






数据集
继上次的图像聚类后,这次准备对比有监督学习的分类和无监督学习的聚类,以及无监督学习聚类中,对比在低维度且简单分布的数据中,各个模型的聚类效果。
首先附上数据集:
链接:https://pan.baidu.com/s/1LNu8toOmGXVz9b7t2Ah-6A
提取码:6fwb
这次数据集很简单,就是1500个二维坐标点,分为3类。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
data = pd.read_csv('D:/桌面/data.csv')
print(data.head())
X_df = data.iloc[0:,:2] # 方便后续可视化对比
X = data.iloc[0:,:2].values # 数组形式
[V1, V2]代表了一组二维数据点,而对应的label就是该组点的分类。数组形式的数据方便训练,dataframe形式方便后面可视化对比效果。
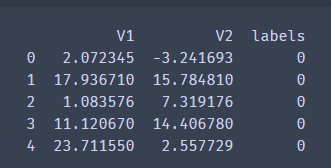
看看我们的y标签。
y = data.loc[:,'labels']
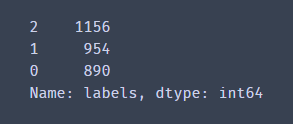
print(pd.value_counts(y))
数据总共被分为3类,其中0标签890组,1标签954组,2标签1156组。
对我们的真实数据标签进行可视化。
plt.figure(figsize=(6,5), dpi=100)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data')
plt.legend()
plt.savefig('D:/桌面/true data.png')
人眼可以很明显的看出,这1500组数据被分为3组,每一组都集中分布在一块区域。还是很容易区分的。接下来就可以看看无监督学习和有监督学习在这份数据集上的表现了。

无监督学习
Meanshift
Mean-shift 聚类是一个基于滑窗的算法,尝试找到数据点密集的区域。它是一个基于质心的算法,也就是说他的目标是通过更新中心点候选者定位每个组或类的中心点,将中心点候选者更新为滑窗内点的均值。这些候选滑窗之后会在后处理阶段被过滤,来减少临近的重复点,最后形成了中心点的集合和他们对应的组。
他有个很明显的优点是,meanshift不怕噪声点,会自动过滤然后检测出来。缺点也很明显,因为是基于滑窗的,也就是下面代码中要确定的bandwidth,这一选择导致meanshift往往运行较慢。
好在sklearn给我们estimate_bandwidth方法能够自动计算出带宽。这点倒是非常的省心。减轻我们调参的痛苦。
from sklearn.cluster import MeanShift, estimate_bandwidth
# 自动获取meanshift带宽
bw = estimate_bandwidth(X,n_samples=151)
print(bw)
# 设置模型
ms = MeanShift(bandwidth=bw)
ms.fit(X)
# 预测
y_predict_ms = ms.predict(X)
print(y_predict_ms)
from collections import Counter
print(Counter(y_predict_ms)) # 预测结果统计
from sklearn.metrics import accuracy_score
accuracy_score(y,y_predict_ms)
很多小伙伴肯定会诧异,为什么正确率才31%?这是因为我们meanshift是无监督学习,它不知道每组数据的原始标签。观察上方代码,我们也确实没有把y标签输入给meanshift模型。因此我们还需要校正结果。
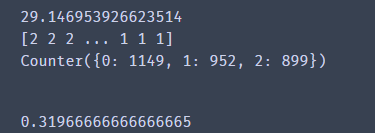
观察数据的数量,我们可以得出由meanshift得出的标签和真实标签对应的结果。然后就可以进行校正。
# 校正结果
y_corrected_ms = []
for i in y_predict_ms:
if i==0:
y_corrected_ms.append(2)
elif i==1:
y_corrected_ms.append(1)
else:
y_corrected_ms.append(0)
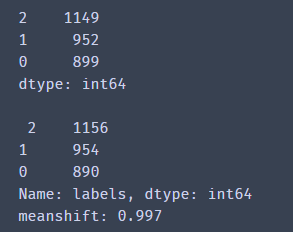
print(pd.value_counts(y_corrected_ms),'\n\n',pd.value_counts(y))
from sklearn.metrics import accuracy_score
print('meanshift:',accuracy_score(y,y_corrected_ms))
看到我们的meanshift模型很不错,正确率达到了99.7%
但是这是以时间为代价的。耗时较长。
对meanshift模型预测后并校正的结果和我们真实数据放在同一张图进行可视化对比。
# meanshift可视化
y_corrected_ms = np.array(y_corrected_ms)
plt.figure(figsize=(11,5), dpi=100)
plt.subplot(121)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data')
plt.legend()
plt.subplot(122)
plt.scatter(X_df.loc[:,'V1'][y_corrected_ms==0],
X_df.loc[:,'V2'][y_corrected_ms==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_corrected_ms==1],
X_df.loc[:,'V2'][y_corrected_ms==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_corrected_ms==2],
X_df.loc[:,'V2'][y_corrected_ms==2], label='2')
plt.title('meanshift predicted')
plt.legend()
plt.savefig('D:/桌面/meanshift.png')
我们发现,在每个类别数据扎堆的中心附近,meanshift模型分类效果很不错。有误差的地方在于边界,交界处meanshift就处理不太好。有几个数据判断错误。

