







CornerNet
1 Introduction
anchor 有两个缺点:第一,我们需要很多anchors,这在正样本anchor和负样本anchor之间造成了巨大额不平衡。第二,anchor引入了很多超参数和设计选择,合资的个数,anchor大小,纵横比等。如果与多尺度体系结构结合,则会变得更加复杂。

corner pooling是一种新型的pooling layer,它可以帮助卷积网络更好地定位边框的corner,包围框的角通常在物体之外,在这种情况下,不能根据局部证据来定位一个角,要确定某像素位置是否有左上角,我们需要水平地向右看对象的最顶层边界,垂直向底部看最左边的边界,这激发了我们的corner pooling:它包含两个特征图; 在每个像素位置,它最大池化从第一个特征映射到右侧的所有特征向量,最大池化从第二个特征映射下面的所有特征向量,然后将两个池化结果一起添加,如图3所示。

为什么检测corner 更好一些,第一,box的中心取决于四个边,而corner取决于两个边,第二,corner提供了一种更有效的方式来密集的离散边界框的空间,我们只需要用O(wh)来表示O(w2h2)个可能的anchor boxes。
3 CornerNet
3.1 Overview
我们将bounding box检测为一堆关键点(右上角和左下角)。卷积网络通过预测两组heatmap来表示不同物体类别的角的位置,一组用于左上角,一组用于右下角。网络还预测每个检测到的corner嵌入向量,使得来自同一目标的两个corner之间的距离很小。为了产生更紧密的bounding box,网络还预测偏移以稍微调整角的位置,通过预测heatmap,嵌入和偏移,我们用一个简单的后处理算法来获得最终的bounding box。

我们使用hourglass作为骨干网络,backbone之后是两个预测模块,一个模块用于左上角,一个右下。每个模块都有自己的corner pooling模块,在预测heatmap,嵌入和偏移之前,对backbone的feature进行池化。我们不会使用多尺度特征来检测不同大小的物体。
3.2 Detecting Corners
我们预测两组热图,一组用于左上角,另一组用于右下角。 每组热图具有C个通道,其中C是分类的数量,并且大小为H×W。没有背景channel,每个channel都是一个二进制mask,用于表示该类的corner位置。
对于每个corner,只有一个ground-Truth正位置,其他所有位置都是负位置,在训练时,我们没有同等的惩罚负位置,而是减少对正位置半径内的负位置给与惩罚。这是因为如果一对假corner检测器靠近它们各自的ground-truth位置,它仍然可以产生一个与ground-truth充分重叠的边界框。我们通过确保半径内的一对点生成的边界框与ground-truth的IoU >= t来确定物体的大小(我们在实验中设为0.7),从而确定半径。对于给定半径,惩罚的减少量由非标准化的2D高斯
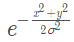
给出,其中心位于正位置,其σ时半径的1/3。
pcij为预测heatmap中c类位置(i,j)的得分,ycij为用非标准化高斯增强的ground-truth heatmap,我们设计了一个局部损失的变体:
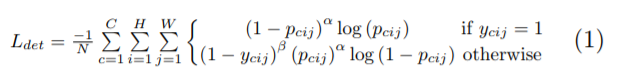
其中N是图像中目标的数量,α和β是控制每个点贡献的超参数(我们在实验中设α=2,β=4).利用ycij中编码的高斯凸点,(1 - ycij)项减少了ground-truth周围的惩罚。
卷积网络的输出尺寸通常小于图像,因此可能丢失一些精度,这会极大的影响小边界框与ground-truth之间的IoU,所以我们还预测位置偏移,以稍微调整角位置,然后再重新映射到输入分辨率。
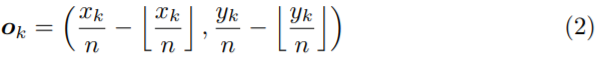
其中ok是偏移量,xk和yk是角点k kk的x xx和y yy坐标。 特别是,我们预测所有类别的左上角共享一组偏移,另一组由右下角共享。对于训练,我们再ground-truth corner 位置应用平滑的L1损失:
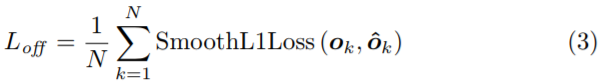
3.3 Grouping Corner
图像中可能出现多个目标,因此可能检测到多个左上角和右下角。我们需要确定左上角和右下角的一对角点是否来自同一个目标边界框。网络预测每个检测到的角点的嵌入向量,使得如果左上角和右下角属于同一个边界框,则它们的嵌入之间的距离应该小。 然后,我们可以根据左上角和右下角嵌入之间的距离对角点进行分组。etk成为对象k的左上的嵌入,ebk为右下角的的嵌入。 如[26]中所述,我们使用“pull”损失来训练网络对角点进行分组,并且用“push”损失来分离角点:

