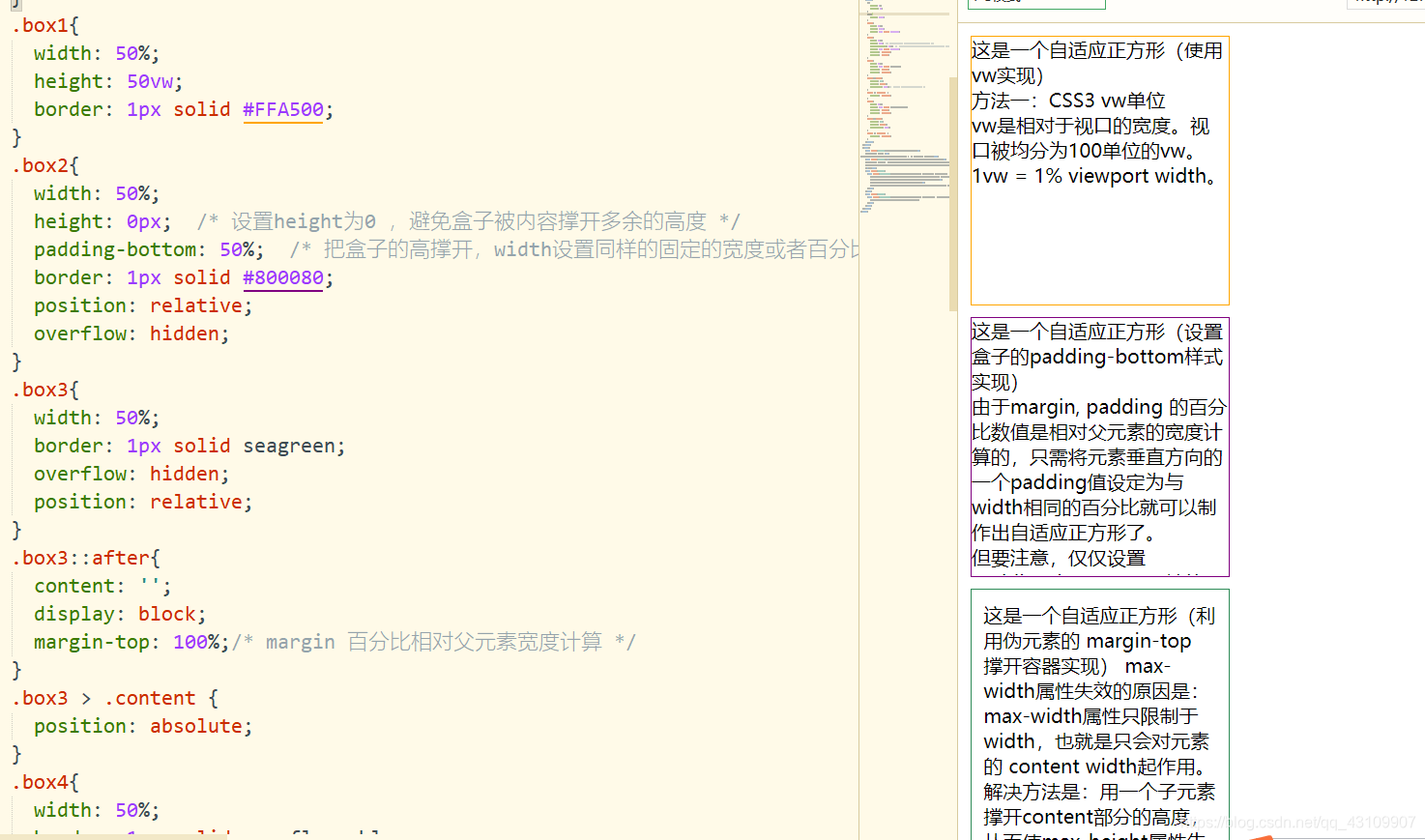
3.20 自适应正方形
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>自适应布局实现正方形</title>
<style>
*{
margin: 0;
padding: 0;
}
div{
margin: 10px;
}
.box1{
width: 50%;
height: 50vw;
border: 1px solid #FFA500;
}
.box2{
width: 50%;
height: 0px; /* 设置height为0 ,避免盒子被内容撑开多余的高度 */
padding-bottom: 50%; /* 把盒子的高撑开,width设置同样的固定的宽度或者百分比 ,百分比相对的是父元素盒子的宽度 */
border: 1px solid #800080;
position: relative;
overflow: hidden;
}
.box3{
width: 50%;
border: 1px solid seagreen;
overflow: hidden;
position: relative;
}
.box3::after{
content: '';
display: block;
margin-top: 100%;/* margin 百分比相对父元素宽度计算 */
}
.box3 > .content {
position: absolute;
}
.box4{
width: 50%;
border: 1px solid cornflowerblue;
overflow: hidden;
position: relative;
}
.box4::after{
content: '';
display: block;
padding-top: 100%;
}
.box4 > .content {
position: absolute;
}
</style>
</head>
<body>
<div class="box1">这是一个自适应正方形(使用vw实现)<br>
方法一:CSS3 vw单位 <br>
vw是相对于视口的宽度。视口被均分为100单位的vw。1vw = 1% viewport width。</div>
