







MeanShift聚类
又称均值漂移算法,首先需要一个迭代半径r,相似阈值T
对每个数据,作为一个新类,从其位置半径r内,选择满足相似条件的数据,放到一个表中。
计算表内数据的位置均值,数据均值,将新的位置和均值作为该类的特征,重新计算满足相似条件的数据,不断迭代直到收敛。
相当于数据有两个相似条件,一个位置相似条件r,一个数据相似条件T。
K-Means聚类
该方法被称为k均值,首先需要选定k个聚类中心。
对每个数据,计算出最近的聚类中心C,将其放入C类的数据列表中
拿到每个聚类中心列表中的数据,求取数据均值,将该值作为新的数据中心。不断迭代直到中心不再变化
若将数据分为位置数据和特征值,它和meanshift就很像了。
不过区别在于k-means中,类的数量是手动确定的,而mean shift的类数量是迭代自动确定的,并且最坏情况可能是每个数据都是一个类。
GMM聚类
原理
基于高斯函数的算法,通过混合单个或多个高斯函数,计算对应数据的概率中哪个分类的概率最高的,则属于哪个类别。
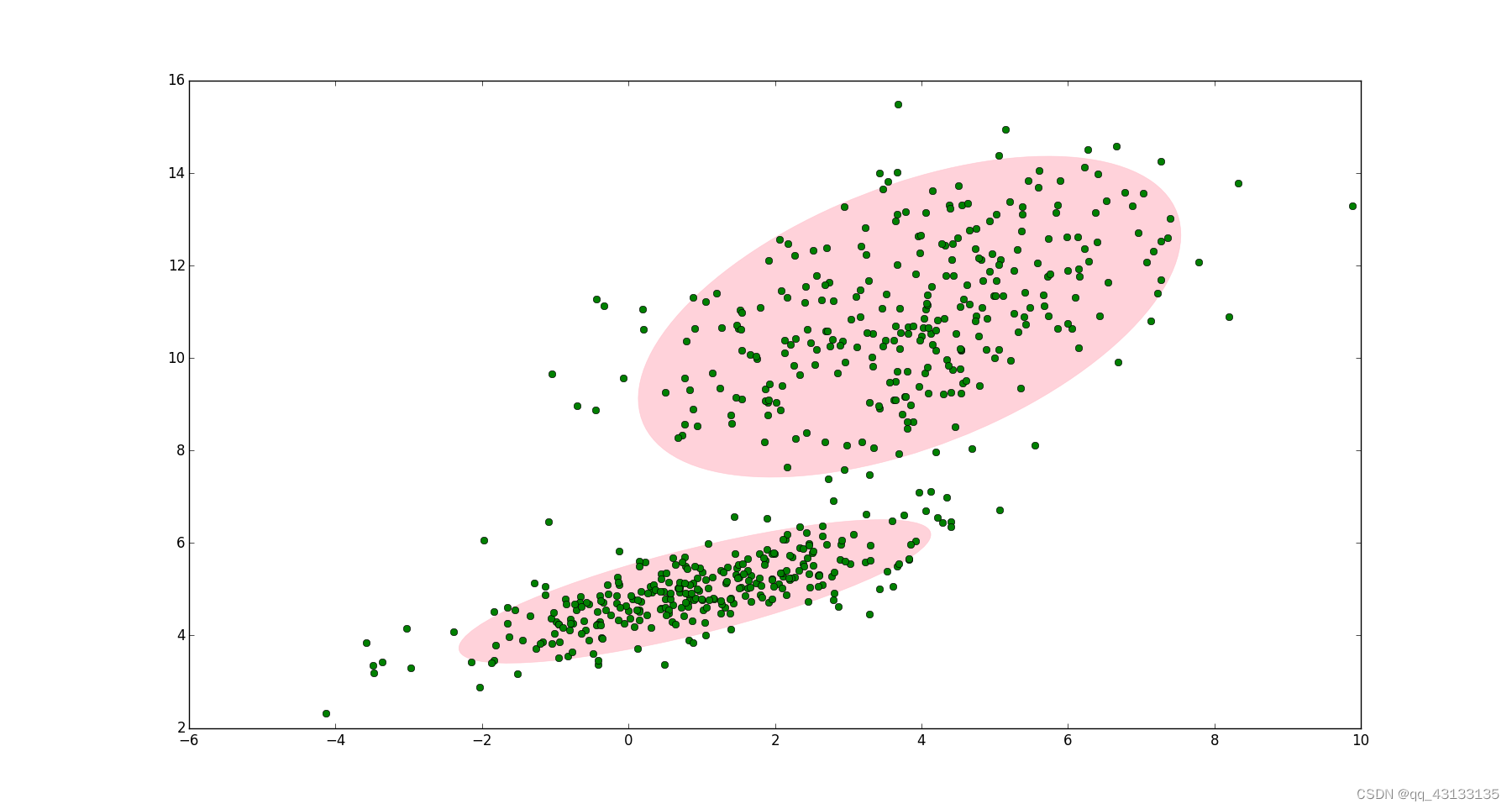
首先,假设数据中有k个高斯分布,数据的实际分布可用其线性组合描述:
p
(
x
)
=
∑
k
=
1
K
π
k
N
(
x
∣
μ
k
,
Σ
k
)
p(\boldsymbol{x}) = \sum_{k=1}^K\pi_k \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)
p(x)=∑k=1KπkN(x∣μk,Σk)
其中 N ( x ∣ μ k , Σ k ) \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) N(x∣μk,Σk)称为混合模型中的第k个分量。 π k \pi_k πk 是混合系数(或者叫权重、选中该分量的概率),且满足:
- ∑ k = 1 K π k = 1 \sum_{k=1}^K\pi_k = 1 ∑k=1Kπk=1
- 0 ≤ π k ≤ 1 0\leq \pi_k \leq 1 0≤πk≤1
如果要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:
首先随机地在这 K 个分量之中选一个,每个分量被选中的概率实际上就是它的系数 π k \pi_k πk
选中之后,再单独地考虑从这个分量的高斯分布中选取一个点就可以了。
通常我们并不能直接得到高斯混合模型的参数,而是观察到了一系列 数据点,给出一个类别的数量K后,希望求得最佳的K个高斯分模型。
因此,高斯混合模型的计算,便成了最佳的均值μ,方差Σ、权重π的寻找,这类问题通常通过 最大似然估计来求解。遗憾的是,此问题中直接使用最大似然估计,得到的是一 个复杂的非凸函数,目标函数是和的对数,难以展开和对其求偏导。在这种情况下,可以用EM算法。