DBSCAN
相较于其他聚类算法,DBSCAN 提出了一些很棒的优点。首先,它根本不需要预置集群的数量。它还将离群值认定为噪声,不像 mean-shift 中仅仅是将它们扔到一个集群里,甚至即使该数据点的差异性很大也这么做。另外,这个算法还可以很好的找到任意尺寸核任意形状的集群。
DBSCAN 最大的缺点是当集群的密度变化时,它表现的不像其他算法那样好。这是因为当密度变化时,距离的阈值 ε 和用于确定邻居点的 minPoints 也将会随之改变。这个缺点也会发生在很高为的数据中,因为距离阈值 ε 变得很难被估计。也就是下面代码的eps和min_samples,这两个超参数非常让人头疼,想要的出好的结果就不断的调试,sklearn也没有直接帮我们确定这两个超参数的方法。博主总结出来的经验是,如果数据集较小的话就可以eps调大,min_samples调小,如果数据集较大的话就反着来。
from sklearn.cluster import DBSCAN
# 密度聚类之DBSCAN算法
print("===DBSCAN聚类===")
# 设置模型
dbscan = DBSCAN(eps=5.8, min_samples=8)
# 预测
dbscan.fit(X)
y_predict_dbscan = dbscan.labels_
from collections import Counter
print(Counter(y_predict_dbscan)) # 预测结果统计
from sklearn.metrics import accuracy_score
accuracy_score(y,y_predict_dbscan)
和上面一样,由于是无监督学习,我们仍然要进行结果校正。
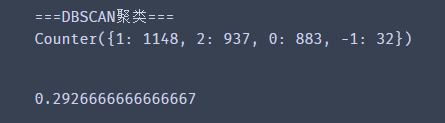
校正结果。
# 校正结果
y_corrected_dbscan = []
for i in y_predict_dbscan:
if i==1:
y_corrected_dbscan.append(2)
elif i==2:
y_corrected_dbscan.append(1)
else:
y_corrected_dbscan.append(0)
print(pd.value_counts(y_corrected_dbscan),'\n\n',pd.value_counts(y))
from sklearn.metrics import accuracy_score
print('DBSCAN:',accuracy_score(y,y_corrected_dbscan))
看到我们DBSCAN模型正确率和meanshift相差不多。

对其进行可视化。
# dbscan可视化
y_corrected_dbscan = np.array(y_corrected_dbscan)
plt.figure(figsize=(11,5), dpi=100)
plt.subplot(121)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data')
plt.legend()
plt.subplot(122)
plt.scatter(X_df.loc[:,'V1'][y_corrected_dbscan==0],
X_df.loc[:,'V2'][y_corrected_dbscan==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_corrected_dbscan==1],
X_df.loc[:,'V2'][y_corrected_dbscan==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_corrected_dbscan==2],
X_df.loc[:,'V2'][y_corrected_dbscan==2], label='2')
plt.title('dbscan predicted')
plt.legend()
plt.savefig('D:/桌面/DBSCAN.png')
和上面meanshift一样,DBSCAN模型对于大部分点的分类结果较好,但是对于里分类中心稍远的点就容易判断错误,有一些是噪声点,博主把他们归为蓝色了。这样很明显看出DBSCAN对于密度小的地方就容易判断为噪声点。和meanshift一样,DBSCAN对于2分类边界处也存在模糊判断的结果。

