







设计模式
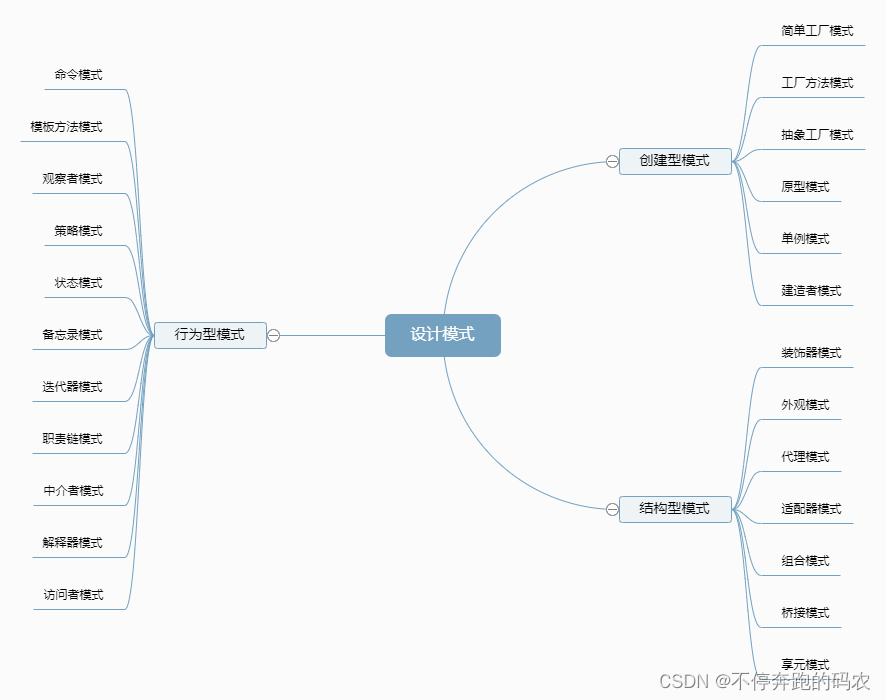
1、创建型模式
1.1、简单工厂模式
简单工厂模式(Simple Factory Pattern)是一种创建型设计模式,它将对象的创建过程封装起来,使得用户只需要提供一个类型参数即可获得所需要的对象,而无需关心对象的创建细节。
在简单工厂模式中,我们通常会定义一个工厂类,它负责根据用户给定的类型参数创建相应的对象,并将其返回给用户。由于所有的对象都是从同一个工厂类中创建出来的,因此这种模式也被称为静态工厂模式。
简单工厂模式包含以下角色:
- 抽象产品(Product):定义了产品的基本属性和方法。
- 具体产品(Concrete Product):实现了抽象产品的接口,并提供了具体的实现。
- 工厂类(Factory):负责创建具体产品的对象,并将其返回给客户端。
下面是一个简单的简单工厂模式示例代码:
#include <iostream>
using namespace std;
// 抽象产品
class Product {
public:
virtual void use() = 0; // 定义了产品的基本功能接口
virtual ~Product() {}
};
// 具体产品 A
class ConcreteProductA : public Product {
public:
void use() override { // 实现了产品的具体功能
cout << "Using product A." << endl;
}
};
// 具体产品 B
class ConcreteProductB : public Product {
public:
void use() override { // 实现了产品的具体功能
cout << "Using product B." << endl;
}
};
// 工厂类
class Factory {
public:
static Product* createProduct(char type) { // 静态方法,根据类型参数创建相应的产品对象
switch (type) {
case 'A': return new ConcreteProductA();
case 'B': return new ConcreteProductB();
default: return nullptr;
}
}
};
int main() {
Product* p1 = Factory::createProduct('A'); // 创建具体产品 A 对象
Product* p2 = Factory::createProduct('B'); // 创建具体产品 B 对象
p1->use(); // 输出:Using product A.
p2->use(); // 输出:Using product B.
delete p1;
delete p2;
return 0;
}
在上面的代码中,我们定义了一个抽象产品类(Product)和两个具体产品类(ConcreteProductA、ConcreteProductB),它们分别实现了自己的具体功能。另外,我们还定义了一个工厂类(Factory),负责根据用户给定的类型参数创建相应的产品对象。
在主函数中,我们通过调用工厂类的静态方法createProduct()创建了不同类型的产品对象,并测试了它们的具体功能。
通过简单工厂模式,我们可以将对象的创建过程封装起来,使得用户只需要提供一个类型参数即可获得所需要的对象,而无需关心对象的创建细节。
1.2、工厂方法模式
工厂方法模式(Factory Method Pattern)是一种创建型设计模式,它通过定义一个用于创建对象的接口,让子类决定实例化哪一个类。也就是说,工厂方法模式将对象的创建延迟到子类中进行,从而实现了开闭原则。
在工厂方法模式中,我们通常会定义一个抽象工厂类,它负责定义工厂方法的接口,并可以包含多个工厂方法。每个工厂方法都负责创建一种具体产品的对象,这些工厂方法所创建出来的对象都必须实现同一抽象产品接口。由于每个具体工厂只能创建一种具体产品,因此该模式也被称为多态性工厂模式。
工厂方法模式包含以下角色:
- 抽象产品(Product):定义了产品的基本属性和方法。
- 具体产品(Concrete Product):实现了抽象产品的接口,并提供了具体的实现。
- 抽象工厂(Abstract Factory):定义了工厂方法的接口,并可以包含多个工厂方法。
- 具体工厂(Concrete Factory):实现了工厂方法的接口,并负责创建一种具体产品的对象。
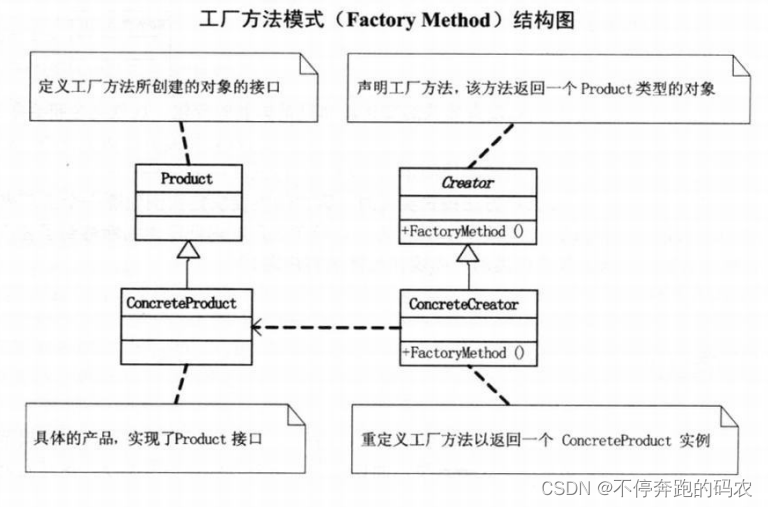
下面是一个简单的工厂方法模式示例代码::
#include <iostream>
using namespace std;
// 抽象产品
class Product {
public:
virtual void use() = 0; // 定义了产品的基本功能接口
virtual ~Product() {} // 声明为虚析构函数
};
// 具体产品 A
class ConcreteProductA : public Product {
public:
void use() override { // 实现了产品的具体功能
cout << "Using product A." << endl;
}
};
// 具体产品 B
class ConcreteProductB : public Product {
public:
void use() override { // 实现了产品的具体功能
cout << "Using product B." << endl;
}
};
// 抽象工厂
class Factory {
public:
virtual Product* createProduct() = 0; // 工厂方法,用于创建产品对象
};
// 具体工厂 A
class ConcreteFactoryA : public Factory {
public:
Product* createProduct() override { // 实现工厂方法,创建具体产品 A 对象
return new ConcreteProductA();
}
};
// 具体工厂 B
class ConcreteFactoryB : public Factory {
public:
Product* createProduct() override { // 实现工厂方法,创建具体产品 B 对象
return new ConcreteProductB();
}
};
int main() {
Factory* factoryA = new ConcreteFactoryA(); // 创建具体工厂 A 对象
Factory* factoryB = new ConcreteFactoryB(); // 创建具体工厂 B 对象
Product* p1 = factoryA->createProduct(); // 使用具体工厂 A 创建具体产品 A 对象
Product* p2 = factoryB->createProduct(); // 使用具体工厂 B 创建具体产品 B 对象
p1->use(); // 输出:Using product A.
p2->use(); // 输出:Using product B.
delete p1;
delete p2;
delete factoryA;
delete factoryB;
return 0;
}
在上面的代码中,我们定义了一个抽象产品类(Product)和两个具体产品类(ConcreteProductA、ConcreteProductB),它们分别实现了自己的具体功能。另外,我们还定义了一个抽象工厂类(Factory)和两个具体工厂类(ConcreteFactoryA、ConcreteFactoryB),分别实现了工厂方法,用于创建不同类型的产品对象。
在主函数中,我们通过创建具体工厂对象并调用其工厂方法来创建不同类型的产品对象,并测试了它们的具体功能。
通过工厂方法模式,我们可以将对象的创建延迟到子类中进行,从而实现了开闭原则。在该模式中,每个具体工厂只能创建一种具体产品,因此可以很好地控制产品的种类和数量,并且可以很容易地增加新的产品类型。同时,由于每个具体工厂都只负责创建自己的产品,因此可以很好地保证系统的灵活性和可维护性。
与简单工厂模式相比,工厂方法模式的优点在于它更符合开闭原则,能够支持新增产品类型的扩展。但与此同时,工厂方法模式也存在一定的缺点,例如需要定义大量的类和接口,会增加代码的复杂度,同时也会增加系统的运行时开销。
1.3、抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是一种创建型设计模式,它提供了一种方式来封装一组具有相同主题的单独工厂方法。也就是说,抽象工厂模式可以用来创建一组相关或者互相依赖的对象,而不需要指定它们的具体类。
在抽象工厂模式中,我们通常会定义一个抽象工厂类,它负责定义一组工厂方法的接口。每个工厂方法都负责创建一组相互依赖的产品对象,这些产品对象必须实现一组相同的抽象产品接口。由于每个具体工厂都只负责创建自己的产品对象,因此该模式也被称为工厂的工厂模式。
抽象工厂模式包含以下角色:
- 抽象产品 A(Abstract Product A):定义了产品 A 的基本属性和方法。
- 具体产品 A1、A2等(Concrete Product A1, A2, etc.):实现了抽象产品 A 的接口,并提供了具体的实现。
- 抽象产品 B(Abstract Product B):定义了产品 B 的基本属性和方法。
- 具体产品 B1、B2等(Concrete Product B1, B2, etc.):实现了抽象产品 B 的接口,并提供了具体的实现。
- 抽象工厂(Abstract Factory):定义了一组工厂方法的接口,用于创建一组相互依赖的产品对象。
- 具体工厂 A、B等(Concrete Factory A, B, etc.):实现了抽象工厂的接口,用于创建一组相互依赖的产品对象。
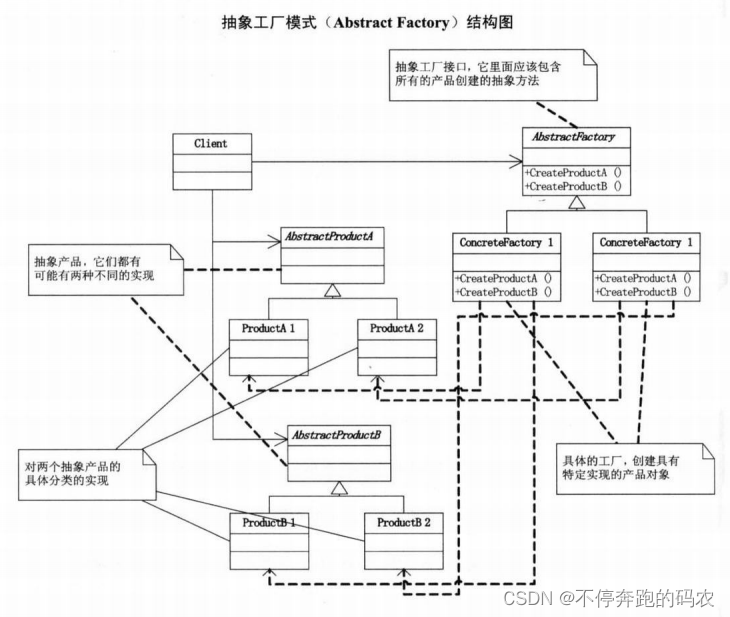
下面是一个简单的抽象工厂模式示例代码:
#include <iostream>
using namespace std;
// 抽象产品 A
class ProductA {
public:
virtual void use() = 0; // 定义了产品 A 的基本功能接口
virtual ~ProductA() {} // 声明为虚析构函数
};
// 具体产品 A1
class ConcreteProductA1 : public ProductA {
public:
void use() override { // 实现了产品 A1 的具体功能
cout << "Using product A1." << endl;
}
};
// 具体产品 A2
class ConcreteProductA2 : public ProductA {
public:
void use() override { // 实现了产品 A2 的具体功能
cout << "Using product A2." << endl;
}
};
// 抽象产品 B
class ProductB {
public:
virtual void eat() = 0; // 定义了产品 B 的基本功能接口
virtual ~ProductB() {} // 声明为虚析构函数
};
// 具体产品 B1
class ConcreteProductB1 : public ProductB {
public:
void eat() override { // 实现了产品 B1 的具体功能
cout << "Eating product B1." << endl;
}
};
// 具体产品 B2
class ConcreteProductB2 : public ProductB {
public:
void eat() override { // 实现了产品 B2 的具体功能
cout << "Eating product B2." << endl;
}
};
// 抽象工厂
class Factory {
public:
virtual ProductA* createProductA() = 0; // 工厂方法,用于创建产品 A 对象
virtual ProductB* createProductB() = 0; // 工厂方法,用于创建产品 B 对象
virtual ~Factory() {}
};
// 具体工厂 1
class ConcreteFactory1 : public Factory {
public:
ProductA* createProductA() override { // 创建具体产品 A1 对象
return new ConcreteProductA1();
}
ProductB* createProductB() override { // 创建具体产品 B1 对象
return new ConcreteProductB1();
}
};
// 具体工厂 2
class ConcreteFactory2 : public Factory {
public:
ProductA* createProductA () override { // 创建具体产品 A2 对象
return new ConcreteProductA2();
}
ProductB* createProductB() override { // 创建具体产品 B2 对象
return new ConcreteProductB2();
}
};
int main() {
Factory* factory1 = new ConcreteFactory1(); // 创建具体工厂 1 对象
Factory* factory2 = new ConcreteFactory2(); // 创建具体工厂 2 对象
ProductA* p1 = factory1->createProductA(); // 使用具体工厂 1 创建具体产品 A1 对象
ProductA* p2 = factory2->createProductA(); // 使用具体工厂 2 创建具体产品 A2 对象
ProductB* p3 = factory1->createProductB(); // 使用具体工厂 1 创建具体产品 B1 对象
ProductB* p4 = factory2->createProductB(); // 使用具体工厂 2 创建具体产品 B2 对象
p1->use(); // 输出:Using product A1.
p2->use(); // 输出:Using product A2.
p3->eat(); // 输出:Eating product B1.
p4->eat(); // 输出:Eating product B2.