EM算法是在最大化目标函数时,先固定一个变量使整体函数变为凸优化函数,求导得到最值,然后利用最优参数更新被固定的变量,进入下一个循环。
EM参数估计
具体到高 斯混合模型的求解,EM算法的迭代过程如下:
首先,初始随机选择各参数的值。然后,重复下述两步,直到收敛。
E步骤: 根据当前的参数,计算每个点由某个分模型生成的概率。
M步骤: 使用E步骤估计出的概率,来改进每个分模型的均值,方差和权重。
对于GMM中的每个分量,有三个参数:选中概率 π k \pi_k πk,分布均值 μ k {\mu}_k μk,分布标准差 Σ k {\Sigma}_k Σk。如果我们从分布选取一个点,怎么知道这个点是来自哪个分量呢?或者说如何确定 π k \pi_k πk?EM算法就可以解决GMM参数估计的问题。
通过EM算法,我们可以迭代计算出GMM中的参数: ( π k , x k , Σ k ) (\pi_k, \boldsymbol{x}_k, \boldsymbol{\Sigma}_k) (πk,xk,Σk)。
首先我们可以引入一个新的随机变量 z ∈ { z 1 , z 2 , . . . z k } \boldsymbol{z}∈\{z_1,z_2,...z_k\} z∈{z1,z2,...zk}
p ( z k ) = π k p(z_k)=\pi_k p(zk)=πk,表示第k个分量被选中的概率,由于是每次只能有一个分量被选中,即:
- ∑ k z k = Ω \sum_k{z_k}=\Omega ∑kzk=Ω
- p ( z ) = ∑ k p ( z k ) = ∑ k π k = 1 p(z)= \sum_k{p(z_k)}=\sum_k{\pi_k}=1 p(z)=∑kp(zk)=∑kπk=1
- p ( x ∣ z k ) = N ( x ∣ μ k , Σ k ) p(x|z_k)= \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k) p(x∣zk)=N(x∣μk,Σk)
- p ( x ) = ∑ k p ( x ) p ( x ∣ z k ) p(x)= \sum_kp(x)p(x|z_k) p(x)=∑kp(x)p(x∣zk)
根据贝叶斯定理, p ( z ) p(z) p(z)是先验概率, p ( x ∣ z ) p(x∣z) p(x∣z)是似然概率, p ( z ∣ x ) p(z∣x) p(z∣x)是后验概率。设 x = { x 1 , x 2 , . . . x N } \boldsymbol{x}=\{x_1,x_2,...x_N\} x={x1,x2,...xN},我们有
- p ( z ∣ x ) = p ( x ∣ z ) p ( z ) p(z∣x)=p(x∣z)p(z) p(z∣x)=p(x∣z)p(z)
- μ k = 1 N k ∑ n p ( z ∣ x n ) p ( x n ) μ_k=\frac{1}{N_k}\sum_np(z∣x_n)p(x_n) μk=Nk1∑np(z∣xn)p(xn)