GMM
高斯混合模型可以看作是由 K 个单高斯模型组合而成的模型。一般来说,一个混合模型可以使用任何概率分布,这里使用高斯混合模型是因为高斯分布具备很好的数学性质以及良好的计算性能。
让我们来看看高斯混合模型有没有上面2个模型的通病。
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=3, covariance_type='full')
gmm.fit(X)
y_predict_gmm = gmm.predict(X)
# print(y_gmm)
from collections import Counter
print(Counter(y_predict_gmm)) # 预测结果统计
from sklearn.metrics import accuracy_score
accuracy_score(y,y_predict_gmm)
一样的,因为高斯混合模型也是无监督学习,所以仍然需要校正结果。
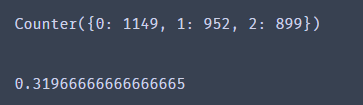
校正结果。
# 校正结果
y_corrected_gmm = []
for i in y_predict_gmm:
if i==1:
y_corrected_gmm.append(2)
elif i==2:
y_corrected_gmm.append(0)
else:
y_corrected_gmm.append(1)
print(pd.value_counts(y_corrected_gmm),'\n\n',pd.value_counts(y))
from sklearn.metrics import accuracy_score
print('gmm:',accuracy_score(y,y_corrected_gmm))
我们发现高斯混合模型的正确率还挺高的,和meanshift正确率一样。那么这是否代表gmm模型也有meanshift和DBSCAN的通病呢。

对gmm模型预测的分类结果进行可视化。
# gmm可视化
y_corrected_gmm = np.array(y_corrected_gmm)
plt.figure(figsize=(11,5), dpi=100)
plt.subplot(121)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data')
plt.legend()
plt.subplot(122)
plt.scatter(X_df.loc[:,'V1'][y_corrected_gmm==0],
X_df.loc[:,'V2'][y_corrected_gmm==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_corrected_gmm==1],
X_df.loc[:,'V2'][y_corrected_gmm==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_corrected_gmm==2],
X_df.loc[:,'V2'][y_corrected_gmm==2], label='2')
plt.title('gmm predicted')
plt.legend()
plt.savefig('D:/桌面/gmm.png')
gmm不像DBSCAN对于密度小的区域就判断为噪声点,它仍然能够较好的归类,但对于边界处,仍然还是判断有误。

有监督学习
有监督学习比起无监督学习最大的特点在于它需要输入每组数据的标签,那这样是否能够解决无监督学习的通病呢?下面看一个经典的有监督学习的聚类模型–knn。
KNN
建立knn模型,注意我们要对其输入X和y,二维数据和标签都需要输入。
# 建立knn模型
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X,y)
y_predict_knn = KNN.predict(X)
from collections import Counter
print(Counter(y_predict_knn)) # 预测结果统计
print(pd.value_counts(y_predict_knn),'\n\n',pd.value_counts(y))
from sklearn.metrics import accuracy_score
accuracy_score(y,y_predict_knn)
因为输入了标签,有监督学习就不会产生无监督学习那样标签混乱的现象。因为其输入了每一组数据对应的y标签,因此对训练集预测的正确率为100%是理所当然的。

对其进行可视化。
# knn可视化
plt.figure(figsize=(11,5), dpi=100)
plt.subplot(121)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data')
plt.legend()
plt.subplot(122)
plt.scatter(X_df.loc[:,'V1'][y_predict_knn==0],
X_df.loc[:,'V2'][y_predict_knn==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_predict_knn==1],
X_df.loc[:,'V2'][y_predict_knn==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_predict_knn==2],
X_df.loc[:,'V2'][y_predict_knn==2], label='2')
plt.title('knn predicted')
plt.legend()
plt.savefig('D:/桌面/knn.png')
可以看到knn这一有监督学习在输入标签后,对训练集的再预测达到了100%准确率,那不妨拿个测试数据来测试下。