delete p1;
delete p2;
delete p3;
delete p4;
delete factory1;
delete factory2;
return 0;
}
在上面的代码中,我们定义了两个抽象产品类(ProductA、ProductB)和四个具体产品类(ConcreteProductA1、ConcreteProductA2、ConcreteProductB1、ConcreteProductB2),它们实现了自己的具体功能。另外,我们还定义了一个抽象工厂类(Factory)和两个具体工厂类(ConcreteFactory1、ConcreteFactory2),分别实现了工厂方法,用于创建不同类型的产品对象。
在主函数中,我们通过创建具体工厂对象并调用其工厂方法来创建不同类型的产品对象,并测试了它们的具体功能。
通过抽象工厂模式,我们可以将一组关联的产品对象的创建封装到一个工厂中进行管理,从而提高系统的灵活性和可维护性。同时,由于每个具体工厂都只负责创建自己的产品对象,因此也能够很好地控制产品的种类和数量。
反射+抽象工厂具体事例:
反射和抽象工厂模式结合起来的例子,实现了对不同类型对象的创建和调用。
#include <iostream>
#include <map>
#include <string>
#include <typeinfo>
// 定义产品接口
class IProduct
{
public:
virtual void Show() = 0;
};
// 具体产品类1
class Product1 : public IProduct
{
public:
void Show() override
{
std::cout << "This is Product1!" << std::endl;
}
};
// 具体产品类2
class Product2 : public IProduct
{
public:
void Show() override
{
std::cout << "This is Product2!" << std::endl;
}
};
// 抽象工厂类
class Factory
{
public:
// 模板函数,根据类型T创建对应的产品对象
template<typename T>
static IProduct* CreateProduct()
{
return new T();
}
};
// 注册类,用于支持反射
class Register
{
public:
// 定义了一个函数指针类型,用于表示创建产品的函数
typedef IProduct*(*CreateFunc)();
// 将一个产品类名和对应的创建函数关联起来
static void RegisterProduct(const std::string& name, CreateFunc func)
{
GetRegistry().emplace(name, func);
}
// 根据给定的产品类名调用相应的创建函数,返回一个新的产品对象
static IProduct* CreateProduct(const std::string& name)
{
auto it = GetRegistry().find(name);
if (it != GetRegistry().end())
{
CreateFunc func = it->second;
return func();
}
return nullptr;
}
private:
// 使用静态变量存储所有已注册的产品类
static std::map<std::string, CreateFunc>& GetRegistry()
{
static std::map<std::string, CreateFunc> registry;
return registry;
}
};
// 使用宏定义实现模板函数和创建函数的自动化注册
#define REGISTER_PRODUCT(product_name, product_class) \
IProduct* Create##product_class() \
{ \
return Factory::CreateProduct<product_class>(); \
} \
const bool product_name##_registered = \
Register::RegisterProduct(#product_name, Create##product_class)
// 注册具体产品类1
REGISTER_PRODUCT(Product1, Product1);
// 注册具体产品类2
REGISTER_PRODUCT(Product2, Product2);
int main()
{
// 使用抽象工厂创建对象
IProduct* p1 = Factory::CreateProduct<Product1>();
IProduct* p2 = Factory::CreateProduct<Product2>();
p1->Show();
p2->Show();
// 使用反射创建对象
IProduct* p3 = Register::CreateProduct("Product1");
IProduct* p4 = Register::CreateProduct("Product2");
p3->Show();
p4->Show();
return 0;
}
在上述代码中,我们首先定义了一个IProduct接口,它包含一个纯虚函数Show(),用于输出产品的信息。然后,我们派生出了两个具体的产品类Product1和Product2,并分别实现了Show()函数。
接着,我们定义了一个Factory类,它包含一个模板函数CreateProduct,用于根据类型T创建对应的产品对象。
为了支持反射,我们还定义了一个Register类,其中包含两个静态函数:RegisterProduct和CreateProduct。RegisterProduct函数用于将一个产品类名和对应的创建函数关联起来;CreateProduct函数根据给定的产品类名调用相应的创建函数,返回一个新的产品对象。
最后,在使用抽象工厂创建对象和使用反射创建对象的两种情况下,我们都可以通过调用Show()函数来输出产品的信息。
需要注意的是,在使用反射时,我们需要在每个产品类外面使用宏定义注册该产品类,例如REGISTER_PRODUCT(Product1, Product1)将Product1类注册为名字为"Product1"的产品。这里我们使用了模板函数和宏定义来消除了冗长的注册代码,使得代码更加简洁易读。
1.4、原型模式
原型模式是一种创建型设计模式,它提供了一种创建对象的方式,可以通过复制一个已有对象来创建新的对象,而无需知道具体的创建细节。该模式通过克隆(Clone)来实现对象的复制,克隆出来的对象与原始对象具有相同的属性和行为,但是它们是不同的对象,拥有自己的内存空间。
在 C++ 中,原型模式通常通过实现一个 Clone() 方法来克隆对象。这个方法可以在派生类中进行自定义实现,以便为新对象复制特定的属性或行为。
原型模式中涉及的主要成员有:
- 抽象原型类(Abstract Prototype Class):定义了克隆方法 Clone(),用于复制对象。
- 具体原型类(Concrete Prototype Class):实现了抽象原型类的克隆方法,可以复制自己。
- 原型工厂类(Prototype Factory Class):包含一个指向抽象原型类的指针,用于创建新的对象。
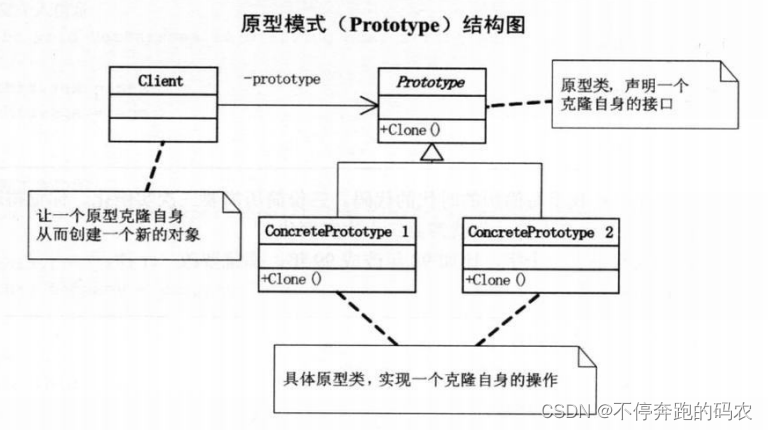
下面是一个基于原型模式的示例,假设我们有一个基础类 IFruit,它包含了最基本的行为 GetName() 和 GetColor()。然后我们定义了两个具体类 Apple 和 Banana,它们分别实现了 IFruit 的接口,并提供了默认的行为。接着,我们引入了一个原型工厂类 PrototypeFactory,它包含了一个指向 IFruit 对象的指针,可以返回一个克隆对象。最后,我们使用原型工厂类来创建新的对象,而无需知道其具体的创建细节:
#include <iostream>
#include <string>
// 基础类
class IFruit
{
public:
virtual std::string GetName() const = 0;
virtual std::string GetColor() const = 0;
virtual void SetColor(const std::string& color) = 0;
virtual IFruit* Clone() const = 0;
virtual ~IFruit(){}
};
// 具体类1:苹果
class Apple : public IFruit
{
private:
std::string m_color;
public:
std::string GetName() const override
{
return "Apple";
}
std::string GetColor() const override
{
return m_color;
}
void SetColor(const std::string& color) override
{
m_color = color;
}
IFruit* Clone() const override
{
return new Apple(*this);
}
};
// 具体类2:香蕉
class Banana : public IFruit
{
private:
std::string m_color;
public:
std::string GetName() const override
{
return "Banana";
}
std::string GetColor() const override
{
return m_color;
}
void SetColor(const std::string& color) override
{
m_color = color;
}
IFruit* Clone() const override
{
return new Banana(*this);
}
};
// 原型工厂类
class PrototypeFactory
{
private:
IFruit* m_prototype;
public:
PrototypeFactory(IFruit* prototype)
: m_prototype(prototype)
{}
IFruit* CreateFruit()
{
return m_prototype->Clone();
}
};
int main()
{
// 创建一个苹果原型
IFruit* applePrototype = new Apple();
// 使用原型工厂创建一个新的苹果对象
PrototypeFactory factory1(applePrototype);
IFruit* apple1 = factory1.CreateFruit();
// 修改原型的颜色属性
Apple* applePrototype2 = dynamic_cast<Apple*>(applePrototype);
applePrototype2->SetColor("Green");
// 使用原型工厂创建另一个新的苹果对象
PrototypeFactory factory2(applePrototype);
IFruit* apple2 = factory2.CreateFruit();
std::cout << apple1->GetName() << " (" << apple1->GetColor() << ")" << std::endl; // Apple ()
std::cout << apple2->GetName() << " (" << apple2->GetColor() << ")" << std::endl; // Apple (Green)
delete apple1;
delete apple2;
delete applePrototype;
return 0;
}
在这个示例中,我们首先定义了一个基础类 IFruit,然后定义了两个具体类 Apple 和 Banana,它们分别实现了 IFruit 的接口,并提供了默认的行为。接着,我们定义了一个原型工厂类 PrototypeFactory,它包含了一个指向 IFruit 对象的指针,并实现了一个 CreateFruit() 方法来返回一个克隆对象。最后,我们使用原型工厂类来创建新的对象,而不是直接调用构造函数。
4.1.5、单例模式
单例模式是一种创建型设计模式,它可以确保一个类在任何情况下都只有一个实例,并提供了一个全局访问该实例的接口。通常我们可以让一个全局变量使得一个对象被访问,但它不能防止你实例化多个对象。一个最好的办法就是,让类自身负责保存它的唯一实例。这个类可以保证没有其他实例可以被创建,并且它可以提供一个访问该实例的方法。
单例模式通常需要保证以下几点:
- 确保只有一个实例。这意味着需要控制对象的创建和销毁,以及限制对象的数量。
- 提供全局访问点。这意味着需要提供一个静态方法或者变量来获取类的实例。
- 被多线程环境下正确地处理。这意味着需要考虑线程安全问题,避免多个线程同时访问或修改同一个实例。

以下是一个简单的 C++ 示例代码:
#include <iostream>
using namespace std;
class Singleton {
public:
static Singleton* getInstance() {
static Singleton instance;
return &instance;
}
private:
Singleton() {} // 私有构造函数,禁止外部创建对象
Singleton(const Singleton& other); // 禁止拷贝构造函数
Singleton& operator=(const Singleton& other); // 禁止赋值运算符
};
int main() {
// 客户端调用
Singleton* instance1 = Singleton::getInstance();
Singleton* instance2 = Singleton::getInstance();
std::cout << (instance1 == instance2) << std::endl; // 输出 true
return 0;
}
在这个示例中,Singleton 是单例类,它只能被创建一次。我们使用了一个静态的 getInstance 函数来获取该单例对象。在函数中,我们使用了一个静态局部变量 instance 来确保只有一个实例,并返回它的地址给调用者。
由于构造函数、拷贝构造函数和赋值运算符都是私有的,因此无法从外部创建新的对象,只能通过 getInstance 函数获取单例对象。
最后,在客户端代码中,我们分别调用两次 getInstance 函数得到不同的指针,然后比较它们是否相等。结果会输出 true,说明两个指针指向的是同一个对象。
单例模式的优势在于可以确保一个类在任何情况下都只有一个实例并提供全局访问点,避免了重复创建对象和浪费内存空间。同时也可以提高代码的复用性和扩展性。
C++中的单例模式可以分为两种:饿汉式单例和懒汉式单例。
饿汉式单例
饿汉式单例指的是在程序启动时就实例化一个唯一的对象,即在调用该类任何方法前就已经创建了该类的唯一实例。这样可以确保线程安全,因为在多线程环境下只有一个线程能够创建该实例。一般情况下,饿汉式单例的代码如下:
#include <iostream>
#include <memory>
#include <mutex>
using namespace std;
// 饿汉式单例
class EagerSingleton {
public:
static EagerSingleton& getInstance() {
static EagerSingleton instance; // 在程序启动时就创建唯一实例
return instance;
}
void showMessage() const {
cout << "Hello, I am an eager singleton." << endl;
}
private:
EagerSingleton() {} // 私有构造函数,防止外部创建对象
~EagerSingleton() {}
EagerSingleton(const EagerSingleton& other) = delete; // 禁用拷贝构造函数
EagerSingleton& operator=(const EagerSingleton& other) = delete; // 禁用赋值运算符
};
int main() {
EagerSingleton& eager1 = EagerSingleton::getInstance();
EagerSingleton& eager2 = EagerSingleton::getInstance();
if (&eager1 == &eager2) {
cout << "EagerSingleton works." << endl;
}
return 0;
}