EM算法
- 定义分量数目 k k k,对每个分量设置 π k \pi_k πk、 μ k μ_k μk和 Σ k \boldsymbol{\Sigma}_ k Σk 的初始值,然后计算对数似然函数。
l n p ( x ∣ π , μ , Σ ) = ∑ n l n ∑ k π k N ( x n ∣ μ k , Σ k ) ln\ \ p(x|\pi,μ,\boldsymbol{\Sigma})= \sum_n\ ln\sum_k\pi_kN(x_n∣μ_k,\boldsymbol{\Sigma}_k) ln p(x∣π,μ,Σ)=∑n ln∑kπkN(xn∣μk,Σk)
- E 阶段: 根据当前的 π k \pi_k πk、 μ k μ_k μk和 Σ k \boldsymbol{\Sigma}_ k Σk 计算后验概率 γ ( z n k ) γ(z_{nk}) γ(znk)
γ ( z n k ) = π k N ( x n ∣ μ n , Σ n ) ∑ j = 1 k π j N ( x n ∣ μ j , Σ j ) γ(z_{nk})=\frac{π_kN(x_n∣μ_n,\boldsymbol{\Sigma}_n)} {∑_{j=1}^kπ_jN(x_n∣μ_j,\boldsymbol{\Sigma}_ j)} γ(znk)=∑j=1kπjN(xn∣μj,Σj)πkN(xn∣μn,Σn)
- M阶段:根据E阶段中计算的 γ ( z n k ) \gamma(z_{nk}) γ(znk)再计算新的 π k \pi_k πk、 μ k μ_k μk和 Σ k \boldsymbol{\Sigma}_ k Σk
令 N k = ∑ n γ ( z n k ) N_k=\sum_n\gamma(z_{nk}) Nk=∑nγ(znk) ,则:
- π k = N k N \pi_k=\frac{N_k}{N} πk=NNk
- μ k = 1 N k ∑ n γ ( z n k ) x n μ_k=\frac{1}{N_k}\sum_n\gamma(z_{nk}) x_n μk=Nk1∑nγ(znk)xn
- Σ k = 1 N k ∑ n γ ( z n k ) ( x n − μ k ) ( x n − μ k ) T \boldsymbol{\Sigma}_ k=\frac{1}{N_k}\sum_n\gamma(z_{nk})(x_n-μ_k)(x_n-μ_k)^T Σk=Nk1∑nγ(znk)(xn−μk)(xn−μk)T
-
重新计算步骤1中的对数似然函数
-
检查参数是否收敛或对数似然函数是否收敛,若不收敛,则返回第2步。
其他参考
EM算法
详解EM算法与混合高斯模型
高斯混合模型(GMM)及其EM算法的理解
更多聚类算法参考我另一篇博客:无监督算法















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