<div class="box2"><p>这是一个自适应正方形(设置盒子的padding-bottom样式实现)<br>
由于margin, padding 的百分比数值是相对父元素的宽度计算的,只需将元素垂直方向的一个padding值设定为与width相同的百分比就可以制作出自适应正方形了。<br>
但要注意,仅仅设置padding-bottom是不够的,若向容器添加内容,内容会占据一定高度,为了解决这个问题,需要设置height: 0。
</p></div>
<div class="box3">
<div class="content">这是一个自适应正方形(利用伪元素的 margin-top 撑开容器实现)
max-width属性失效的原因是:max-width属性只限制于width,也就是只会对元素的 content width起作用。<br>
解决方法是:用一个子元素撑开content部分的高度,从而使max-height属性生效。<br>
首先需要设置伪元素,其内容为空,margin-top设置为100%。<br>
但要注意,若使用垂直方向上的margin撑开父元素,仅仅设置伪元素是不够的,这涉及到margin collapse外边距合并的概念,由于容器与伪元素在垂直方向发生了外边距合并,所以撑开父元素高度并没有出现,解决方法是在父元素上触发BFC:设置overflow:hidden。
</div>
</div>
<div class="box4">
<div class="content">这是一个自适应正方形(利用伪元素的 padding-top 撑开容器实现)<br>
若使用垂直方向上的padding撑开父元素,则不需要触发BFC。
</div>
</div>
</body>
</html>
3.21 z-index的定位方法
- z-index属性设置元素的堆叠顺序,拥有更好堆叠顺序的元素会处于较低顺序元素之前。
- z-index可以为负,且z-index只能在定位元素上奏效,该属性设置一个定位元素沿z轴的位置
- 如果z-index为正数,离用户越近,为负数,离用户越远,它的属性值有auto,默认,堆叠顺序与父元素相等,number,inherit,从父元素继承z-index属性的值