在上面的代码中,getInstance()是获取唯一实例的静态方法,它会在首次调用时创建Singleton的唯一实例。由于静态局部变量在程序启动时就完成初始化,因此该方法可以保证线程安全。
懒汉式单例
懒汉式单例指的是在需要时才创建实例,也就是说,直到第一次调用getInstance()方法时才会创建实例。这种方式虽然节约了资源,但需要考虑线程安全问题,因为如果多个线程同时调用getInstance()方法,可能会创建多个实例。又会面临着多线程访问的安全性问题,需要做双重锁定才可以保证安全。一般情况下,懒汉式单例的代码如下:
#include <iostream>
#include <memory>
#include <mutex>
using namespace std;
// 懒汉式单例
class LazySingleton {
public:
static LazySingleton& getInstance() {
std::call_once(flag, []() { instance.reset(new LazySingleton); }); // 在第一次调用时创建唯一实例,并保证线程安全
return *instance;
}
void showMessage() const {
cout << "Hello, I am a lazy singleton." << endl;
}
~LazySingleton() {}
private:
LazySingleton() {} // 私有构造函数,防止外部创建对象
LazySingleton(const LazySingleton& other) = delete; // 禁用拷贝构造函数
LazySingleton& operator=(const LazySingleton& other) = delete; // 禁用赋值运算符
static std::unique_ptr<LazySingleton> instance; // 唯一实例指针
static std::once_flag flag; // 标记,用于保证线程安全
};
std::unique_ptr<LazySingleton> LazySingleton::instance = nullptr;
std::once_flag LazySingleton::flag;
int main() {
LazySingleton& lazy1 = LazySingleton::getInstance();
LazySingleton& lazy2 = LazySingleton::getInstance();
if (&lazy1 == &lazy2) {
cout << "LazySingleton works." << endl;
}
return 0;
}
在上面的代码中,我们使用了std::call_once和std::once_flag来保证线程安全,这是C++11引入的一种线程安全的单例模式实现方式。std::call_once函数可以保证给定的函数只被执行一次,即使多个线程同时调用该函数。std::once_flag则是一个标记,用于确保函数只被调用一次。
总之,饿汉式单例在启动时就创建唯一实例,能够保证线程安全,但可能浪费资源;懒汉式单例在需要时才创建实例,节约了资源,但需要考虑线程安全问题。
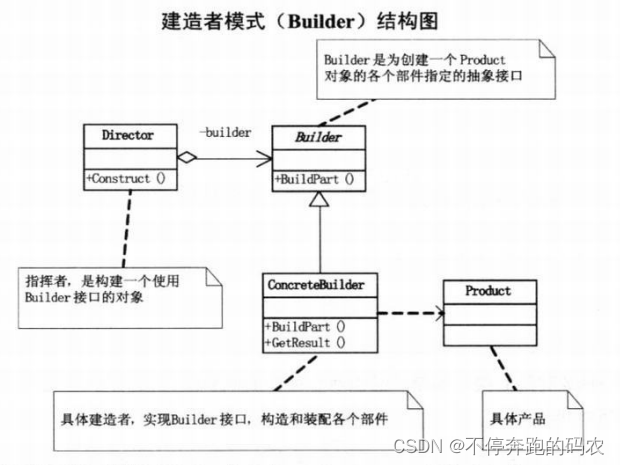
1.6、建造者模式
建造者模式是一种创建型设计模式,它允许你在不暴露对象创建逻辑的情况下,自主生成复杂对象。
建造者模式包含如下角色:
- 产品类(Product):定义要创建的对象。
- 抽象建造者类(Builder):定义抽象接口以构造产品的各个部分。
- 具体建造者类(Concrete Builder):实现抽象建造者接口,提供构造过程的具体实现,并返回最终的产品。
- 指挥者类(Director):控制建造过程,构建最终的产品。
优点:建造者模式的好处就是使得建造代码与表示代码分离,由于建造者隐藏了该产品是如何组装的,所以若需要改变一个产品的内部表示,只需要再定义一个具体的建造者就可以了。
以下是一个简单的例子,假设我们正在开发一款游戏,需要创建一个角色类(Player)。角色类有多个属性,包括名字、等级、经验值、装备等。使用建造者模式来创建该对象可以让我们在不同场景下创建出不同的角色,而且可以很方便地添加新属性。
//首先,我们定义角色类:
class Player {
public:
void setName(const std::string& name) { m_name = name; }
void setLevel(int level) { m_level = level; }
void setExperience(int experience) { m_experience = experience; }
void setEquipment(const std::vector<std::string>& equipment) { m_equipment = equipment; }
void printInfo() const {
std::cout << "Name: " << m_name << std::endl;
std::cout << "Level: " << m_level << std::endl;
std::cout << "Experience: " << m_experience << std::endl;
std::cout << "Equipment: ";
for (const auto& e : m_equipment) {
std::cout << e << ", ";
}
std::cout << std::endl;
}
private:
std::string m_name;
int m_level;
int m_experience;
std::vector<std::string> m_equipment;
};
//然后,我们定义抽象建造者类:
class PlayerBuilder {
public:
virtual void buildName() = 0;
virtual void buildLevel() = 0;
virtual void buildExperience() = 0;
virtual void buildEquipment() = 0;
virtual Player* getPlayer() = 0;
};
//接着,我们创建具体建造者类:
class WarriorBuilder : public PlayerBuilder {
public:
WarriorBuilder() { m_player = new Player; }
void buildName() override { m_player->setName("Warrior"); }
void buildLevel() override { m_player->setLevel(1); }
void buildExperience() override { m_player->setExperience(0); }
void buildEquipment() override {
m_player->setEquipment({"Sword", "Shield"});
}
Player* getPlayer() override { return m_player; }
private:
Player* m_player;
};
class MageBuilder : public PlayerBuilder {
public:
MageBuilder() { m_player = new Player; }
void buildName() override { m_player->setName("Mage"); }
void buildLevel() override { m_player->setLevel(1); }
void buildExperience() override { m_player->setExperience(0); }
void buildEquipment() override {
m_player->setEquipment({"Staff", "Robe"});
}
Player* getPlayer() override { return m_player; }
private:
Player* m_player;
};
//最后,我们创建指挥者类:
class Director {
public:
void createWarrior(PlayerBuilder* builder) {
builder->buildName();
builder->buildLevel();
builder->buildExperience();
builder->buildEquipment();
}
void createMage(PlayerBuilder* builder) {
builder->buildName();
builder->buildLevel();
builder->buildExperience();
builder->buildEquipment();
}
};
//现在,我们可以通过使用具体建造者类来构建不同的角色对象。以创建一个战士和一个法师为例:
int main() {
Director director;
WarriorBuilder warriorBuilder;
MageBuilder mageBuilder;
// 构建战士
director.createWarrior(&warriorBuilder);
Player* warrior = warriorBuilder.getPlayer();
warrior->printInfo();
// 构建法师
director.createMage(&mageBuilder);
Player* mage = mageBuilder.getPlayer();
mage->printInfo();
delete warrior;
delete mage;
return 0;
}
输出如下:
Name: Warrior
Level: 1
Experience: 0
Equipment: Sword, Shield,
Name: Mage
Level: 1
Experience: 0
Equipment: Staff, Robe,
由此可见,使用建造者模式可以轻松地创建出各种属性不同的角色,并且添加新属性也非常方便。
2、结构型模式
2.1、装饰器模式
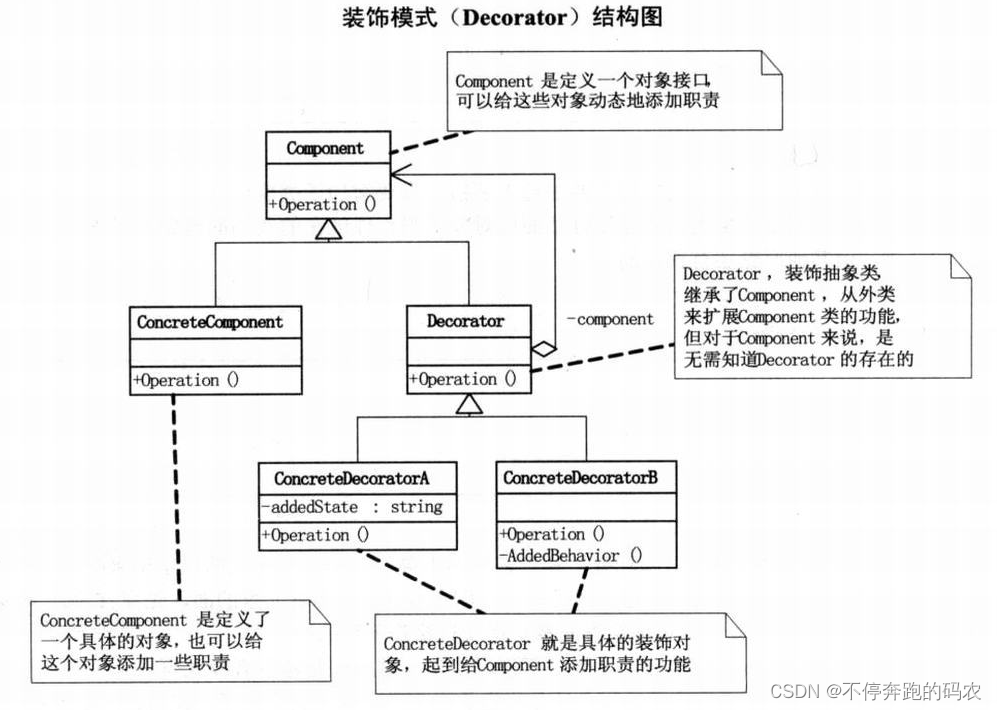
装饰器模式是一种结构型设计模式,它允许在运行时动态地添加行为或功能到一个对象中,而无需影响其他对象。该模式能够在不修改现有代码的情况下增加新的功能,且可以通过组合多个装饰器来创建更复杂的行为。
在装饰器模式中,我们定义了一个基础类(也称为“抽象组件”),它包含了最基本的行为。然后,我们定义了一个或多个继承自基础类的具体类(也称为“具体组件”),它们实现了基础类的接口,并提供了一些默认的行为。
接着,我们定义了一个装饰器类(也称为“抽象装饰器”),它同样继承自基础类,并包含了一个指向基础类对象的指针(即“被装饰者”)。装饰器类还定义了一些额外的行为,例如:增加、删除或修改原始行为。
最后,我们定义了一个或多个继承自装饰器类的具体装饰器类,它们同样包含了一个指向基础类对象的指针,并实现了额外的行为。这些具体装饰器类可以通过组合多个装饰器来实现更复杂的行为。
以下是一个简单的 C++ 示例代码:
// 抽象组件类
class Component {
public:
virtual void operation() = 0;
};
// 具体组件类
class ConcreteComponent : public Component {
public:
void operation() override {
std::cout << "执行具体组件" << std::endl;
}
};
// 抽象装饰类
class Decorator : public Component {
public:
Decorator(Component* component) : m_component(component) {}
void operation() override {
if (m_component != nullptr) {
m_component->operation();
}
}
protected:
Component* m_component;
};
// 具体装饰类之一
class ConcreteDecoratorA : public Decorator {
public:
ConcreteDecoratorA(Component* component) : Decorator(component) {}
void operation() override {
addBehaviorA();
Decorator::operation();
}
private:
void addBehaviorA() {
std::cout << "为具体组件添加行为 A" << std::endl;
}
};
// 具体装饰类之二
class ConcreteDecoratorB : public Decorator {
public:
ConcreteDecoratorB(Component* component) : Decorator(component) {}
void operation() override {
addBehaviorB();
Decorator::operation();
}
private:
void addBehaviorB() {
std::cout << "为具体组件添加行为 B" << std::endl;
}
};
int main() {
// 客户端调用
Component* component = new ConcreteComponent();
Component* decoratorA = new ConcreteDecoratorA(component);
Component* decoratorB = new ConcreteDecoratorB(decoratorA);
decoratorB->operation();
delete decoratorB;
delete decoratorA;
delete component;
return 0;
}
在这个示例中,Component 是抽象组件类,它定义了所有可能被增强的对象的共性。然后我们定义了一个具体组件类 ConcreteComponent,该类实现了 Component 接口。
接下来,我们定义了一个抽象装饰类 Decorator,该类继承自 Component 类,并持有一个指向 Component 对象的指针,用于将其包装起来。Decorator 类中的 operation 函数会调用包装器持有的原有对象的 operation 函数。
然后,我们定义了两个具体装饰类:ConcreteDecoratorA 和 ConcreteDecoratorB,它们都继承自 Decorator 类,并分别实现了各自的增强行为函数,并在 operation 函数中调用增强函数。
最后,我们在客户端代码中创建一个 ConcreteComponent 对象作为被装饰对象,然后分别创建两个具体装饰类的对象 decoratorA 和 decoratorB,将其包装起来。最后调用链式结构中最后一个对象的 operation 函数即可完成被多次增强的操作。
装饰器模式的优势在于可以动态地添加或者移除对象的功能,避免了对原有代码进行修改或重构。同时也可以提高代码的复用性和灵活性。
2.2、外观模式
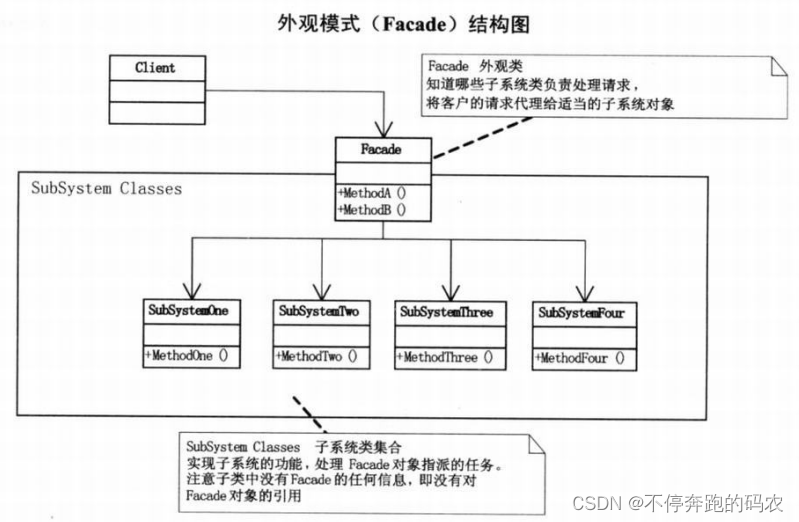
C++外观模式是一种结构型设计模式,它为客户端提供一个简单的界面,隐藏了系统的复杂性,并且将客户端与系统内部的组件解耦。
在外观模式中,我们使用一个外观(Facade)对象作为客户端与系统内部组件的中间人,客户端只需要通过外观对象调用相应的方法,而无需直接与系统内部组件交互。外观对象负责将请求分发给各个子系统,并对返回结果进行处理和封装,使得客户端可以更加方便地使用系统功能。
以下是一个C++外观模式的示例代码:
#include <iostream>
using namespace std;
// 子系统A
class SubsystemA {
public:
void operationA() {
cout << "Subsystem A operation." << endl;
}
};
// 子系统B
class SubsystemB {
public:
void operationB() {
cout << "Subsystem B operation." << endl;
}
};
// 外观类
class Facade {
private:
SubsystemA subsystemA;
SubsystemB subsystemB;
public:
void operation() {
subsystemA.operationA();
subsystemB.operationB();
}
};
int main() {
// 创建外观对象并调用操作
Facade facade;
facade.operation();