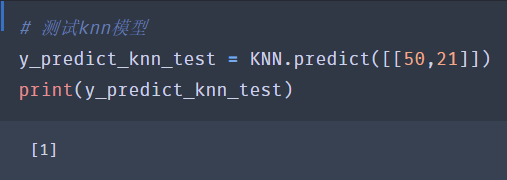
对knn模型进行测试。
# 测试knn模型
y_predict_knn_test = KNN.predict([[50,21]])
print(y_predict_knn_test)
我们选取的点是[50,21],大家观察下,这个数据点似乎是属于3个类别中间,根据人眼判断,博主认为是属于橙色,也就是1标签的。来看看kmm模型的测试结果吧。

结果果然是1,和博主肉眼判断的一样。看来有监督学习效果还是不错的,对于边界区域的判断是挺清楚的。
综合对比
无监督学习的聚类没有输入标签,这会导致其结果判断的标签混乱,需要人工校正结果。而有监督学习的聚类因为在训练过程中已经输入了标签,在预测的时候就不会导致预测出来的结果标签混乱。
无监督学习的聚类还有一个不太理想的地方在于其预测的结果在某两种分类的边界区域会产生模糊判断,也就是分类效果不佳。而有监督学习的分类效果仍然不错,目前看来和博主的眼睛判断差不多,具有一定的水平。
下面就来一张所有的模型的对比吧!主要观察2个地方,1是某类数据的边缘,2是某两类数据的边界。

下面是集体可视化的代码。
# meanshift可视化
plt.figure(figsize=(20,44), dpi=100)
plt.subplot(421)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data', fontsize=30)
plt.legend()
plt.subplot(422)
plt.scatter(X_df.loc[:,'V1'][y_corrected_ms==0],
X_df.loc[:,'V2'][y_corrected_ms==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_corrected_ms==1],
X_df.loc[:,'V2'][y_corrected_ms==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_corrected_ms==2],
X_df.loc[:,'V2'][y_corrected_ms==2], label='2')
plt.title('meanshift predicted', fontsize=30)
plt.legend()
# dbscan可视化
plt.subplot(423)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data', fontsize=30)
plt.legend()
plt.subplot(424)
plt.scatter(X_df.loc[:,'V1'][y_corrected_dbscan==0],
X_df.loc[:,'V2'][y_corrected_dbscan==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_corrected_dbscan==1],
X_df.loc[:,'V2'][y_corrected_dbscan==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_corrected_dbscan==2],
X_df.loc[:,'V2'][y_corrected_dbscan==2], label='2')
plt.title('dbscan predicted', fontsize=30)
plt.legend()
# gmm可视化
plt.subplot(425)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data', fontsize=30)
plt.legend()
plt.subplot(426)
plt.scatter(X_df.loc[:,'V1'][y_corrected_gmm==0],
X_df.loc[:,'V2'][y_corrected_gmm==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_corrected_gmm==1],
X_df.loc[:,'V2'][y_corrected_gmm==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_corrected_gmm==2],
X_df.loc[:,'V2'][y_corrected_gmm==2], label='2')
plt.title('gmm predicted', fontsize=30)
plt.legend()
# knn可视化
plt.subplot(427)
plt.scatter(X_df.loc[:,'V1'][y==0], X_df.loc[:,'V2'][y==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y==1], X_df.loc[:,'V2'][y==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y==2], X_df.loc[:,'V2'][y==2], label='2')
plt.title('true data', fontsize=30)
plt.legend()
plt.subplot(428)
plt.scatter(X_df.loc[:,'V1'][y_predict_knn==0],
X_df.loc[:,'V2'][y_predict_knn==0], label='0')
plt.scatter(X_df.loc[:,'V1'][y_predict_knn==1],
X_df.loc[:,'V2'][y_predict_knn==1], label='1')
plt.scatter(X_df.loc[:,'V1'][y_predict_knn==2],
X_df.loc[:,'V2'][y_predict_knn==2], label='2')
plt.title('knn predicted', fontsize=30)
plt.legend().get_title().set_fontsize(fontsize = 50)
plt.savefig('D:/桌面/all.png')















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