3.22 SASS与LESS
- SASS和LESS都是CSS预处理器,是CSS上的一种抽象层,是一种特殊的语法/语言编译成CSS。
- 区别
- 编译环境不同,SASS在服务端处理,LESS在浏览器端处理
- 变量符号不同,LESS用@,SASS用$
- SASS支持条件语句,LESS不支持
- 为什么使用它们
- 结构清晰,方便扩展
- 可以方便屏蔽浏览器私有语法差异,封装对浏览器语法差异的重复处理
- 减少无意义的机械劳动
- 可以轻松实现多重继承
- 完全兼容CSS代码,可以方便地应用到老项目中。LESS只是在CSS语法上扩展,所以老的CSS代码也可以与LESS代码一同编译。
简书OnlyPiglet:SASS基本指令
4 JS
5 JQuery
5.1 JQuery库中的$()是什么?
$() 函数是 jQuery() 函数的别称,$() 函数用于将任何对象包裹成 jQuery 对象,被允许调用定义在 jQuery 对象上的多个不同方法。可以将一个选择器字符串传入$()函数,它会返回一个包含所有匹配的 DOM 元素数组的 jQuery 对象。
5.2 JQuery获取的DOM对象和原生DOM对象的区别和相互转换
jQuery转DOM对象:
(1)jQuery是一个数组对象,可以通过[index]的得到相应的DOM对象。
(2)可以通过get[index]去得到相应的DOM对象。
DOM转jQuery对象:
$(DOM对象)
5.3 JQuery绑定事件的方式
- jQuery中提供了四种绑定事件 的方法,分别是bind、live、delegate、on,对应的解除监听的函数分别是unbind、die、undelegate、off。
(1)bind(type,[data],fn)为每个匹配元素的特定事件绑定事件处理函数
$("a").bind("click",function() {
alert("ok");
});
(2)live(type,[data],fn)给所有匹配的元素附加一个事件处理函数,即使这个元素是以后添加进来的
$("a").live("click",function() {
alert("ok");
});
(3)delegate(selector,[type],[data],fn)指定的元素(属于被选元素的子元素)添加一个或多个事件处理程序,并规定当这些时间发生时运行的函数
$("container").delegate("a","click",function() {
alert("ok");
})
(4)on(event,[selector],[data],fn)在选择元素上绑定一个或多个事件的事件处理函数
区别:
(1).bind()是直接绑定在元素上
(2).live()则是通过冒泡的方式来绑定到元素上。更合适列表类型的,绑定到document DOM节点上。和.bind()的优势是支持动态数据。
(3).delegate()是更精确的小范围使用事件代理,性能优于.live()
(4).on()是最新的1.9版本整合了之前的三种方式的新事件绑定机制。
5.4 jQuery.extend和jQuery.fn.extend的区别
jQuery为开发插件提供了两个方法:
(1)jQuery.extend():用来扩展jQuery对象本身
(2)jQuery.fn.extend():用来扩展jQuery实例
5.5 jQuery.fn的init方法返回的this指的是什么对象?为什么要返回this?
this执行init构造函数自身,其实就是jQuery实例对象,返回this是为了实现jQuery的链式操作。
5.6 jQuery和zepto的区别
jQuery和zepto的关联:
- zepto最初是为移动端开发的库,是jQuery的轻量级替代品,因为它的API和jQuery相似,而文件更小。zepto最大的优势是它的文件大小,只有8k多,是目前功能完备的库中最小的一个,尽管不大,zepto所提供的的工具足以满足开发程序的需要。
- 大多数jQuery中常用的API和方法zepto也有,zepto中还有一些jQuery没有的。另外,因为zepto的API大部分都能和jQuery兼容,所以用起来极其容易。
- 如果熟悉jQuery,就能很容易掌握zepto。可以用同样的方法重用jQuery的很多方法,也可以方便的把办法串起来得到更简洁的代码,甚至不用看它的文件。
jQuery和zepto的区别:
- 针对移动端程序,zepto有一些基本的触摸事件可以用来做触摸屏交互(tap事件、swipe事件),zepto是不支持IE浏览器的,因为开发者想降低文件尺寸。
- jQuery和zepto的API不是完全兼容的,使用zepto方法时一定要做足充分的测试。
- 具体区别:
- (1)width()和height()的区别
- zepto由盒模型(box-sizing)决定,用.width()返回赋值的width,用.css(‘width’)返回border等的结果。
- jQuery会忽略盒模型,始终返回内容区域的宽/高(不包含padding、border)。
- (2)offset()的区别
- zepto返回{top,left,width,height}
- jQuery返回{width,height}
- (3)zepto无法获取隐藏元素宽高,jQuery可以。
- (4)zepto中没有为原型定义extend方法,而jQuery有。
- (1)width()和height()的区别
5.7 jQuery中attr和prop的区别
monkeyfly007:jQuery中attr()与prop()的区别

5.8 jQuery中detach()和remove()的区别
detach()和remove()都是用来移除一个DOM元素。
区别:
- detach()会保持对过去被解除元素的跟踪,可以被取消解除。
- remove()会保持过去被移除对象的引用。
5.9 jQuery中的find、children、fliter的区别
(1)find()和children()方法的区别:
①children及find方法都用是用来获得element的子elements的,两者都不会返回 text node,就像大多数的jQuery方法一样。
②children方法获得的仅仅是元素一下级的子元素,即:immediate children。
③find方法获得所有下级元素,即:descendants of these elements in the DOM tree
④children方法的参数selector 是可选的(optionally),用来过滤子元素,但find方法的参数selector方法是必选的。
⑤find方法事实上可以通过使用 jQuery( selector, context )来实现:英语如是说:Selector context is implemented with the .find() method; therefore, $(‘li.item-ii’).find(‘li’) is equivalent to $(‘li’, ‘li.item-ii’).
(2)find()和filter()方法的区别:
find()会在div元素内 寻找 class为rain 的元素。
而filter()则是筛选div的class为rain的元素。


















 3079
3079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