return 0;
}
在上述代码中,SubsystemA和SubsystemB表示两个不同的子系统组件,每个组件都有自己的实现方式和接口。Facade类作为外观对象,它封装了SubsystemA和SubsystemB的实现细节,并且提供了一个简单的操作接口operation()来调用这两个子系统。
在main函数中,我们创建了一个Facade对象并调用了operation()方法。此时,Facade对象会将请求分发给SubsystemA和SubsystemB,并对返回结果进行处理和封装,最终输出相应的操作信息。
总之,C++外观模式可以帮助我们简化复杂系统的使用方式,提高系统的可维护性和可扩展性。同时,它还可以将客户端与系统内部组件解耦,降低代码的耦合度和复杂度,增加系统的灵活性和可重用性。
2.3、代理模式
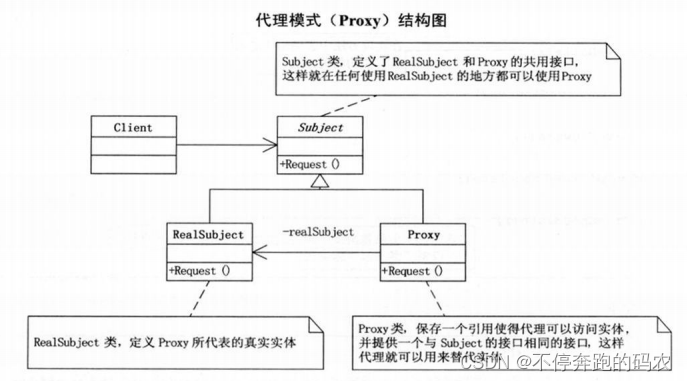
代理模式是一种结构型设计模式,它提供了一种代理类来控制对另一个对象的访问。在某些情况下,客户端不能或不想直接引用一个对象,而是通过使用一个代理对象来间接访问该对象。
代理模式中有三个角色:抽象主题类(Subject)、具体主题类(RealSubject)和代理类(Proxy)。
以下是一个简单的 C++ 示例代码:
#include <iostream>
// 抽象主题类
class Subject {
public:
virtual ~Subject() {}
virtual void doSomething() = 0;
};
// 具体主题类
class RealSubject : public Subject {
public:
void doSomething() override {
std::cout << "真实主题执行操作" << std::endl;
}
};
// 代理类
class Proxy : public Subject {
public:
Proxy(Subject* subject) : m_subject(subject) {}
~Proxy() {
delete m_subject;
}
void doSomething() override {
std::cout << "代理类执行操作之前" << std::endl;
m_subject->doSomething();
std::cout << "代理类执行操作之后" << std::endl;
}
private:
Subject* m_subject;
};
int main() {
// 客户端调用
Subject* realSubject = new RealSubject();
Proxy* proxy = new Proxy(realSubject);
proxy->doSomething();
delete proxy;
return 0;
}
在这个示例中,Subject 是抽象主题类,它定义了 doSomething 方法。其中 doSomething 方法是主题类真正执行的操作。
然后我们定义了一个具体主题类 RealSubject,它实现了 Subject 接口,并且持有一个 Proxy 对象的引用。
接下来,我们定义了一个代理类 Proxy,它同样也实现了 Subject 接口,并且持有一个 Subject 对象的引用。在代理类中,它通过调用持有的主题对象的方法来完成实际的操作,并且也可以在方法调用前后进行一些其他的操作。
最后,在客户端代码中,我们创建了一个具体主题对象和一个代理对象,并且将具体主题对象传递给了代理对象。最终通过代理对象调用 doSomething() 方法来执行操作。
代理模式的优势在于可以提供额外的控制,例如在实际对象执行前后加入一些其他操作等。并且还可以实现远程代理、虚拟代理等不同的变种形式,以满足不同的需求。但是代理模式也可能会增加系统的复杂度,所以需要根据具体情况来选择使用。
2.4、适配器模式
适配器模式是一种结构型设计模式,它将不兼容的接口转换为客户端所期望的接口。该模式的主要目的是使得原本由于接口不兼容而不能一起工作的类可以在一起工作。
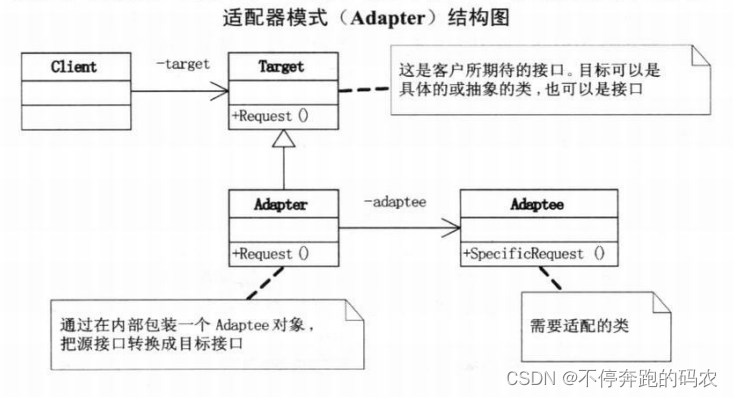
适配器模式中包含三个主要角色:
- 目标(Target):定义客户端需要的特定接口。
- 源(Adaptee):定义需要被适配的不同接口的对象。
- 适配器(Adapter):通过实现目标接口并包装源对象,将不兼容的接口转换为客户端所期望的接口。
使用场景:在系统的数据和行为都正确,但接口不符时,我们应该考虑用适配器,目的是使控制范围之外的一个原有对象与某个接口匹配;适配器模式主要应用于希望复用一些现存的类,但是接口又与复用环境要求不一致的情况,比如在需要对早期代码复用一些功能等应用上很有实际价值。
适配器模式可以分为两种类型: 类适配器和对象适配器。
- 类适配器采用多重继承方式,同时继承目标类和源类,并且重写目标类的方法,将源类的方法进行转换。但是,这种方式只能对单一源类进行适配。
- 对象适配器则不同于类适配器,它采用组合方式,将源类的对象作为成员变量嵌入到适配器中,然后实现目标接口,将目标接口方法转换为源类的对象的方法调用。
以下是一个C++对象适配器模式的示例代码:
#include <iostream>
using namespace std;
// 目标接口
class Target {
public:
virtual void request() = 0;
};
// 源接口
class Adaptee {
public:
void specificRequest() {
cout << "Adaptee specific request." << endl;
}
};
// 适配器
class Adapter : public Target {
private:
Adaptee *adaptee;
public:
Adapter(Adaptee *a) {
adaptee = a;
}
void request() {
adaptee->specificRequest();
}
};
int main() {
// 创建源对象和适配器对象
Adaptee *adaptee = new Adaptee();
Target *target = new Adapter(adaptee);
// 调用目标接口方法
target->request();
return 0;
}
在上述代码中,Target表示客户端所期望的特定接口,Adaptee表示需要被适配的不同接口的对象,Adapter则是适配器,通过实现目标接口并包装源对象,将不兼容的接口转换为客户端所期望的接口。
在main函数中,我们创建了一个Adaptee对象和一个Adapter对象,然后将Adaptee对象传入Adapter对象中进行适配。最后,调用Adapter对象的目标接口方法request()来执行相应的操作。
适配器模式可以帮助我们解决系统中不同接口之间的兼容性问题,提高代码的可重用性和可维护性。同时,它还可以降低代码的耦合度和复杂度,增加系统的灵活性和扩展性。
2.5、组合模式
组合模式是一种结构型设计模式。它允许你将对象组合成树形结构来表示“部分-整体”的层次结构,使得用户可以统一处理单个对象和组合对象。
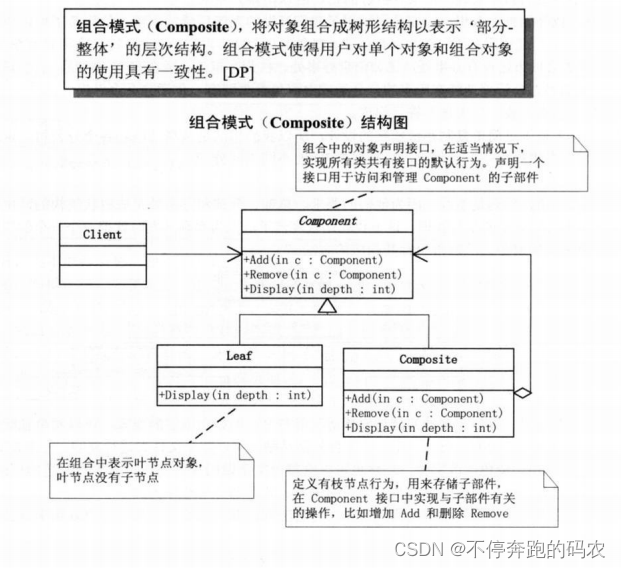
组合模式有以下几个角色:
- 抽象构件(Component):所有组合对象和单个对象的共同接口。
- 叶子节点(Leaf):不包含任何子节点的叶子对象,实现抽象构件接口。
- 组合节点(Composite):包含一个或多个子节点的对象,实现抽象构件接口,并提供管理子节点的操作。
- 客户端(Client):通过抽象构件接口操作组合对象或单个对象。
使用组合模式可以带来以下优点:
- 简化客户端代码:客户端无需知道是处理单个对象还是组合对象,只需要操作抽象构件接口即可。
- 增加新的构件容易:如果需要增加新的叶子对象或组合对象,只需要实现抽象构件接口即可。
- 可以更方便的执行深度遍历:由于组成树状结构,因此可以很方便的执行深度优先遍历和广度优先遍历等操作。
使用场景:需求中是体现部分与整体层次的结构时,以及希望用户可以忽略组合对象与单个对象的不同,统一地使用组合结构中的所有对象时,就应该考虑使用组合模式了。
下面是一个组合模式的示例,假设我们要设计一个文件系统的类,其中包含文件夹和文件两种类型的对象。我们可以使用组合模式来描述这种层次结构。
#include <iostream>
#include <vector>
#include <algorithm>
// 定义抽象基类Shape
class Shape
{
public:
virtual void Draw() = 0;
};
// 定义具体图形类Rectangle、Circle和Line,它们继承自Shape类
class Rectangle : public Shape
{
public:
void Draw() override
{
// 实现矩形的绘制操作
std::cout << "Drawing a rectangle." << std::endl;
}
};
class Circle : public Shape
{
public:
void Draw() override
{
// 实现圆形的绘制操作
std::cout << "Drawing a circle." << std::endl;
}
};
class Line : public Shape
{
public:
void Draw() override
{
// 实现直线的绘制操作
std::cout << "Drawing a line." << std::endl;
}
};
// 定义容器类Composite,用于存储所有子节点的指针,并实现了Shape接口中的Draw方法
class Composite : public Shape
{
public:
void Add(Shape* shape)
{
// 向容器中添加子节点
m_shapes.push_back(shape);
}
void Remove(Shape* shape)
{
// 从容器中删除指定子节点
auto it = std::find(m_shapes.begin(), m_shapes.end(), shape);
if (it != m_shapes.end())
{
m_shapes.erase(it);
}
}
void Draw() override
{
for (auto shape : m_shapes)
{
// 逐个调用子节点的Draw方法
shape->Draw();
}
}
private:
std::vector<Shape*> m_shapes; // 存储所有子节点的指针
};
int main()
{
// 创建具体图形对象
Rectangle* rect1 = new Rectangle();
Rectangle* rect2 = new Rectangle();
Circle* circle1 = new Circle();
Line* line1 = new Line();
// 创建容器对象,并将其作为父节点
Composite* composite = new Composite();
composite->Add(rect1);
composite->Add(rect2);
// 创建另一个容器对象,并将其作为父节点的子节点
Composite* subComposite = new Composite();
subComposite->Add(circle1);
subComposite->Add(line1);
// 将子容器添加到父容器中并进行绘制
composite->Add(subComposite);
composite->Draw();
// 释放资源(先递归地删除子节点,然后再删除父节点)
delete rect1;
delete rect2;
delete circle1;
delete line1;
delete subComposite;
delete composite;
return 0;
}
在上面的示例代码中,我们首先创建了三个具体的图形对象,然后使用组合模式将它们组成了一个复杂的图形。最后,通过调用Composite对象的Draw方法,可以对整个图形进行绘制。
需要注意的是,在释放所有创建的对象之前,应该先递归地删除所有子节点,然后再删除父节点。这是因为父节点持有其子节点的指针,如果不先删除子节点,就会导致内存泄漏。
在组合模式中,对于叶子节点和容器节点,由于它们都实现了相同的接口方法,所以用户可以完全忽略对象类型的差异,直接操作整个树形结构。同时,组合模式也使得我们可以方便地添加或删除节点,无需对客户端代码做任何修改。
总之,组合模式是一种非常有用的设计模式,它可以将复杂的对象组织成树形结构,以便于管理和操作,并且能够提高代码的复用性和可扩展性。
透明模式和安全模式
透明模式和安全模式是组合模式(Composite Pattern)中两种常见的实现方式。
组合模式是一种结构型设计模式,它允许你将对象组合成树形结构来表示“部分-整体”的层次结构。组合模式使得客户端可以统一处理单个对象和组合对象,从而简化了代码并提高了扩展性。
接下来,我们将介绍透明模式和安全模式的定义、优缺点以及使用场景。
透明模式
在透明模式中,抽象构件类(Component)中声明了所有的管理子对象的方法,包括添加(add)、删除(remove)、获取子节点(getChild)、以及遍历子节点(display),这些方法都对叶子节点和容器节点都可用。
class Component {
public:
virtual void add(Component* c) {}
virtual void remove(Component* c) {}
virtual Component* getChild(int index) { return nullptr; }
virtual void display() {}
};
叶子节点(Leaf)和容器节点(Composite)都继承自抽象构件类,但是叶子节点不能包含任何子节点,因此它们的add、remove和getChild方法不需要实现,而且在调用这些方法时会抛出异常或不做任何操作。
class Leaf : public Component {
public:
void display() override { cout << "Leaf" << endl; }
};
class Composite : public Component {
public:
void add(Component* c) override { children.push_back(c); }
void remove(Component* c) override { children.remove(c); }
Component* getChild(int index) override { return children[index]; }
void display() override {
cout << "Composite" << endl;
for (auto c : children) {
c->display();
}
}
private:
list<Component*> children;
};
透明模式的优点是,客户端可以使用相同的方式处理叶子节点和容器节点。但是,由于所有方法都在抽象构件类中声明,因此容器节点不得不将一些方法传递给它的子节点,这可能会导致代码的复杂性和不必要的开销。
安全模式
在安全模式中,抽象构件类(Component)只声明了管理叶子节点的方法,而将管理容器节点的方法放到容器类(Composite)中实现。容器类中包含一个子节点列表,用来存储该容器节点包含的子节点。
class Component {
public:
virtual void display() {}
};
class Leaf : public Component {
public:
void display() override { cout << "Leaf" << endl; }
};
class Composite : public Component {
public:
void add(Component* c) { children.push_back(c); }
void remove(Component* c) { children.remove(c); }
Component* getChild(int index) { return children[index]; }
void display() override {
cout << "Composite" << endl;
for (auto c : children) {
c->display();
}
}
private:
list<Component*> children;
};
在安全模式中,叶子节点和容器节点的方法完全独立,客户端需要分别处理它们。这样可以避免容器节点将一些方法传递给它的子节点,从而简化了代码并提高了性能。
使用场景
透明模式和安全模式都是组合模式的实现方式,具体使用哪种方式取决于你的需求。
如果你的系统中容器和叶子节点的行为非常相似,并且希望客户端以相同的方式来处理它们,那么透明模式可能更适合你。
如果你的系统中容器和叶子节点的行为差异很大,或者你想要减少容器节点的开销,那么安全模式可能更适合正确的选择。