其中ek 是etk和ebk的平均值,我们在所有实验中将Δ设为1。 与偏移损失类似,我们仅在ground-truth角点位置应用损失。
3.4 Corner Pooling
该层有2个输入特征图,特征图的宽高分别用W和H表示,假设接下来要对图中红色点(坐标假设是(i,j))做corner pooling,那么就计算(i,j)到(i,H)的最大值(对应图9上面第二个图),类似于找到图9 中第一张图的左侧手信息;同时计算(i,j)到(W,j)的最大值(对应图9下面第二个图),类似于找到图8 中第一张图的头顶信息,然后将这两个最大值相加得到(i,j)点的值(对应图9最后一个图的蓝色点)。例如feature map的大小是10x10,现在的一个点是(2,1),那么top-left corner pooling就是计算(2,1)到(2,10)这条线上的最大值和(2,1)到(10,1)这条线上的最大值,并将它们进行叠加。实际计算的时候,可以通过反向计算来实现,如图10所示那样。右下角点的corner pooling操作类似,只不过计算最大值变成从(0,j)到(i,j)和从(i,0)到(i,j)。

在这里,我们应用了一个elementwise最大化操作。动态规划可以有效地计算tij和lij。我们以类似的方式定义右下角池化层。最大池化(0,j) (0,j)(0,j)与(i,j) (i,j)(i,j)之间所有的特征向量、(i,0) (i,0)(i,0)与(i,j) (i,j)(i,j)之间所有的特征向量,然后将池化结果相加。Corner pooling层用于预测模块,用于预测热图、嵌入和偏移量。
我们提出corner Pooling通过编码显式先验知识来更好地定位角点。假设我们要确定(i,j) 位置是左上角,设 ft 和 fl 为左上角池化层的输入feature map。ftij
和 flij 分别为(i,j) (i,j)(i,j)位置中 ft 和 fl 的向量。H×W H×WH×W的特征映射,corner pooling层首先最大池化 ft 中在(i,j) (i,j)(i,j)与(i,H) (i,H)(i,H)之间所有的特征向量,使之成为特征向量 tij ,还有,最大池化fl中在(i,j) (i,j)(i,j)与(W,j) (W,j)(W,j)之间所有的特征向量,使之成为特征向量 lij 。最后把 tij 和 lij 加在一起。这个计算可以用以下公式表示:


预测模块的结构如图7所示。模块的第一部分是残差模块的修改版本。在这个修改后的残差模块中,我们将第一个3×3的卷积模块替换为一个corner pooling模块。这个残差模块,首先通过具有128个通道的2个3×3卷积模块的主干网络处理特征,然后应用一个corner pooling层。残差模块之后,我们将池化特征输入具有256个通道的3×3的Conv-BN层,然后加上反向projection shortcut。修改后的残块,后跟一个具有256个通道的3×3的卷积模块,和3个256通道的Conv-ReLU-Conv层来产生热图,嵌入和偏移量。
3.5 Hourglass Networ
CornerNet使用沙漏网络作为其骨干网络。沙漏网络首次被提到是用于人体姿态估计任务。它是一个完全卷积神经网络,由一个或多个沙漏模块组成。沙漏模块首先通过一系列卷积层和最大池化层对输入特性进行下采样。然后通过一系列的上采样和卷积层将特征上采样回原来的分辨率。由于细节在最大池化层中丢失,因此添加了跳过层用来将细节带回到上采样的特征。沙漏模块在一个统一的结构中捕获全局和局部特征。当多个沙漏模块堆积在网络中时,沙漏模块可以重新处理特征以获取更高级别的信息。这些特性使沙漏网络成为目标检测的理想选择。事实上,许多现有的检测器已经采用了类似沙漏网络的网络。
我们的沙漏网络由两个沙漏组成,我们对沙漏模块的结构做了一些修改。我们不使用最大池,而是使用步长2来降低特征分辨率。我们减少了5倍的特征分辨率,并增加了特征通道的数量(256,384,384,384,512)。当我们对特征进行上采样时,我们应用了两个残差模块,然后是一个最近的相邻上采样。每个跳跃连接还包含两个残差模块。沙漏模块中间有4个512通道的残差模块。在沙漏模块之前,我们使用128个通道7×7的卷积模块,步长为2,4倍减少的图像分辨率,后跟一个256个通道,步长为2的残差块。
在基础上,我们还在训练时增加了中间监督。但是,我们没有向网络中添加反向中间预测,因为我们发现这会损害网络的性能。我们在第一个沙漏模块的输入和输出,应用了一个3×3的Conv-BN模块。然后,我们通过元素级的加法合并它们,后跟一个ReLU和一个具有256个通道的残差块,然后将其用作第二个沙漏模块的输入。沙漏网络的深度为104。与许多其他最先进的检测器不同,我们只使用整个网络最后一层的特征来进行预测。
参考:https://blog.csdn.net/weixin_40414267/article/details/82379793















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