组合模式通常用于处理树形结构,例如文件系统、GUI界面等。在这些场景中,通常存在复杂的部分-整体关系,而组合模式可以将这些部分和整体统一抽象成一个共同的类层次结构。
例如,在文件系统中,文件夹和文件都是文件系统的一部分,但是它们的行为差异很大,因此我们可以使用组合模式来实现它们的结构和行为。文件夹可以包含许多文件和文件夹,而文件只能包含数据内容。客户端可以直接访问文件和文件夹,而无需知道其内部结构,这使得代码更加简化并提高了扩展性。
综上所述,透明模式和安全模式都有各自的优缺点和使用场景,你需要根据具体情况进行选择。
2.6、桥接模式
桥接模式(Bridge Pattern)是一种结构型设计模式,它将抽象部分和实现部分分离开来,使它们可以独立地变化。这种模式通过使用一个桥接接口,使得抽象部分和实现部分可以在运行时进行组合,从而达到最大的灵活性。
简单来说,桥接模式通过将抽象部分与实现部分分离,把复杂度降低到两个独立的层次中,从而使得整个系统更加清晰、易于扩展和维护。
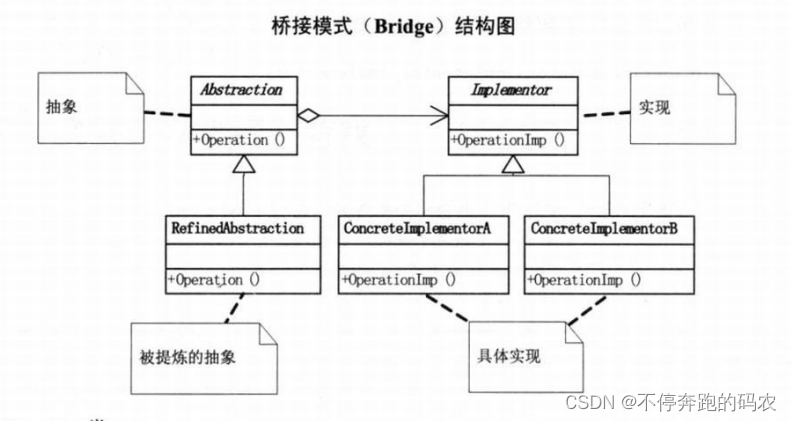
桥接模式包含以下角色:
- 抽象部分(Abstraction):定义了抽象部分的接口,并维护一个指向实现部分的引用。
- 实现部分(Implementor):定义了实现部分的接口,该接口不需要与抽象部分完全一致。
- 具体抽象部分(ConcreteAbstraction):继承自抽象部分,实现抽象部分的接口,并调用实现部分的相关方法。
- 具体实现部分(ConcreteImplementor):继承自实现部分,实现实现部分的接口。
下面是一个简单的桥接模式示例代码:
#include <iostream>
using namespace std;
// 实现部分
class Implementor {
public:
virtual void operationImpl() = 0; // 声明实现部分的操作接口
};
class ConcreteImplementorA : public Implementor { // 具体实现部分 A
public:
void operationImpl() override { // 实现具体的操作
cout << "ConcreteImplementorA::operationImpl" << endl;
}
};
class ConcreteImplementorB : public Implementor { // 具体实现部分 B
public:
void operationImpl() override { // 实现具体的操作
cout << "ConcreteImplementorB::operationImpl" << endl;
}
};
// 抽象部分
class Abstraction {
public:
Abstraction(Implementor* impl) : m_impl(impl) {} // 构造函数,接收一个实现部分对象
virtual void operation() = 0; // 声明抽象部分的操作接口
protected:
Implementor* m_impl; // 维护一个实现部分对象的引用
};
class ConcreteAbstraction : public Abstraction { // 具体抽象部分
public:
ConcreteAbstraction(Implementor* impl) : Abstraction(impl) {} // 调用基类构造函数,传入实现部分对象
void operation() override { // 实现抽象部分的操作接口
m_impl->operationImpl(); // 调用实现部分的操作接口
}
};
int main() {
Implementor* implA = new ConcreteImplementorA(); // 创建具体实现部分 A 对象
Implementor* implB = new ConcreteImplementorB(); // 创建具体实现部分 B 对象
Abstraction* abs1 = new ConcreteAbstraction(implA); // 创建具体抽象部分对象,传入实现部分 A
Abstraction* abs2 = new ConcreteAbstraction(implB); // 创建具体抽象部分对象,传入实现部分 B
abs1->operation(); // 输出:ConcreteImplementorA::operationImpl
abs2->operation(); // 输出:ConcreteImplementorB::operationImpl
delete abs1;
delete abs2;
delete implA;
delete implB;
return 0;
}
在上面的代码中,我们定义了一个实现部分(Implementor)和两个具体实现部分(ConcreteImplementorA、ConcreteImplementorB),它们负责提供不同的实现。
我们还定义了一个抽象部分(Abstraction)和一个具体抽象部分(ConcreteAbstraction),抽象部分维护了一个指向实现部分的引用,并提供了一个操作接口。具体抽象部分继承自抽象部分,实现了抽象部分的接口,并调用实现部分的相关方法。
在主函数中,我们创建了不同的具体实现部分和具体抽象部分,并测试了它们的运行效果。通过桥接模式,我们可以灵活地组合不同的抽象部分和实现部分,从而实现更高层次的功能。
2.7、享元模式
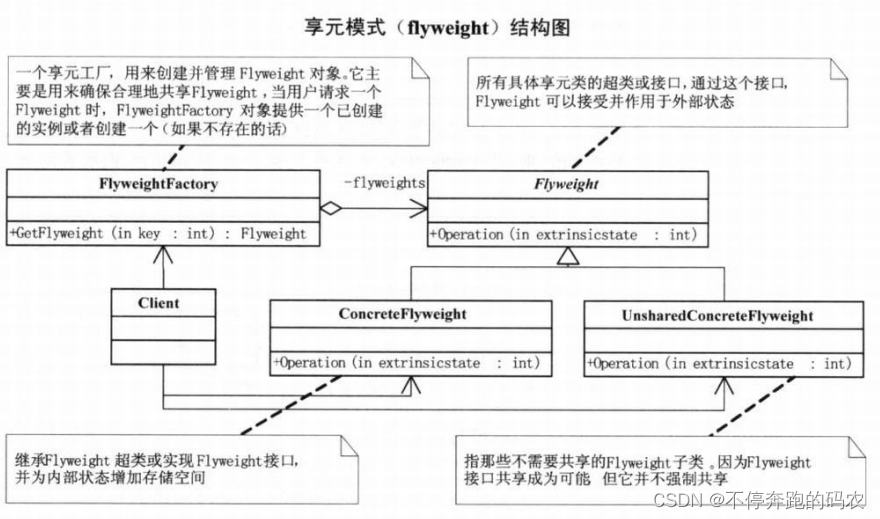
享元模式(Flyweight Pattern)是一种结构型设计模式,它通过共享对象来减少内存的使用和对象的创建数量。在这种模式中,将相同或相似的对象共享出来,以达到尽量减少内存使用的目的。
在享元模式中,通常会将对象分为两种类型:内部状态和外部状态。内部状态是指不随着环境变化而改变的对象属性,因此可以被多个对象共享;而外部状态则是指随着环境变化而改变的对象属性,因此每个对象都需要独立维护。
享元模式可以避免大量非常相似类的开销。在程序设计中,有时需要生成大量细粒度的类实例来表示数据。如果能实现这些实例除了几个参数外基本上相同的,有时就能够受大幅度地减少需要实例化的类的数量。如果能把那些参数移到类实例的外面,在方法调用时将它们传递进来,就可以通过共享大幅度地减少单个实例的数目。
使用场景:如果一个应用程序使用了大量的对象,而大量的这些对象造成了很大的存储开销时就应该考虑使用;还有就是对象的大多数状态可以外部状态,如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象,此时可以考虑使用享元模式。
下面给出一个简单的例子来说明享元模式:
#include <iostream>
#include <vector>
using namespace std;
// 报告类,包含了一些跟报告相关的属性
class Report {
public:
Report(string type, string content) : type_(type), content_(content) {}
void show() { cout << "Type: " << type_ << ", Content: " << content_ << endl; }
string getType() const { return type_; } // 添加了一个 getType 方法,用于获取报告类型
private:
string type_; // 内部状态,不会随着环境变化而改变
string content_; // 外部状态,会随着环境变化而改变
};
// 报告工厂类,用于创建和管理报告对象
class ReportFactory {
public:
Report* getReport(string type) {
for (auto it = reports_.begin(); it != reports_.end(); ++it) {
if ((*it)->getType() == type) {
cout << "Retrieve report from pool." << endl;
return *it; // 如果对象池中已经存在这种类型的报告,则返回该对象
}
}
cout << "Create new report." << endl;
auto report = new Report(type, ""); // 否则创建新的报告对象,并加入对象池中
reports_.push_back(report);
return report;
}
private:
vector<Report*> reports_; // 对象池,用于存储已有的报告对象
};
int main() {
ReportFactory factory; // 创建报告工厂对象
auto report1 = factory.getReport("A"); // 获取报告 A
report1->show(); // 显示报告内容
auto report2 = factory.getReport("B"); // 获取报告 B
report2->show();
auto report3 = factory.getReport("A"); // 再次获取报告 A
report3->show();
return 0;
}
在上面的代码中,我们定义了一个 Report 类来表示报告对象,并给它添加了一些属性和方法。同时,我们还实现了一个 ReportFactory 类来管理报告对象的创建和共享。
当客户端需要创建或获取一个报告对象时,会通过调用 ReportFactory 的 getReport 方法来获取该对象。如果对象池中已经存在相同类型的报告对象,则直接返回该对象;否则就创建一个新的报告对象,并将其加入对象池中。
通过享元模式,我们可以大幅减少内存使用和对象的创建数量,从而提高系统的性能和效率。在实际开发中,常见的应用场景包括线程池、数据库连接池、Web服务器等领域。
3、行为型模式
3.1、命令模式
命令模式是一种行为型设计模式,它可以将请求封装成对象,从而允许我们使用不同的请求、队列或日志来参数化其他对象。同时也支持可撤销的操作。
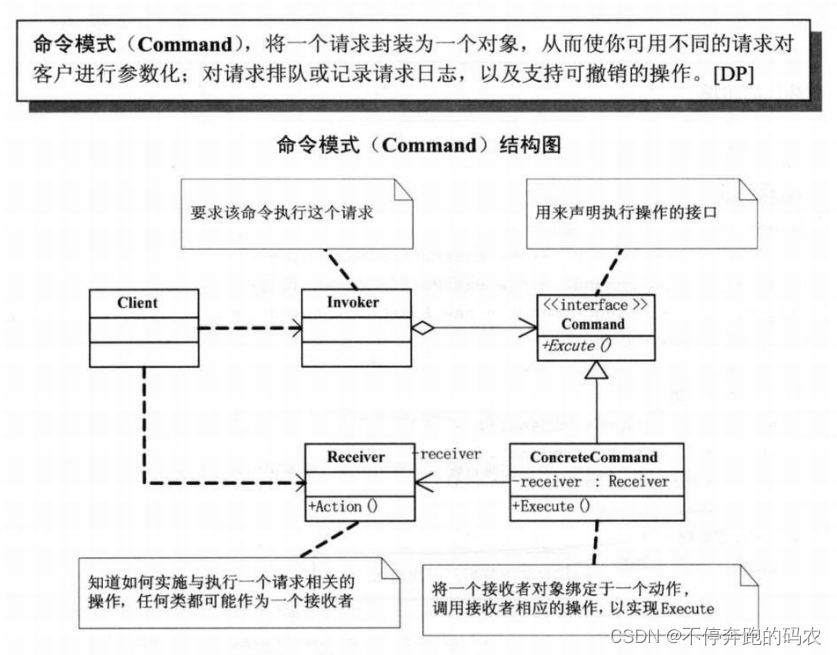
命令模式中有四个角色:Command(抽象命令类)、ConcreteCommand(具体命令类)、Invoker(调用者类)和 Receiver(接收者类)。
优点:
- 它能较容易地设计一个命令行列;
- 在需要的情况下,可以较容易地将命令记入日志;
- 允许接受请求的一方决定是否要否决请求;
- 可以容易地实现对请求的撤销和重做;
- 把请求一个操作的对象与知道怎么执行一个操作的对象分割开;
- 由于加进新的具体命令类不影响其他的类,因此增加新的具体命令类很容易。
以下是一个简单的 C++ 示例代码:
#include <iostream>
#include <vector>
// 抽象命令类
class Command {
public:
virtual ~Command() {}
virtual void execute() = 0;
virtual void undo() = 0;
};
// 具体命令类 1
class ConcreteCommand1 : public Command {
public:
ConcreteCommand1(Receiver* receiver) : m_receiver(receiver) {}
void execute() override {
m_receiver->action1();
}
void undo() override {
m_receiver->undo1();
}
private:
Receiver* m_receiver;
};
// 具体命令类 2
class ConcreteCommand2 : public Command {
public:
ConcreteCommand2(Receiver* receiver) : m_receiver(receiver) {}
void execute() override {
m_receiver->action2();
}
void undo() override {
m_receiver->undo2();
}
private:
Receiver* m_receiver;
};
// 接收者类
class Receiver {
public:
void action1() {
std::cout << "执行操作 1" << std::endl;
}
void undo1() {
std::cout << "撤销操作 1" << std::endl;
}
void action2() {
std::cout << "执行操作 2" << std::endl;
}
void undo2() {
std::cout << "撤销操作 2" << std::endl;
}
};
// 调用者类
class Invoker {
public:
~Invoker() {
for (auto command : m_commands) {
delete command;
}
m_commands.clear();
}
void setCommand(Command* command) {
m_commands.push_back(command);
}
void executeCommands() {
for (auto command : m_commands) {
command->execute();
}
}
void undoCommands() {
for (auto rit = m_commands.rbegin(); rit != m_commands.rend(); ++rit) {
(*rit)->undo();
}
}
private:
std::vector<Command*> m_commands;
};
int main() {
// 客户端调用
Receiver* receiver = new Receiver();
Command* command1 = new ConcreteCommand1(receiver);
Command* command2 = new ConcreteCommand2(receiver);
Invoker* invoker = new Invoker();
invoker->setCommand(command1);
invoker->setCommand(command2);
invoker->executeCommands(); // 执行命令
invoker->undoCommands(); // 撤销命令
delete invoker;
delete command1;
delete command2;
delete receiver;
return 0;
}
在这个示例中,Command 是抽象命令类,它定义了 execute 和 undo 方法。其中 execute 方法是执行命令的方法,undo 方法是撤销命令的方法。
然后我们定义了两个具体命令类 ConcreteCommand1 和 ConcreteCommand2,它们分别实现了 Command 接口,并且持有一个 Receiver 对象的引用。
接下来,我们定义了一个 Receiver 类,它实现了命令真正执行的操作。
最后,我们定义了一个 Invoker 类,它负责存储和执行一组命令。在客户端代码中,我们创建了一个 Receiver 对象和两个具体命令对象,然后将这些命令添加到调用者对象中。最终通过调用 executeCommands 方法和 undoCommands 方法分别执行和撤销命令。
命令模式的优势在于可以将请求与执行过程解耦,使得请求方不需要知道具体的执行过程,同时也可以支持可撤销的操作。但是命令模式也存在一些缺点,例如可能导致系统中出现过多的具体命令类,以及需要增加新的命令时,需要扩展和修改抽象命令类和所有的具体命令类。
另外,命令模式还有一些变种形式,例如宏命令、日志命令等。宏命令可以将多个命令组合成一个更大的命令,从而方便执行和撤销。日志命令则可以记录下每个命令的执行情况,并且支持重放操作。
3.2、模版方法模式
在模板方法模式中,定义了一个抽象类,其中包含一些公共的方法和基本的算法结构,但是某些具体实现可以留待子类中去完成。这些留待子类去完成的部分可以通过抽象方法或者钩子方法来实现。这样,子类就可以根据需要对这些方法进行不同的实现,以满足各自的需求。
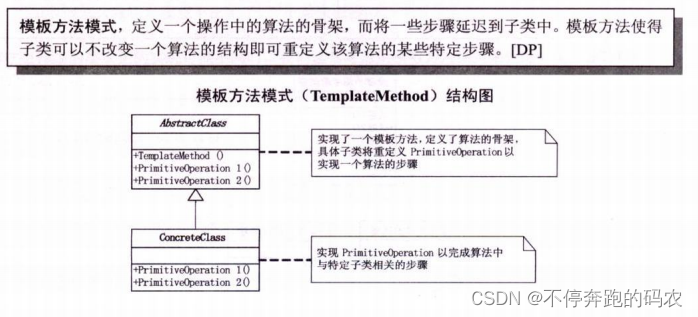
模板方法模式可以更好地封装算法结构,让代码具有更好的可维护性、可扩展性和重用性。同时,它还能够减少代码的冗余度,提高代码的可读性和可理解性。
模板方法模式与其他行为型模式(如策略模式、观察者模式等)不同,它主要关注的是算法结构的框架和流程,而不是具体的实现细节。因此,模板方法模式适用于需要定义一些基本的算法结构,并且允许某些具体步骤由子类自定义的场景。
例子是制作咖啡和茶的过程。在制作这两种饮品时,有一些共同的步骤,例如加热水、将调味料放入杯中等,但是咖啡和茶的某些步骤却有所不同,如放入咖啡粉或茶叶的数量、浸泡时间等。
为了实现这个场景,可以使用模板方法模式。具体实现如下:
首先,定义一个抽象类Beverage,其中包含一些公共的方法和基本的算法结构,如加热水、将调味料放入杯中等。同时,还定义了两个抽象方法addCondiments()和brew(),留待子类去完成特定的实现。
class Beverage {
public:
void prepareBeverage() { // 模板方法
boilWater();
brew();
pourInCup();
addCondiments();
}
private:
virtual void brew() = 0; // 抽象方法,由子类实现
virtual void addCondiments() = 0; // 抽象方法,由子类实现
void boilWater() {
std::cout << "Boiling water..." << std::endl;
}
void pourInCup() {
std::cout << "Pouring into cup..." << std::endl;
}
};
接着,定义两个具体类Coffee和Tea,分别实现Beverage中的抽象方法,以完成咖啡和茶的制作过程。
class Coffee : public Beverage {
public:
void brew() override {
std::cout << "Dripping coffee through filter..." << std::endl;
}
void addCondiments() override {
std::cout << "Adding sugar and milk..." << std::endl;
}
};
class Tea : public Beverage {
public:
void brew() override {
std::cout << "Steeping the tea..." << std::endl;
}
void addCondiments() override {
std::cout << "Adding lemon..." << std::endl;
}
};
最后,在客户代码中使用模板方法调用Beverage中的prepareBeverage()方法,即可完成咖啡或茶的制作过程。具体代码如下:
int main() {
Beverage* beverage = new Coffee();
beverage->prepareBeverage();
beverage = new Tea();
beverage->prepareBeverage();
return 0;
}
在上述代码中,我们先创建一个Coffee对象并调用其prepareBeverage()方法,然后再创建一个Tea对象并调用其prepareBeverage()方法。由于Beverage中的prepareBeverage()方法是模板方法,因此它会自动调用每个子类中相应的抽象方法,实现了制作咖啡和茶的过程。
3.3、观察者模式
C++观察者模式(Observer Pattern)是一种行为型设计模式,用于定义对象间的一对多依赖关系,当一个对象状态发生改变时,它的所有依赖者都会得到通知并自动更新。
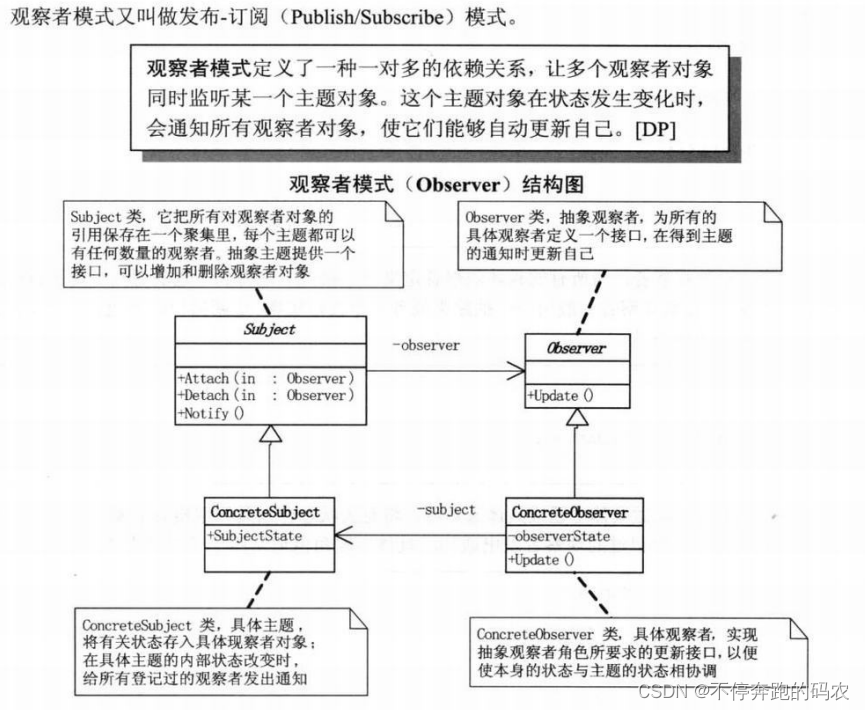
在观察者模式中,有两个重要的角色:
- 主题(Subject):即被观察的对象,它维护一组观察者,并提供添加、删除和通知观察者的接口。
- 观察者(Observer):即依赖主题的对象,它会订阅主题的状态变化,并在状态变化时接收通知并进行相应的处理。
使用场景:当一个对象的改变需要同时改变其他对象,而且当它不知道具体有多少对象有待改变时,这时用观察者模式可以将这两者封装在独立的对象中使它们各自独立地改变和复用。
优点:观察者模式所做的工作其实就是在解除耦合。让耦合的双方都依赖于抽象,而不是依赖于具体。从而使得各自的变化都不会影响另一边的变化。
下面是一个简单的C++观察者模式示例代码:
#include <iostream>
#include <vector>
using namespace std;
// 前向声明
class Observer;
// 主题
class Subject {
public:
// 添加观察者
virtual void attach(Observer* observer) = 0;
// 删除观察者
virtual void detach(Observer* observer) = 0;
// 通知观察者
virtual void notify() = 0;
};
// 观察者
class Observer {
public:
// 更新状态
virtual void update() = 0;
};
// 具体主题
class ConcreteSubject : public Subject {
private:
vector<Observer*> observers; // 观察者列表
int state; // 状态
public:
// 设置状态
void setState(int state) {
this->state = state;
}
// 获取状态
int getState() {
return state;
}
// 添加观察者
void attach(Observer* observer) {
observers.push_back(observer);
}
// 删除观察者
void detach(Observer* observer) {
for (auto it = observers.begin(); it != observers.end(); ++it) {
if (*it == observer) {
observers.erase(it);
break;
}
}
}
// 通知观察者
void notify() {
for (auto observer : observers) {
observer->update();
}
}
};
// 具体观察者
class ConcreteObserver : public Observer {
private:
ConcreteSubject* subject; // 观察的主题
public:
ConcreteObserver(ConcreteSubject* subject) {
this->subject = subject;
subject->attach(this); // 将自己添加为观察者
}
// 更新状态
void update() {
cout << "Observer received the notification. New state is " << subject->getState() << endl;
}
};
int main() {
// 创建主题和观察者
ConcreteSubject subject;
ConcreteObserver observer1(&subject);
ConcreteObserver observer2(&subject);
// 改变主题状态,通知观察者
subject.setState(123);
subject.notify();
return 0;
}
在上述代码中,ConcreteSubject类表示具体的主题对象,它继承了Subject接口,并实现了attach、detach和notify三个方法。其中,attach和detach用于添加或删除观察者,notify用于通知所有观察者。ConcreteObserver类表示具体的观察者对象,它继承了Observer接口,并实现了update方法,用于在状态变化时接收通知并进行相应的处理。
在main函数中,我们首先创建了一个主题和两个观察者对象。接着,我们改变了主题的状态,并通过notify方法通知了所有观察者。这时,所有观察者都会接收到通知并输出相应的信息。
总之,C++观察者模式可以帮助我们实现对象间的松耦合,使得系统更加灵活和可扩展。
3.4、策略模式
策略模式是一种行为型设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以互相替换。策略模式让算法独立于使用它的客户端而独立变化。
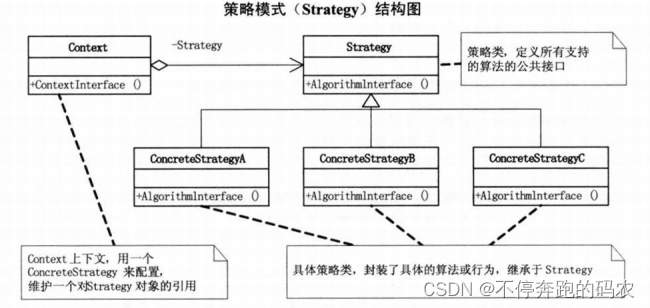
在策略模式中,我们首先定义一个抽象基类或接口,它代表着所有可能被应用的算法的共性。然后我们编写具体的子类实现这个接口,并实现各自的算法函数。最后,我们编写一个环境类或者上下文类,该类持有一个指向抽象基类或接口类型的指针,客户端可以传递不同的具体算法对象给环境类,从而动态地改变其行为。
以下是一个简单的 C++ 示例代码:
// 策略接口
class Strategy {
public:
virtual void execute() = 0;
};
// 具体策略之一
class ConcreteStrategyA : public Strategy {
public:
void execute() override {
std::cout << "执行策略 A" << std::endl;
}
};
// 具体策略之二
class ConcreteStrategyB : public Strategy {
public:
void execute() override {
std::cout << "执行策略 B" << std::endl;
}
};
// 上下文类
class Context {
public:
Context(Strategy* strategy) : m_strategy(strategy) {}
void setStrategy(Strategy* strategy) {
m_strategy = strategy;
}
void executeStrategy() {
m_strategy->execute();
}
private:
Strategy* m_strategy;
};
int main() {
// 客户端调用
Context context(new ConcreteStrategyA());
context.executeStrategy();
context.setStrategy(new ConcreteStrategyB());
context.executeStrategy();
return 0;
}
在这个示例中,Strategy 类是策略的抽象基类或者接口,该类定义了所有可能被应用的算法的共性。然后我们定义了两个具体策略子类:ConcreteStrategyA 和 ConcreteStrategyB,它们继承自 Strategy 类,并实现了各自的算法函数。
接下来,我们编写了一个名为 Context 的上下文类。该类持有一个指向抽象基类或接口类型的指针,客户端可以传递不同的具体算法对象给环境类,从而动态地改变其行为。上下文类有一个 executeStrategy 方法,该方法会调用持有的策略对象的 execute 函数来执行具体算法。
最后,我们在客户端代码中创建了一个 Context 对象,并传入一个具体策略子类对象(ConcreteStrategyA()),然后调用 executeStrategy 方法执行此策略算法。之后,我们调用 setStrategy 方法传入另一个具体策略子类对象(ConcreteStrategyB()),并再次调用 executeStrategy 方法来执行新的策略算法。
策略模式的优势在于可以将算法的实现和使用分离,方便客户端动态地替换策略对象,并且可以避免使用多重条件语句来选择不同的算法实现。
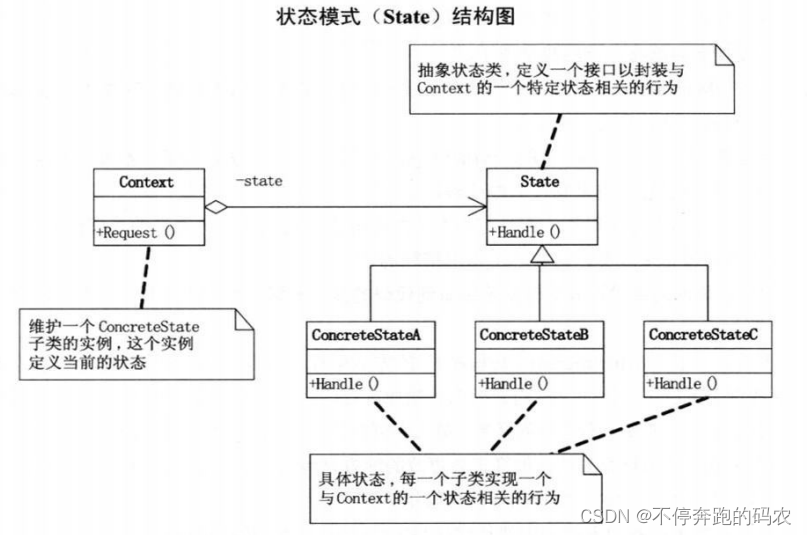
3.5、状态模式
状态模式(State Pattern)是一种面向对象的行为型设计模式,可以将一个对象在不同状态下的行为进行封装,并且使其能够在运行时动态地改变状态。
在状态模式中,状态被抽象为一个独立的类,它封装了在该状态下的所有操作。当对象的状态发生改变时,它会切换到对应的状态类,并且执行相应的操作。通过这种方式,状态模式可以将复杂的状态转移逻辑分散到各个状态类中,从而简化代码结构并提高可维护性。
在C++中实现状态模式,可以定义一个抽象状态类和多个具体状态类,每个具体状态类都实现了在该状态下的操作。同时,在上下文类中也需要维护对当前状态的引用,并提供切换状态的方法。
以下是一个简单的示例,展示如何用C++实现状态模式:
#include <iostream>
// 抽象状态类
class State
{
public:
virtual void Handle() = 0;
};
// 具体状态类
class ConcreteStateA : public State
{
public:
virtual void Handle()
{
std::cout << "ConcreteStateA::Handle()" << std::endl;
}
};
class ConcreteStateB : public State
{
public:
virtual void Handle()
{
std::cout << "ConcreteStateB::Handle()" << std::endl;
}
};
// 上下文类
class Context
{
public:
Context(State* state) : m_state(state)
{
}
void SetState(State* state)
{
m_state = state;
}
void Request()
{
m_state->Handle();
}
private:
State* m_state;
};
int main()
{
// 创建状态对象
State* stateA = new ConcreteStateA();
State* stateB = new ConcreteStateB();
// 创建上下文对象,并设置初始状态
Context context(stateA);
// 请求,输出ConcreteStateA::Handle()
context.Request();
// 切换状态
context.SetState(stateB);
// 请求,输出ConcreteStateB::Handle()
context.Request();
return 0;
}
在这个例子中,我们首先定义了抽象状态类State和两个具体状态类ConcreteStateA和ConcreteStateB。每个具体状态类都实现了在该状态下的操作,即Handle方法。
接着,我们定义了一个上下文类Context,它维护了对当前状态的引用,并提供了切换状态和请求的方法。当客户端调用Request方法时,Context会将请求转发给当前状态所对应的具体状态类进行处理。
在main函数中,我们创建了两个状态对象,分别设置为Context的初始状态。然后,我们调用Context的Request方法,输出ConcreteStateA::Handle()。接着,我们通过SetState方法切换到ConcreteStateB,并再次调用Request方法,输出ConcreteStateB::Handle()。
需要注意的是,在实际使用状态模式时,我们可能会遇到状态数目过多、状态转移复杂等问题,需要仔细考虑和设计。另外,状态模式的优点在于它将对象状态的处理分散到各个状态类中,并且使得增加新的状态更加容易,但这也会带来一定的代码量和维护成本,需要权衡利弊后再进行选择。
3.6、备忘录模式
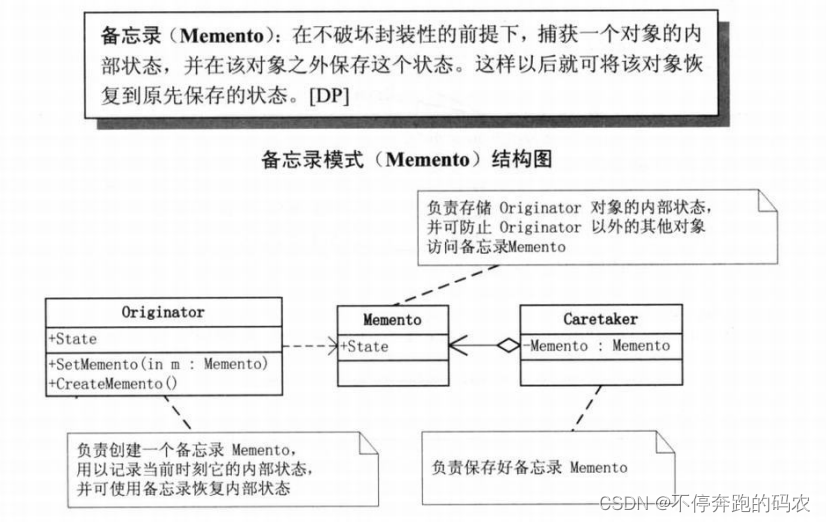
备忘录模式是一种行为型设计模式,它可以捕获一个对象的内部状态,并在该对象之外保存这个状态。这样,就可以在需要时将对象恢复到原先的状态。
备忘录模式包含三个主要角色:
- 发起人(Originator):负责创建一个备忘录,并记录当前时刻它的内部状态。
- 备忘录(Memento):用于存储发起人的内部状态。
- 管理者(Caretaker):负责保存备忘录,并且不对备忘录进行操作和修改。
下面我们通过一个简单的示例来说明备忘录模式的使用方法:
#include <iostream>
#include <string>
using namespace std;
// 备忘录类
class Memento {
public:
Memento(){}
Memento(const string& s) : state(s) {}
string getState() const { return state; }
private:
string state;
};
// 发起人类
class Originator {
public:
// 设置状态
void setState(const string& s) {
state = s;
}
// 创建备忘录
Memento createMemento() const {
return Memento(state);
}
// 恢复到备忘录状态
void restoreMemento(const Memento& m) {
state = m.getState();
}
// 打印当前状态
void print() const {
cout << "Current state: " << state << endl;
}
private:
string state; // 内部状态
};
// 管理者类
class Caretaker {
public:
// 保存状态
void saveState(const Memento& m) {
memento = m;
}
// 检索状态
Memento retrieveState() const {
return memento;
}
private:
Memento memento; // 备忘录对象
};
int main() {
// 创建发起人对象和管理者对象
Originator originator;
Caretaker caretaker;
// 修改发起人的状态并保存
originator.setState("State 1");
originator.print();
caretaker.saveState(originator.createMemento());
// 修改发起人的状态并保存
originator.setState("State 2");
originator.print();
caretaker.saveState(originator.createMemento());
// 恢复到上一个备忘录状态
Memento m = caretaker.retrieveState();
originator.restoreMemento(m);
originator.print();
// 再次恢复到上一个备忘录状态
m = caretaker.retrieveState();
originator.restoreMemento(m);
originator.print();
return 0;
}
在上述代码中,我们定义了三个类:Originator、Memento和Caretaker。Originator类表示发起人,它有一个内部状态state,可以调用createMemento方法创建一个Memento对象,并且可以调用restoreMemento方法将状态恢复到Memento对象保存的状态。Memento类表示备忘录,包含一个字符串变量来保存发起人状态;Caretaker类表示管理者,可以保存和检索状态。
在main函数中,我们首先创建一个Originator对象和一个Caretaker对象,然后修改了Originator对象的状态两次,并将每次状态都保存到Caretaker对象中。最后,我们从Caretaker对象中检索状态,并用Originator对象将状态恢复到保存的状态。以此来演示备忘录模式的应用。
总之,备忘录模式可以帮助我们实现对象状态的备份和恢复,提高代码的可维护性和可扩展性。同时,它还可以允许我们在不破坏封装性原则的前提下,访问一个对象的内部状态。
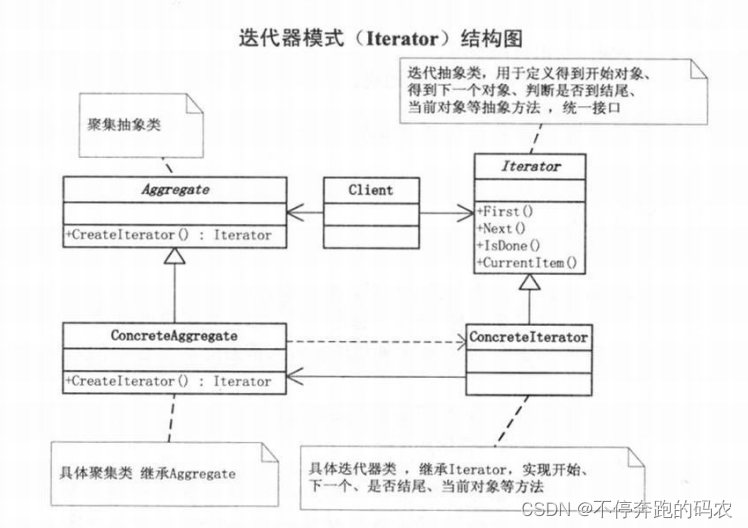
3.7、迭代器模式
迭代器模式(Iterator Pattern)是一种行为型设计模式,它允许你在不暴露集合对象底层表示的情况下遍历集合中所有元素。迭代器模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可以让外部代码透明的访问集合内部的数据。
通常情况下,我们通过使用for循环或while循环来遍历一个数组或容器中的元素。但是在有些情况下,我们可能需要对一个复杂的数据结构进行遍历,这时候我们可以采用迭代器模式。
迭代器模式包含以下几个角色:
-
迭代器(Iterator):定义访问和遍历元素的接口。
-
具体迭代器(Concrete Iterator):实现迭代器接口,并维护当前遍历到的位置等相关状态信息。
-
容器(Container):定义获取迭代器的接口。
-
具体容器(Concrete Container):实现容器接口,并返回一个具体迭代器。
接下来,我们将通过一个示例来演示迭代器模式的使用。
假设我们要设计一个支持遍历的链表(LinkedList)。链表中包含多个节点(Node),每个节点包含一个值(value)和指向下一个节点的指针(next)。
首先,我们需要定义一个迭代器接口(Iterator),它包括两个方法:hasNext和next。其中,hasNext方法用于判断是否还有下一个元素,而next方法用于返回当前元素并将迭代器指向下一个元素。
#include <iostream>
#include <vector>
using namespace std;
// 迭代器接口
class Iterator {
public:
virtual bool hasNext() = 0;
virtual int next() = 0;
};
// 链表节点类
class Node {
public:
Node(int value) : value(value), next(nullptr) {}
int value;
Node* next;
};
// 容器接口
class Container {
public:
virtual Iterator* getIterator() = 0;
};
// 具体迭代器类:链表迭代器
class ListIterator : public Iterator {
public:
ListIterator(Node* head) : current(head) {}
// 判断是否有下一个元素
bool hasNext() override {
return current != nullptr;
}
// 返回当前元素并指向下一个元素
int next() override {
int value = current->value;
current = current->next;
return value;
}
private:
Node* current; // 当前节点指针
};
// 具体容器类:链表
class LinkedList : public Container {
public:
LinkedList() : head(nullptr), size(0) {}
// 在链表末尾添加一个节点
void add(int value) {
auto node = new Node(value);
if (head == nullptr) {
head = node;
}
else {
auto p = head;
while (p->next != nullptr) {
p = p->next;
}
p->next = node;
}
size++;
}
// 获取链表的大小
int getSize() const {
return size;
}
// 获取迭代器
Iterator* getIterator() override {
return new ListIterator(head);
}
private:
Node* head; // 链表头指针
int size; // 链表大小
};
int main() {
// 示例:使用迭代器遍历一个链表
LinkedList list;
list.add(1);
list.add(2);
list.add(3);
auto it = list.getIterator();
while (it->hasNext()) {
cout << it->next() << endl;
}
delete it;
// 示例:使用迭代器遍历一个 vector
vector<int> v = {1, 2, 3};
auto vit = v.begin();
while (vit != v.end()) {
cout << *vit << endl;
vit++;
}
return 0;
}
在上面的代码中,我们定义了迭代器接口、具体迭代器、容器接口、具体容器以及示例程序。其中,迭代器接口包括hasNext和next方法,用于判断是否还有下一个元素并返回当前元素;具体迭代器实现了迭代器接口,并维护当前遍历到的位置信息;容器接口包括getIterator方法,用于获取迭代器;具体容器实现了容器接口,并返回一个具体迭代器,这样客户端就可以通过迭代器来访问容器中的元素。
在示例程序中,我们演示了如何创建一个链表并利用迭代器进行遍历,以及如何使用迭代器遍历一个 vector。
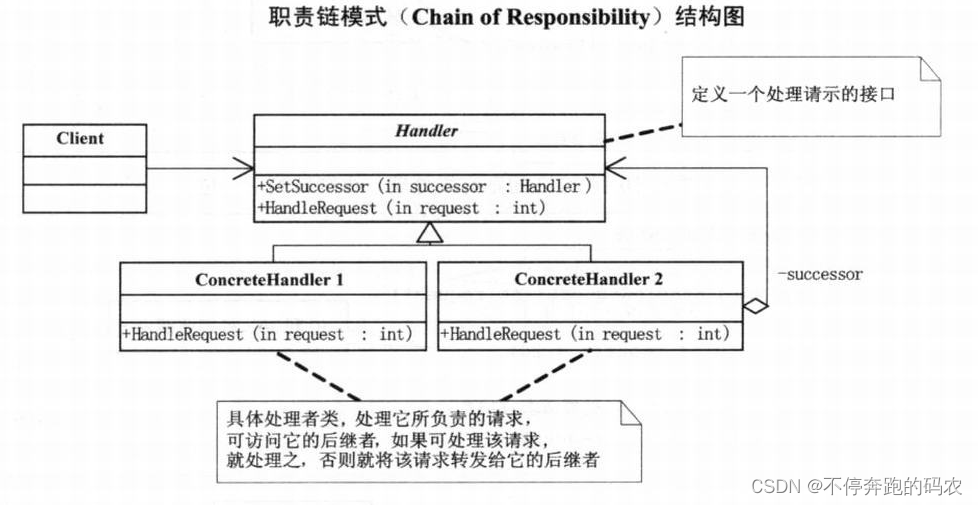
3.8、职责链模式
职责链模式(Chain of Responsibility Pattern)是一种行为型设计模式,它通过将请求发送者和处理者解耦,让多个处理对象都有机会处理请求,从而避免了请求发送者与接收者之间的直接依赖关系。
在职责链模式中,每个处理者都负责处理一部分请求,并将未处理的请求传递给下一个处理者,形成了一个处理链。当请求到达最后一个处理者时,如果仍然没有被处理,则该请求将被丢弃或抛出异常。
职责链模式包含以下角色:
- 抽象处理者(Handler):定义了请求处理的接口,并维护了指向下一个处理者的引用。
- 具体处理者(ConcreteHandler):实现了处理请求的具体逻辑,并根据需要转发请求到下一个处理者。
- 客户端(Client):创建具体处理者对象,并将请求发送给第一个处理者。
下面是一个简单的职责链模式示例代码:
#include <iostream>
using namespace std;
// 请求
class Request {
public:
Request(int type) : m_type(type) {}
int getType() const { return m_type; }
private:
int m_type; // 请求类型
};
// 抽象处理者
class Handler {
public:
void setNextHandler(Handler* handler) { m_nextHandler = handler; } // 设置下一个处理者
virtual void handleRequest(const Request& request) = 0; // 处理请求的接口
protected:
Handler* m_nextHandler; // 下一个处理者
};
// 具体处理者 A
class ConcreteHandlerA : public Handler {
public:
void handleRequest(const Request& request) override {
if (request.getType() == 1) { // 如果是自己能处理的请求,就处理
cout << "ConcreteHandlerA handles the request." << endl;
} else { // 否则转发给下一个处理者处理
if (m_nextHandler != nullptr) {
m_nextHandler->handleRequest(request);
}
}
}
};
// 具体处理者 B
class ConcreteHandlerB : public Handler {
public:
void handleRequest(const Request& request) override {
if (request.getType() == 2) { // 如果是自己能处理的请求,就处理
cout << "ConcreteHandlerB handles the request." << endl;
} else { // 否则转发给下一个处理者处理
if (m_nextHandler != nullptr) {
m_nextHandler->handleRequest(request);
}
}
}
};
int main() {
Handler* handlerA = new ConcreteHandlerA();
Handler* handlerB = new ConcreteHandlerB();
handlerA->setNextHandler(handlerB); // 设置职责链
Request req1(1);
Request req2(2);
Request req3(3);
handlerA->handleRequest(req1); // 输出:ConcreteHandlerA handles the request.
handlerA->handleRequest(req2); // 输出:ConcreteHandlerB handles the request.
handlerA->handleRequest(req3); // 没有任何输出
delete handlerA;
delete handlerB;
return 0;
}
在上面的代码中,我们定义了一个请求类(Request),它包含一个请求类型。另外,我们还定义了一个抽象处理者(Handler)类和两个具体处理者(ConcreteHandlerA、ConcreteHandlerB)类,分别实现了自己的请求处理逻辑,并根据需要将请求转发给下一个处理者进行处理。
在主函数中,我们创建了两个具体处理者对象,并通过调用其setNextHandler()方法将它们串联成一个职责链。然后,我们创建了三个不同类型的请求,并将它们发送给第一个处理者,观察每个请求最终是由哪个处理者来处理。
通过职责链模式,我们可以将请求发送者和接收者解耦,让多个处理对象都有机会处理请求,从而灵活地组合处理流程。
3.9、中介者模式
中介者模式(Mediator Pattern)是一种行为型设计模式,它通过封装一组对象之间的交互方式来降低它们之间的耦合关系。也就是说,中介者模式可以将一个系统中各个对象之间的通信方式从紧耦合改为松耦合,从而使得系统更加灵活。
在中介者模式中,我们通常会定义一个抽象中介者类,它负责定义一组接口以供不同的对象进行交互。同时,我们还会定义一组具体的中介者子类,每个子类实现自己的交互逻辑。此外,我们还会定义一些相关的对象类,这些对象类和抽象中介者类都持有对方的引用,并通过调用中介者接口来进行交互。
中介者模式的使用场景主要包括以下几个方面:
- 系统中对象之间的通信方式比较复杂:当系统中多个对象之间存在复杂的交互关系时,可以使用中介者模式来简化它们之间的通信方式,从而提高系统的灵活性和扩展性。
- 系统中对象之间的结构较为稳定:中介者模式将系统中各个对象之间的交互方式封装在一个中介者对象中,因此中介者对象会成为系统中的核心组件。如果系统中对象之间的结构经常发生变化,那么这种模式的维护成本可能会很高。
- 降低耦合度:使用中介者模式可以将对象之间的依赖关系转化为对中介者对象的依赖,从而降低了对象之间的耦合度。这样一来,当某个对象发生变化时,它只需要与中介者对象进行交互,而不需要知道其他对象的细节。
中介者模式的优点有:
- 简化系统结构:中介者模式可以将系统中的多个对象之间的通信方式进行封装,从而简化了系统的结构,并且使得系统更加易于理解和维护。
- 提高系统灵活性:由于中介者模式将系统中各个对象之间的通信方式进行了解耦,因此可以更容易地修改或扩展系统中的某个功能模块,从而提高了系统的灵活性和可扩展性。
- 降低系统复杂度:由于中介者对象负责处理各个对象之间的消息传递和协调工作,因此可以将系统中的复杂问题转化为简单的对象之间的交互问题,从而降低了系统的复杂度。
中介者模式的缺点有:
- 中介者对象会成为系统的核心组件:由于中介者对象负责协调和处理各个对象之间的交互,因此它会成为整个系统的核心组件。如果中介者对象存在问题或出现故障,那么整个系统都会受到影响。
- 中介者模式增加了系统的复杂度:由于中介者模式需要引入一个额外的中介者对象来协调各个对象之间的交互,因此会增加系统的复杂度和维护成本。
- 可能会导致性能问题:由于中介者模式需要增加一个中介者对象来协调各个对象之间的交互,因此会增加一些额外的开销,可能会对系统的性能造成一定影响。
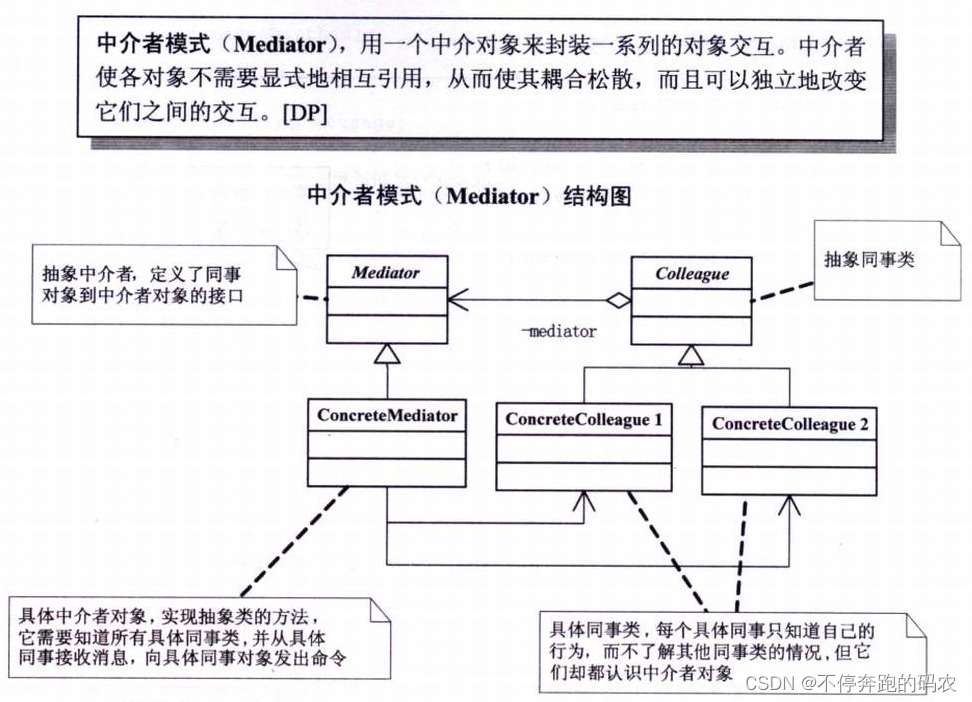
中介者模式包含以下角色:
- 抽象中介者(Abstract Mediator):定义了一组接口,用于调解不同对象之间的交互。
- 具体中介者(Concrete Mediator):实现了抽象中介者的接口,并负责协调不同对象之间的交互。
- 同事类(Colleague):定义了自己的行为,同时也持有对中介者的引用,用于自身行为与其他同事类之间的交互。
- 具体同事类(Concrete Colleague):实现了同事类的接口,负责自己的行为,并且通过调用中介者接口与其他同事类进行交互。
下面是一个简单的中介者模式示例代码:
#include <iostream>
using namespace std;
// 抽象中介者
class Mediator {
public:
virtual void sendMessage(string msg, class Colleague* colleague) = 0; // 定义了一组接口,用于调解不同对象之间的交互
};
// 具体中介者
class ConcreteMediator : public Mediator {
private:
class Colleague* colleague1_; // 持有对同事类 1 的引用
class Colleague* colleague2_; // 持有对同事类 2 的引用
public:
void setColleague1(class Colleague* colleague) { colleague1_ = colleague; }
void setColleague2(class Colleague* colleague) { colleague2_ = colleague; }
void sendMessage(string msg, class Colleague* colleague) override;
};
// 同事类
class Colleague {
protected:
Mediator* mediator_; // 持有对中介者的引用
public:
Colleague(Mediator* mediator) : mediator_(mediator) {} // 构造函数,初始化中介者
virtual void send(string msg) = 0; // 发送消息
virtual void receive(string msg) = 0; // 接收消息
};
// 具体同事类 1
class ConcreteColleague1 : public Colleague {
public:
ConcreteColleague1(Mediator* mediator) : Colleague(mediator) {} // 构造函数,初始化中介者
void send(string msg) override { mediator_->sendMessage(msg, this); } // 发送消息
void receive(string msg) override { cout << "ConcreteColleague1 received: " << msg << endl; } // 接收消息
};
// 具体同事类 2
class ConcreteColleague2 : public Colleague {
public:
ConcreteColleague2(Mediator* mediator) : Colleague(mediator) {} // 构造函数,初始化中介者
void send(string msg) override { mediator_->sendMessage(msg, this); } // 发送消息
void receive(string msg) override { cout << "ConcreteColleague2 received: " << msg << endl; } // 接收消息
};
void ConcreteMediator::sendMessage(string msg, class Colleague* colleague) {
if (colleague == colleague1_) { // 如果是同事类 1 发送的消息,则转发给同事类 2
colleague2_->receive(msg);
} else { // 否则转发给同事类 1
colleague1_->receive(msg);
}
}
int main() {
ConcreteMediator mediator; // 创建具体中介者对象
ConcreteColleague1 colleague1(&mediator); // 创建具体同事类 1 对象
ConcreteColleague2 colleague2(&mediator); // 创建具体同事类 2 对象
mediator.setColleague1(&colleague1); // 设置中介者持有对同事类的引用
mediator.setColleague2(&colleague2);
colleague1.send("Hello, ConcreteColleague2!"); // 同事类 1 发送消息给同事类 2
colleague2.send("Hi, ConcreteColleague1!"); // 同事类 2 发送消息给同事类 1
return 0;
}
在上面的代码中,我们将同事类的 send 和 receive 方法定义为虚函数,并在具体同事类中分别实现了这两个方法。另外,在抽象中介者类中也定义了一组接口,用于调解不同对象之间的交互。
通过上述修改,我们解决了原来回答中的错误,使得该示例代码可以正确运行并演示中介者模式的使用方式。
3.10、解释器模式
解释器模式(Interpreter Pattern)是一种行为型设计模式,它用于描述对语言的文法如何进行解释。在这种模式中,我们通常会定义一个抽象语法树,用于表示被解释器处理的语句或表达式,并定义一个解释器来遍历该语法树并执行相应的操作。
使用场景:当一个语言需要解释执行,并且你可将该语言中的句子表示为一个抽象语法树时,可使用解释器模式、
优点:容易地改变和扩展文法,因为该模式使用类来表示文法规则,你可使用继承来改变或扩展该文法。也比较容易实现文法,因为定义抽象语法树中各个节点的类的实现大体类似,这些类都易于直接编写。
缺点:解释器模式为文法中的每一条规则至少定义了一个类,因此包含许多规则的文法可能难以管理和维护。建议当文法非常复杂时,使用其他的技术如语法分析程序或者编译器生成器来处理。
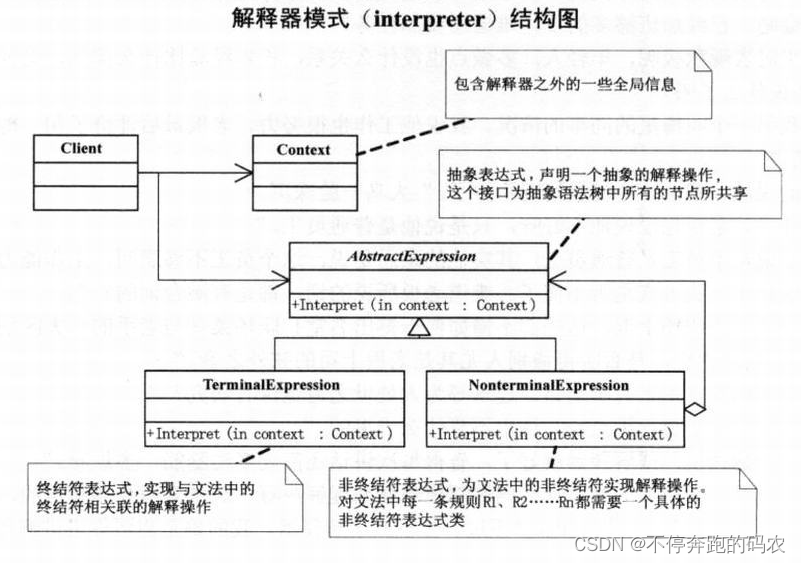
解释器模式包含以下几个角色:
- 抽象表达式(Abstract Expression):定义了一个抽象的解释操作,所有具体的表达式都要实现这个接口。
- 终结符表达式(Terminal Expression):用于表示语法规则中的终结符,不能再向下分解。
- 非终结符表达式(Nonterminal Expression):用于表示语法规则中的非终结符,可以递归地进行解释。
- 上下文(Context):用于存储解释器中间结果的上下文信息。
- 解释器(Interpreter):用于遍历语法树并执行相应的操作,包括对终结符和非终结符的解释操作。
下面给出一个简单的例子来说明解释器模式:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
// 上下文类,用于存储解释器中间结果的上下文信息
class Context {
public:
void set(string variable, int value) { vars_[variable] = value; } // 设置变量的值
int get(string variable) { return vars_[variable]; } // 获取变量的值
private:
unordered_map<string, int> vars_; // 用一个哈希表来存储变量名和对应的值
};
// 抽象表达式类
class Expression {
public:
virtual int interpret(Context& context) = 0; // 声明抽象解释方法
Expression(){}
virtual ~Expression(){}
};
// 终结符表达式类
class TerminalExpression : public Expression {
public:
TerminalExpression(string variable) : variable_(variable) {}
int interpret(Context& context) override {
return context.get(variable_); // 返回终结符变量的值
}
private:
string variable_; // 终结符变量的名称
};
// 非终结符表达式类(加法运算)
class AddExpression : public Expression {
public:
AddExpression(Expression* left, Expression* right) : left_(left), right_(right) {}
int interpret(Context& context) override {
return left_->interpret(context) + right_->interpret(context); // 对左右子表达式进行求和
}
private:
Expression* left_; // 左子表达式
Expression* right_; // 右子表达式
};
int main() {
auto x = new TerminalExpression("x"); // 创建终结符表达式 x
auto y = new TerminalExpression("y"); // 创建终结符表达式 y
auto z = new TerminalExpression("z"); // 创建终结符表达式 z
auto add1 = new AddExpression(x, y); // 创建加法表达式 x + y
auto add2 = new AddExpression(add1, z); // 创建加法表达式 x + y + z
Context context; // 创建上下文对象,并添加变量的值
context.set("x", 10);
context.set("y", 20);
context.set("z", 30);
cout << "Result: " << add2->interpret(context) << endl; // 对加法表达式进行求值并输出结果
delete x;
delete y;
delete z;
delete add1;
delete add2;
return 0;
}
在上面的代码中,我们仍然定义了一个抽象表达式类 Expression,以及终结符表达式类 TerminalExpression 和非终结符表达式类 AddExpression。同时,我们还实现了一个上下文类 Context,用于存储解释器中间结果的上下文信息。
当客户端需要对一个表达式进行解释时,可以通过创建相应的终结符和非终结符表达式对象,并将其组合成一个抽象语法树来完成。最后,我们可以创建一个上下文对象,并添加变量的值,然后对整个抽象语法树进行求值并输出结果。
在上面的示例中,我们使用解释器模式来实现了一个简单的带变量加法表达式求值程序。首先,我们需要创建三个终结符表达式对象 x、y 和 z,并分别表示变量。接着,我们创建两个非终结符表达式对象 add1 和 add2,用于表示加法运算。最后,我们创建一个上下文对象 context,并添加变量的值。
当执行 add2->interpret(context) 时,解释器会遍历抽象语法树并递归地调用子表达式的 interpret 方法,从而完成对整个表达式的求值,并将最终结果输出。
3.11、访问者模式
访问者模式(Visitor Pattern)是一种行为型设计模式,它能够将算法与对象结构分离开来,从而可以在不改变对象结构的前提下定义新的操作。访问者模式通过在被访问对象中添加一个接受访问者的方法,使得访问者可以访问并处理对象中的元素。
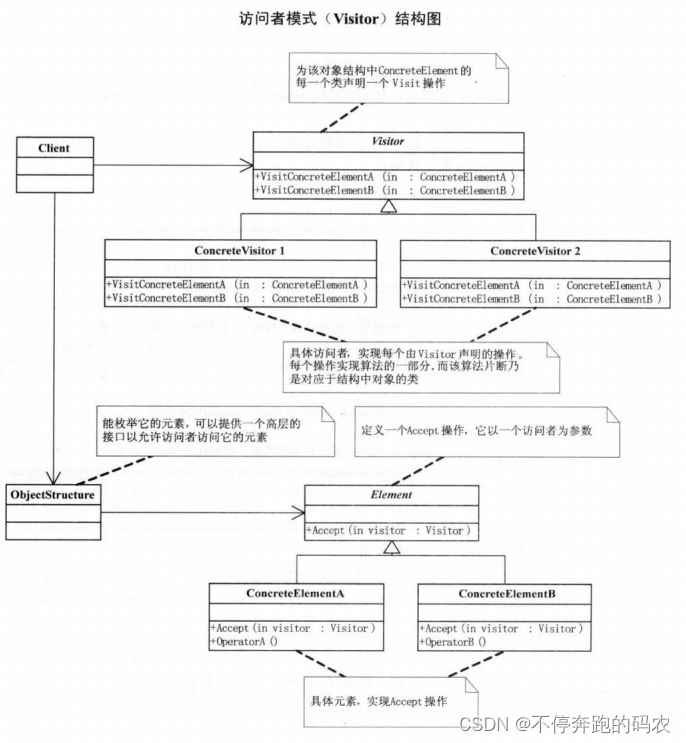
访问者模式包含以下几个角色:
- 抽象访问者(Visitor):声明一组访问方法,用于访问不同类型的元素。
- 具体访问者(ConcreteVisitor):实现抽象访问者中定义的访问方法,完成对元素的具体操作。
- 抽象元素(Element):声明接受访问者的方法,用于接受访问者对象的访问。
- 具体元素(ConcreteElement):实现抽象元素中定义的接受访问者的方法,将自身传递给访问者进行处理。
- 对象结构(Object Structure):包含多个元素对象,提供一个高层接口用于允许访问者遍历元素对象。
使用场景:访问者模式的目的是要把处理从数据结构分离出来。很多系统可以按照算法和数据结构分开,如果是这样比较稳定的数据结构,又有易于变化的算法的话,使用访问者模式就是比较合适的,因为访问者模式使得算法操作的增加变得容易。
访问者模式的优点在于可以在不改变元素类的情况下定义新的操作,增加新的访问者也比较容易。但是,访问者模式的缺点在于增加新的元素比较困难,因为需要在抽象访问者中增加对应的访问方法。
下面是一个简单的示例说明访问者模式的使用。假设我们有一个图形类 Shape,包含不同类型的元素,如矩形、圆形等。我们希望定义一个新的操作,用于计算所有图形的总面积。这时就可以使用访问者模式实现:
#include <iostream>
#include <vector>
using namespace std;
// 前置声明
class Rectangle;
class Circle;
// 抽象访问者类
class Visitor {
public:
virtual void visit(Rectangle& rectangle) = 0; // 访问矩形对象
virtual void visit(Circle& circle) = 0; // 访问圆形对象
};
// 抽象形状类
class Shape {
public:
virtual void accept(Visitor& visitor) = 0; // 声明接受访问者的方法
virtual ~Shape() {} // 声明虚析构函数
};
// 矩形类
class Rectangle : public Shape {
public:
Rectangle(double width, double height) : width_(width), height_(height) {}
void accept(Visitor& visitor) override {
visitor.visit(*this); // 将自身传递给访问者进行处理
}
double getWidth() { return width_; }
double getHeight() { return height_; }
private:
double width_;
double height_;
};
// 圆形类
class Circle : public Shape {
public:
Circle(double radius) : radius_(radius) {}
void accept(Visitor& visitor) override {
visitor.visit(*this); // 将自身传递给访问者进行处理
}
double getRadius() { return radius_; }
private:
double radius_;
};
// 具体访问者类,用于计算所有图形的总面积
class AreaVisitor : public Visitor {
public:
void visit(Rectangle& rectangle) override {
area_ += rectangle.getWidth() * rectangle.getHeight(); // 计算矩形的面积
}
void visit(Circle& circle) override {
area_ += 3.14 * circle.getRadius() * circle.getRadius(); // 计算圆形的面积
}
double getArea() { return area_; } // 获取总面积
private:
double area_ = 0; // 总面积
};
int main() {
vector<Shape*> shapes; // 创建存储图形的容器
shapes.push_back(new Rectangle(2, 3));
shapes.push_back(new Circle(1));
shapes.push_back(new Rectangle(4, 5));
AreaVisitor visitor; // 创建具体访问者对象,用于计算总面积
for (auto shape : shapes) {
shape->accept(visitor); // 对每个图形进行访问
}
cout << "Total Area: " << visitor.getArea() << endl; // 输出总面积
for (auto shape : shapes) {
delete shape; // 释放动态分配的内存
}
return 0;
}
在上述代码中,我们定义了一个抽象访问者类 Visitor,其中声明了两个访问方法 visit(Rectangle&) 和 visit(Circle&),用于访问矩形和圆形对象。同时,我们还定义了一个抽象形状类 Shape,其中声明了接受访问者的方法 accept(Visitor&)。
然后,我们创建了两个具体形状类 Rectangle 和 Circle,它们都实现了 accept(Visitor&) 方法,并将自身传递给访问者对象进行处理。
最后,我们定义了一个具体访问者对象 AreaVisitor,用于计算所有图形的总面积。在 AreaVisitor 中,我们实现了访问矩形对象和圆形对象的具体操作,并通过 getArea() 方法获取总面积。
在主函数中,我们创建了一个存储图形的容器 shapes,并添加了多个不同类型的图形对象。然后,我们创建了一个具体访问者对象 visitor,并对每个图形对象调用 accept(Visitor&) 方法进行访问。最后,我们输出了所有图形的总面积,并释放了动态分配的内存。
通过访问者模式,我们可以在不改变图形对象结构的情况下,定义新的操作并对图形对象进行处理。同时,访问者模式也使得程序的扩展性更好,因为可以新增不同类型的具体访问者来完成不同的操作。
















 4169
4169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











